自注意力机制的短文本分类算法
2020-06-12杨文忠袁婷婷马国祥
姚 苗,杨文忠,+,袁婷婷,马国祥
(1.新疆大学 软件学院,新疆 乌鲁木齐 830046;2.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
0 引 言
随着互联网应用的快速发展,网络文本信息呈现出爆炸式增长的特点。设计一个高效的模型,实现对舆情信息的有效监控变得越来越困难。如何利用文本上下文依赖关系,利用文本中的关键信息,加大对文本局部关键信息的注意力,减少与主题相关性低的句子或词对文本分类性能的负面影响,改善文本分类的效果是目前研究工作的重点与难点。
通过捕获更加充分的上下文依赖关系的文本表示和突出局部关键信息的注意力,本文提出Att-BLSTMs模型。stack Bi-LSTMs网络结构利用文本的上下文信息,通过正向LSTM和反向LSTM的交替传播,可以更好捕获文本上下文的强依赖关系,得到语义特征更加丰富的文本向量。利用自注意力机制,把握文本中的关键信息,使得关键信息权重增加,突出重点,从而更好地进行文本表示,进而达到优化文本分类的精确率的目标。
1 相关工作
文本分类是一个经典的自然语言处理任务。因此,文本分类吸引了学者们的广泛研究兴趣,并且提出了诸多模型。Guo A等[1]提出利用粗糙集将训练集划分成确定领域和不确定领域,对确定领域直接用KNN进行分类,对不确定领域进行依赖分析后采用KNN分类。Bidi N等[2]提出利用遗传算法改进文本分类过程中特征选取过程,从而提高分类的准确率。Lin Y等[3]通过结合KNN算法与SVM算法,通过反馈和改进分类预测概率来提高分类器的性能。Neethu等[4]提出结合K-means算法和极限学习机的文本分类模型。Li Zhenzhong等[5]提出基于LDA主题模型的新闻文本分类算法。上述方法虽然在文本分类准确率上有所提高,但是未曾考虑文本上下文依赖依赖关系,忽略了上下文语义对分类准确率的影响。
近年来,随着深度学习模型在计算机视觉和语音识别的应用上取得了显著的成就。将深度学习的优势发挥在文本分类任务中,提高文本分类的准确率是值得研究的工作。Yoon Kim[6]提出基于卷积神经网络的句子级分类模型,该模型在训练词向量时,利用CNN进行预训练,优化特征表达。Zhang Xiang等[7]提出一种字符级的卷积神经网络模型,与传统词袋模型、n-grams以及基于词的ConvNets模型相比有明显提升,但也存在不足,例如模型性能依赖数据集的大小以及字母表的选择。龚千健[8]提出利用神经网络模型RNN来进行文本分类,有效解决了统计学习方法未能利用上下文信息等缺点。Zhou Peng等[9]提出改进的Bi-LSTM,给Bi-LSTM增加了2D的卷积层和2D的池化层,用Bi-LSTM来捕获句子间的依赖关系,用2D的卷积层和2D的池化层来提取深层特征表达,与RNN、CNN、RecCNN对比,效果有明显提升。