基于路径探索的车载自组网贪婪路由算法
2020-06-20汤星峰徐卿钦马世纬
汤星峰,徐卿钦,马世纬
(移动通信技术重庆市市级重点实验室(重庆邮电大学通信与信息工程学院),重庆 400065)
(∗通信作者电子邮箱S170101085@stu.cqupt.edu.cn)
0 引言
车载自组网(Vehicular Ad-hoc NETwork,VANET)是一种新兴技术,它将新一代无线网络集成到车辆中,旨在实现车辆之间的通信,以改善道路安全和提供必要的服务[1]。车载自组网作为一种特殊的移动自组网,在智能交通和智慧城市的发展中发挥着重要的作用[2]。车载自组网主要包含两种类型的应用:安全预警和娱乐服务。安全预警消息,比如碰撞警告、前车变速预警等,是以广播的形式进行传播,对时延有很高的要求。而娱乐服务,比如文件共享、对特定路段的视频请求等,是通过多跳单播路由来实现的,具有一定的时延容忍特性。本文所提出的算法是应用在车辆间娱乐服务的多跳单播路由中。
在车载自组网多跳单播路由算法中,基于地理位置转发的路由算法在车载自组网环境中具有更好的性能。文献[3-5]通过预测车辆的运动以及设定路口中继车辆的方式来转发数据包,虽然减小了车辆间链路的断开概率,但在频繁变化的拓扑中,通过预测的方式选择下一跳转发车辆具有较高的计算复杂度,对数据包的传输时延也有较大的影响。文献[6-8]中将车辆速度、密度等作为参数,计算出各个路段的权重值。结合地理信息和城市拓扑,使用Dijkstra算法计算从源车辆到目的车辆的最短路径,然后使用贪婪转发的方式将数据包发送到目的车辆。虽然算法中考虑了城市车辆的密度,避免数据包在车辆稀疏的道路中传输,但这类算法没有考虑车辆密度变化的实时性,缺少对道路中车辆密度的实时反馈。文献[9-10]提出了车辆与车辆和车辆与路边单元的混合路由方式,车辆通过路边单元转发能很好地适应车辆拓扑的变化,降低发送时延,但路边单元的部署和成本问题以及可扩展性问题是该路由算法的难点。
为了提高数据包的到达率,降低数据包端到端时延。本文在以上研究成果的基础上提出了基于路径探索的车载自组网贪婪路由算法(Vehicular ad-hoc network Greedy routing algorithm based on Path Exploration,VGPE)。本文所提算法将数据路由分为路径探索和限制贪婪转发两个过程,充分考虑城市环境的特殊性,在快速变换的车辆拓扑结构中具有很好的适应性和可扩展性。
本文的主要工作如下:1)结合数字地图规划出的多条路由路径,提出了基于人工蜂群算法的路径探索策略,以找到时延最小的路由路径转发数据包。2)在车辆的信标消息中加入速度、车辆所在路段ID 等字段,以便在选择转发车辆时能确保数据传输稳定,且使得整个路由跳数最少。3)在贪婪转发数据包时使用限制性策略,避免数据包转发到陷入路由空洞的车辆。
1 问题引出
在介绍本文路由算法之前,先对城市道路中的车辆作如下假设:
1)城市道路上的每辆车都安装了全球定位系统(Global Positioning System,GPS)导航系统和所在城市的数字地图,车辆可以通过GPS和数字地图获得当前车辆所在道路的编号和位置坐标。
