基于“互联网+”的声纹识别技术在刑事案件侦破中的应用研究
2020-06-15魏莲芳
魏莲芳

摘 要: 对面向“互联网+”的声纹识别技术进行研究,并分析了其在刑事案件侦破中的应用。基于GMM?UBM声纹识别确认系统,对GMM?UBM模型构建方法进行详细描述,研究模型参数最大后验概率算法、估计期望最大化算法、参数训练和识别过程。对基于GMM?UBM的声纹识别系统进行设计,利用对比实验的方法分别验证在相同条件下GMM建模方法、GMM?UBM建模方法的识别效果。在测试随机抽取的一组语音时,系统均具有较高的识别成功率,在进行不同人数测试时,随着样本人数的增加,系统识别率会有少许降低,但平均识别率较高,为89.6%;与GMM系统相比,GMM?UBM系统具有较高的识别率,随着混合度的增加,GMM?UBM系统识别率随之增大。
关键词: 刑事案件侦破; 声纹识别; 互联网+; GMM?UBM; 识别率; 参数训练
中图分类号: TN912?34; TP311 文献标识码: A 文章编号: 1004?373X(2020)07?0034?05
Research on application of "Internet+" based voiceprint recognition
technology in criminal case investigation
WEI Lianfang
(Sichuan Police College, Luzhou 646000, China)
Abstract: The voiceprint recognition technology applied to "Internet+" is studied and its application in criminal case investigation is analyzed. On the basis of the GMM?UBM (Gaussian mixture model?universal background model) voiceprint recognition system, the construction method of GMM?UBM is elaborated, and the maximum posterior probability algorithm, estimation expectation maximization algorithm and training & recognition process of model parameters are studied. The voiceprint recognition system based on GMM?UBM is designed. The recognition effects of GMM modeling method and GMM?UBM modeling method under the same conditions are verified respectively by comparative experiments. When testing a group of randomly?extracted voices, both the systems are of high recognition rate. When testing different numbers of people, the recognition rate of the system decreases somewhat with the increase of the number of sampling people, but the average recognition rate is 89.6%, which is high. In comparison with the GMM system, the GMM?UBM system is of higher recognition rate. The recognition rate of GMM?UBM system increases with the increase of the degree of mixing.
Keywords: criminal case investigation; voiceprint recognition; Internet+; GMM?UBM; recognition rate; parameter training
0 引 言
近年来,随着计算机技术发展越来越快,语音识别技术也随之获得一定的发展。在实际应用中,语音识别技术能对说话人个人身份语音特征进行获取、表征。“互联网+”时代正在飞速发展,安全保障以及身份验证等成为医疗、共享出行以及移动支付的重要内容。
