基于CHAID模型的现代人肥胖状况及其成因分析
2020-06-23李银刘丽芬卢利敏
李银,刘丽芬,卢利敏
(韶关学院 1. 教育学部,2. 数学与统计学院,广东 韶关 512005)
近年来,肥胖危机在我国迅速蔓延,已逐渐成为全球性的健康问题.肥胖人群是一类特殊的群体,肥胖是人体体内脂肪积聚过多导致的现象,不仅影响形体美,更重要的是肥胖人群比正常体质量人群更容易患病,如高血压和糖尿病等[1-6].本文针对韶关市浈江区现代人的肥胖现状,运用决策树方法对韶关市浈江区人员的肥胖现状及其成因进行分析,并利用多元Logistic回归模型和主成分分析法对决策树CHAID模型得出的结果进行检验,为相关决策者制定干预方案提供参考.
1 调查指标选取
世界卫生组织(WHO)一般用身体质量指数(BMI)来对肥胖或超重进行定义,用体质量(kg)数除以身高(m)平方得出的数字,是目前国际上常用的衡量人体胖瘦程度的一个标准.适合中国成年人的肥胖标准为:身体质量指数小于18.5为轻体重,大于等于18.5小于24为健康体重,大于等于24为超重,大于等于28为肥胖.身体质量指数按 B MI ≤ 18.5,18.5 ≤ BMI< 24,24 ≤ BMI< 28, B MI ≥ 28这4个等级水平依次赋值为1,2,3,4.本文在已有研究[7-10]的基础上,得到调查问卷指标(见表1).

表1 调查问卷指标
2 数据的获取与处理
通过问卷星进行网上发放问卷和现场发放现场回收的方式,收集韶关市浈江区居民肥胖状况的相关数据,回收有效问卷196份.问卷采用国际通用的Likert五等级评分法,从“没有”到“总是”按程度不同分为5个选项,依次赋1~5分.正向条目评分与原始分相同,反向条目评分等于6减原始评分.性别与职业因素、年龄因素、代谢因素、睡眠因素、遗传因素、心理因素、运动因素和饮食习惯8个一级指标的得分之和为总分,得分越高对应的肥胖状况应该越严重.
将原始得分换算为转换分数,计算公式为

性别与职业因素理论最高得分为12,理论最低得分为3,因此性别与职业因素的转化分数为

3 肥胖现状及其成因分析的决策树CHAID模型[1]
决策树CHAID模型是利用卡方自动交互检测法快速、有效地挖掘出主要的影响因素,它不仅可以处理非线性和高度相关的数据,而且可以将缺失值考虑在内,能克服传统的参数检验方法在这些方面的限制.本文运用决策树方法,建立CHAID模型.
利用性别与职业因素、年龄因素、代谢因素、睡眠因素、遗传因素、心理因素、运动因素和饮食习惯共8个变量共同建立一个决策树CHAID模型来预测肥胖状态的影响因素.
根据建立的决策树CHAID模型,运用SPSS软件对模型进行求解,具体部分操作:选择菜单分析——分类——决策树,打开对话框,将相关变量选入到变量栏中,再进行相关操作,得到最终的自变量为性别与职业因素得分、运动得分和代谢得分.
决策树模型见图1.决策树共分为2层,第1层判断依据是性别与职业因素,第2层判断依据是运动因素和代谢因素.
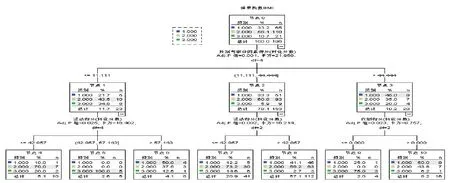
图1 决策树模型
进行模型风险评估,结果见表2.