2)车辆之间的传输信号无法穿过城市道路两边的建筑物,所以不同道路上的车辆想要传输信息必须通过在交叉路口车辆的转发。
3)不同类型的车辆,比如出租车、公交车、大货车等在转发数据时都不作区分,拥有相同的转发半径、数据发送速率等参数。
车辆在城市中以基于地理位置的贪婪方式转发数据包时,可能会形成如图1中所示的情况。源车辆S根据贪婪转发的方式将数据包发送给在源车辆S 通信范围内离目的车辆D最近的车辆A。而车辆A 在以相同的方式转发数据包时,因为道路两边建筑物的遮挡,车辆A 接收不到车辆E 的位置消息,在车辆A 的邻居列表中车辆B 离目的车辆D 最近,所以车辆A 将数据包发送给车辆B。但车辆B 所在的路段中的车辆无法将数据包转发给目的车辆,且车辆B 所在路段中的车辆与目的车辆的距离都比车辆B 与目的车辆的距离大,所以数据的发送会进入恢复模式。根据恢复模式的规则,车辆B 会把数据发送给车辆C,车辆C 再把数据发送给车辆E,车辆E与目的车辆的距离小于车辆B,从而继续贪婪转发。由此可以看出,基于地理位置的贪婪路由算法可能因城市场景的特殊性,无法将数据发送到正确的路径上,从而造成路由跳数的增多,增大了数据路由的时延和丢包率。
在城市场景中使用基于地理位置的贪婪方式转发数据包时,最短路径并不一定就是最优路径,有可能在最短路径上车辆稀疏,连接性不好,路由时延和丢包率反而更大。因此本文先使用人工蜂群算法对数据包路由路径进行探索,再对数据包进行转发。
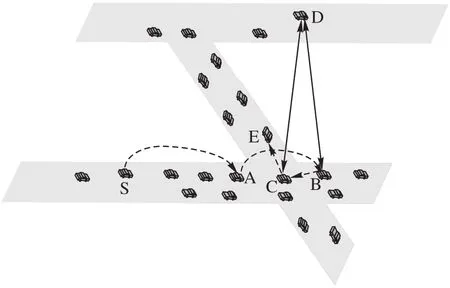
图1 贪婪转发局限性示意图Fig.1 Schematic diagram of greedy forwarding limitation
2 基于人工蜂群算法的路由路径探索策略
2.1 人工蜂群算法介绍
人工蜂群(Artificial Bee Colony,ABC)算法是一种模仿蜜蜂采蜜的群智能优化算法[11]。人工蜂群算法初始化后包含三个阶段:雇佣蜂阶段、跟随蜂阶段和侦查蜂阶段。
1)雇佣蜂阶段。在雇佣蜂阶段,雇佣蜂通过式(1)来寻找蜜源[12]。

其中:φ是在[-1,1]中取值的随机数;xij是初始化时产生的蜜源,xkj代表在初始蜜源中与xij不相等的蜜源,i代表蜜源的编号,j代表蜜源的维度。一个蜜源就表示一个解。在雇佣蜂找到新的蜜源后,比较vij和xij适应度的值,选择具有更优适应度值的蜜源作为本次寻找的结果。适应度的值为蜜源花粉的数量。
2)跟随蜂阶段。在雇佣蜂确定要开采蜜源后,雇佣蜂返回蜂巢通过舞蹈分享蜜源信息。跟随蜂采用轮盘赌的方法选择雇佣蜂所找到的蜜源来开采。轮盘赌的方法是:通过(其中fiti是蜜源i的适应度的值,N是初始化时蜜源的个数)所得出的数比在[0,1]产生的一个均匀分布的随机数大,则跟随蜂就去开采这个雇佣蜂所找的蜜源,否则不开采。
3)侦查蜂阶段。在搜索过程中,如果一个蜜源经过多次迭代,在达到阈值limit前没有找到更优适应度值的蜜源,则这个蜜源将会被抛弃,雇佣蜂将会变成侦查蜂,通过式(2)产生一个新的蜜源来代替被抛弃的蜜源。