Lai Siwei等[10]提出RCNN(recurrent convolutional neural networks)模型,在RNN的变体Bi-LSTM基础上增加max-pooling layer(即最大池化层),Bi-LSTM可以捕获上下文语义信息,利用最大池化层来捕获文本分类中起关键作用的特征。以上方法,CNN和RNN神经网络的模型都可以捕获上下文依赖关系,但是未曾考虑对文本中关键信息的捕获,以及关键信息对文本分类准确率提升的影响。
Li Chao等[11]提出基于统计特征和注意力机制的异常文档检测方法,利用注意力机制计算单词的注意力权重捕获句子中的关键单词。Zhao G等[12]提出结合LSTM和注意力机制方法,对视频中连续语义进行捕获。Bai J等[13]提出基于注意力机制的Bi-LSTM与CNN结合的微博发布位置检测模型,提高了位置检测的准确率。田生伟等[14]针对维吾尔语的事件时序关系识别任务提出利用Bi-LSTM和注意力机制结合的混合神经网络模型,先把文本向量放入Bi-LSTM层,提取一些文本信息,利用注意力机制进行深层文本特征提取。Wang X等[15]提出一种基于情境感知的注意力机制的LSTM模型,利用LSTM学习时间序列的隐藏特征表示,利用时间注意力机制学习每个时隙的重要性权重,达到预测未来的动乱新闻量的目的。上述方法虽然将LSTM、Bi-LSTM与注意力机制结合,从一定程度上捕获了上下文隐藏深层依赖关系,也利用注意力机制对关键信息进行捕获,但是LSTM与Bi-LSTM相比于stack Bi-LSTMs,多层Bi-LSTMs不允许前后向层之间共享信息而stack Bi-LSTMs前后向信息交替传播,有利于捕获更深层次的隐含依赖关系。
2 相关技术
2.1 Bi-LSTM
为了解决传统RNN的长期依赖问题、梯度消失的问题,Hochreiter和Schmidhuber[16]提出了LSTM(long short-term memory)。LSTM的主要思想是引入了自适应的门控机制,来决定LSTM单元保存先前状态的程度和记忆当前输入单元的抽取特征的程度。
LSTM循环神经网络是由3部分组成:带对应权重矩阵Wxi,Whi,Wci,bi的输入门(input gate)、带对应权重矩阵Wxf,Whf,Wcf,bf的忘记门(forget gate)和带对应权重矩阵Wxo,Who,Wco,bo的输出门(output gate),所有门控制机制使用当前输入xi,上一层生成的状态hi-1,以及当前单元的激活值ci-1来决定是否接受输入,是否忘记之前存储的记忆,和输出最后的状态。以下为更新各个门控机制及单元状态的公式
it=σWxixt+Whiht-1+Wcict-1+bi
(1)
ft=σWxfxt+Whfht-1+Wcfct-1+bf
(2)
