基于关联规则和时间阈值算法的5G基站部署研究
2016-12-10陈少权杜翠凤
陈少权+杜翠凤
【摘 要】为了保障高价值用户感知,从高价值用户的业务连续性出发,探寻高价值用户使用业务的局部兴趣区域,并结合用户逗留时间来对基站进行评分,以评分高的区域作为通信运营商部署5G基站的优先点。经过实验表明,在极具稀疏性的数据集上,基于关联规则算法的精度较以往传统的方法有明显提高,且具有较高的扩展性。
【关键词】关联规则 时间阈值 用户感知 业务连续性 兴趣区域
doi:10.3969/j.issn.1006-1010.2016.20.004 中图分类号:TP391.4 文献标志码:A 文章编号:1006-1010(2016)20-0022-05
1 引言
随着第四代移动通信技术的快速发展以及移动互联网的大规模应用,给高价值用户感知的维护带来了严峻的挑战,目前的网络规划是否能够满足用户业务连续性使用的需求,成为5G时代亟待解决的问题。本文从高价值用户的业务连续性出发,探寻高价值用户使用业务的局部兴趣区域,并结合用户逗留时间来对基站进行评分,以此作为通信运营商部署5G基站的优先点。
2 关联规则算法的研究
2.1 问题定义
用户使用业务的局部兴趣区域是研究用户出行行为的一个关键性的问题,局部兴趣区域识别实质是通过轨迹数据分析得到的用户的兴趣区域集合,再根据设定的阈值范围筛选具有价值的兴趣区域。基于用户的局部兴趣区域,并结合用户逗留时间来对基站进行评分,以评分高的基站作为通信运营商部署5G基站的优先点。
本文是采用Apriori算法挖掘出移动用户具有一定价值的兴趣区域,再通过时间阈值对用户的兴趣区域进行打分,以高得分的区域作为移动运营商部署5G基站的优先点。
2.2 关联规则——Apriori算法
(1)关联规则算法
关联规则的获取主要是通过数据挖掘的方法,从大量的事件记录数据库中找出那些用户给定的满足一定条件的最小支持度(Minsup)和最小置信度(Minconf)的频繁模式[1-2]。关联规则的传统算法步骤是:先找出所有的频繁项目集,再由频繁项目集产生满足最小支持度和最小置信度的规则。因此,关联规则的属性可用以下参数描述[2-3]:
◆支持度:全体事务集T中有s%同时支持事务集X和Y,则称s%为关联规则X→Y的支持度。支持度S(X→Y)表示规则的频繁程度,一般用Minsup表示最小支持度。
◆置信度:全体事务集T中支持事务集X的事务里有c%的事务同时也支持事务集Y,则称c%为关联规则X→Y的置信度。置信度C(X→Y)表示规则的强度,一般用Minconf表示最小置信度。