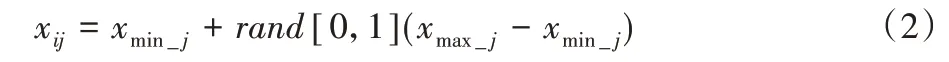
其中,xmin_j和xmax_j分别表示解中第j维的最小值和最大值。
2.2 人工蜂群算法在路由路径探索中的应用
将人工蜂群算法查找最优值的过程应用在车载自组网数据路由路径探索中,以应对城市环境中车辆拓扑的快速变化。在城市环境中,把一条从源车辆到目的车辆的路由路径作为人工蜂群算法中的一个蜜源,人工蜂群算法的每次迭代都要找出所有蜜源中适应度值最大的蜜源作为跟随蜂的开采蜜源,也就是数据包转发的路径。而适应度的值就是雇佣蜂发现的蜜源的花粉数量,在本文中就是探测包在各个路径上的传输时延,传输时延越少说明适应度的值越大。适应度的值如式(3)所示:

其中,τSD是探测包从源车辆通过路径中车辆的多跳转发到达目的车辆的时延。
步骤一 初始化阶段。在初始化阶段要确定蜜源的个数,即备选路径集。如图2 所示,图中In是各个路口的编号。当源车辆响应目的车辆的数据请求,向目的车辆发送数据包之前,源车辆先通过车载的城市道路的数字地图,找到经过最少路口数到达目的车辆的路径,在图2 中,就是最短路径L1。本文规定,从源车辆到目的车辆的路径中,只要经过的路口数小于等于最短路径路口数的2 倍,都加入车辆发送路径探索包的备选路径集中,在图2 中就有路径L2、L3,从而路径集{L1,L2,L3}就是初始化的蜜源集。

图2 路径探索示意图Fig.2 Schematic diagram of path exploration
步骤二 雇佣蜂阶段。源车辆分别向初始化阶段所产生的路径集中的所有路径发送路径探索消息(Routing Path Exploration Message,RPEM),即雇佣蜂。路由路径探索消息的格式如图3所示。

图3 路径探索消息格式Fig.3 Path exploration message format
1)类型:表示不同的数据包类型。其值为1 时,表示路径探索包;值为2时,表示目的车辆回复包。
2)路径条数:记录初始化时路径集中的路径条数,也就是探索包的发送个数,以便目的车辆对接收到的探索包个数进行验证。
3)所要经过路段的ID 序列:规定路径探索包所要经过路段的ID序列,包括源车辆和目的车辆所在路段。
4)探索包发送时间:记录探索包发送时间,以便在探索包到达目的车辆后计算路径的传输时延。
5)多跳转发跳数计数器:记录探索包从源车辆到目的车辆被转发的跳数。
路由路径探索消息通过第3 章中的限制性贪婪路由策略以多跳的形式转发到目的车辆。当目的车辆收到源车辆的路径探索消息时,比较各个路径探索消息的适应度值,适应度越大说明这条路径连接性越好、时延越少,因此目的车辆按具有最大适应度值的路径向源车辆回送一个应答消息(Routing Path Exploration Response Message,RPERM)。应答消息的格式如图3 中所示,和路径探索消息的格式一样,只不过在应答消息中类型值为2,所经过的路段ID 序列为所选定的路径中各路段的ID号。
步骤三 跟随蜂阶段,即数据发送阶段。当源车辆接收到目的车辆的应答消息后,记录选定路径的转发时延,即蜜源适应度的值,将路径的路段ID 序列写入数据包的包头,发送数据包。数据包就会根据选定的路径通过多跳的方式转发数据包。
