基于改进Apriori算法的仓库货物关联度分析
2020-06-23刘小倩
赵 峰,刘小倩
(安徽工业大学 管理科学与工程学院,安徽 马鞍山 243032)
随着经济的持续稳定发展,现代物流业也日益呈现出高速发展的状态.然而物流行业在快速发展中也存在着许多问题亟待解决,体现尤为明显的就是物流仓储业.2018年我国社会物流总额增速有所放缓,约降低0.2%,全年社会物流总额为283.1×104亿元.同年我国社会物流总费用增速提高,增长了9.8%,全年社会物流总费用为13.3×104亿元,运输费用比率有所降低,而仓储费用和管理费用的比率呈现上升状态,社会物流总费用与GDP的比率为14.8%.在费用构成方面,2018年保管费用即仓储费用金额为4.6×104亿元,增速同比提高7.1%,相较去年增长了13.8%.根据数据分析得出,我国物流仓储业的发展仍然还有待改进:1)由于经济的快速发展,消费市场呈现多样性的特点,传统仓库逐渐不能满足客户的需求,导致传统仓储企业盈利效益差;2)我国人口众多,人均仓储用地面积相对较小导致仓储用地成本增加,仓储行业面临着巨大的成本压力;3)我国物流技术的发展仍存在许多壁垒,物流标准和物流效率稀缺.在这些宏观环境影响下微观层面同样存在问题:1)Q卷烟配送中心仓库内部货物放置混乱,没有明确的仓库出入库制度,将货物随机储存至空缺货位,导致出库速度慢效率低;2)Q卷烟配送中心仓库内部无明确的区域划分,空缺的通道和区域随意摆放着货物、包装盒、托盘甚至出入库机械与杂物,导致仓库整体显得紊乱无序;3)Q卷烟配送中心仓库工作人员缺乏员工工作操作标准的培训,员工素质有待提高,导致工作效率低下.因此,本文根据上述问题,研究分析传统的Apriori算法并进行改进,比较传统Apriori算法与改进Apriori算法的效率,运用改进的Apriori算法分析仓库内货物品种的关联度,通过降低拣选货物的时间来缩短出库作业的时间,进一步提高响应客户的速度,从而增强拣货效率,提高仓库的经济效益.
货位优化是用来确定品种规格的恰当储存方式,在恰当储存方式下的空间储位分配.GyuLee和Sung[1]等人提出了一个系统化的整合方法并延伸了相关储存指派策略,以最小化行程时间与拣选延迟将其分为两个阶段来模拟,并采用多目标进化算法求解;Jason和Shih[2]等人提出了一种基于群体遗传算法的订单批处理方法使拣货系统的批数最小化,结果表明所提出的启发式策略优于现有的订单批处理策略;Y.Zhang[3]提出了一种相关存储分配策略的多种解决方案,运用一种包含预处理和两个分支过程的csas算法提出了求和种子聚类算法和静态种子聚类算法来寻找项目集;李永伟,刘树安[4]等人建立了以入库作业过程中工作人员行走总路程最小为目标的货位优化模型,将传统遗传算法同启发式算法相结合对模型进行求解;李鹏飞,马航[5]提出以出入库效率和货架稳定性为优化因素的货位优化模型,采取病毒协同遗传算法对优化模型进行优化;李珍萍,陈星艺等人[6]研究了基于自动引导机器人(AGV)的货到人拣选模式下智能仓库系统补货阶段的储位分配问题,以同一货架上的各种商品之间的关联度之和最大化为目标函数建立了补货阶段储位分配问题的整数规划模型;谷君[7]以YH公司成品仓库为研究对象,主要通过数学建模方法、遗传算法以及Flexsim仿真方法对该仓库的自动化立体仓储区进行货位优化.
