基于Spark的层次聚类算法的并行化研究
2020-06-16余胜辉李玲娟
余胜辉,李玲娟
(南京邮电大学 计算机学院,江苏 南京 210023)
0 引 言
大数据时代的来临导致行业领域产生的信息数据呈爆炸式的增长。对海量数据的挖掘以及利用成为了当下最热门的重点研究课题之一。聚类方法是数据挖掘领域中最为重要的方法之一,是一种无监督的机器学习算法,能够将数据对象中具有相同属性的数据划分为若干个子集,每个子集形成一个簇,同一个簇中的数据具有相似的特征,不同簇中的数据相异[1]。层次聚类算法是聚类算法中最常见的一类方法,“类内的点都足够近,类间的点都足够远”[2]是其最重要的判断标准。CURE算法是一种典型的层次聚类算法,该算法简单、速度快,对大数据集有较高的聚类效率和可伸缩性,时间复杂度近于线性,适合对大规模数据集进行挖掘[3-4]。Spark[5-6]是专门为大规模数据处理设计的快速通用计算引擎,是以Hadoop MapReduce为基础框架的一个新的开源平台。Spark支持交互式计算和复杂算法,速度很快;具有很高的通用性;支持多种资源管理器。为了进一步提升CURE层次聚类算法的效率和可伸缩性,文中基于Spark平台对其进行并行化,并通过对不同的数据集的聚类实验来证明该并行化方案的有效性。
1 CURE算法的原理
CURE是一种基于取样和代表点的层次聚类算法,它采用迭代的方式,自底向上地合并两个距离最近的簇[7]。CURE算法在传统的划分聚类算法受异常数据比较敏感这一特点上能够得到很好的解决。CURE算法在计算过程中将每一类当成一个点,用这个点代表其中一个类型的数据,然后计算一个类与另一个类之间的距离,最相似的两个点进行合并,不需要计算类内每个数据点之间的距离,这样计算有利于减少运算量,提高效率。但此算法的复杂度较高,运行时所消耗的资源较多。CURE算法的具体特征及思想主要体现在如下几个方面[8-9]:
(1)最初,每一个对象就是一个独立的类,然后从最相似的对象开始进行合并。
(2)为处理大数据集,采用了随机抽样和分割手段。采用抽样的方法可降低数据量,提高算法效率。一般能得到比较好的聚类结果。分割手段,即样本分割为几个部分,然后针对各个部分中的对象分别进行局部聚类,形成子类。再针对子类进行聚类,形成新的类。
(3)CURE算法由分散的若干对象按收缩因子移向其所在类的中心之后来代表该类。由于CURE算法采用多个对象代表一个类,并通过收缩因子类调节类的形状,因此能够处理非球形的对象分布。
(4)消除异常值可以分两个阶段进行,第一个阶段的工作,是将聚类过程中增长非常缓慢的类作为异常值除去,第二个阶段的工作(聚类基本结束的时候)是将数目明显少的类作为异常值除去。
CURE的具体操作流程如下[10]:
(1)从原始数据中随机抽取样本,得数据集S。
(2)对S进行分区,对每个分区分别进行聚类。
(3)如果一个类增长很慢,说明它是噪声要去除。
(4)将局部的类进行聚类。
(5)对原始数据进行标记。
2 Spark
Spark是为了提高计算速度、易用性和复杂分析而构建的大数据处理框架。为了提高Spark处理大量数据的实时性,因此计算都是基于内存计算的,Spark的集群一般都是部署在很多廉价的硬件上的,这种部署对容错性和可伸缩性都能得到保障。
(1)Spark与传统大数据平台的对比。
在Spark之前已有Hadoop和Strom等大数据平台,这些大数据平台都是基于MapReduce[11]技术,与之相比Spark具有十分明显的优势[12]:
①Spark底层通过开辟了线程池,利用了线程池能够复用线程,不必反复创建销毁线程的优势,能够减少资源,大大减少了任务调度的开销。
②Spark中的RDD可以理解为一个集合,可以在上面进行计算,传统数据模型的容错,可伸缩性等特点RDD都具有,也可将数据缓存,方便后续的重复使用。
