基于多目标进化的复杂网络社区检测
2020-06-16柴争义
王 聪,柴争义
(天津工业大学 计算机科学与技术学院,天津 300387)
0 引 言
在复杂网络中,被广泛关注的一个重要的拓扑属性就是网络的社区结构[1]。所谓社区结构,就是指整个网络由若干“簇”或“组”构成,这些“簇”或“组”叫做社区,位于每个社区内部的节点相互之间的连接非常稠密,而位于不同社区内的节点相互之间的连接比较稀疏[2-3]。
近几年,复杂网络社区发现作为一个研究热点,已经受到越来越多的关注,也有越来越多的学者参与其中,现如今已经涌现出了许多优秀的社区发现算法,主要有以下几类:
(1)基于节点相似度。
为了准确计算节点的相似性,文献[4]通过分析二分网络中两类节点的结构特征及其对社区密度的影响,结合了Salton指数和改进的Logistic函数,定义了一种新的相似度计算方法;文献[5]基于网络节点相似度矩阵,结合改进的K-means算法对网络节点进行相似性聚类,实现网络的社区发现;文献[6]提出一种基于多层节点的节点相似度计算方法,该方法既可以有效地计算节点之间的相似度,又可以解决节点相似度相同时的节点合并选择问题。
(2)基于层次化聚类。
文献[7]则引进节点相似度并加以适当改进,然后重新定义模块度函数,提出基于节点相似度的层次化社区发现算法,提高了层次化社区发现的准确性;为了处理大规模复杂网络中的社区结构,文献[8]提出一种基于SCAN算法的密度聚类算法——QSCAN算法。
(3)基于AP算法。
当前很多学者将AP聚类算法应用于社区检测[9],文献[10]利用网络潜在几何概念对网络的相似性矩阵进行改进,能有效提高AP聚类算法的聚类效果;对于复杂度较高的社区网络,则需要利用并行计算处理对数据进行AP聚类[11]。
(4)结合算法。
有学者提出MOEA/D算法的多目标社区检测算法,且经过案例测试,在解决复杂网络社区检测问题上具有一定优势,且通过AP聚类算法对初始解进行优化,再用多目标检测算法进行社区发现的社区发现效果更佳[12-13]。
文中将聚类和启发式的算法相结合,提出一种改进的多目标进化算法来进行复杂网络的社区检测,用半监督的AP聚类算法确定初始解的聚类数目以及节点所属类别,克服传统的通过随机方式产生的初始解聚类效果不稳定的缺点,进而采用模拟退火算法改进MOEA/D算法完成参数寻优过程,防止算法陷入局部最优,提高算法的全局搜索能力。
1 相关技术
1.1 近邻传播聚类
Affinity Propagation(AP)算法是一种半监督聚类算法,该算法无需制定聚类数目以及聚类中心,将所有样本点作为可疑的聚类中心,算法会在每一次迭代过程中对(responsibility)和(availability)的数据进行更新。该算法的终值条件是可以找到m个高质量的聚类中心,且其他样本点都能规划到相应的类别。
该算法的步骤如下:
(1)计算数据集的相似度S,再对p赋值。
(2)计算样本点之间的responsibility值。
(3)计算样本点间的availability值。
(4)responsibility及availability值更新。
其中λ是收敛系数,主要用于调节算法的收敛速度以及迭代过程的稳定性。
终止计算的条件必须满足迭代次数已经超过设定的最大值或者经过若干次的迭代计算后聚类中心已经不再发生改变时,计算终止后得出聚类的中心点和每类所包含的数据,反之返回步骤2,继续计算。
文中将AP聚类算法作为初始解的产生算法,用来实现初始解的半监督聚类。
1.2 模拟退火算法