步骤四 侦查蜂阶段。当目的车辆每次收到数据包后都会通过所选路径向源车辆发送应答消息。源车辆收到应答消息后计算适应度的值,当有其他路径适应度的值连续三次大于当前路径适应度的值时,将适应度值最大的路径中各路段的ID 写入数据包头部,切换数据包转发路径,以适应路径中车辆拓扑的变化。
3 车辆间消息转发的限制性贪婪转发策略
3.1 车辆间的信标消息
在传统的贪婪周边无状态路由(Greedy Perimeter Stateless Routing,GPSR)协议中,车辆间的信标消息是用来交换位置信息的。在本文算法中,给车辆间的信标消息增加了几个字段,以传递更多有用的信息。信标消息的格式如图4所示。

图4 信标消息的格式Fig.4 Beacon message format
1)车辆的行驶方向:表示为一个路口号对(车辆驶离的路口号,车辆驶向的路口号)。
2)车辆所在路段的ID:可以结合车辆上的数字地图和GPS定位来获得,如果车辆在交叉路口上,则车辆所在路段的ID就是车辆所在交叉路口的编号。
3)车辆是否在交叉路口处:如果是,值为1;如果不是,值为0。当车辆在路段上行驶时,由于城市两边建筑的限制,车辆不能接收到其他路段上车辆的信标消息。当车辆接收到的信标消息中,路段ID数大于等于3时,说明车辆处在交叉路口上,则将信标消息的这个字段置为1。
4)在相同/相反行驶方向上车辆是否有下一跳:是为了避免将数据包发送给陷入路由空洞的车辆。
3.2 数据包的限制性贪婪转发
数据包的限制性贪婪转发优化了基于地理位置贪婪转发中的三个问题。
3.2.1 优化问题一
如图5 所示,传统的基于地理位置的贪婪转发路由协议,每次转发都是以离目的车辆最近的邻居车辆作为下一跳转发车辆,这样容易将数据包发送给陷入路由空洞的车辆,从而进入恢复模式,增加了路由的跳数。
为了解决这个问题,本文在车辆的信标消息中加入了“在相同/相反行驶方向上车辆是否有下一跳”这样两个字段。在车辆转发数据包之前,先查看收到的邻居车辆的信标消息中这两个字段是否都等于1,只有在这两个字段的值都为1 时,才能确定要转发的下一跳车辆没有陷入路由空洞中,从而将数据包转发给选定的下一跳车辆。从图5 中可以看出,因为在车辆C 的邻居中没有比车辆C 更接近目的车辆D 的下一跳车辆,所以车辆C 的是否有下一跳车辆这个字段置0,从而车辆S 就不会因为车辆C 距离目的车辆更近而把数据包发送给车辆C,而是把数据包发送给下一跳车辆字段置1 的车辆B。所以在数据每次转发时并不是以离目的车辆最近作为转发车辆选择标准,还要借助“在相同/相反行驶方向上车辆是否有下一跳”这两个字段进行筛选。
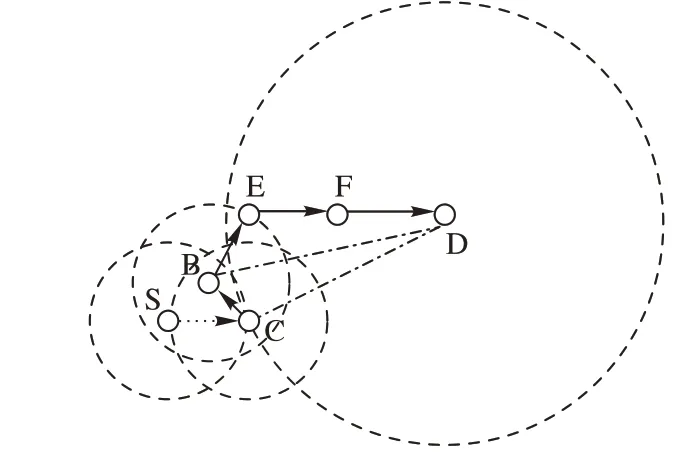
图5 传统贪婪转发Fig.5 Traditional greedy forwarding
3.2.2 优化问题二
由于城市道路中车辆的高度动态性,所以在传输数据的过程中,接收车辆可能离开发送车辆的传输范围造成链路中断,导致数据传输失败。
