基于SVM模型的企业信用风险评估研究
2020-06-19郑建国李新
郑建国 李新
【摘 要】近年来,我国企业信用风险上升。文章结合传统的财务指标,加入非财务指标,以构建更为全面的企业信用风险评估指标体系。以2015—2017年的A股上市公司为样本,将PCA、SMOTE与通过网格搜索法进行参数寻优后的SVM结合,构建PCA-SMOTE-GS-SVM模型评估企业信用风险,并对比其他模型,结果表明,所构建模型具有较高的稳定性和预测能力。
【关键词】支撑向量机;企业信用风险评估;PCA;SMOTE;网格搜索法
【中图分类号】F832.4 【文献标识码】A 【文章编号】1674-0688(2020)05-0220-03
1 概述
1.1 研究背景
目前,在经济增长放缓、生产能力下降、库存减少、去杠杆化加剧等多种因素的影响下,我国信用贷款的风险频繁发生,不良贷款不断增加,所以我国建立相对完善的银行及其他金融机构信用风险评估体系刻不容缓。支持向量机(SVM)广泛应用于模型的分类和回归中,在用于信用风险评估中,可以实现将不良贷款与优良贷款的主体进行分类。
1.2 国内外研究综述
从近几年的研究来看,方匡南等人[1]将基于网络结构的Logit模型用于企业信用风险评估中。蒋翠霞等人[2]基于 Lasso二元选择分量回归,建立了一个评价模型,并将其应用于中国上市公司的信用评价中,结论表明所提模型较于Lasso-logit 模型和支持向量机等具有更好的评价效果和变量选择能力。吴金旺等人[3]建立了Logistic模型以分析A商业银行海量客户信贷数据。肖会敏等人[4]将神经网络模型用于对P2P网络借款人的信用评估研究。Guangrong Tong and Siwei Li[5]提出了lsomap-RVM模型,并用它来对中国上市公司信用进行评估。Ye Tian等人[6]提出一种新的模糊集和最先进的无内核QSSVM模型用于信用风险评估。赵亚等人[7]选取股东、企业诚信情况等构建非财务指标并进行研究。
2 企业信用风险评估指标体系的构建
2.1 数据来源
本文数据来自国泰安金融数据库,样本选自2015—2017在A股上市的公司,根据证监会对企业信用风险的标准,ST的公司为信用差的公司,未被认定为信用好的公司。样本数据总共有9 060条,因变量表示公司是否违约,赋值0和1,其中0表示良好企业;1表示坏企业。
2.2 体系构建
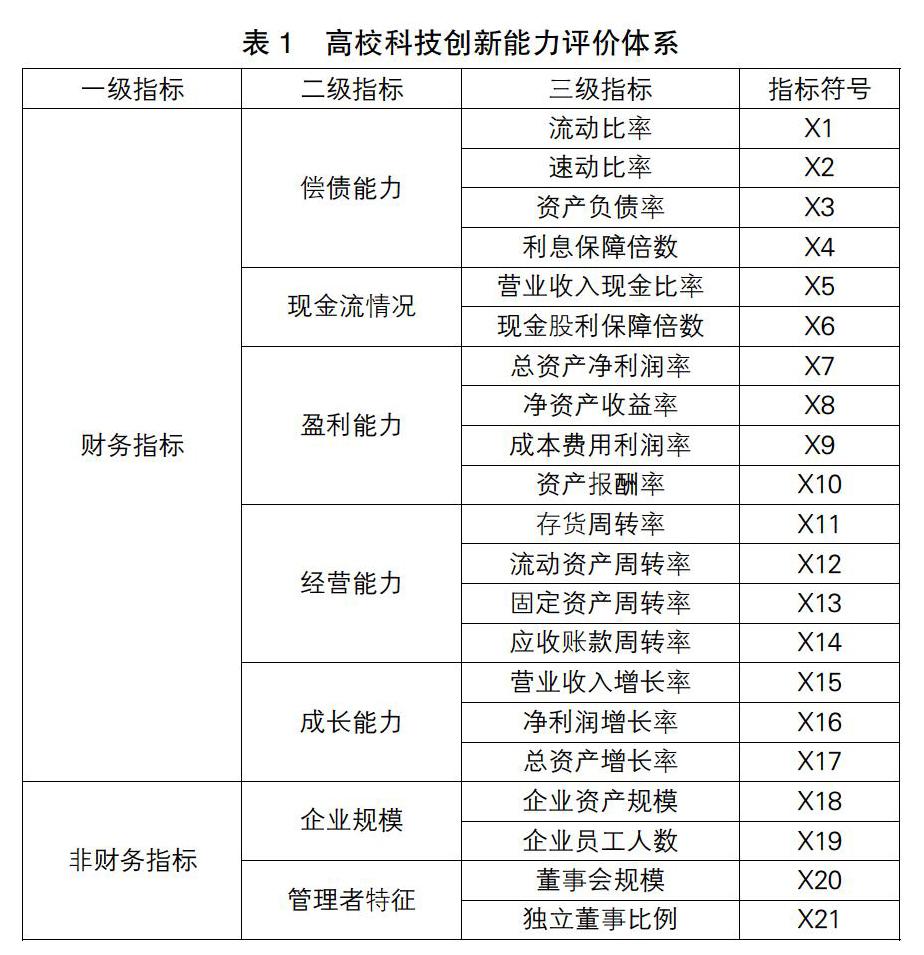