gt=tanhWxcxt+Whcht-1+Wccct-1+bc
(3)
ct=itgt+ftct-1
(4)
ot=σWxoxt+Whoht-1+Wcoct-1+bo
(5)
ht=ottanhct
(6)
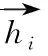
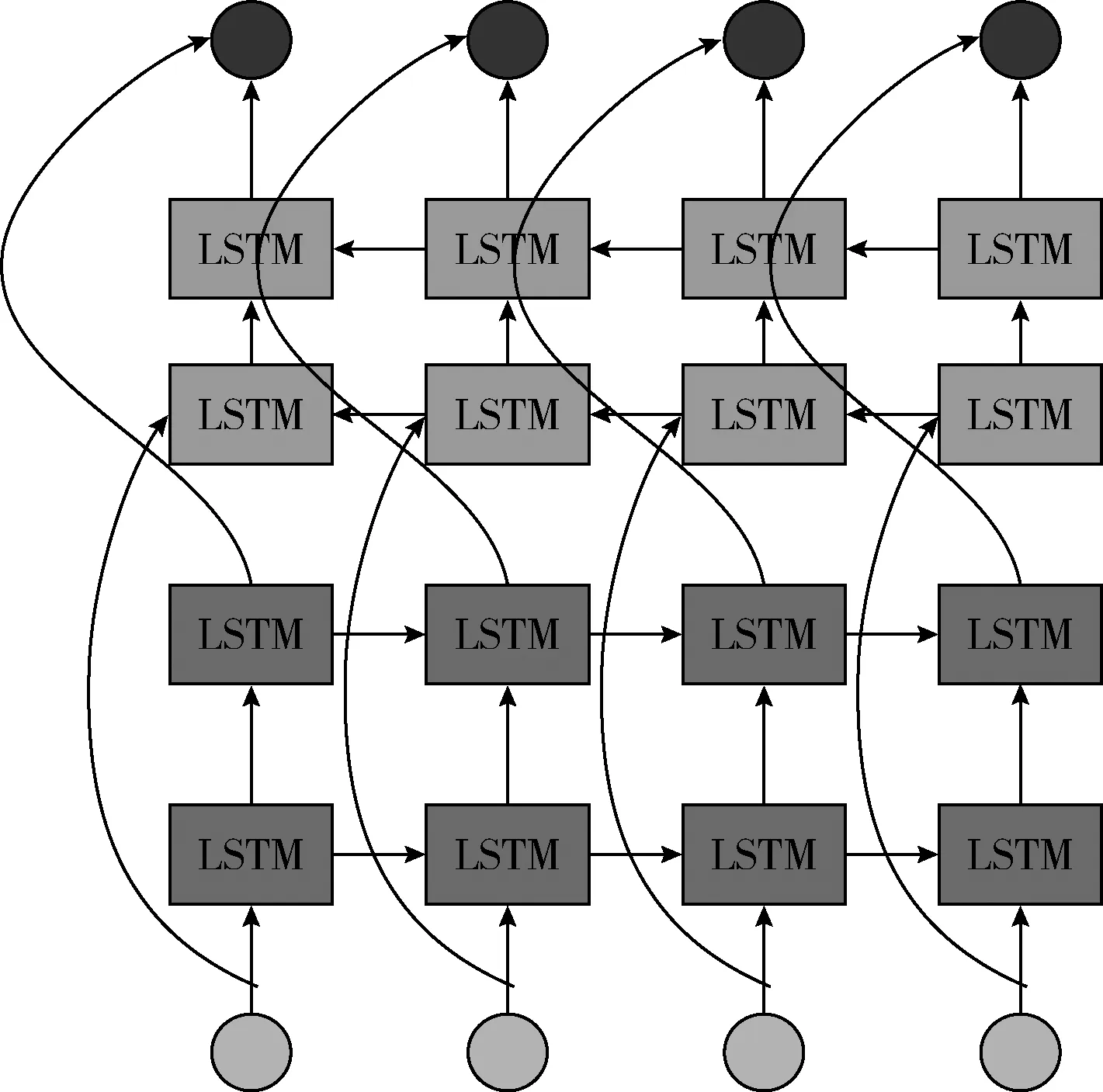
图1 Bi-LSTMs网络结构

图2 stack Bi-LSTMs网络结构
图1中,Bi-LSTMs[17]网络结构不允许在前后向LSTM层之间共享前向和后向信息,多层LSTM时,总是先进行前向LSTM训练,再进行后向LSTM训练。
图2中,stack Bi-LSTMs[17]通过前后LSTM层交替进行训练,增加了前向LSTM和后向LSTM的信息交互,有利于对上下文语义特征信息的捕获,充分发掘上下文语义时序依赖关系。
2.2 注意力机制
注意力机制最初只应用于计算机视觉中的图片识别[18]任务中,人们视觉在感知东西时,通常不会是一个场景从到头看到尾每次全部都看,而往往是根据需求观察注意特定的一部分。当人们发现一个场景经常在某部分出现,人们会进行学习在将来再出现类似场景时,把注意力放到该部分上。随后注意力机制在问答系统[19]、机器翻译[20]、语音识别[21]、图像捕捉[22]上有成功的应用。

M=tanh(H)
(7)
α=softmax(W(3)TM)
(8)
r=HαT
(9)
h*=tanhr
(10)
其中,M∈Rdw×n,H∈Rdw×n,dw是词向量的维度,W(3)是训练得到的参数向量,W(3)T是参数向量的转置。W,α,r的维度分别是dw,n,dw。通过式(10)用一个tanh激活函数得到最终的句子表示h*。
3 Att-BLSTMs模型
Att-BLSTMs模型利用stack Bi-LSTMs来捕获上下文语义特征信息,优化词表示向量,缓解了短文本特征稀疏的问题。利用注意力机制加大文本局部关键信息的注意力,优化了文本表示。模型结构如图3所示。
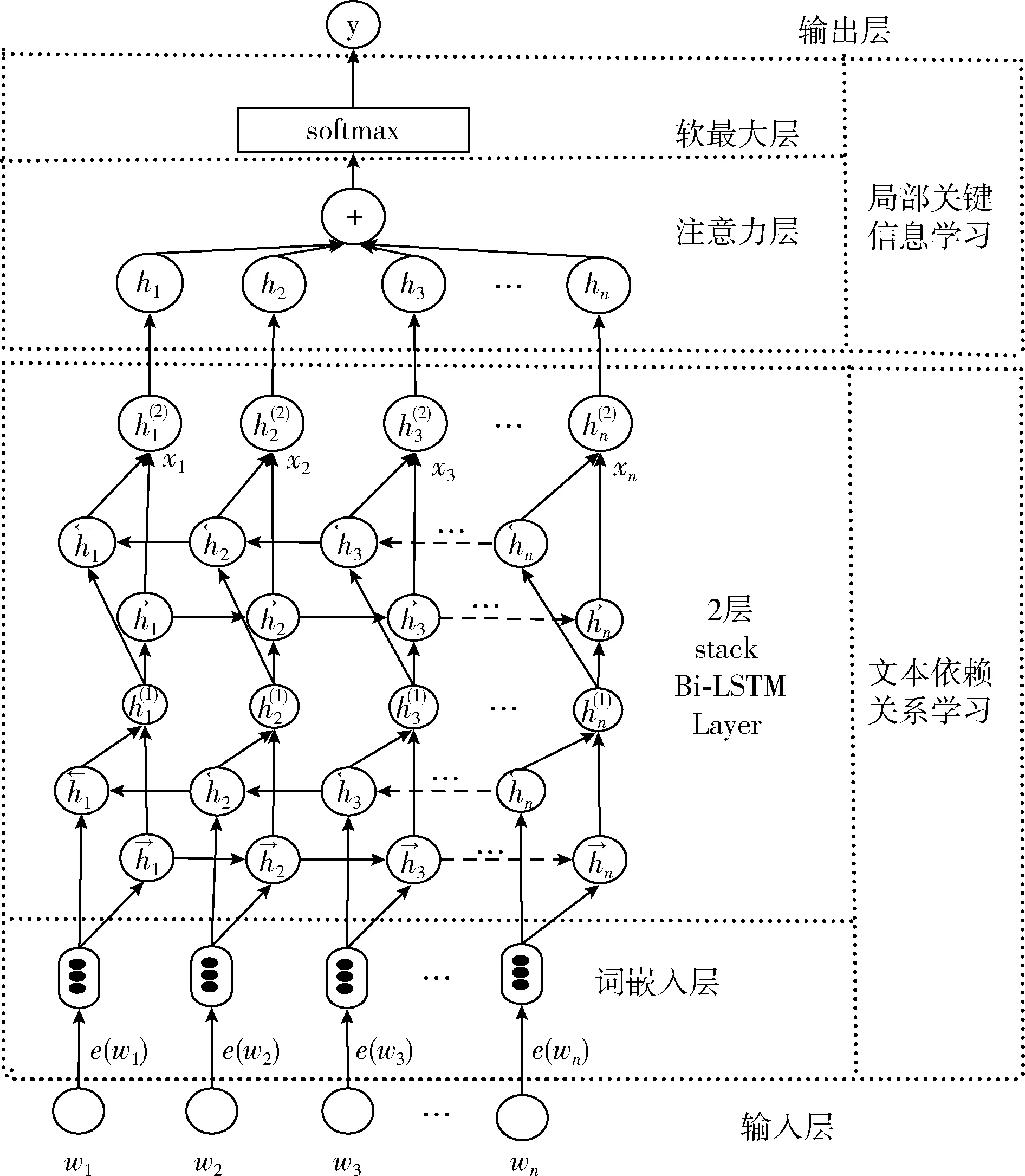
图3 Att-BLSTMs模型结构
如图3所示,模型的输入是文档D,文档D为包含n个单词w1,w2…wn的序列。对输入文档D,进行分词处理,去噪处理。将处理过得文档D,通过Word Embedding预训练生成词向量,将词向量作为stack Bi-LSTMs模型的输入,通过stack Bi-LSTMs对单词上下文语义特征信息进行挖掘后,虽然词向量本身可以捕获一些词与词之间的依赖关系,但是对于一些隐藏的深层次的上下文依赖关系不能很好捕获,而stack Bi-LSTMs通过前向LSTM和后向LSTM交替传播,将上下文信息紧密联系到一起,能够捕获到隐藏的上下文依赖关系,从而来优化短文本语义特征稀疏的问题。然后利用自注意力机制,计算注意力值,增强文档中关键信息的注意力,从而来优化文本表示。模型的输出为文档类别y,本文使用概率pkD,θ来验证文档D属于文档标记类别k的概率,其中θ是模型的训练得到的参数。