SA(模拟退火)算法是一种模仿系统中的粒子通过运动逐渐趋向平稳的过程,这个过程可以分为加热、等温和冷却三个阶段。随着迭代的进行,系统的温度逐渐下降,对于优化问题来说其当前解逐渐逼近真实解,因而系统趋向于稳定[14-16]。
文中温度T的初始温度T0=100,且降温系数为0.9,即个体下一状态温度为上一状态温度的90%,如下式:
Tk+1=0.9Tk
(1)
其中,k为当前状态,k+1为下一状态;Tk,Tk+1分别为两次相邻状态的温度。
对于个体的变异操作将加入模拟退火的改进,假设当代种群的温度为Tk,对于个体i来说是否接受其变异后的个体取决于该个体变异后的新个体的适应度是否大于变异前个体的适应度。如果变异后的个体的适应度大于原来个体的适应度,则对其进行变异;反之则以概率p接受该个体的变异,其中:
p=e(f(xk,i,mutatio)-f(xk,i))/Tk
(2)
其中,p为在变异后个体的适应度小于当前个体的适应度的情况下的变异概率,k为当前的迭代种群索引,i为个体索引,f(xk,i,mutatio)和f(xk,i)分别为变异后个体的适应度与当前个体的适应度。
变异原则如下式:
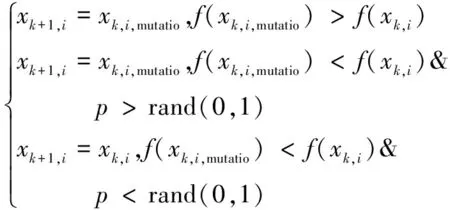
(3)
其中,rand(0,1)为[0,1]之间的一个随机数。变异后个体的适应度f(xk,i,mutatio)大于原来个体的适应度f(xk,i),则对其进行变异;反之只有当变异概率p大于随机数rand(0,1),接受该个体的变异,其余情况下保持个体不变异,对于k+1代种群的第i个个体依旧沿用上一代的第i个个体。
2 算法思想
通过AP聚类算法可实现对节点网络的半监督聚类,不用再去人为确定聚类数目以及聚类中心;继而采取模拟退火算法对遗传算法进行改进,因为模拟退火算法的独特之处就在于其在个体进化过程中会满足一定的概率来决定是否接受新个体的产生,这个准则也被称为Metropolis准则,这也是模拟退火算法相较于遗传算法的优势,通过一定概率接受新个体来提高算法的全局解空间的搜索能力,防止陷入局部最优。
3 MOEA/D多目标进化社区发现算法
MOEA/D是由Zhang和Li在2007年提出的一种基于分解的进化多目标优化算法,该算法将一个多目标问题根据权值矢量分解成个单目标子问题,并通过进化计算方法同时优化这些子问题。
文中采用模块度密度D作为指标对Pareto解进行优秀个体的选取。
3.1 目标函数及评价指标
为了使网络社区划分的好坏可以有一个明确的评价指标来衡量,根据对复杂网络的研究提出了模块度(modularity)的概念,但利用模块度来优化会导致分辨率限制的问题,于是有研究者引入了模块度密度D来避免这个问题。在大量的重复验证中,以模块度密度D作为指标要比以模块度Q作为指标在复杂网络社区检测的效果更好。
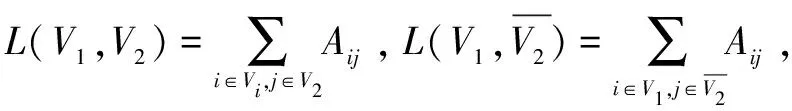
(4)
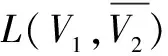
文中把RA改成了Kernel K-means(KKM),将上述问题转换成了关于最小值的优化问题,则目标函数定义为下式:
(5)
其中,n=|V|,σ为一实数。这样一来,社团内部的紧密性就可以用KKM的值来表示,而内部节点和外部节点连接的稀疏性则可以用RC的值来表示。KKM的值越小,社区内节点间的连接越紧密;RC的值越大,社区间节点间的连接越稀疏。
3.2 算法构建
文中算法共有三个部分,分别是初始解优化、多目标进化以及结果可视化。
步骤1~6为AP算法初始解优化部分,步骤7~13为AP算法多目标进化部分。

