基于Spark 的海量数据冗余检测方法
2020-06-28宾冬梅杨春燕
余 通 宾冬梅 黎 新 杨春燕 凌 颖
(广西电网有限责任公司电力科学研究院,广西 南宁530023)
冗余是指一个实体由多个不完全相同的记录表示的现象,它是影响数据质量的主要因素[1]。在应用系统的信息采集中,数据信息的冗余检测是数据质量优劣保证的关键,是有效实现数据清洗的保障。随着信息化的发展的不断深入,数据呈指数级膨胀,年数据量的增长从GB 级增长到了TB 级。这快速增长的数据体量使数据维度也在不断扩大,并且其中大部分数据都是冗余的。这使传统方法上的冗余检测难度大大增加,因此,海量数据的冗余检测已成为当下广泛研究的热点[2-3]。
长期以来,冗余检测的研究取得了大量的成效,这些研究在处理小数据集时表现出良好的性能,但单机环境下的计算资源无法满足海量数据集的处理要求。为此,本文提出了数据冗余检测算法ROFA,并基于Spark 和ROFA 设计了海量数据的冗余检测策略,实现了海量数据的冗余检测,解决了海量数据产生的瓶颈。
1 基于指纹检索树的数据冗余检测算法
本文引用文献[3]中Simhash 算法完成数据元组与对应的二进制串(指纹)的转换。而为实现冗余数据的有效检测,本文设计了指纹检索树(F-Indextree),并提出了基于F-Indextree 的指纹冗余检测算法ROFA。
1.1 F-Indextree 的构建
定义指纹Si的标识符flag 为(di,IDi),其中IDi为Si的行标,di为Si对应的十进制数。指纹检索树F-Indextree 的构建Step 描述如下:
(1)初始化根节点为空集;
(2)计算记录IDi的f 维指纹Si,并将Si均分为ω=f/r 段,用βk表示各段,βk为r bit 的二进制串,即Si表示为β1…βω;
(3)以βk为节点构建F-Indextree,若βk=βξ,则视为同个节点,kξ∈[1,ω]。当βk为叶节点,则在其中插入Si的标识flagi=(di,IDi),F-Indextree 中各个不同的路径,分别表示不同的指纹;
(4)循环(2)至(3)Step,直到Si为空。
1.2 基于F-Indextree 的指纹冗余检测算法
从F-Indextree 结构可见,若需检测指纹Si的相似性,则需遍历指纹树F-Indextree 至各个叶节点。为解决高时间复杂度,引入Hamming distance 并利用广度优先算法和结合抽屉原理,设计了基于F-Indextree 的指纹检索算法。假设要在S=(fi)T中检测出与Si冗余的部分,设定阈值为μ,即Hamming distance<u的指纹是冗余的。则算法描述如下:
(1)F-Indextree(S),用创建指纹检索树T;
(2)将指纹Si按T 中指纹的方式分段,即将Si均分为ω=f/r段,Si=(α1…αω)。
(3)以广度优先检索算法规则,求αi与βk的海明距离hi;
(4)引用抽屉原理规则判断指纹的冗余性,若与Hammin distance(αi)=0 的ω-μ 个βk是冗余的,则包含这ωμ 个βk的所有Sk都是冗余的。
(5)输出Sk的叶节点的flagk,u={flagk}。
(6)输出u,即为所检索的冗余指纹。通过冗余指纹即可提取冗余的数据。
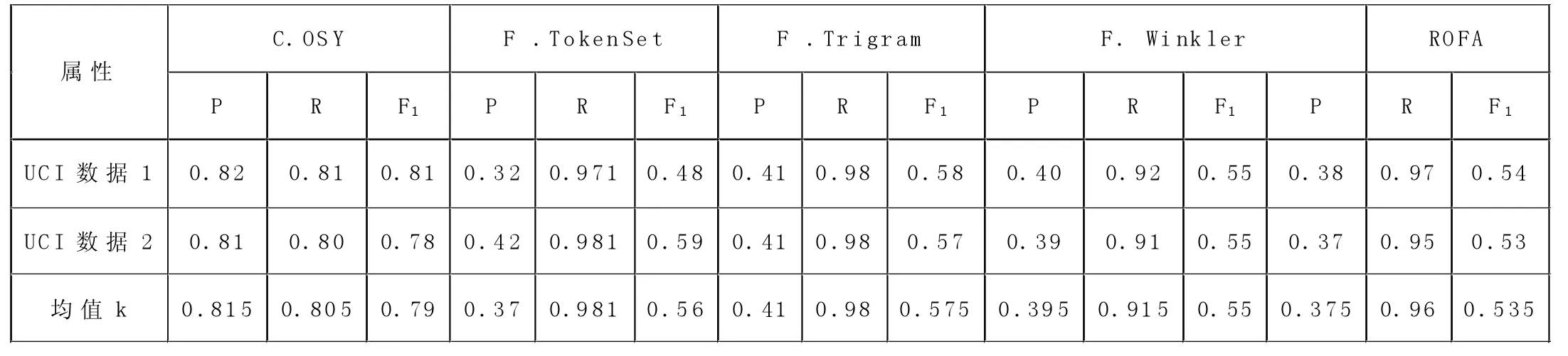
表1 算法的精确性比较
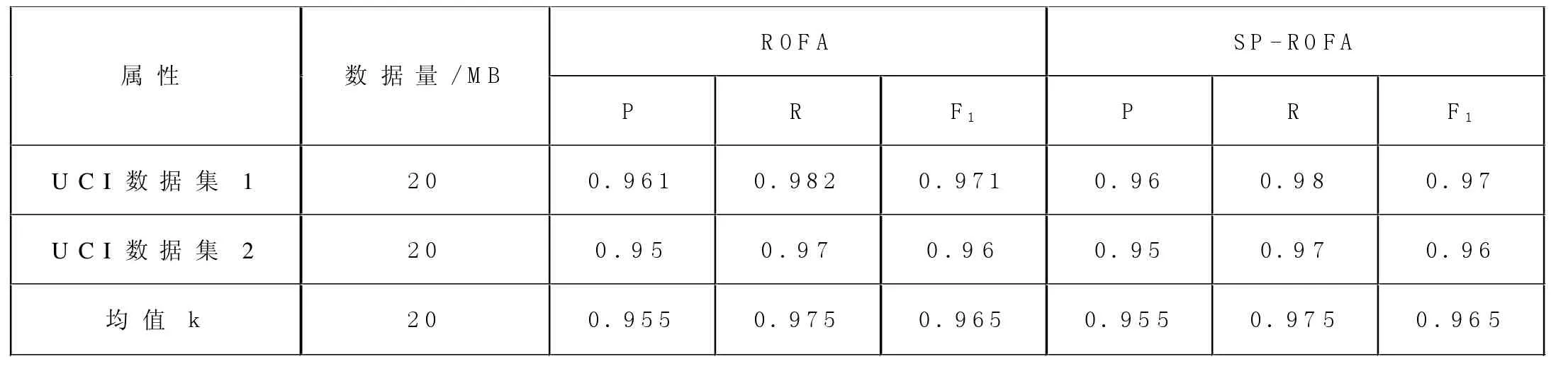
表2 SP-ROFA 算法检测精度
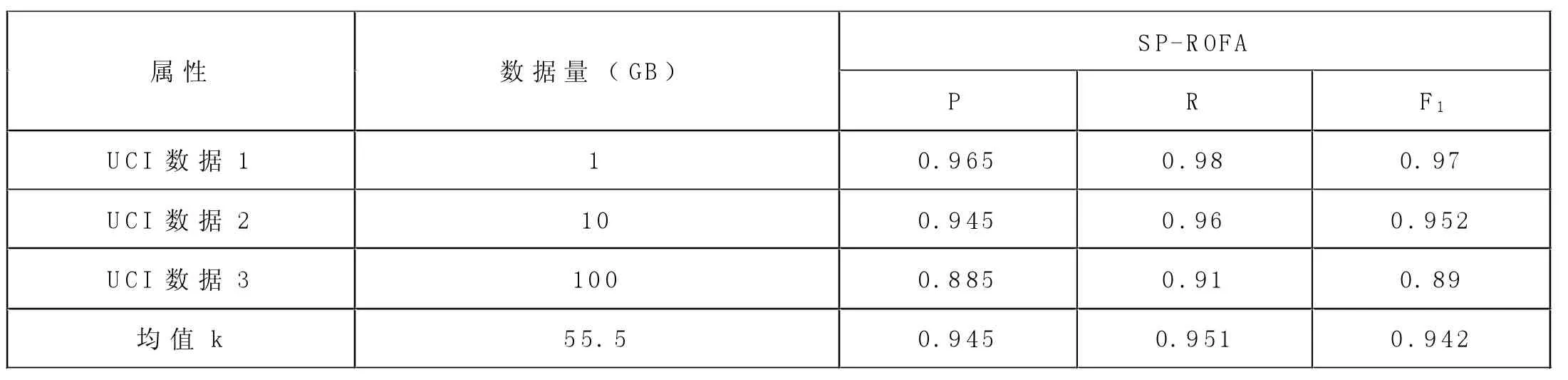
表3 SP-ROFA 算法检测结果
2 基于Spark 和ROFA 的海量数据冗余检测策略
基于Spark 的性质,结合ROFA 算法,本文设计了海量数据冗余检测算法。
基于Spark 和ROFA 的算法(Sp-ROFA)实现:
对关系表Ek,K∈R 行号记为ID,关系表的第i 行j 列的属性值记为Ai,j且Ai,j∈Ai;检测Ek中的冗余,算法描述如下:
输入:数据关系表Ek
输出:冗余记录
Step1:通过SparkContext.textFile()和RDD.Cache();
Step2:通过SimHash 方法生成指纹RDD;并按<key=IDi,value=si>的格式存储;
Step3:Executor.Map(),Update(<key=IDi,value=si>);
Step4:Executor.Reduce(<key=IDi,value=Si>);
Step5:引入指纹检索树算法生成指纹检索树RDD;
Step3:执行Executor 进程,调用基于指纹检索树的指纹检索算法,生成冗余RDD;
Step4:Action.saveAsTextFile(),输出冗余指纹。
3 实例分析
