基于云计算的数据挖掘聚类算法研究
2020-06-15杨丽君
杨丽君
(新疆工程学院信息工程学院,乌鲁木齐 830091)
0 引言
云计算作为新一代数据处理与存储技术,实现了数据的快速处理与移动应用[1]。由于海量的数据信息深度挖掘问题已经成为一个急需解决的难题,因此,设计了一种基于云计算的数据挖掘聚类算法。数据挖掘聚类指的就是尽可能复用前人已经完成的人工识别工作,从而提高工作效率。解决形式上的数据挖掘聚类问题并不困难,最简单直接的办法就是为各种基本数据格式两两之间开发一个转换器,因为流行的数据格式数量不多,并且转换规则明确,这是一个只要投入一定人力就能解决的问题[2]。但语义上的数据挖掘聚类比较复杂,因此,本文进行基于云计算的数据挖掘聚类算法研究。
1 基于云计算的数据挖掘聚类算法研究
考虑到传统的数据挖掘聚类算法已经不能满足对海量数据高效、准确挖掘聚类的要求[3]。因此,利用云计算数据库来存储数据并对这些数据进行智能挖掘成为需要重点研究的课题。在基于云计算的数据挖掘聚类算法研究中,首先,确定数据挖掘聚类的白化权函数,进而实现基于云计算的数据挖掘聚类。
1.1 确定数据挖掘聚类的白化权函数
白化权函数作为基于云计算的数据挖掘聚类算法中最重要的指标,必须确定数据挖掘聚类的白化权函数才能保证基于云计算的数据挖掘聚类算法的准确性。本文采用这种方法确定数据挖掘聚类的白化权函数。设确定数据挖掘聚类的集合为数据挖掘聚类的白化权函数的计算公式为:
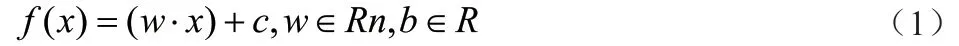
在公式(1)中,w、c为数据挖掘聚类的压缩函数,f(x)为未知参数,但均为实数。为数据挖掘聚类的向量、和输入数据挖掘聚类向量x的点积。根据数据挖掘聚类的概率质量函数最大值与最小值削减和合并结果调整聚类中心数目,当聚类中心数目保持稳定或满足迭代结束条件时停止计算。
1.2 实现基于云计算的数据挖掘聚类
根据数据挖掘聚类的白化权函数的确定,选择一个可以准确评价基于云计算的数据挖掘聚类算法的指标。在数据挖掘聚类迭代过程中,随着聚类中心的数目不断减少,各个聚类中心的位置也会随之发生变化。必须运用云计算技术建立数据挖掘聚类数据库,将聚类中心的位置整合数据的形式存储在数据库中。运用云计算技术建立的数据库是对海量数据挖掘聚类的集成与管理,将大量类型相同的海量数据挖掘聚类构成同构数据库。再通过数据挖掘聚类迭代过程不断地位移,最后剩下的聚类中心的坐标就已经能够非常接近真实的聚类中心。基于云计算的数据挖掘聚类算法可以最大限度的提高数据挖掘聚类覆盖率,实现基于云计算的数据挖掘聚类。
2 仿真实验
2.1 实验准备
为验证基于云计算的数据挖掘聚类算法的有效性,通过对比实验的方法对比基于云计算的数据挖掘聚类算法与传统的数据挖掘聚类算法的聚类覆盖率,设置传统的数据挖掘聚类算法为对照组。将集成化数据均衡分组,选用25台计算机构成并行计算环境,为确保实验的公正性,所选用的服务器处理器统一为IntelCBR1S350,主频为1.98GHz。
2.2 实验结果分析与结论
根据上述设计的仿真实验,统计实验结果,如下图1所示。
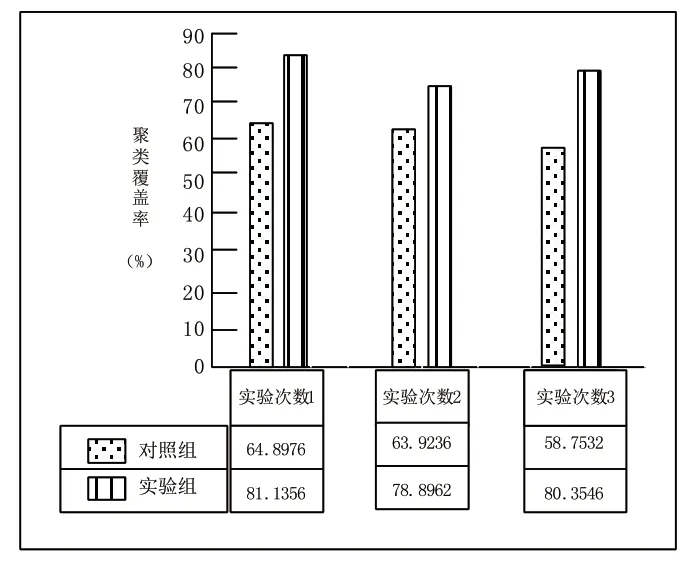
图1 数据挖掘聚类覆盖率对比图
通过图1可得出如下的结论,本文设计的基于云计算的数据挖掘聚类算法的聚类覆盖率高于传统的数据挖掘聚类算法,可以实现数据挖掘聚类。
3 结束语
随着云计算环境下计算机联网的逐步实现,数据挖掘的聚类问题显得越来越重要。基于云计算的数据挖掘聚类算法是针对数据挖掘进行聚类的最实用和最可靠的方法。针对基于云计算的数据挖掘聚类算法的研究可以大幅度提高数据挖掘的聚类覆盖率,完成传统的数据挖掘聚类算法所不能完成的任务。基于云计算的数据挖掘聚类算法是数据挖掘聚类的核心技术,为数据挖掘聚类提供学术意义。