③Spark在每一轮计算过程中都会得到一个中间结果,因此可以将每一轮的输出结果在内存缓存,在后续的运算需要时,可以直接从缓存中对数据进行读取,代替了从HDFS中读取数据,从而避免了大量耗时的磁盘I/O操作,直接从内存里进行读取,对运行速度有很大的提升[13]。
(2)Spark的组成。
Spark主要包含以下几个部分[5]:
①Spark Core:这是Spark最为核心的一个部分,是一个通用分布式数据引擎,它自成一个体系,可适应在任何商用服务器集群上。对Spark一些基础功能进行了定义,尤其是RDD的API,操作及这两者的动作。
②Spark SQL:是提供在大数据上的SQL查询语句,这一功能扩充了SQL算子,丰富了Spark的算子和功能。
③Spark Streaming:利用Spark Core的快速调度能力来执行流数据。它以最小批次获取数据,并对批次上的数据执行RDD转化,其核心是采用微批处理引擎,支持多种数据源的导入,可根据程序配置的时间,将数据打成一个RDD,发送给Spark Core进行处理。
④MLib:一个常用算法库,包含了几种常见的机器学习算法。
(3)Spark的架构。
与传统经典的分布式计算架构模型类似,Spark沿用了传统的架构模式:Master-Slave模型[14],如图1所示,Master对应ClusterManger进程的节点,能够控制整个集群的运行,是集群中最不可缺少的部分。Slave对应着Worker进程的节点,它的作用是对现在的形态向上汇报和接受特定的命令和向下进行分发具体的任务,Executor是执行任务的具体部分进行运算,Client是与用户进行交互的界面提供了可视化的功能,同时也负责任务的提交。Driver相当于处理中心,进行对应用的执行。当新建一个任务被提交上来之后,Driver节点会创建一个SparkContext,由SparkContext向资源管理器(ClusterManger)申请资源,资源分配完毕后Spark会启动Worker上负责执行具体任务的进程Executor,并把任务分给Executor,计算完成后Worker会将结果发回Driver,然后释放资源[15]。这就是一次具体的任务提交处理流程。
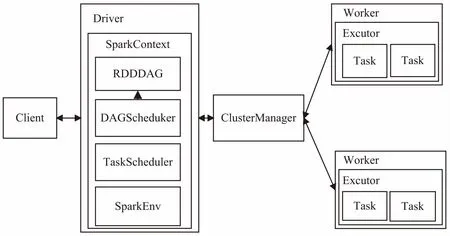
图1 Spark架构
3 基于Spark的CURE算法的并行化方案
基于上述的分析,CURE算法具有适合处理海量数据集,需要对数据进行分区处理,以及需要对数据进行反复迭代等特点,这与Spark大数据计算框架RDD的特性十分相契合。文中正好通过此特性,实现CURE算法基于Spark的并行化。
CURE算法基于Spark的并行化步骤如下:
(1)Spark的配置与数据源的读取。
构建Spark Application的运行环境后,配置文件会被Spark的驱动器程序自行加载,首先会生成一个SparkConf对象,之后通过该对象又会自动生成一个新的SparkContext,Exctuor资源就是通过SparkContext向资源管理器注册并申请运行的。通过上述的分析,得知Spark计算流程实际上是将待处理的数据集读取后转换成为源RDD,然后通过Spark Core提供的transformation算子,对该RDD进行转换来获取新的RDD,最后调用Action操作求得结果值。使用HDFS文件创建RDD是最常用的方式,可以针对HDFS上存储的大数据,进行离线批处理操作。在RDD计算过程中,每个分区都会运行一个task,所以RDD的分区数目决定了总的task数目,在Spark集群资源有限的条件下,需要对RDD进行合理的分区,分区太多或太少都会导致计算效率的降低。
(2)CURE算法并行化执行的流程。
Step1:对原始数据进行分区,随机分成N个数据片,将数据读入HDFS转化成DataFrame。相比于RDD,DataFram能提供更为详细的结构信息,使得Spark SQL可以清楚地知道数据的详细信息。DataFrame相比RDD不仅提供了更丰富的算子,最重要的是可提升执行效率。
