大兴安岭蒙古栎生物量分配格局与可加性模型研究
2020-06-29孟盛旺常广军彭道黎刘秦笑芝
阳 帆 孟盛旺 王 威 常广军 彭道黎 刘秦笑芝
(1.北京林业大学林学院, 北京 100083; 2.中国科学院地理科学与资源研究所生态系统网络观测与模拟重点实验室, 北京 100101;3.国家林业和草原局调查规划设计院, 北京 100714; 4.内蒙古自治区第二林业监测规划院, 乌兰浩特 137400;5.中国林业科学研究院华北林业实验中心, 北京 102300)
0 引言
作为陆地生态系统最大的碳库,森林在维持区域碳平衡和应对全球气候变化中具有不可替代的作用[1-4]。森林碳储量通常是基于生物量采用含碳系数转换而来[5],因此,作为重要的生物学特征和生态学指标,森林生物量的准确核算具有重要意义。
生物量最准确的测定方法是在野外将树木伐倒后直接称量,也称为收获法,但这种方法破坏性大,且耗时、耗力[6],而且仅能在一定范围或较小的个体上使用,不适合大面积或保护区的森林生物量估算[7]。异速生长模型结构简单、使用方便,基于易测变量即可快速实现生物量估算,已经成为十分有效的森林生物量测定手段[8-9]。通常情况下,生物量模型是干物质量与胸径之间的回归模型,也有许多研究将树高、冠幅、树龄等变量添加到模型中,以提高生物量的预测能力[10-12],木材密度也用于混合树种的生物量模型中[13]。除模型的自变量多样化外,模型形式也多种多样,其中,最常用的形式为幂函数及其对数转换形式[14-15]。
树木总生物量可分为地上生物量和根系生物量,地上生物量又由树干、树枝和树叶生物量构成,由于林木各组分之间存在内在相关性,因此树木各组分模型的预测值之和应等于总量模型的预测值[16]。目前,针对全球主要分布树种构建了许多生物量模型,但大多采用最小二乘法对总量、分量模型单独拟合,使模型之间不具有可加性[17],导致预测结果不符合生物学逻辑。因此,构建生物量模型时,有必要考虑可加性[18-19]。生物量模型的可加性已有几十年的研究历史,研究者提出了多种手段来解决线性或非线性模型的可加性问题[20-22]。近年来,使用最广泛的是似乎不相关模型(Seemingly unrelated regression,SUR),该模型通过联立方程系统,综合考虑了不同组分之间的关联性,并对方程参数和误差结构设置约束条件[14],从而保证模型结果之间的可加性。
大兴安岭是我国寒温带森林的主要分布区,林区面积广阔、资源丰富、碳储量巨大,不仅在全国碳平衡和气候调控上发挥着重要的生态作用[23-24],而且还是我国重要的木材生产基地,具有很高的生态价值和经济价值。蒙古栎(QuercusMongolica),又称柞树,是国家二级保护珍贵树种,也是大兴安岭地区的主要建群树种和优势树种[25],具有抗干旱、耐瘠薄、适应性强的特性,在生态环境建设、生物多样性保护和森林可持续发展方面具有重要作用[25]。在未来气候变化下,蒙古栎的地理分布范围可能会更广[26],因此,研究其生物量的变化规律对未来气候下生态系统碳计量和碳循环具有重要意义。目前,有关蒙古栎生物量模型的研究相对较少,主要针对黑龙江大兴安岭地区[5,23],而缺少内蒙古大兴安岭地区的数据支撑。本研究通过收获法采集天然蒙古栎地上和根系的生物量,旨在探讨其生物量的分配格局及变化规律,并基于胸径、树高和冠幅变量,采用似乎不相关模型构建可加性生物量模型,为大兴安岭林区蒙古栎生物量及碳储量估算提供有效手段。