对于刑侦工作来说,开始广泛应用数字声纹识别技术,能够有效弥补其他特征识别技术存在的缺陷。声纹识别是通过声学、语音学原理,对磁介质机载的声语频谱进行分析,对声音进行语言判断、鉴别的过程。数字声纹识别技术可利用计算机技术、多元化通信技术转化声纹样本频谱图,通过数字声纹样本的方式自动识别声纹。基于该技术能够有效建立虚拟标准人类声纹样本,涉及人类发生多元化特征。声纹样本基于对比获取后,可以记录特征参数差值。
现阶段,刑事诉讼活动当中可以广泛应用声纹鉴定技术实现声音资料的查证等。基于此,本文对面向“互联网+”的声纹识别技术进行了研究,并分析了其在刑事案件侦破中的应用。
1 基于高斯混合模型的声纹识别技术
高斯混合模型(GMM)为最近几年使用的声纹识别方法,该模型实际叠加了不同的高斯分布概率密度函数,对特征矢量在概率空间分布情况进行表述,在声纹识别时,每一个GMM代表一个说话的样本。
1.1 高斯混合模型简介
1.1.1 GMM模型参数描述
基于GMM模型声纹识别技术是针对训练说话者集合内每一说话人对属于自己身份特征概率分布进行构建的模型,说话人自身特征直接影响参数值,所以可以有效描述说话人身份特征。假设说话者概率密度函数形式均相同,但在函数中设定不同参数值,说话人模型此时可看作一组参数值,且符合概率密度分布形式。实证分析表明,说话人特征分布并非是完全的特征分布,然而这些分布近似接近高斯分布混合加权值,高斯混合模型即可得到。具体情况见式(1):
[PXλ=i=1MwibiX, i=1Mwi=1] (1)
式中:[biX]表示单个高斯混合模型的分量,其属于高维高斯分布函数;高维随机语音特征向量用[X]表示;[biX]对应分量加权系数用[wi]表示;在高斯混合模型中,[M]表示分量个数。[biX],[wi]满足式(2):
[biX=expX-utTΣ-1tX-ut22πD2Σt12] (2)
高斯混合模型由协方差矩阵、混合分量均值向量、混合权重共同组成,假定[λ]为参数对模型进行描述,因此,[λ=ωi,ui,Σt,i=1,2,…,n]。
1.1.2 GMM模型参数估计
因每个说话者在声纹识别系统中均由其自身对应的高斯混合模型进行表述。在得到某一说话者训练语音后,通过训练对其模型进行构建。使用高斯混合模型对说话者模型进行构建,实质上是对GMM模型参数值进行估计,常用最大似然估计算法。对于已有[T]个特征向量[t=1,2,…,T],通过极大似然估计原理对其模型参数值进行确认。参数要使[T]个平均概率获得最大值,即对数似然函数[L]最大,见式(3):
[log pXλ=t=1Tlog pxtλ] (3)
基于最大似然准则,即ML估计GMM参数值,通过EM迭代算法进行计算,可获得模型均值[u′i],权重[w′i],方差[σ][′2i]的计算公式,具体如下:
[w′i=1nj=1npixj,λ]
[u′i=j=1nxjpixj,λj=1npixj,λ] (4)
[σ][′2i=j=1nxj-u′i2pixj,λj=1npixj,λ]
式中:[pixj,λ]表示第[i]个混合分量后验概率,参数集合及似然函数[pxλ]间包含一种比较复杂的非线性函数关系,通过常规方法不容易找到极大点。参数值[λ]可通过EM算法进行迭代求取。EM算法是从初始化模型开始,估计获取一新模型参数[λ],且满足[pxλ≥pxλ]。
1.1.3 模型参数初始化
在获取GMM模型前,对模型参数进行初始化,在构建高斯混合模型时,初始化算法包括[K]均值算法、随机初始化算法。[K]均值算法主要使用样本先验概率分布知识,效果较好,本文选择均值算法对GMM模型参数进行初始化。对语音数据进行规整,同时得到满足方差最小标准的[K]个聚类。
算法实现流程如下:
1) 对不同样本进行划分,形成[k]个互不相交子集,通过计算获得每个子集均值[m1,m2,…,mk]及[Je],且第[i]个子集有[N]个样本点,假定第[i]个子集为[Si],其中,[N=i=1kNi],[mi=1Nx∈Six],[Je=i=1kx∈Six-mi2],[Je]表示误差准则,其表示[k]个聚类中心[m1,m2,…,mk],[k]个样本子集[S1,S2,…,Sk]可形成总平方误差,准则下最优结果及误差平方使[Je]极小聚类;
2) 随机进行一个样本[x]的指定,使[x∈Si];
3) 如果存在[M=1],则转向步骤2),否则继续;
4) 计算[ρj]值:
[ρj=NjNj+1x-mj2, j≠iNjNj-1x-mj2, j=i] (5)
5) 对于每一个[j=1,2,…,k],如果有一个[tt≠i]存在,使得[ρt<ρi],则将[x]由[Si]转换到[St]中;
6) 再次計算[mj],[mt],同时对[Je]进行修改;
7) 若[Je]在几次迭代中无改变,则运算停止,否则转到步骤2)。
在EM算法初始化运算时,通过[k]均值算法可将EM算法迭代速度提高,尤其是对于聚类海量数据则具有更加显著的效果。
1.1.4 基于GMM的说话人确认