Apriori算法应用层面十分广泛,也引发了众多学者对其进行研究.杜永兴,高迪[8]等人提出基于荒漠草原数据多样性关联规则改进的算法,并在此基础上增加判断数据集,减少候选项集的产生,减少大量的时间消耗,提高改进的Apriori算法的效率;赵峰,刘博妍[9]利用改进的Apriori算法对某高校计算机学院学生的成绩进行挖掘分析,发现不同学科之间的关联关系,给予学校管理指导方向;曾子贤,巩青歌[10]等人在现有Apriori算法改进优化思想的基础上,结合矩阵、改进频繁模式树和计算候选集频数优化策略提出了一种改进的关联规则挖掘算法—MIFP-Apriori算法;孙帅,刘子龙[11]针对Apriori算法存在的缺陷利用概率理论与有效的参数设置,在原有Apriori算法基础上,提出一种基于概率事务压缩的关联规则改进算法;郭鹏,蔡骋[12]针对某高校学生的学习状况和培养方案的改进需求,提出一种基于改进K-means和引入兴趣度Apriori算法的学生课程成绩分析方法;文武,郭有庆[13]针对Apriori算法存在效率低、内存损耗大等问题,提出一种基于遗传算法来寻找频繁项集的(GNA)算法,利用交叉算子产生候选项集和变异算子筛选频繁项集,避免多次扫描数据库的同时,减少冗余.虽然Apriori算法在数据挖掘领域的应用性很广泛,但是其缺陷仍然显而易见,在算法运行的过程中,需要多次往返地扫描事务数据库,直接导致产生大量冗余的候选集项目,严重影响了算法运行的效率.所以目前关于Apriori算法的研究已经集中到对其进行改进运用的阶段:本文在经典Apriori算法的基础上对其进行改进,增加判断候选集标的条件,减少扫描次数,提高算法效率.
1 Apriori算法简介
随着大数据时代的到来,信息量以爆炸的速度增长,为了更好地汲取有用的信息从而产生了大数据、云储存和云计算等技术,数据挖掘也应运而生.在数据挖掘中,关联规则的挖掘应用广泛,例如人们日常接触网购时的商品推送、搜索引擎进行数据搜索、公司进行营销分析等.在关联规则挖掘算法中,Apriori算法是最先被提出的,也是应用发展前景最为广泛的[14].Apriori算法通过关联规则来分析研究对象的关联程度,根据关联程度来分析货物的相关程度,再依据相关程度将相关程度高的对象进行邻近配置,从而缩短相关操作的时间,提高相关操作的效率.
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法,其中频繁项集为所有支持度大于或者等于最小支持度的项集,它对挖掘对象的频繁项集进行分析并得出事件关联程度,其关键思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集.该算法的关联规则属于单维、单层以及布尔关联规则.Apriori算法的基本操作流程是找出所有的频繁项目集,生成所有频繁集使用递归的方法,这些项集出现的频繁性即支持度必须大于或者等于预定义的最小支持度,然后由算法得出的频繁项目集产生强关联规则,这些规则必须满足设定的最小支持度和最小置信度,一旦这些规则被生成,只有大于人工设定的最小置信度的规则才会被保留,最后根据算法产生的关联规则分析事件相关性程度.
Apriori算法通过使用逐层搜索的迭代方法进而发现频繁项目集,每个x项目集是探索下一个项目集即(x+1)项集的依据,以此迭代直到求出符合最小支持度的最终频繁项目集.Apriori算法的第一步是通过自连接获取频繁项目集的候选集,第一轮的候选集就是原始数据集A中的项,而剩下每一次的候选集则是由前一次获得的频繁项目集自连接得到,而频繁项目集由候选集进行剪枝得到;第二步是对候选集进行剪枝,如果候选集的每一条记录S的支持度小于预设的最小支持度,那么此记录就会被自动剪掉,另外,如果一条记录的子集中包含不是频繁项目集的记录也会被剪掉;算法的终止条件是自连接得到的已经不再是频繁集,最后一次得到的频繁项目集则为最终结果.所以,Apriori算法的具体流程为扫描事务记录,找出所有存在的频繁项目集1,记该项目集为K1,然后依据K1找频繁项目集2的集合K2,K2找K3,以此类推,直到不能再找到任何频繁x项目集,最后再在所有的频繁项目集中找出强规则,得出关联程度高的研究对象,产生客户感兴趣的关联规则,用以指导实际的操作目的.算法操作步骤如下:
1)Begin
2)Scanning database and counting;
3)If 1阶候选项目集>Minimum support
4) 则产生1阶频繁项目集;
5)Else delete
6)依此规则,迭代计算;
7)If 不再产生频繁项目集
8) 则End;
9)Else 继续迭代计算.