1 材料与方法
1.1 研究区概况
大兴安岭是我国最大的原始林区,属于寒温带大陆性季风气候,全年气温较低,四季温差大,年平均温度低于0℃,极端低温和高温分别为-52℃和40℃。年降雨量为350~500 mm,且主要集中在5—10月,土壤类型以棕色针叶林土为主。林区内主要树种有兴安落叶松(Larixgmelinii)、樟子松(Pinussylvestrisvar.mongolica)、蒙古栎(Quercusmongolica)、白桦(Betulaplatyphylla)、山杨(Populusdavidiana)等。灌木层主要有杜鹃(Rhododendronsimsii)、杜香(Ledumpalustre)和越橘(Vacciniumvitis-idaea)等。
1.2 样木生物量测定
根据蒙古栎的分布特点和立地条件等,按径阶选取样木并采用破坏性采样法测定生物量,胸径10 cm以下的树木取样径阶设置为1 cm,而10 cm以上的树木设置为2 cm,共选择78株蒙古栎,全部测定胸径和冠幅,伐倒后测定树干长度(树高),树高随胸径的变化趋势及各径阶样木分布情况见图1。由于根系生物量取样、测定费时耗力,尤其对细根的准确计量难度更大,因此,在采集地上生物量数据的78株样木中,按径阶分布共选择了31株样木用于根系生物量的测定。

图1 树高-胸径散点与各径阶样木分布频度Fig.1 Distribution frequency of tree height-DBH scatter and sample wood of various sizes
单木生物量测定分为地上和地下两部分,地上生物量又分为干材、树皮、树枝和树叶4部分。将伐倒木的树干均匀分为10个区分段,测定各区分段处的带皮直径和去皮直径,然后称得所有区分段的鲜质量,在全树高的0.1、0.3、0.7处的上下位置,各取2个3~5 cm厚的圆盘,称其鲜质量后,将树皮剥离再次称量,用于树皮生物量计算。树冠生物量分层测定,将树冠分为3层,每层选择生长良好、长度和叶量适中的3个标准枝,分别称枝、叶的鲜质量,然后在各层标准枝分别对枝条和叶片取样,并称其鲜质量。根系生物量采用全挖法测定,并对不同位置根系取样,称其鲜质量。所有样品带回实验室后,放入105℃的干燥箱中干燥至质量恒定,测量样品干质量,计算含水率。鲜质量乘以含水率得到各个组分的生物量,各组分生物量相加得到树木总生物量(表1)。
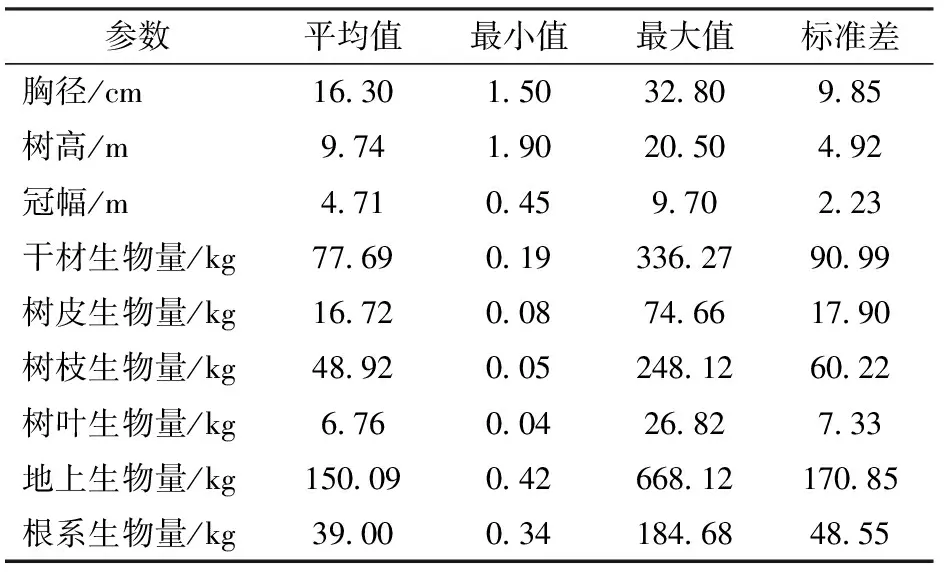
表1 建模样木基本统计量Tab.1 Descriptive statistics of sampled trees for biomass equations development
1.3 数据处理与分析
通过计算干材、树皮、树枝和树叶占地上生物量的比例,分析地上生物量在树木不同组分的分配模式及随胸径的变化趋势。基于测定根系生物量的样木,计算根茎比(即根系生物量与地上总生物量之比)并分析其随胸径的变化规律。