结合国内外学者的研究,我们构建了企业信用风险评估指标体系,其中财务指标共17个,非财务指标共4个(见表1)。
(1)财务指标。偿债能力是衡量企业的经营状况和财务能力的重要表现;而现金流量可以判断企业经营状况是否良好,是否有足够的现金流进行周转;盈利能力可以看出企业是否可以创造价值;经营能力衡量企业的经营状况,企业利用各种资源来经营企业;成长能力反映企业在生存的同时不断扩大规模和发展实力。
(2)非财务指标。通常,我们认为企业规模越大,说明企业承担风险的能力越强,更有资金还贷;管理者特征表明了企业的组织结构,一个具备强大的组织者和领导人的企业更会长期稳定地发展下去。
3 实证分析
3.1 主成分分析
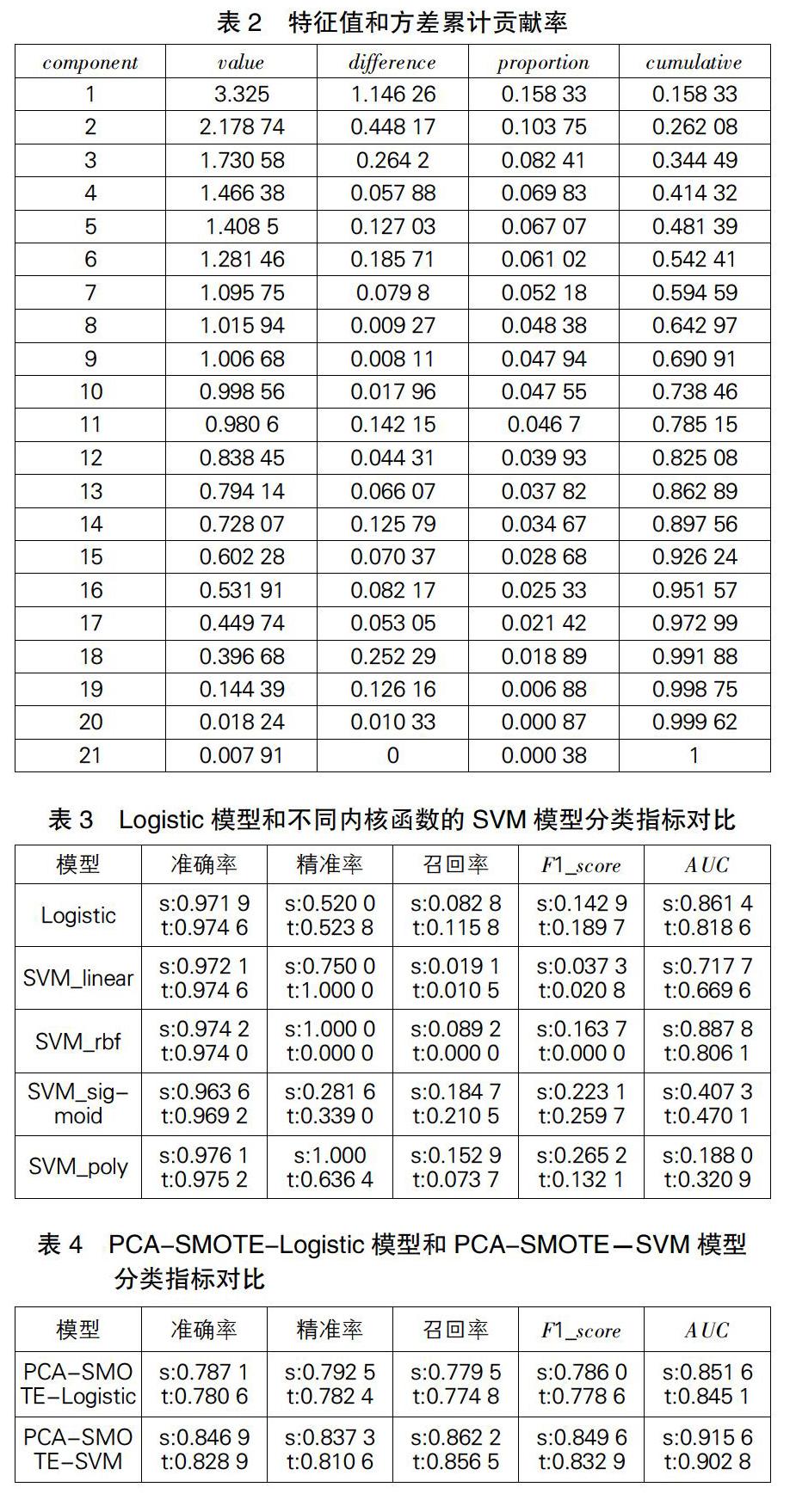
通过计算可得特征值和方差累计贡献率(见表2)。
根据表2,我们提取了10个主成分,且方差累计贡献率74%。
3.2 实验与模型效果对比
我们选取样本的40%为测试集,将没有经过主成分分析降维和SMOTE平衡数据的Logistic模型与不同内核函数的SVM模型进行对比试验,其中s表示训练集,t表示测试集,最终分类效果见表3。
从表3中我们可以看出,不论是训练集还是测试集,每个模型的分类准确率都很高,很大一部分原因是由于数据的不平衡导致的,因为即使将所有的样本预测成0,即违约风险低的企业,预测准确率都有97%,所以我们不能根据准确率进行判断。同时,大部分模型的精准率和召回率、F1_score指标较低,说明正确判断正类样本效果不好,对比AUC指标我们发现,SVM选择径向基核函数RBF的分类性能较其他内核函数更好。所以,后面我们选择内核函数为RBF的SVM进行训练。
很明显,不平衡数据和特征抽取之后的模型对企业信用风险进行评估的效果不好,于是我们先做主成分分析,然后用SMOTE算法过采样平衡样本,对比模型进行实验,分类评价指标见表4。
我们从表4中可以看出,进行主成分降维和平衡数据之后,分类评价指标相较于之前大部分都提高了,并且可以看出PCA-SMOTE-SVM模型比PCA-SMOTE-Logistic模型具备更好的分类性能,训练集和测试集各个指标都高5%左右,说明分类器的效果较好。