◆频繁项集:满足一定最小支持度和最小置信度的事务集。基于关联规则的算法以Apriori算法为代表,利用逐层搜索的迭代方法找出数据库中项集的关系,以形成规则,其过程由连接(类矩阵运算)与剪枝(去掉那些没必要的中间结果)组成。该算法中项集(Itemset)的概念即为项的集合,包含k个项的集合为K项集。项集出现的频率是包含项集的事务数,称为项集的频率。如果某项集满足最小支持度,则称其为频繁项集[4]。
(2)Apriori算法实现步骤
Apriori算法实现步骤具体如下:
◆设定最小支持度(Minsup)和最小置信度(Minconf)。
◆Apriori算法是一种需要多次迭代的算法,经过扫描一次数据库,统计数据库中单个项目的计数,将满足最小支持度要求的单个项目提取成1-频繁项集L1,并将频繁项目L1作为下一次扫描的基础项目[3]。然后重复扫描数据库,第(k-1)次扫描生成(k-1)-频繁项集L后,第k次扫描时先通过连接操作将Lk-1中的项集生成k-项候选集Ck,再通过剪枝操作删除Ck中不满足最小支持度计数的项集,从而得到频繁项集Lk。重复扫描数据库,从该集合里产生下一级候选项集,直到不产生新的候选项集为止[4]。
2.3 时间阈值实现步骤
时间阈值法作为移动对象频繁模式挖掘的常用算法,其定义为:在一定时间范围内,用户发生事件之间先后顺序的事件间隔大于δ,只有满足该条件,才能挖掘移动对象频繁模式。本文通过检测移动用户停留在用户频繁活动区域的时间间隔,如果用户都留在该区域的时间大于设定的时间阈值且评分较高,则判定该区域是5G基站部署的优先点。
其实现步骤具体如下:
(1)通过Apriori算法找到兴趣区域数据——小区;
(2)对每个移动用户所涉及到的兴趣小区按照时间顺序排序:Cell1(Lngt1, Lat1, t11, t12), Cell2(Lngt2, Lat2, t21, t22), …, Cellm(Lngtm, Latm, tm1, tm2);
(3)遍历Cell1-Cellm ,判断每个Cell的停留时间是否大于设定的阈值δ,若大于则评分为1,否则为0;
(4)遍历每个Cell的停驻点,计算每个用户在每一个Cell的得分,再通过归一化得出每个基站的最终得分。
3 基于关联规则和时间阈值算法挖掘5G优先部署站点
3.1 移动用户轨迹数据的提取
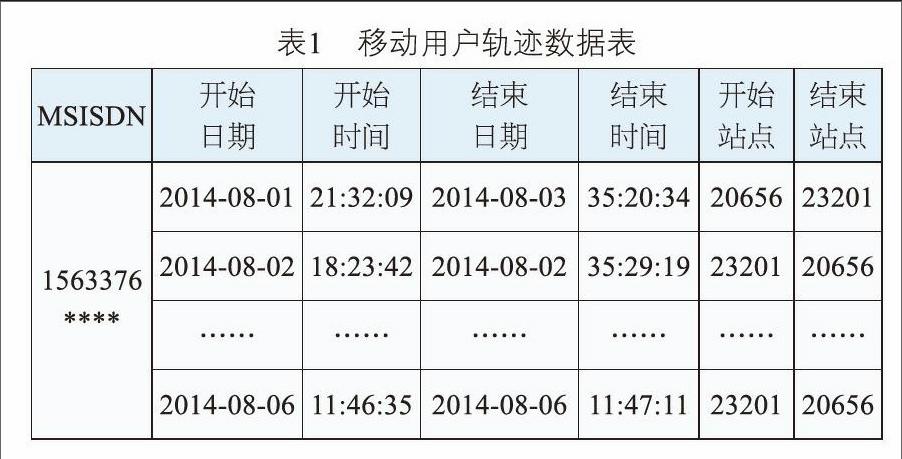
在提取用户的轨迹数据之前,首先需要说明切换的定义。切换是指当移动台在通话过程中从一个基站覆盖区移动到另一个基站覆盖区或者由于外界干扰造成通话质量下降时,必须改变原有的话音信道而转接到一条新的空闲话音信道上,以继续保持通话的过程。切换通常发生在移动台从一个基站覆盖小区进入到另一个基站覆盖小区的情况下,为了保持通信的连续性,MSC(Mobile Switching Center,移动交换中心)将移动台与当前基站之间的链路转移到移动台与新的基站之间的链路,这种切换操作不仅要识别一个新的基站,而且要求将语音和控制信号分配到新的基站相关信道上[5]。