胸径和树高是野外调查中的易测变量,也是树木生物量模型构建的重要因子。采用胸径以及胸径、树高的组合为自变量,并在此基础上加入冠幅因子,观察模型的拟合效果。
lnWi=lnαi+βilnd+εi
(1)
lnWi=lnαi+βiln(d2h)+εi
(2)
lnWi=lnαi+βilnd+γilncw+εi
(3)
lnWi=lnαi+βiln(d2h)+γilncw+εi
(4)
式中Wi——各组分生物量,kg
αi、βi、γi——模型系数
εi——模型误差d——胸径,cm
h——树高,mcw——冠幅,m
由于根系生物量较少,不能与地上部分建立模型系统,故根系生物量模型利用模型(1)~(4)单独拟合。地上各组分生物量模型则分别以式(1)~(4)为基础,采用似乎不相关模型构建模型系统对干材、树皮、树枝、树叶、树冠和地上生物总量同时拟合。似乎不相关模型在参数约束的基础上,综合考虑了总量和分量模型之间的误差结构关联性,对总量和分量的生物量模型同时构建,使分量模型没有独立于总量而构建,确保模型具有可加性[14, 17-18]。模型(1)~(4)的可加性结构形式类似,因此以自变量最多的模型(4)为例,构建可加性模型系统,具体形式为
(5)
式中Wwd——干材生物量,kg
Wbk——树皮生物量,kg
Wbr——树枝生物量,kg
Wlf——树叶生物量,kg
Wcw——树冠生物量,kg
Wag——地上生物量,kg
α、β、γ——模型系数
ε——模型误差
所有模型均在R 3.6.1软件中使用“systemfit”包进行拟合。
1.4 模型评价
生物量模型是否可靠、能否用来合理准确地估算生物量,需要经过检验。本文基于全部数据建模,采用留一交叉法(刀切法)对模型进行验证,即每次留一个样本进行检验,其他样本用于模型建立。该方法广泛用于模型检验,在相关研究中取得了较好的效果[27-28]。
2 结果与分析
2.1 地上生物量分配模式及根茎比
蒙古栎各部分生物量占地上生物量的比例差异较大,其中树干对地上生物量贡献最高,干材和树皮占地上生物量的比例分别为51%和14%;与树干相比,树冠部分生物量相对较少,约占地上生物量的35%,其中树枝为28%,树叶仅为7%(图2,图中的点表示平均值)。干材占地上生物量的比例较为稳定,随胸径的变化波动性较弱,树枝生物量比例随胸径的增加而逐渐增加,表现为正相关关系,而树皮和树叶生物量比例呈相反趋势(图3,图中黑色线条为loess平滑曲线,阴影为95%置信区间,下同)。

图3 各组分生物量占比随胸径的变化趋势Fig.3 Fraction of aboveground biomass allocated in wood, bark, branch and leaf varied with diameter
根茎比是树木根系生物量与地上生物量的比值。基于开展根系生物量采样的31株样木可知,根茎比的变动范围为0.11~0.81,主要集中于0.2~0.5之间,均值和标准差分别为0.36和0.17。树木较小时,根系生物量所占比例较高,根茎较大时,随着胸径的增加,根茎比逐渐减小(图4)。
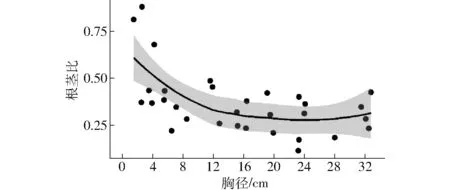