为了尽量避免车辆在传输数据时链路断开,在数据传输方向上满足下一跳车辆字段为1 的邻居车辆中,本文使用信标消息中的车辆速度字段记录的车辆实时速度计算出每一个邻居车辆与数据包携带车辆的速度差,从而计算出接收车辆和邻居车辆的链路连接时间,也称为连接窗口时间。如果在邻居车辆中有窗口时间大于数据包发送时间的邻居车辆,就在这些邻居车辆中选择拥有最小的窗口时间的车辆作为转发车辆;如果邻居车辆的窗口时间都是小于数据包发送时间的,就选择拥有最大窗口时间的邻居车辆作为转发车辆。当接收车辆和发送车辆之间的距离越来越大时,车辆之间链路连接时间Tlink的计算式如式(4)所示。
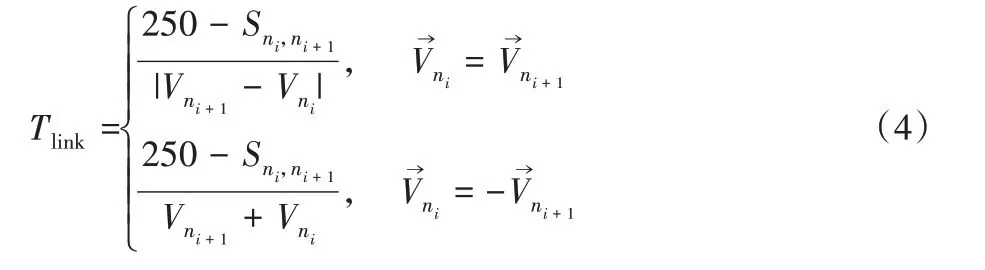
式中:Sni,ni+1为发送车辆ni和接收车辆ni+1之间的距离;250是指设定的车辆的通信半径为250 m;Vni和Vni+1分别是发送车辆ni和接收车辆ni+1的速度。表示发送车辆ni和接收车辆ni+1的速度方向相同,表示发送车辆ni和接收车辆ni+1的速度方向相反。
如果接收车辆和发送车辆之间的距离越来越小时,就认为车辆之间链路的连接时间Tlink为∞。
数据包的发送时间tdata由式(5)计算得出。

式中:xdata表示数据包的大小;vdata表示数据包的发送速率;αt表示数据发送时的排队时延;γt是信道争用时间。
3.2.3 优化问题三
在城市环境中,当数据包转发到交叉路口附近时,因为道路两旁的建筑物的遮挡,发送车辆的邻居表中可能没有要转发道路上的下一跳车辆,所以一般的解决方法是以交叉路口的车辆作为中转车辆,进行数据包的转发;但这样可能会增加整个路由的转发跳数。如图6 所示,数据包转发到车辆S,而下一个转发路段与车辆S 所在路段同方向。车辆D 在车辆S的通信范围内,车辆S 可以直接将数据包发送给车辆D,如果先将数据包发送给路口车辆A,再由A 转发,则就会增加转发跳数,从而增加转发时延。
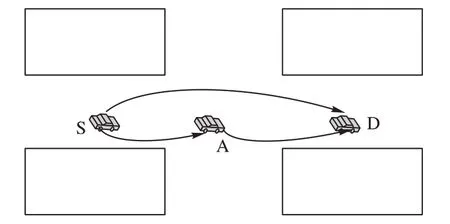
图6 接收车辆和转发车辆在同方向路段Fig.6 Receiving vehicles and forwarding vehicles in same direction
本文的优化方法是:车辆在转发数据包前,通过查找数据包头部字段“所经过路段的ID序列”,找到当前路段ID的下一个路段ID,然后查找当前车辆的邻居列表中所有车辆所在路段的ID是否有与下一个路段ID相同的车辆,如果有就加入备选转发车辆集,如果没有再将字段车辆是否处于交叉路口置1的车辆加入备选转发车辆集。
数据包贪婪转发策略伪代码如下所示。


4 实验仿真与结果分析
4.1 实验设置
使用NS3 和SUMO 软件对本文所提出的路由算法(VGPE)进行了仿真,并将该算法与传统路由算法GPSR[13]和改进的路由算法最大持续时间最小角的GPSR(Maxduration-Minangle GPSR,MM-GPSR)进行了对比。为了使仿真能反映更加真实的场景,本文使用OpenStreetMap 在北京市提取了一个2 000 m*3 000 m 的仿真区域,然后使用SUMO 将地图文件生成城市道路文件,如图7 所示,并在城市主干道路中生成车辆的移动轨迹文件,以便在后续仿真中使用。