2 Apriori算法的改进
由上述研究中阐述的流程可表明经典的Apriori算法存在较大缺陷即算法效率问题,因为在反复扫描数据库的过程中有许多不必比较的项目或者项目集重复比较[15].在依据x阶频繁项目集产生x+1阶候选频繁项目集时,会形成大量的冗余项集,所以在x+1阶候选频繁项目集中剪枝非频繁项目集的步骤需要进行改进;在连接过程中相同的项目集重复使用多次,此步骤也需要进行改进.
针对上述经典Apriori算法的缺陷提出相应的改进方法:若某个元素要成为k维项目集中的一元素,该元素在k-1阶频繁项目集中的数量必须达到k-1个,否则不可能生成k维项目集.因此,在迭代搜索过程中,根据k-1步形成的k-1维频繁项目集来产生k维候选项目集,并在形成k-1维频繁项目集时对该项目集中的元素个数进行计数处理,如若项目集元素的数量达不到k-1个则删除该元素,从而能去除由该元素形成的大规格的所有项目集组合.根据以上改进思路得到候选项目集后,可以对数据库A中的每一个项目进行扫描,若该项目中至少含有候选项目集Ck中的一元素则保留该项目,否则把该事物记录与数据库末端没有作删除的项目记录进行交换,并对移到数据库末端的项目记录作删除标记,整个数据库扫描结束后产生新的事务数据库D′.因此随着k的增大,D′中项目记录量极大地缩减,可直接节约输入输出开销.在实际情况中,由于客户一次一般可能只购买几件商品,因此这种方法可以剔除大量的交易记录,并且在剩余的项目中做更高维的数据挖掘是可以节约大量的时间.下面为改进的Apriori算法流程操作步骤:
1) Begin
2) Scanning database and counting;
3) If 1阶候选项目集> Minimum support
4) 则产生1阶频繁项目集;
5) Else delete
6) 连接1阶频繁项目集产生2阶候选项目集;
7) If 2阶候选项目集>Minimum support
8) 则产生2阶候选频繁项目集;
9) Else delete
10)Counting 2阶候选频繁项目集中元素出现的次数;
11) If 出现次数>=2;
12) 则保留为2阶频繁项目集;
13) Else delete 此元素;
14) 依次规则,迭代计算;
15) If 不再产生频繁项目集
16) 则End;
17) Else 继续迭代计算.
3 改进Apriori算法的应用
本文根据Q卷烟配送中心客户对仓库货物的订货情况,运用改进后的Apriori算法分析客户订货时的习惯订货行为与组合,帮助Q卷烟配送中心仓库部门提高出入库效率,增加仓库的收益.
3.1 算法运行
为了验证Apriori算法的有效性,将其运用在分析Q卷烟配送中心仓库货物品种的关联性上,从而进一步分析客户订货时的习惯订货行为,指导仓库在货物货位入库时能根据客户的订货习惯将货物品种关联度高的货物邻近摆放,提高拣货速度,缩短拣货时间,增强仓库工作效率,给Q卷烟配送中心带来良好的经济效益.表1为Q卷烟配送中心客户一周的订货品种及数量,由于篇幅限制只截取部分订货数据,通过分析客户一周订货表中的数据,运用改进的Apriori算法运算得出客户订货品种的关联性.