步骤2:计算数据集的相似度S。
步骤3:计算样本点之间的responsibility值。
(6)
其中,a(i,j)表示节点j对于节点i的availability值,s(i,k)表示节点i和节点j的相似度,r(i,k)表示节点k对于节点i的responsibility值。
步骤4:计算样本点间的availability值。

(8)
其中,a(i,k)表示节点k对于节点i的availability值,r(k,k)表示节点k的responsibility值。
步骤5:responsibility及availability值更新。

(9)
其中,λ是收敛系数,主要用于调节算法的收敛速度以及迭代过程的稳定性。
步骤6:计算个体的适应度并记录。
步骤7:判断p是否等于pmax,如果成立则进入下一步的多目标进化算法,初始寻优过程结束;反之,p=p+Δp返回步骤2。
步骤8:个体编码采用直接编码,其中每个个体都包含m个十进制的染色体,也就是每个节点所属的社团的类别号,这些类别号都是整数,可以是1-m之间的随机整数。对于一个具有m个节点的网络图最多可以分为n类社区,则在这种情况下个体编码[1,2,…,m],则该个体具有m个染色体,每个染色体代表一个节点的所属社团的类别。
步骤10:交叉。对相邻的两个父代个体采取单点交叉方式,通过产生一个随机的位置点,将该点以后的个体的相应位置的编码进行交换,以此产生两个新的相邻的子代个体。对于相邻两个个体的交叉过程如图1所示。

图1 单点交叉示意图

步骤11:变异。就是对某一节点所属的社团分类以概率pm进行随机改变,但是社团分类小于节点的数目m,也就是对于第i个种群的第j个个体的第k个染色体是否变异应满足一下原则:
(10)
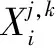
步骤12:对当代种群进行解码;计算当代各个个体所对应的两个目标函数,KKM以及RC数值;且计算个体的模块度密度D对Pareto解进行优秀个体的选取。
步骤13:是否达到预设最大迭代次数,如果是,则输出最后一代种群,算法结束;反之则返回步骤(2)。
结果可视化部分则是通过将算法在不同的μ值之下仿真40次,分别求均值以此逼近不同μ值之下的复杂网络的NMI数值,通过画图进行算法效果的对比。
4 实验分析
文中的分析案例为Footbal足球社交网络、Karate-Club网络和Dolphins网络,编程平台为MATLAB2016B,机器配置为CPUi5-4200h,12 GB内存。首先,设置AP聚类算法的p参数的上下限为[-20,0],且对其进行400等分,作为初始种群;然后设置MOEA/D算法的迭代次数为40,种群大小为400,交叉概率为0.8;接着通过改变μ参数从0.1到0.9,间隔为0.1分别进行40次实验得到实验结果;最后绘制出不同μ值下所对应的NMI曲线,且以MOEA/D算法[12]和AP-MOEA/D算法作为对比[13]。
选用NMI指标来评价社区检测效果,归一化互信息函数(NMI)用于评价两个社区划分之间的相似性。互信息在信息论中是一种重要的炮测量方法,用来衡量两个事件之间的相关性,其启发式原则是,如果两个社区是相似的,那么通过其中一个社区的类内信息即可得到另外一个社区的结构。使用几何均值的方法归一化互信息的表达式为:
(11)
利用NMI来评价两个社区之间的相似性,当其值接近1时,表示两个社区之间结构很相似;当NMI的值接近0时,表示两个社区之间结构很不相似。
经过MATLAB编程运算可以得到AP-SA-MOEA/D社区发现算法在不同μ值之下的40次实验经过剔除异常值的NMI平均值曲线,且以AP-MOEA/D算法、MOEA/D算法作为对比算法,对比曲线如图2~图4所示,对比结果如表1~表3所示。