图4 根茎比随胸径的变化趋势Fig.4 Root/shoot ratio varied with diameter
2.2 各组分最优模型结构确定

确定地上各组分最优模型(自变量)后,基于似乎不相关模型,构建新的可加性生物量模型系统,并重新进行拟合,得到各组分最优可加性生物量模型(表3)。树皮、树枝和树叶模型拟合优度与原来相比略有提升,干材则略有下降。各组分最优生物量模型的残差随预测值的增加基本呈均匀分布,不存在异方差问题(图5)。

表2 各组分模型系数及拟合优度Tab.2 Coefficients with standard error and goodness-of-fit statistics of four models for wood, bark, branch, leaf and root
注:地上部分生物量采用可加性模型拟合,根系模型单独拟合,模型系数括号中数据表示标准误差,***表示显著性水平(p<0.001),ns表示不显著。

表3 地上最优可加性生物量模型及根系最优模型Tab.3 Optimum additive biomass models for aboveground parts and selected models for root

图5 各组分生物量模型残差Fig.5 Residuals of wood, bark, branch, leaf, aboveground and root biomass models
2.3 留一交叉法模型验证
采用留一交叉法对根系生物量模型和地上部分最优可加性生物量模型的验证结果如图6(图中灰色虚线为1∶1线,黑色线条为线性回归结果)所示。
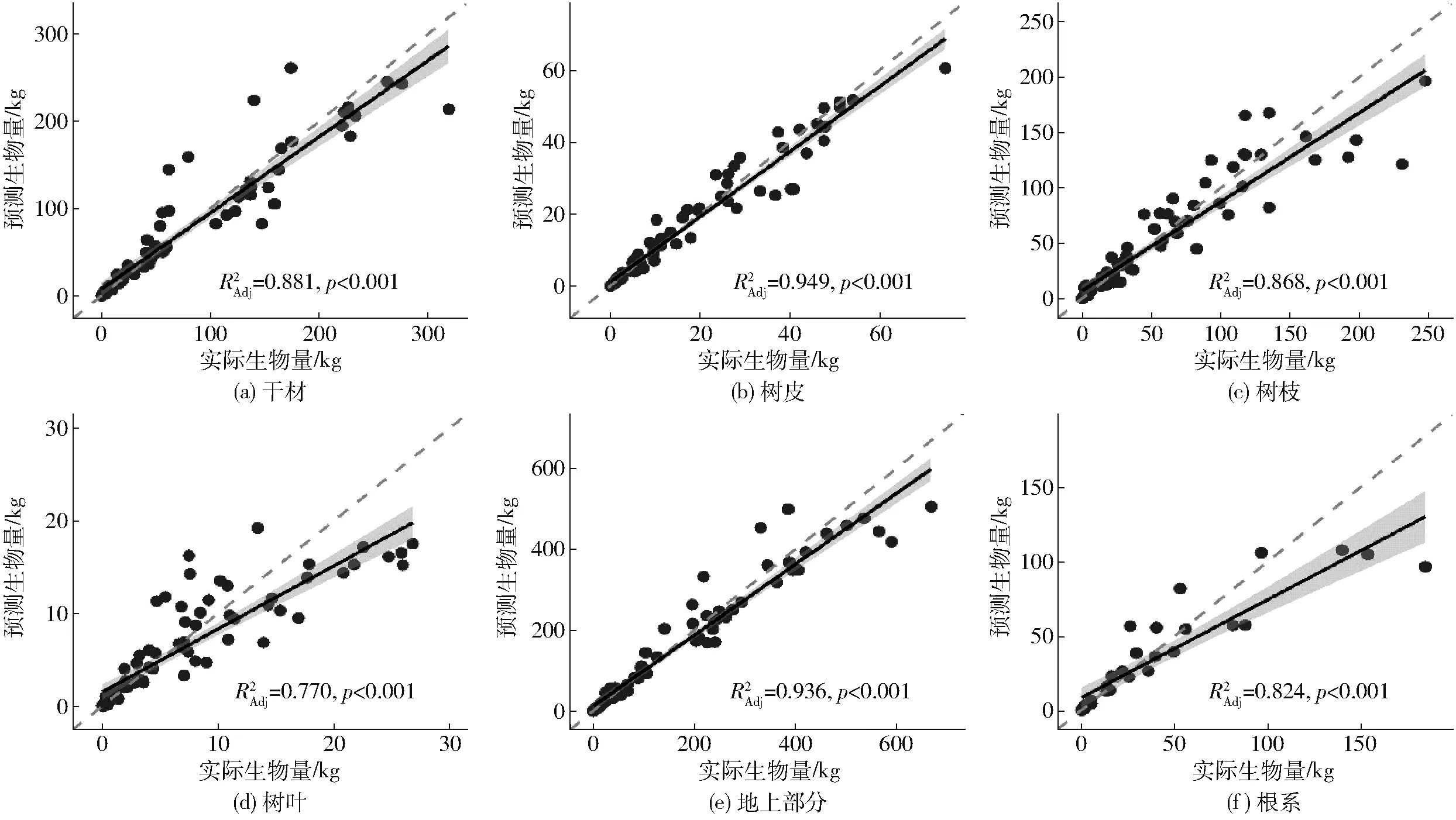
图6 各组分生物量预测值与实际值散点图Fig.6 Scatterplots of predicted and observed values for wood, bark, branch, leaf, aboveground and root biomass using leave-one-out cross-validation method
图中预测值为模型估计值反对数转换的结果。线性回归表明,各组分模型的预测值与实际值都具有良好的一致性,干材、树皮和地上生物量模型的预测效果相对较好(斜率更接近于1∶1线),而树枝、树叶、根系生物量模型的预测误差相对较大。生物量较小时,各组分模型的预测结果均表现为高估,当生物量较高时,模型的预测值常小于实际值。
3 讨论
生物量模型在森林资源清查和碳储量估计中具有不可替代的作用,尤其是作为一种高效率、低成本的无损估计方法,使森林碳汇计量变得更加快捷、简单[29]。本研究基于似乎不相关模型构建了大兴安岭地区蒙古栎的可加性生物量模型,为该地区森林生物量和碳库的准确核算提供了有效手段。
3.1 生物量分配格局及根茎比