表2 风险评估
由表2可以看出,风险评估值为0.388,表示该模型预测判别个案错误率为0.388,模型拟合效果较好.
决策树CHAID模型的分类判别效果见表3(其中:1为轻体重,2为健康体重,3为肥胖/超重).
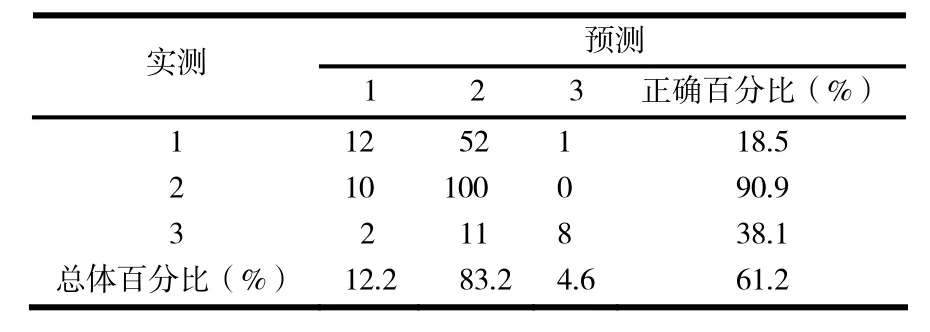
表3 分类预测效果
由表3可以看出,决策树CHAID模型对大概61.2%的个体进行了正确的判别.由此看来,该模型是比较合理的.
综合分析可知,影响肥胖状况的首要因素是性别与职业,另外运动和代谢也是需要考虑的因素.
4 模型的检验
为了避免只采用决策树CHAID模型方法得出的结论不具备较强的说服力,采用多元Logistic回归模型和主成分分析法对决策树CHAID模型进行检验.
4.1 多元Logistic回归模型[1]
设身体质量指数 BMI的等级为y,性别与职业因素为x1,年龄因素为x2,运动因素为x3,遗传因素为x4,心理因素为x5,睡眠因素为x6,代谢因素为x7,饮食习惯为x8.
建立现代人肥胖状况影响因素的实证模型

其中:μ为随机扰动项,反映无法观察到的其它因素.
由于被解释变量身体质量指数的选项有多个且有序,故采取多元Logistic回归模型
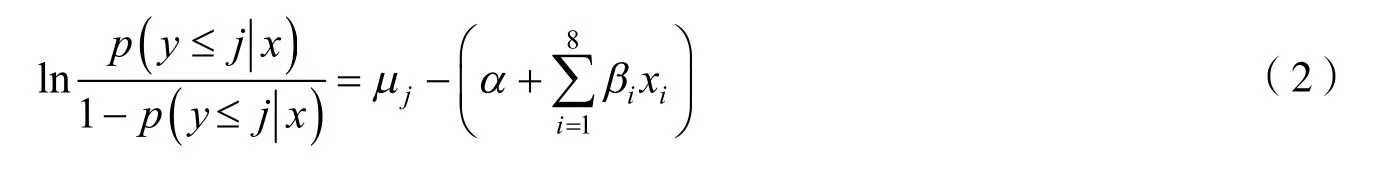
其中:j为现代人肥胖程度的4个等级,j=1,2,3,4;μj为分界点;α为截距项;βi为偏回归系数;为分类j及其以下类别的累积概率,即

采用SPSS进行多元Logistic回归估计,得到初始模型,再根据似然比检验结果将不显著的变量逐个剔除,直到模型中的变量全部都为较显著的变量.
对多元Logistic回归模型进行显著性检验,结果见表4.

表4 模型拟合信息
由表4可以看出,显著性水平的值明显小于0.05,所以多元Logistic回归模型是显著的.
检验模型的伪2R,3种伪决定系数考克斯-斯奈尔系数、内戈尔科系数和麦克法登系数分别为0.481,0.570,0.353.
对多元Logistic回归模型进行似然比检验,结果见表5.