实际数据信息如下:3 779个客户,117类订货品种.而表1截取了部分客户订货数据为5个客户及23个品种的订货数量,空缺部分指客户对此类货物品种的订货数量为0.根据客户数据以及改进的Apriori算法,运用Matlab对改进的Apriori算法进行编程求解出货物品种的关联度.设置支持度和置信度均为0.9,最大规则数为1000,得出如下部分关联规则.
表2为关联规则的部分截取表格,由算法挖掘得出关联格则如表1可知,客户订t类货物的同时也会订z类货物、s类货物,订z类货物的同时也会订s类和t类货物;订ai类货物的同时也会订s类、t类和z类,剩下的规则以此类推.根据以上的关联规则将关联度高的货物放置在邻近的货位上,可以极大的缩短出入库时间,提高仓库工作效率.

表1 客户一周订货数据表(单位:条)
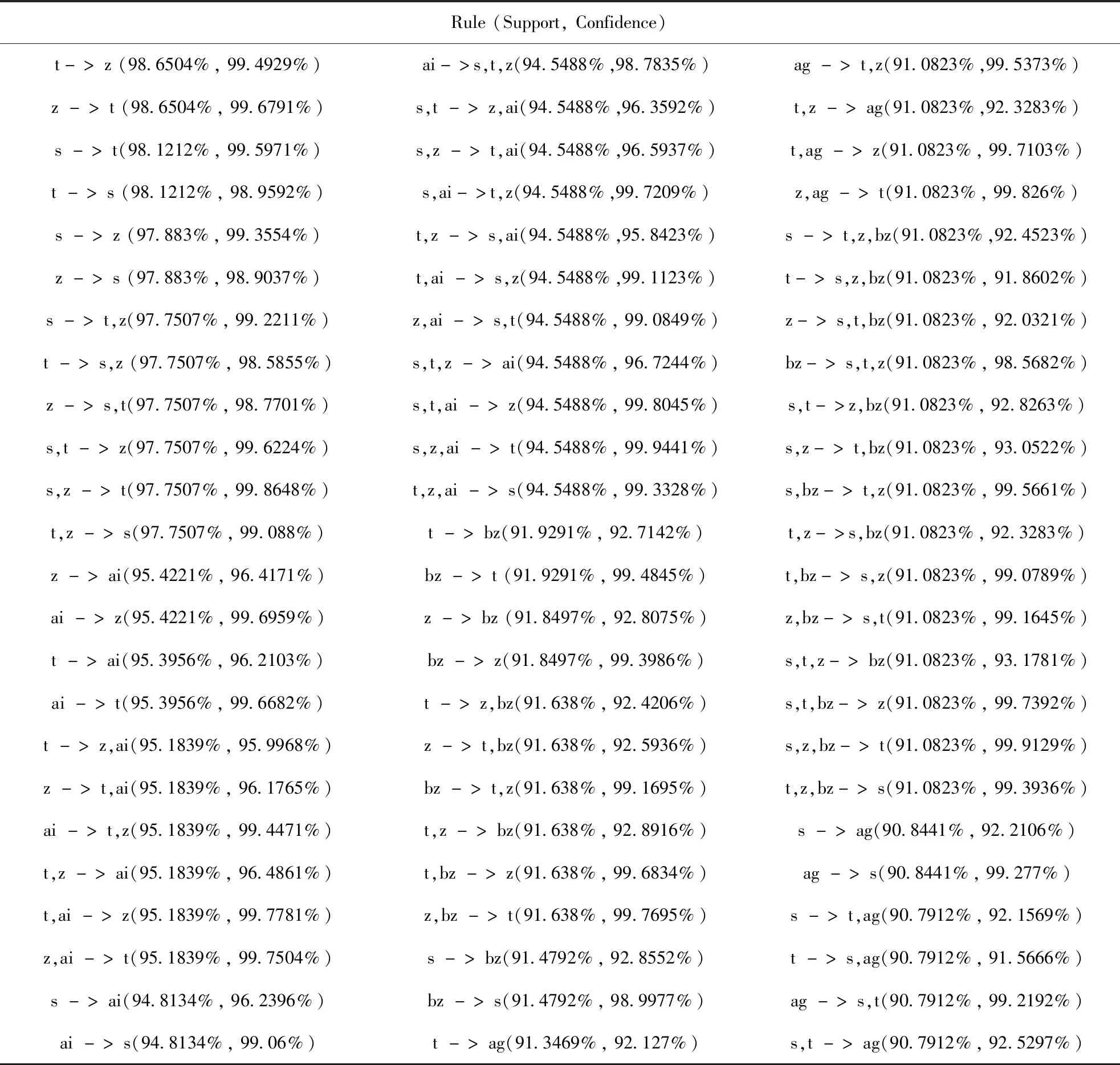
表2 关联规则表

s->t,ai(94.7341%,96.159%)ag->t(91.3469%,99.8265%)s,ag->t(90.7912%,99.9417%)t->s,ai(94.7341%,95.5431%)s->t,bz(91.3205%,92.6941%)t,ag->s(90.7912%,99.3917%)ai->s,t(94.7341%,98.9771%)t->s,bz(91.3205%,92.1003%)s->z,ag(90.606%,91.9688%)s,t->ai(94.7341%,96.548%)bz->s,t(91.3205%,98.8259%)z->s,ag(90.606%,91.5508%)s,ai->t(94.7341%,99.9163%)s,t->bz(91.3205%,93.069%)ag->s,z(90.606%,99.0168%)t,ai->s(94.7341%,99.3065%)s,bz->t(91.3205%,99.8264%)s,z->ag(90.606%,92.5656%)s->z,ai(94.6017%,96.0247%)t,bz->s