生物量的增加是树木对能量的积累过程,其在各组分的分配模式受植物个体和外部环境的共同影响[30],树龄不同,各组分生物量占总生物量的比例也不相同。而胸径基本可以反映树龄的高低[31],本研究中生物量分配模式随胸径的变化规律基本反映了树龄对生物量分配的影响。随着树木的逐渐成长,木质生物量的积累常常以消耗树叶的生物量为代价[32-33],因此,树干和树枝生物量占地上总生物量的比例最高,树叶所占比例较小。树叶生物量比例随胸径的增加而降低,原因可能是树叶更多的着生在幼年生枝条而不是老年生枝条上,意味着单位干质量枝条上的叶生物量随着树木的成长而减少[12]。此外,由于林分中林木对光的竞争,与生长在开阔地带的树木相比,地上生物量会更多地分配到树干部分用于树高生长[34]。
全球树木根茎比的平均值为0.26,变化趋势在0.2~0.3之间,且根茎比的变化趋势与土壤质地和树种无关[35]。我国针叶树和阔叶树根茎比的平均值分别为0.25和0.29,阔叶树略高于针叶树[36]。本研究得到蒙古栎根茎比为0.36,相比全球和我国平均水平都较高。
3.2 异速生长模型

可加性是树木生物量估测模型中的一个重要特征,它可以消除分量预测值之和与总量预测值之间的不一致性[16]。但由于目前大多的生物量模型都采用最小二乘回归估计,使模型之间不具有可加性[43-45]。似乎不相关模型构建的总量和分量模型系统,考虑到各模型误差的协同相关性,修正了每个模型估计之间的固有误差问题,在这种情况下,总量方程式是所有分量方程式的累加,即总量方程式的自变量为所有分量方程式的自变量,从而对回归系数的估计设定了限制条件[15,46],有效降低了回归系数的方差。模型系统求解的过程中,同时获得了所有回归系数,达到减少总量和分量之间不确定性的目的,保证各组分生物量模型估计值之和等于总量模型估计值,提高生物量的预测精度。
基于生物量对数值建立的线性模型,在实际应用时需要将预测值进行反对数转换,但在转换的过程中会产生系统偏差[43,47]。为了尽可能地减小偏差,通常使用基于估计值标准误差计算的校正系数(CF)对模型预测值进行校正。然而,也有研究认为使用校正系数后会使生物量的预测值偏高,而且在反对数转换过程中产生的偏差与生物量估计过程中产生的总体误差相比通常较小,实际使用中可忽略不计[48]。本研究中,各组分生物量模型的校正系数均相对较小(CF小于1.1),尤其对于干材、树皮和地上部分(CF小于1.05),因此,模型估计值在反对数转换时产生的误差较小,在实际使用中可忽略不计。此外,若使用转换系数,会导致各组分之间生物量模型的可加性遭到破坏。
由于生物量与易测变量之间的关系随树木大小、年龄和林型等的变化而不同,本研究得到的模型更加适用于大兴安岭林区蒙古栎生物量的估计,对此区域之外或者其他树种估计时,会产生较大的误差[9]。本研究生物量模型建模数据的胸径范围为1.5~32.8 cm,超出该胸径范围的生物量估计都存在很大的不确定性,因此,应依据特定区域、特定树种和特定估测范围选择模型进行生物量估计。
4 结束语
蒙古栎地上生物量主要分配在树干,尤其是干材部分,分配到叶片的生物量最少。根系以胸径为自变量的根系生物量模型拟合效果最佳,基于胸径和树高组合变量的干材和树皮生物量模型预测能力最强,而在胸径基础上添加冠幅变量的树枝和树叶生物量模型拟合效果更优。采用似乎不相关模型不仅有助于实现生物量模型的可加性,还可以降低误差,并提高模型的预测能力。由于对数转换校正系数通常较小,在实际使用中可以忽略。本研究得到的最优可加性生物量模型可有效估计大兴安岭林区蒙古栎生物量,但需要特别注意模型的胸径适用范围。