图7 城市道路图Fig.7 City road map
NS3 网络模拟器用于路由实现和性能评估,实验中仿真参数的设置如表1所示。

表1 参数设置Tab.1 Parameter settings
4.2 评价指标
为了量化路由算法的性能,本文以下面三个评价指标对路由算法的性能进行分析,每个指标都进行了10 次实验,取10次实验的平均值以消除误差。
4.2.1 数据包到达率
数据包到达率(Packet Delivery Ratio,PDR):仿真时间内网络中目的车辆接收到的数据包的总数Prcvd与源车辆发送的数据包的总数的Psend的比值,计算式如式(6)所示。
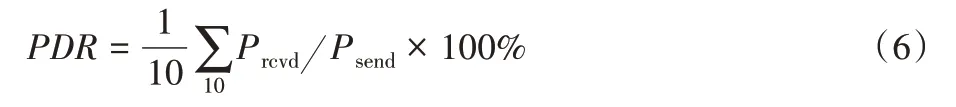
4.2.2 平均端到端时延
平均端到端时延(Average end To end Delay,ATD):数据包i从源车辆到目的车辆所经过的时间Ti与目的车辆接收到的数据包总数的比值,计算式如式(7)所示。

4.2.3 平均端到端跳数
平均端到端跳数(Average end-To-end Hops,ATH):数据包i从源车辆到目的车辆所经过的跳数xi与目的车辆接收到的数据包总数的比值,计算式如式(8)所示。

4.3 结果分析
图8(a)中源车辆的发送速率为每秒4 个数据包,在这样的数据包发送速率下比较了在道路中不同车辆数情况下,通过三种不同路由算法到达目的车辆的数据包到达率。从图8(a)中可以看出,随着道路中车辆数的增加,三种路由算法的数据包到达率都呈上升趋势。本文所提路由算法(VGPE)因为规划了数据传播路径,并优化了数据在十字路口的转发,所以本文算法在道路中不同车辆数情况下,数据包到达率皆优于对比算法。在车辆数为400 时,本文算法的数据包到达率相较GPSR 路由算法提高了13.81%,相较MM-GPSR 路由算法提高了9.64%。
图8(b)是在每秒8 个数据包的发送速率下,道路中不同车辆数的数据包到达率。从图8 中可以看出,图(b)三种路由算法的数据包到达率的趋势和图(a)基本相同,但在相同车辆数情况下,图(b)与图(a)相比,同一路由算法的数据包到达率有所下降,本文所提路由算法(VGPE)优势减弱。在车辆数为400 时,本文算法的数据包到达率相较GPSR 路由算法提高了9.86%,相较MM-GPSR路由算法提高了7.35%。
图8(c)是在每秒16个数据包的发送速率下,道路中不同车辆数的数据包到达率。从图8(c)中可以看出,因为源车辆每秒发送的数据包数大于车辆一次缓存的数据包数量,必然有些数据包会因为缓冲区溢出而被丢弃,所以三种路由算法的数据包到达率都有大幅的降低。因为本文路由算法要进行路径探索,在发送数据包过程中还要对路径进行调整,所以在每秒16 个数据包的发送速率下,本文路由算法的数据包到达率低于GPSR 路由算法。综上可以得出,本文路由算法适用于在每秒数据包发送速率低于车辆缓存数量的情况。