表5 含8个自变量多元Logistic回归模型的似然比检验
就显著性水平来看,显著性水平大于0.05的因素对肥胖状态并没有显著的影响,因此可以剔除显著性水平大于0.05的因素.根据表5,首先剔除最不显著的饮食因素,再次建立回归模型,以此类推,直至不存在不显著变量,依次分别剔除了饮食因素、年龄因素、代谢因素和遗传因素.
在依次剔除饮食因素、年龄因素、代谢因素和遗传因素后,对只包含自变量性别与职业因素、运动因素、睡眠因素和心理因素的多元Logistic回归模型进行似然比检验,结果见表6.

表6 含4个自变量多元Logistic回归模型的似然比检验
由表6可以看出,所有变量的显著性水平都小于0.05,因此有理由认为此时所有的变量对肥胖状态都有显著的影响.
综合该模型分析可以认为,肥胖状态的主要影响因素是性别与职业因素、运动因素、睡眠因素和心理因素.
4.2 主成分模型
主成分分析是采用一种数学降维的方法,设法将原来众多具有一定相关性的变量,重新组合成一组新的相互无关的综合变量代替原来的变量.利用降维的思想,把多指标转化为少数几个综合指标(即主成分),其中每个主成分都能够反映原始变量的大部分信息,且所含信息互不重复.主成分分析所需样本数据较多,比较适合本文的研究.
主成分分析(PCA)方法的基本步骤为:
Step1对原始数据进行标准化处理,得到样本观测数据矩阵
Step2计算样本相关系数矩阵
Step3计算相关系数矩阵R的特征值λ1,λ2,λ3,λ4,λ5,λ6,λ7,λ8和相应的特征向量.
Step4选择重要的主成分,并写出主成分的表达式.主成分个数的选取主要根据主成分的累计贡献率来决定,一般要求累计贡献率达到85%以上,这样才能保证综合变量能包括原始变量的绝大多数信息.
根据建立的主成分分析模型,运用Matlab软件对模型进行求解.
运用Matlab软件计算相关系数矩阵及相关系数阵的特征值,计算结果为

前7个特征值之和所占比例(累计贡献率)达到92.88%,因此去掉第8个主成分.7个保留的特征值对应的7个特征向量分别为

因此取前7个主成分,分别为

对数据直接作线性回归,得到经验回归方程

作主成分回归分析,得到回归方程
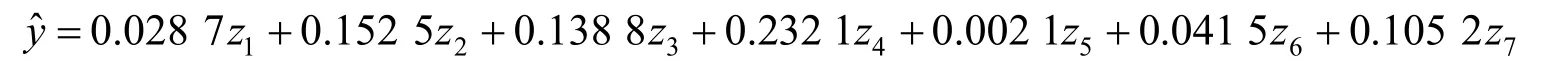
化为标准化变量的回归方程为

综合分析可以认为,影响肥胖状况的首要因素是性别与职业因素,其次是运动因素和饮食因素.
通过主成分模型提示人们,如果平时压力较大,不经常运动且饮食习惯较为不正常者,则肥胖的可能性较大.通过该模型,让健康人群(非患病等特殊人群)中任一人填写该问卷,可以预测该人的肥胖状况,且准确率较高.
综合分析结果,建议肥胖人群应该做到:(1)适当地增加运动.人体能量的消耗主要是通过基础代谢、肌肉运动和食物的生热效应进行的.正常情况下,人的基础代谢较为稳定,肌肉运动是人体能量额外消耗的主要方式,通过运动可以达到减肥的效果.(2)多吃蔬菜水果和五谷杂粮,保持饮食均衡,这样有利于促进新陈代谢.(3)保持愉快的心情,调整好心态,不要焦虑,适当地释放压力.
5 结束语
对于某一健康人群,通过该人的某些数据,利用本文模型可以预测该人的肥胖状况并且准确率较高.且模型对于研究高校大学生亚健康状况,现代人亚健康状况及其成因分析,现代人肥胖状况及其成因分析等都具有一定的借鉴作用和参考价值.