支持向量机模型具有两个非常重要的参数,即C和gamma。C表示惩罚系数,C越小,模型越容易欠拟合,反之,就会过拟合。gamma是内核函数的参数,gamma越大,支持向量越少,反之越多。我们采用传网格搜索法寻求最优的参数组合,以达到模型更优的预测效果。设置5折交叉验证的网格参数寻优,最后得到最优参数:C=1 000,gamma=1,此时的最优性能为0.948。最后各个分类指标都上升且很高,AUC值高达97%,准确率高达95%,表明所提模型的分类效果很好。
4 结论和不足
为了研究企业的信用风险评估问题,构建了具有21个指标的企业信用风险评价指标体系,选取2015—2017年3年A股上市公司為样本,构建了PCA-SMOTE-GS-SVM模型,并进行对比实验,所提模型的分类评价指标较高,研究的不足之处有以下两点:①对于参数寻优,文章仅仅采用网格搜索法寻找最优参数,可以寻找最佳分类模型。②本文所提模型,只适用于二分类信用风险分级的样本,可以尝试对企业信用风险评估进行多分类的研究。
参 考 文 献
[1]方匡南,范新妍,马双鸽.基于网络结构Logistic模型的企业信用风险预警[J].统计研究,2016,33(4):50-55.
[2]蒋翠侠,黄韵华,许启发.基于Lasso二元选择分位数回归的上市公司信用评估[J].系统工程,2017,35(2):16-24.
[3]吴金旺,顾洲一.基于非平衡样本的商业银行客户信用风险评估——以A银行为例[J].金融理论与实践,2018(7):51-57.
[4]肖会敏,侯宇,崔春生.基于BP神经网络的P2P网贷借款人信用评估[J].运筹与管理,2018,27(9):112-118.
[5]Tong Guangrong,Li Siwei.Construction and App-lication Research of Isomap-RVM Credit AssessmentModel[J].Mathematical Problems In Engineering,2015(9):1135-1143.
[6]Tian Ye,Sun,Miao,Deng Zhibin.A New Fuzzy Set and Nonkernel SVM Approach for Mislabeled Binary Classification With Applications[J].IEEE Tra-nsactions On Fuzzy Systems,2017(10):1536-1545.
[7]赵亚,李田,苑泽明.基于随机森林的企业信用风险评估模型研究[J].财会通讯,2017(29):110-114,129.