在移动用户进行移动的过程中会发生各种手机业务或者进行小区的切换,这些信息都会记录在用户的轨迹数据里,具体如表1所示:
3.2 采用Apriori算法挖掘移动用户的兴趣区域
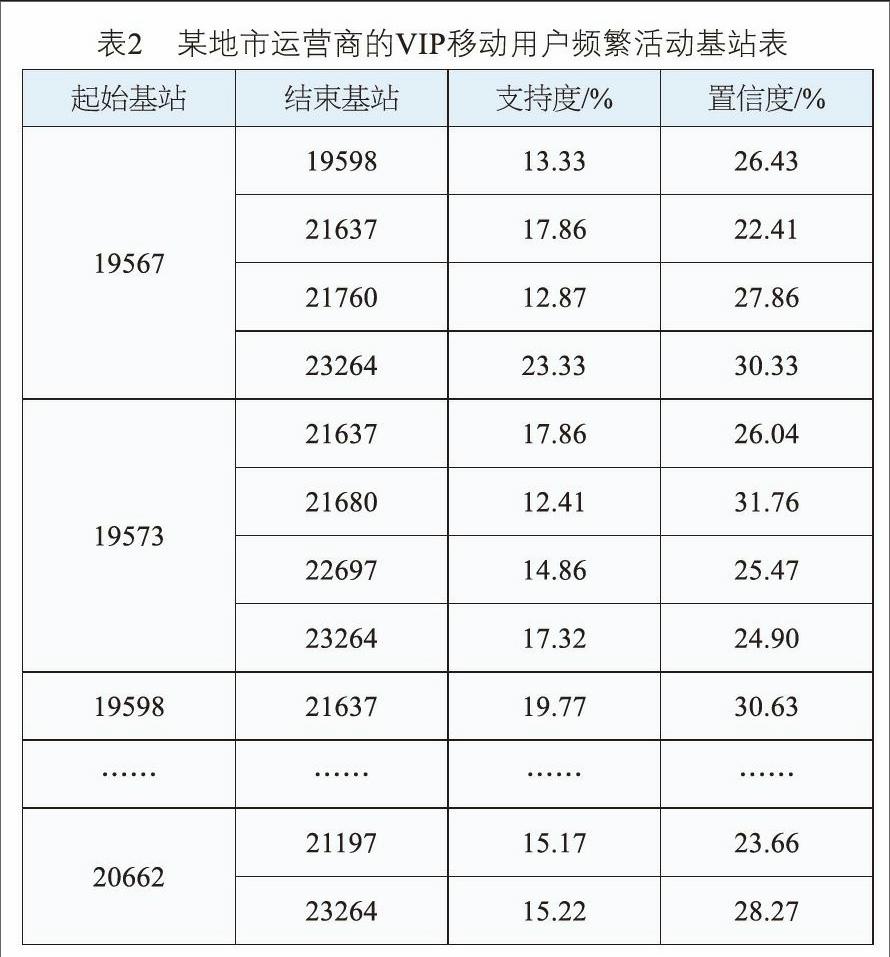
本文对某地市运营商的10万VIP移动用户在一个月工作日时间段(8点至17点)的轨迹进行分析。在实验中,min_sup设置为0.1,min_conf设置为0.2,把数据放进MATLAB中进行处理,得到的结果如表2所示。
由表2可知,有13 330名VIP移动用户在一个月工作日时间段(8点至17点)同时去过基站19567和基站19598;有3 523名VIP移动用户经过基站19567后又到达基站19598。
通过Apriori算法找到运营商关注的VIP移动用户的兴趣区域局部相似性,下一步需要通过计算VIP移动用户在该区域的停留时长,才能作为5G基站部署的优先点。
3.3 基于时间阈值识别5G基站部署的优先点
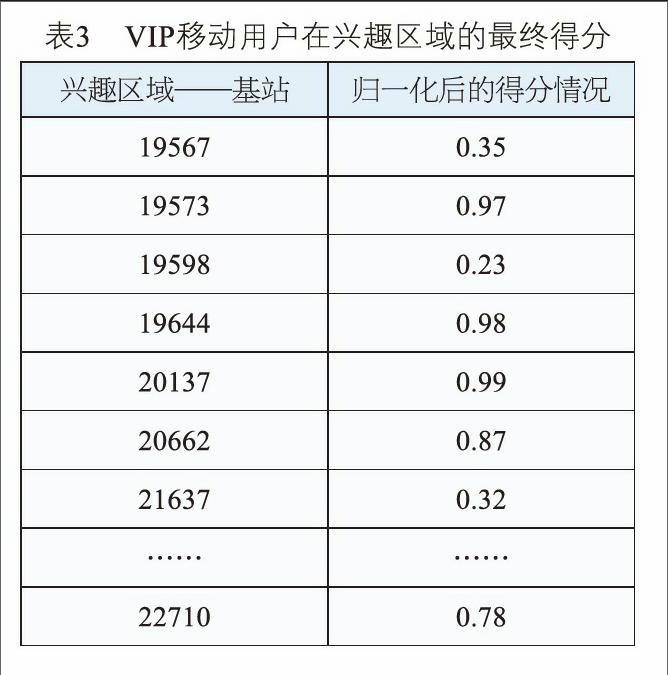
通过Apriori算法确定VIP移动用户兴趣区域的相似性后,提取每个VIP移动用户停留在兴趣区域的时间,运营商可以设置时间阈值δ识别。如果VIP移动用户在该区域停留的时间大于时间阈值δ且发生的得分较高,则认为基站可作为5G基站的优先部署点。VIP移动用户在兴趣区域的最终得分如表3所示:
由表3可知,基站19567最终得分较少,因此可以认为部署5G基站所获得的预期收益相对较少;而该用户在基站20137得分很高,则可以认为部署5G基站所获得的预期收益相对较多(注:本文认为若有价值用户在基站得分大于0.8时,则判断该基站是5G的优先部署点)。
3.4 实验结果及分析
本文对某地市运营商的10万VIP移动用户进行关联规则和时间阈值算法的处理后,将得到的结果与基于传统方法得出的5G基站优先部署点进行对比分析,具体如图1和图2所示:
通过对比图1和图2可知,采用Apriori算法和时间阈值相结合的算法来挖掘5G基站的优先部署点具有较高的精度。运营商根据有价值用户的业务行为确定5G部署的优先点,不仅实现基站的精准规划建设,使用有限的资源最大程度地满足用户的需求和提升用户的感知,而且还能保证有价值用户对运营商自身利润的贡献,提升市场竞争力。
4 结束语
本文以高价值用户感知为出发点,提出了满足高价值用户业务连续性使用需求的5G基站部署算法——基于关联规则和时间阈值的算法。通过实验证明,该算法不仅比较贴合运营商的实际需要,还能够体现网络精细化规划的思路,以最少的资源实现利润的最大化,在一定程度上提升运营商网络运行和客户维护的能力。