表1 Footbal网络三种算法NMI均值对比

图2 Footbal网络三种算法NMI对比曲线
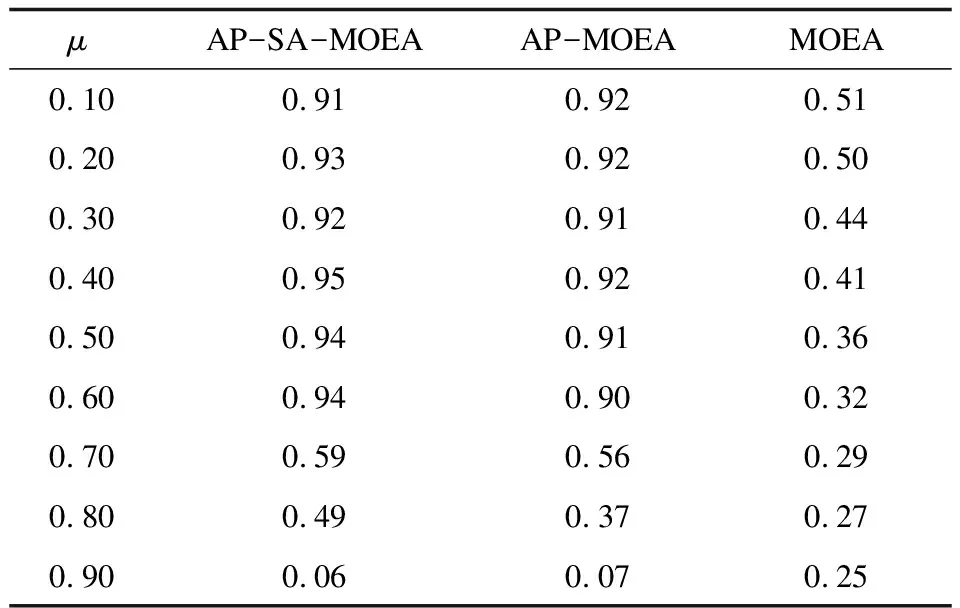
表2 Karate-Club网络三种算法NMI均值对比

图3 Karate-Club网络三种算法NMI对比曲线
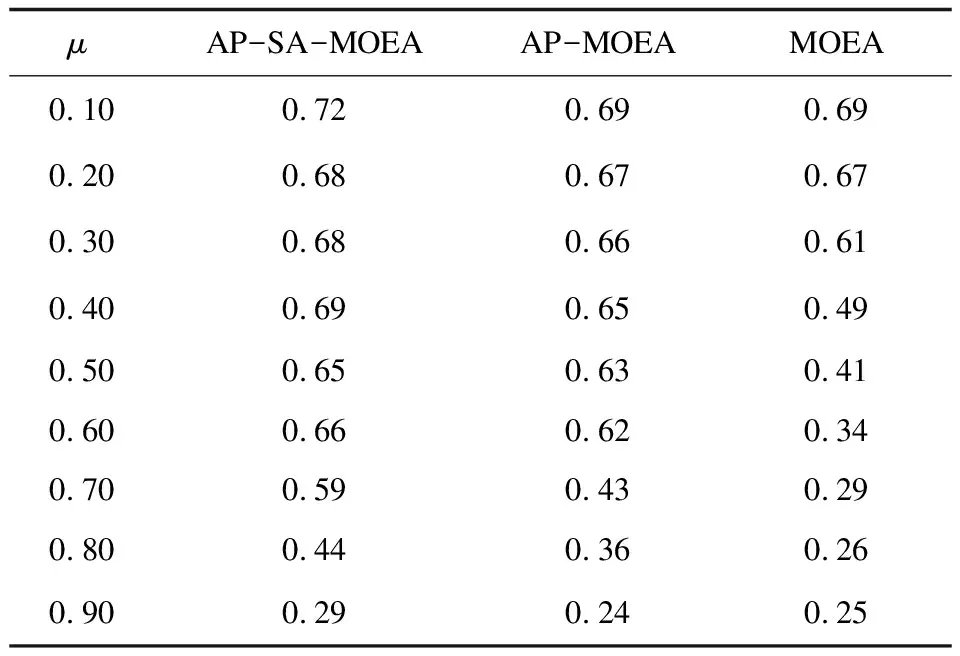
表3 Dolphins网络三种算法NMI均值对比

图4 Dolphins网络三种算法NMI对比曲线
通过对比可以发现,总体上AP-SA-MOEA/D算法显然比AP-MOEA/D算法、MOEA/D算法的社区发现效果明显,因而文中提出的算法对于社区发现是有效的。
5 结束语
提出一种改进的复杂社区检测多目标进化算法,首先利用近邻传播(AP)聚类算法半监督产生初始解以及聚类数目,克服传统的通过随机方式产生的初始解聚类效果不稳定的缺点;进而利用模拟退火(SA)算法对MOEA/D算法进行改进,提高全局搜索能力;最后通过仿真及算法对比,证明该算法效果更佳。