在进行基于GMM的声纹确认时,进行语音前端处理,并对特征进行提取,在训练时,使用训练语音特征进行GMM声纹模型的构建。测试时,让测试语音特征参数和已知身份的声纹模型进行匹配,并获得一个相似度评分,由某话者模型对语音向量[O]进行测试,并将概率评分[pλO]输出,通过此评分和阈值比较对确认结果进行获取。[pλO]为GMM模型输出概率,因[pλO]无法通过计算获取,可将声纹确认看作是一个假设检验问题,也就是对测试语音而言,其是目标说话人(H0)获冒认者(H1)中的一个进行选取,说话人确认中评分算法采用似然比。似然比是在冒认者模型输出的概率中,由目标说话者模型输出的待识语音[O]概率所占比值。参数表征目标说话人模型为[λ],参数表征冒认者模型为[λH1];在模型[λ]中,[pOλ]表示待识语音参数向量[O]输出概率;在[λH1]条件下,[pOλH1]表示待识语音参数向量[O]输出概率,因此似然比为[LO=][pOλpOλH1],通常使用对数似然比方法,记为[LO=logpOλpOλH1=]
[log pOλ-log pOλH1]。
本研究将时间归一化方法应用到对数似然比式中,这样语音长度对似然比函数的影响可削弱,具体通过公式[LO=1Tlog pOλ-log pOλH1]实现,其中,[T]表示测试语音长度或帧数。对数似然可使不同说话人间的可区分性增多,输出评分分布动态范围得到削弱,声纹确认系统对阈值可依赖性减小。
1.2 高斯混合通用背景模型
1.2.1 模型提出
高斯混合模型存在不足,相对而言,高斯混合通用背景模型(GMM?UBM)使用性能比较优良,可实现声纹识别。用户在现实应用中提供的训練语料有限,通常情况下,训练不能太充分。因而,不能将GMM模型高斯混合数目取很高,但在识别过程中,对混合度要求比较高;在训练过程中,UBM需要的背景语音量比较大,因而可获得充分训练,获得的混合量比较高。在说话人模型自适应时,可对UBM中同训练语音特征少量的相似高斯分量部分进行修改,因UBM由大量背景语音训练得到,通常情况下,其能很好地将冒充者的平均特征分布情况反映出来,因此,GMM?UBM能对用户集合外的语音进行较好适应。
在声纹识别过程中,关键步骤是选择阈值。在GMM?UBM模型匹配之中,目标说话人模型和UBM得分的比值形式是输出的结果,因而比值形式可大幅削弱最终似然函数评分对阈值选择的影响。在一定程度上,GMM?UBM的判别性能更优秀。
1.2.2 基于GMM?UBM模型的声纹识别系统
目标说话人模型在基于GMM声纹确认系统中通常仅由目标说话人自身训练语料获得,当目标说话人训练数据较少时,说话人模型参数估计准确性则较差。在将自适应算法引入构建目标声纹模型后,根据待测目标说话者训练语料,通过背景模型(UBM),利用最大后验概率算法,经过自适应训练可得到目标说话人声纹模型,这就是GMM?UBM声纹识别系统原理。
实际上UBM属于一个庞大的GMM模型,其训练语料为各信道条件全部不同待辨识说话人的语音,可对与所有说话人均无关的语音特征空间分布进行训练描述。通过最大后验概率算法,GMM?UBM模型训练参数由UBM自适应得到,这可节约训练时间,将训练效率提高。该自适应方法分两步:第一步是在UBM中,对目标说话人及每一个混合成分训练语音统计分布进行估量计算;第二步是用一个语音数据集,将与新充分估计及旧充分估计相关的混合系数进行结合。调整UBM的各不同高斯分量,使其偏向训练向量方向,默认目标说话人的训练数据[X=x1,x2,…,xT]和初始化GMM模型参数,通过计算,获得训练向量概率分布状况,即式(6)所示的第[i]个混合分量:
[Prixt=wipixtj=1Mwjpjxt] (6)
然后通过[Prixt]、平均向量值、混合加权量、方差进行统计:
[ni=t=1TPrixtEix=1nt=1TPrixtxtEix2=1nit=1TPrixtx2t] (7)
最终将全部由训练数据获得的新充分统计数据量进行UBM更新,其第[i]个混合数据充分统计量为:
[wi=awiniT+1-awiwiγui=amiEix+1-amiuiσi=aviEix2+1-aviσ2i+u2i-u2i] (8)
式中:自适应系数为[awi,ami,avi],用于维持旧的、新的估计值间的平衡,用来控制平均值、权重大小、方差。定义[aρi=nini+rρ,ρ∈w,m,v]为自适应系数,其属于一个参数固定不变的因子。在GMM?UBM系统中,[awi=ami=avi=nini+r],其中,[r]=16。
2 声纹识别技术及其在刑事案件侦破中的应用
数字声纹识别技术应用于刑事案件侦破工作需满足一定条件,在实现声纹采样前,需排除周围嘈杂环境,确保录音环境的稳定,录音采样方式分为两种,分别是自由交谈和听说。前一种方式在使用过程中,要求对方不知情,否则将会大大影响发音效果;后一种方式在使用时,要引导对方所说的语句与样本相同。
在鉴定之前,需要完成相应的案件检材审查环节,确保语音是连续稳定的。没有剪辑的检材必须通过滤波处理,从而实现语音信号的加强,同时,要保证声纹鉴定基础资料质量合格,数量足够。因此,要建立犯罪情报系统语音库,完成语音信息准确资料搜集。