(91.3205%,99.3379%)s,ag->z(90.606%,99.7378%)z->s,ai(94.6017%,95.5882%)z->ag(91.2411%,92.1925%)z,ag->s(90.606%,99.3039%)ai->s,z(94.6017%,98.8388%)ag->z(91.2411%,99.7108%)s->t,z,ag(90.5531%,91.9151%)s,z->ai(94.6017%,96.6477%)s->z,bz(91.1617%,92.5329%)t->s,z,ag(90.5531%,91.3264%)
3.2 算法性能分析
改进前后的算法支持度及置信度一致,但算法运行的时间不同,改进前的算法运行时间为 57.537 951 s,改进后的算法时间为20.323 541 s,算法运行时间缩短了一半.这是因为频繁候选集出现后,都会事先进行计数,如若本次频繁候选集阶数的数目不一致则删除此候选集,大大缩短了项目记录量,对于下一次事务扫描则可以节约输入输出开销.因此,这种删除方式可以实现大量的项目记录在挖掘中被剔除出来,时间将呈倍数的减少.见图1.

图1 算法性能图
4 结 语
本文运用改进的Apriori算法研究分析Q卷烟配送中心货物品种的关联度,介绍了传统的Apriori算法在数据挖掘中的广泛性和经典性,说明其在商品搜索,数据引擎,市场营销中的作用,进而分析在使用过程中Apriori算法存在缺陷使得算法效率低下,因此对传统的Apriori算法进行改进,缩减项目元素,极大减少I/0开销,算法效率得到提升.根据算法得到的关联规则可以分析得出Q卷烟配送中心仓库货物品种的关联度,再依据预先设定的支持度和置信度确定客户在订货时购买一种货物品种后,极有可能会购买哪种货物品种,由此指导Q卷烟配送中心仓库部门货物摆放,将关联度高的货物品种放置在临近的位置,缩短找货拿取时间,提高出入库效率,从而增加Q卷烟配送中心的经济效益.今后可以根据周转率以及车辆容量限制等分析具体的货位分配,周转率高的货物组合可放置离出入口近的货架,以此类推.