图9(a)是在每秒发送4个数据包的发包速率和改变道路中车辆数情况下,通过三种不同路由算法到达目的车辆的平均端到端时延。由图9(a)中可以看出,随着道路中车辆数的增加,发送车辆更容易找到下一跳车辆进行转发,所以三种路由算法的平均端到端时延都呈下降趋势。但GPSR 路由算法由于可能将数据包发送到远离目的车辆的路段从而进入恢复模式,增加了时延,所以在三个算法中GPSR 路由算法的时延最多。在车辆数为400 时,本文路由算法的时延相较GPSR、MM-GPSR降低了61.91%、27.28%。
图9(b)、(c)是在每秒发送8、16 个数据包的发包速率和改变道路中车辆数情况下,通过三种不同路由算法到达目的车辆的平均端到端时延。计算端到端时延是通过目的车辆收到数据包的时延除以收到数据包的个数来求得的,因为过快的发包速率而被丢弃的溢出缓冲区的数据包无法到达目的车辆,因而不会被计入收到的数据包个数中,所以从图9(b)、(c)中可以看出,数据包的发送速率对数据包的端到端时延影响并不大,三种路由算法的平局端到端时延总体趋势不变。在图9(b)中,车辆数为400时,本文路由算法的时延相较GPSR、MM-GPSR 降低了30.77%、14.29%。在图9(c)中,车辆数为400 时,本文路由算法的时延相较GPSR、MM-GPSR 降低了22.22%、3.92%。
图10(a)、(b)、(c)分别是以每秒4、8、16 个数据包的发送速率,并在道路中不同车辆数情况下,通过三种不同路由算法到达目的车辆的平均端到端跳数。从图10 中可以看出,不同的数据包发送速率对平均端到端跳数影响不是很大,因为本文路由算法对各种可能出现冗余跳数的情况进行了优化,所以在不同数据包发送速率和不同车辆数情况下,本文算法的转发跳数相对来说是最少的。GPSR 路由算法由于在恢复模式下转发跳数的不确定性,所以平均端到端跳数不稳定。
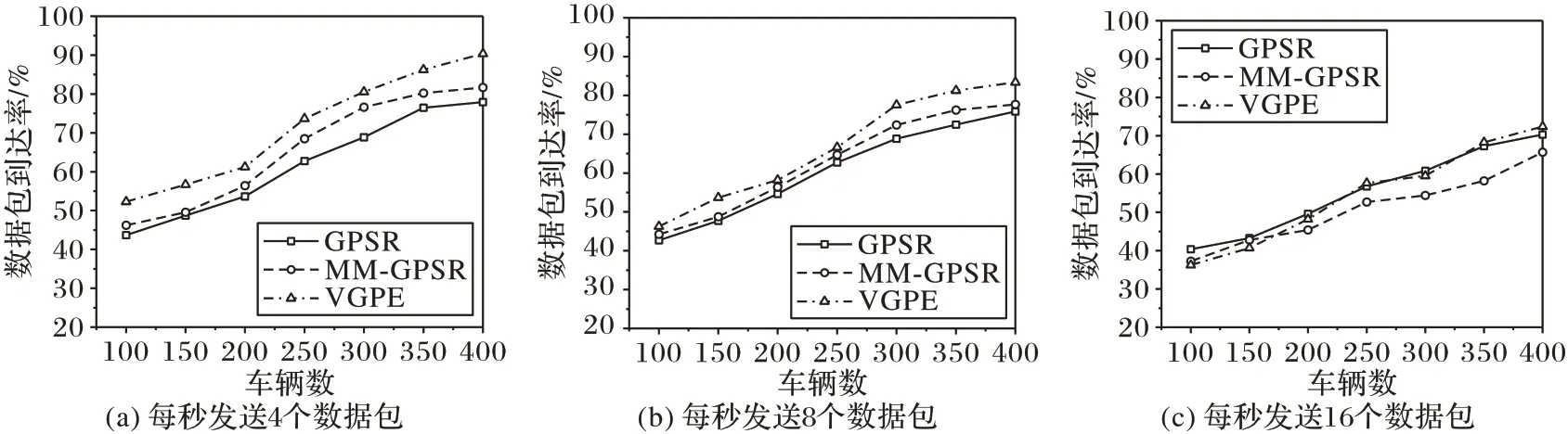
图8 不同数据包发送速率条件下包到达率比较Fig.8 Comparison of packet arrival rates under different data packet transmission rate conditions

图9 不同数据包发送速率条件下平均端到端时延比较Fig.9 Comparison of average end-to-end delays under different data packet transmission rate conditions
5 结语
本文分析了城市环境的特殊性,以及传统的基于地理位置转发的贪婪路由算法在城市环境中的局限性,提出了基于路径探索的贪婪路由算法。通过将人工蜂群算法运用到城市道路中选择路由路径,优化转发车辆的选择方法,使得路由算法能感知道路中车辆的变化,并作出相应的调整。实验结果表明,本文提出的路由算法相较于传统的和其他改进的地理位置路由算法具有较好的性能。
但是本文的路由算法应用在相距较远的车辆之间进行数据路由时,会因为道路的复杂性使得路径探索的复杂度和时延增加,从而造成整体路由性能下降。将路边静态节点作为中继,转发数据包,是克服车辆之间数据转发距离过长而造成的性能下降的可行方法,接下来可在这些方面进行研究。