为评估算法的有效性,本文在6 台曙光I620-G10 服务器上搭建Spark 集群实验环境,实验数据来自UCI 的数据是家庭用电信息。此外,定义海明距离小于或等于3 的两个指纹是相似的,指纹长度为64 位。标准hash 算法采用MD5。实验从检测精度、召回率和算法对参数的敏感性三个维度进行分析。
3.1 检测精度和召回率分析
检验ROFA 的有效性及其精确性,将其检测结果与表1 中的算法对比。采用召回率(R)、准确率(P)和F1-score(F1)作为评价标准;实验数据为4MB 且为单机环境,实验结果如表1 所示。
同样地,在6 台服务器上搭建Spark 集群环境检验SP-ROFA 的精确性和召回率并与单机环境下的ROFA 的精确度和召回率对比。实验结果见表2 所示。
由表2 见,因SP-ROFA 仅仅是ROFA 在Spark 平台上的并行化实现,因此,相同环境下,ROFA 的检测精度、召回率和SP-ROFA 的在相当的水平上,平均检测精度均约为96%,召回率均约为98%,F1均约为98%。此外,由于初始数据格式存在差异等因素,算法检测效果表现相当,存在1.05%的浮动差异,但是仍具有良好的检测效果和适用性。
由表1 和表2 中算法的平均P、R、F1的对比可知:SP-ROFA 和ROFA 的检测精度、召回率和平衡性平均提高了约59.21%、2.1%和44.2%;并且在所有对比算法中,SP-ROFA 和ROFA 的召回率略低于其中的两个算法,但它们的平均P 和F1最高,即本文算法的性能最优,具有更强的适用性。
3.2 算法对参数的敏感性分析
检测数据规模对检测精度、召回率的影响,采用1.0GB、10.0GB、100.0GB 的数据来对SP-ROFA 的P、R 和F1进行评估,见表3 所示。
由上表可见,当数据以递增到100GB 时,SP-ROFA 的P、R和F1均在8%内浮动,其平均P 为93%、平均R 为95%、平均F1为94%,算法具有良好的稳定性和检测效果。而随着数据规模的快速增加,SP-ROFA 的P、R 和F1有所下降,但受数据快速增长的影响比较小,稳定性高,适用于快速增长的海量数据冗余的检测。
4 结论
针对传统方法难以有效完成海量数据的冗余检测问题,设计了ROFA 算法,并提出了基于Spark 和ROFA 的海量数据冗余检测策略SP-ROFA。实验结果表明,本文的算法有效、稳定,并表现出良好的伸缩性和加速比,适用于海量数据的冗余检测。接下来的任务是算法寻优,使其更好应用于海量数据的处理中。