在侦查诬陷、绑架、敲诈案件时,需对未知说话人性别、身高、年龄、体态等信息利用语音人身识别技术进行推断,刻画嫌疑人特征,缩小范围。分析未知说话人的声学特征,对其出生地、文化水平以及长住地等进行推断确认。
2.1 实验系统测试环境
在本研究中,北京瑞泰创新公司生产的ICETEK?DM6437?B?KIT为系统测试硬件;美国TI公司生产的TMS320DM6437为主芯片;仿真设备为ICETEK?XDS560USB仿真器、5 V直流电源、TIXDS560连接电缆、USB连接线;显示器为ICETEK?5100TFT;Microsoft Windows XP Professional为PC机平台操作系统,内存为3.25 GB,主频为3.0 GHz。
2.2 实验数据及系统描述
本次实验选取某男子监狱和女子监狱犯罪人员各50名,分别建立GMM?UBM,GMM两个声纹识别系统,特征参数提取为:预加重为1-0.95z-1,FFT点数为256,加窗为汉明窗,帧移为32 ms,帧长为32 ms,滤波器组及个数为梅尔三角滤波器(24个),特征向量为39维(13mfcc,13△mfcc,13△△mfcc)。在实验中,在不同条件下选取GMM混合数两个系统的识别率,实验中所用高斯混合度分别为4,8,16,24,32,保持其他参数不变。
2.3 实验结果与分析
加汉明窗处理图如图2所示,由图2可知,在进行语音信号加窗后,在语音信号上,信号很长的一段语音被窗函数平滑滑动分成帧。在每次进行处理时,分析后再取下一段数据进行分析。
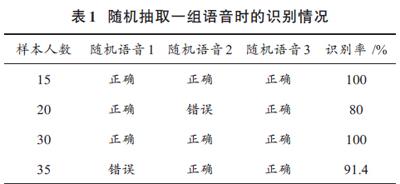
本文采用随机背景下电话通道录音对语音进行测试,如果改变训练样本人数,使其数值分别为15人、20人、30人、35人时,通过三次随机抽取的方式处理测试样本,最终得到的测试结果如表1所示。
当样本人数分别为15人、20人、30人、35人时,测试结果见表2。
表2 选取不同人数时的识别情况
[样本人数 识别正确次数 识别率 /% 15 15 100 20 19 95 30 24 83.3 35 28 80 平均 89.6 ]
在测试随机抽取的一组语音时,系统均具有较高的识别成功率,在进行不同人数测试时,随着样本人数的增加,系统识别率会有少许降低,但平均识别率较高,为89.6%,因此,系统识别率总体上比较理想。
表3为不同混合度两个系统的识别率,由表3可知,在其他条件相同,高斯混合度不同时,与GMM系统相比,GMM?UBM系统具有较高的识别率。随着混合度的增加,GMM系统识别率随之减小,而GMM?UBM系统识别率随之增大。
3 结 论
本文对面向“互联网+”的声纹识别技术进行研究,并分析了其在刑事案件侦破中的应用,得出如下结论:
1) 基于GMM?UBM声纹识别确认系统,对GMM?UBM模型构建方法进行详细描述,研究模型参数最大后验概率算法、估计期望最大化算法、参数训练和识别过程。
2) 对基于GMM?UBM的声纹识别系统进行设计,利用对比实验的方法,分别验证在相同条件下GMM建模方法、GMM?UBM建模方法的识别效果。
3) 在测试随机抽取的一组语音时,系统均具有较高的识别成功率,在进行不同人数测试时,随着样本人数的增加,系统识别率会有少许降低,但平均识别率较高,为89.6%;与GMM系统相比,GMM?UBM系统具有较高的识别率,随着混合度的增加,GMM?UBM系统识别率随之增大。
参考文献
[1] 赵成辉,杨大利.基于声纹识别技术的移动通信监听方案[J].北京信息科技大学学报(自然科学版),2015,30(1):59?65.
[2] 刘弘胤.AI赋能下的声纹识别技术在公共安全领域的深度应用[J].中国安防,2019(6):60?64.
[3] 丁冬兵.TL?CNN?GAP模型下的小样本声纹识别方法研究[J].电脑知识与技术,2018,14(24):177?179.
[4] 田秀丽,黄永平.关于语音个人身份优化识别建模仿真研究[J].计算机仿真,2016,33(10):403?408.
[5] 司向军.基于Android的声纹识别和语音识别的设计[D].南京:东南大学,2017.
[6] ZWEIG G. Speech recognition with segmental conditional random fields [J]. Optical engineering, 2016, 5(6): 177?182.
[7] 于娴,贺松,彭亚雄,等.基于GMM模型的声纹识别模式匹配研究[J].通信技术,2015,48(1):97?101.
[8] NODA K, YAMAGUCHI Y, NAKADAI K, et al. Audio?visual speech recognition using deep learning [J]. Applied intelligence, 2015, 42(4): 722?737.
[9] 曹海涛.基于时频域分析的音频信号滤波与识别技術研究[D].广州:广州大学,2016.
[10] 叶勇.汉语语音识别系统中关键词检测技术的研究[D].北京:北京邮电大学,2015.