参考文献:
[1] 郭涛,张代远. 基于关联规则数据挖掘Apriori算法的研究与应用[J]. 计算机技术与发展, 2011,21(6): 101-103.
[2] 滕智源. 基于关联规则挖掘的Q-CFIsL算法在网络入侵检测系统中的应用[J]. 企业科技与发展, 2010(10): 59-61.
[3] 赵洪英,蔡乐才,李先杰. 关联规则挖掘的Apriori算法综述[J]. 四川理工学院学报: 自然科学版, 2011,24(1): 66-70.
[4] 赵文涛,杨静. 基于数据挖掘的煤矿安全信息管理模型的研究[J]. 工矿自动化, 2009,35(7): 36-39.
[5] 杨飞,惠英. 基于手机切换变化模式的道路匹配方法[J]. 系统工程, 2007,25(11): 6-13.
[6] Lu E H-C, Tseng V S, Yu P S. Mining cluster-based mobile sequential patterns in location-based service environments[J]. IEEE Transactions on Knowledge and Data Engineering, 2011,23(6): 914-927.
[7] Monreale A, Pinelli F, Trasarti R, et al. WhereNext: a location predictor on trajectory pattern mining[A]. Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD09)[C]. New York: ACM, 2009: 637-646.
[8] Agrawal R, Imiclinski T, Swami A. Mining Assocation Rules between Sets of Items in Large Database[A]. Proceedings of the 1993 ACM SIGMOD Conference on Management of Data Table of Contents[C]. New York: ACM, 1993: 207-216.
[9] 王德兴. 基于概念格模型关联规则挖掘的关键问题研究[D]. 合肥: 合肥工业大学, 2006.
[10] 罗可,贺才望. 基于Apriori算法改进的关联规则提取算法[J]. 计算机与数字工程, 2006,34(4): 48-51.