3.1 stack Bi-LSTMs的依赖关系学习
在对数据集进行分词、去停用词之后得到词汇表,本文利用Word Embedding技术,将词汇表中的单词映射成由实数构成的向量,从而得到最初的文本表示。在预训练词向量时,利用由Hinton等[24]提出的dropout方法,采用dropout丢失率为0.5随机丢弃部分的特征,防止模型出现过拟合现象。
Word Embedding可以对文本中词向量的简单依赖关系进行捕获,但是对文档中上下文中隐藏的深层语义依赖关系捕获不足。本文采用图2的stack Bi-LSTMs网络结构进行上下文隐含依赖关系捕获。因为一层stack Bi-LSTM在短文本中捕获深层隐含依赖关系效果不明显,所以采用两层stack Bi-LSTMs能突出深层次隐含强依赖关系的捕获。具体利用下面公式进行计算
ewi=W(wrd)vi
(11)
(12)
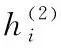
通过利用word Embedding和stack Bi-LSTMs结合的方式,捕获上下文隐含的依赖关系,得到了更加丰富的文本表示向量,缓解了短文本因为字符数少而造成的语义特征稀疏的问题,为更好提高文本分类准确率打下良好的基础。
3.2 结合自注意力机制的关键信息表示学习
Att-BLSTMs模型利用自注意力机制来表示文本。结合注意力机制的处理信息冗余和信息丢失问题的优势,加大对文本关键信息的注意力,从而优化文本表示,强化文本语义特征。
本文利用将文本表示成一系列(键key-值value)对的映射。自注意力捕获关键信息表示如图4所示。

图4 自注意力key-value映射
利用式(7)-式(10),将stack Bi-LSTMs和每个key进行相似度计算,利用softmax函数对得到的权重进行归一化处理,将权重和相应的键值value进行加权求和,得到最终的注意力值。在stack Bi-LSTMs捕获到依赖关系明确的上下文语义依赖关系特征后,利用自注意力机制,加大关键信息的注意力,充分利用了关键信息,从而优化了文本表示,有利于提高文本分类的准确性。
3.3 softmax分类
通过对上下文隐藏依赖关系的捕获和增加关键信息注意力进行优化文本表示后,利用softmax分类器进行文本分类。用softmax分类器将输出值yi转换成概率p(kiD,θ),如式(13)所示
(13)
θ={E,Wxi,Whi,Wci,bi,Wxf,Whf,Wcf,bf,Wxo,Who,Wco,bo}
(14)
E=ew1,ew2,…,ewn
(15)