Step2:采用收缩因子的方法为每个数据块选取代表点,通过mapPartiotions对N个数据片进行MapReduce聚类计算,计算出中心点。为了提升聚类结果的准确度有两种删除异常点的操作:①如果出现两次及以上的聚类计算则会统计该类的增长速度,发现增长速度慢的类则当作噪声去除;②当类内的数目低于某一个阈值时也会进行删除,因为有可能恰好较近的几个异常点在同一个类中。
Step3:对上一步聚类产生的类,通过拉格朗日距离来计算它们之间的中心点距离,并将距离最小的两个类合并,合并之后得到一个新的类。
Step4:对新的类重新进行MapReduce计算,得到新类的中心点以及代表点。
Step5:判断聚类后的个数是否满足设定的聚类数,如果不满足则继续重复Step2,如果满足则得到最终聚类结果。
CURE算法基于Spark的并行化流程如图2所示。

图2 CURE算法并行化流程
CURE算法本身在不确定的数据上的计算时间消耗可能会非常大,在上述执行过程中通过Spark平台MapReduce以及缓存特性,执行器会将需要缓存的数据缓存到内存中,调用驱动器节点对需要处理的数据进行再次计算,当达到终止条件时会将计算好的结果存储在HDFS中。Spark的核心就是RDD是分发到不同executer节点上进行并行计算,并将中间结果缓存到内存中,对需要大量迭代重复计算的CURE算法在时间效率上有很大的提升。
4 实验与结果分析
为了验证和分析基于Spark的并行化CURE算法聚类结果的准确性与时间效率,设计了以下实验,分别在单机和Spark上对CURE算法对相同大小的实验数据集进行聚类操作,比较对多种数据集在不同运行模式下的聚类准确率和时间效率。
(1)实验环境和实验数据。
实验环境如下:共搭建了包括1台驱动器节点,2台执行器节点的Spark。节点的CPU是Intel CORE i5-7440H,每个节点配有2个处理器,硬盘数据读写速度为600.00 MB/s,驱动器节点的内存大小为6 G,执行器节点的内存大小为4 G。操作系统是centos6.5;Java版本是JDK1.8.0_144;Spark版本为1.6.0;Scala版本为2.11.0。实验分别采用了UCI实验室提供的Bag of Words数据集,该数据集包含五个文字集合,八百万个实例数;YouTube MuLtiview Video Games Dataset数据集,该数据集包含大约120 000个实例,每个实例由13种要素类型描述;Plants数据集,该数据集包含了70个属性,22 632个实例数。
(2)聚类准确率对比实验。
通过CURE算法对上述的数据集进行聚类,聚类准确率如表1表示。

表1 不同数据集上CURE算法的聚类准确率
由表1可以看出,对于三个数据集,基于Spark的并行CURE算法相对于传统单机运行模式的CURE算法的聚类准确率略微有所提高。可以看出分布式数据处理对结果的精准度和稳定性有较好的保障。
(3)时间效率对比实验的聚类时耗。

图3 单机和基于Spark平台的CURE算法聚类时间对比
由图3可知,在开始阶段数据量比较少,两种不同环境的CURE聚类运行所消耗的时间相差不大,因为Spark启动消耗了大量的时间,在数据量较少的情况下无法体现其在时间方面的优势。伴随着数据量增大,基于Spark的并行化计算所消耗的时间明显少于传统的单机计算方式。因此,在处理大量数据的情况下Spark的并行化计算具有良好的时效性。
5 结束语
主要研究了CURE算法基于Spark平台的并行化实现方案,给出了通过将数据集分区后分发给多个子节点和进行RDD转换来实现CURE算法的并行化步骤;通过在两种运行模式和三种公开数据集上的聚类实验,验证了CURE算法基于Spark的并行化运行比传统的单机运行的聚类准确率略有提升,且随着聚类数据量的增加,基于Spark平台的并行化CURE算法展示了更好的时效性。