其中,D为输入文档,θ为模型训练学习到的参数,ki为分类标记,因为本文实验采用数据集包含4个标记类别,所以i∈{1,2,3,4}。模型最后输出p(kiD,θ)概率值最大的类别。
4 实验结果与分析
为了验证本文提出方法的可行性设计了以下实验。实验环境:操作系统为win10,处理器为Intel Core i7,内存8 G,CPU为1.99 GHz,开发工具为PyCharm Community Edition 3.3。
4.1 数据集
本文采用公开数据集AG-news作为实验的语料库。它包含了从2000多个新闻源上选取的496 835篇已经分类的文章。包含4个类别,分别是:World、Sports、Business、Sci/Tech,使用标题和文章内容两个领域,来构建本文实验的语料库。包括110 000条数据作为训练语料,其中验证数据集占30%,使用7058条数据作为测试语料。根据统计显示,类别World包含27 597条语料,Sports包含27 555条语料,Business包含27 515条语料,Sci/Tech包含27 333条语料。从统计数目上,可以看出在训练语料中4个种类的新闻条数分布均匀。根据统计显示,本文使用训练语料库AG-news平均每篇文档包含34个单词,认定属于短文本。
本文采用公开DBpedia分类数据集是通过从DBpedia 2014中挑选14个非重叠类来构建的。包括Company、Educational Institution、Artist、Athlete、Office Holder、Mean Of Transportation、Building、Natural Place、Village、Animal、Plant、Album、Film、Written Work。每个类别随机选择40 000条训练语料,选择5000条作为测试语料。训练数据集的总大小为560 000条,测试数据集为70 000条。
4.2 实验设计
为保证实验结果的稳定,所有实验均将样本数据随机打乱作为模型的输入。采用微平均的F1值和宏平均的F1值作为模型的评价指标。
(1)模型参数
本次模型的参数设置见表1。
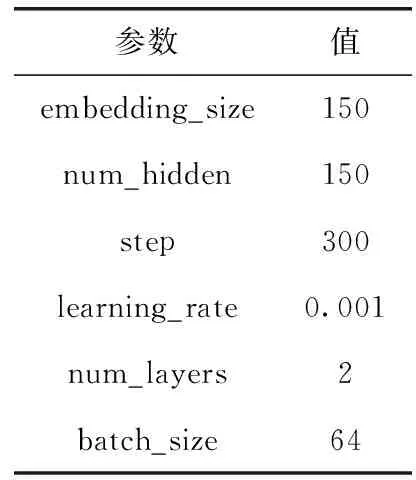
表1 模型参数
其中,embedding_size为词向量的维度,step是指模型训练达到最优的迭代次数,num_hidden为Bi-LSTMs的隐藏层节点数,learning_rate为学习率,num_layers为Att-BLSTMs模型中Bi-LSTMs的层数,batch_size为单次迭代训练批处理样本的个数。
(2)embedding_size的取值对实验性能的影响
不同维度的词向量所蕴含的语义信息不同,理论上词向量维度越大所蕴含的语义信息就越多。在AG-news数据集中,下面对embedding_size取值为50维、100维、150维、200维进行实验,实验结果见表2。
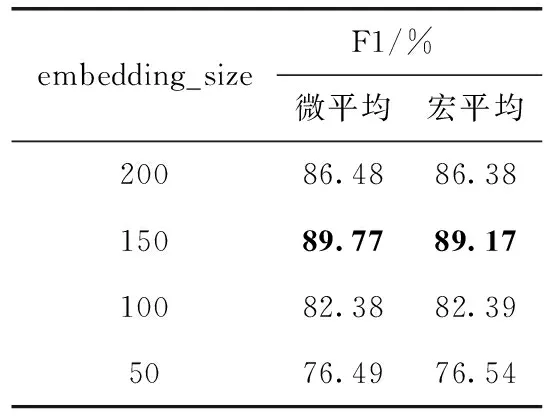
表2 embedding_size与模型性能的关系
从表2可以得出,当词向量维度为150维时,模型性能达到最优,此时微平均的F1值和宏平均的F1值分别为89.77%、89.17%。但当词向量维度增大到200维时,模型性能相比维度为150维时,微平均的F1值下降了3.29%,宏平均的F1值下降了2.79%。这是因为词向量维度过高,虽然表达了更多的语义信息,但是其中也包含了一些噪声,模型出现了过拟合的现象,从而导致模型的泛化性能下降。
(3)learning_rate的取值对实验性能的影响
学习率控制模型的学习进度,直接影响着模型训练达到最优的效果。在AG-news数据集中,下面对learning_rate的常用取值0.0001、0.0003、0.001、0.003、0.01进行实验,实验结果见表3。

表3 learning_rate与模型性能的关系
从表3得知,当learning_rate为0.001时,模型性能达到最优。但是当学习率增大至0.01时,模型性能相比学习率为0.001时,评价模型性能的微平均F1值下降了7.1%,宏平均F1值下降了6.58%。由于学习率太大,导致训练过程中跨过最优值,长时间无法收敛,造成模型无法达到最优性能。而当学习率降低至0.0001时,评价模型性能的微平均F1值下降了8.69%,宏平均F1值下降了8.07%。这是因为当学习率过小时,模型容易陷入局部最优,而达不到在全局范围内的最优性能。
(4)num_layers的取值对实验性能的影响
Att-BLSTMs模型中,深度神经网络的层数与模型的复杂程度直接相关,反映了模型对数据的拟合程度。在AG-news数据集中,下面对超参数num_layers的取值为1层、2层、3层进行实验,实验结果见表4。
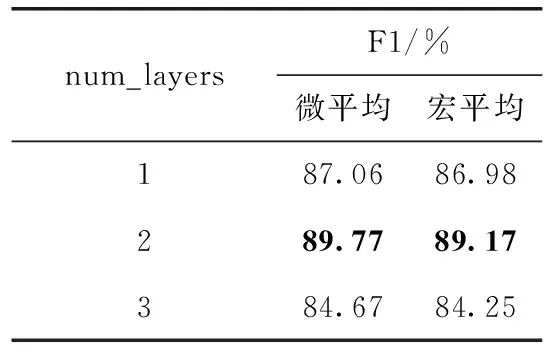
表4 num_layers与模型性能的关系
由表4可知,当Att-BLSTMs模型的num_layers取值为2层时,模型的性能达到最优。与层数为3层相比,评价模型性能的微平均F1值下降了5.1%,宏平均F1值下降了4.92%。这是因为在数据集不变的情况下,模型层数增加,模型复杂程度提高,出现过拟合现象,使得模型在测试数据集上泛化能力降低。与层数为1层相比,评价模型性能的微平均F1值下降了2.71%,宏平均F1值下降了2.19%。这是因为模型层数减少,模型出现欠拟合现象,从而导致模型的泛化能力下降。
(5)Att-BLSTMs与其它模型的实验性能对比
在AG-news网页新闻数据集和DBpedia分类数据集上,将本文提出的Att-BLSTMs方法与LSTM模型和变体Bi-LSTM模型进行对比实验,与CNN模型以及LaiSiwei等[14]提出了RCNN模型进行对比实验,结果见表5。
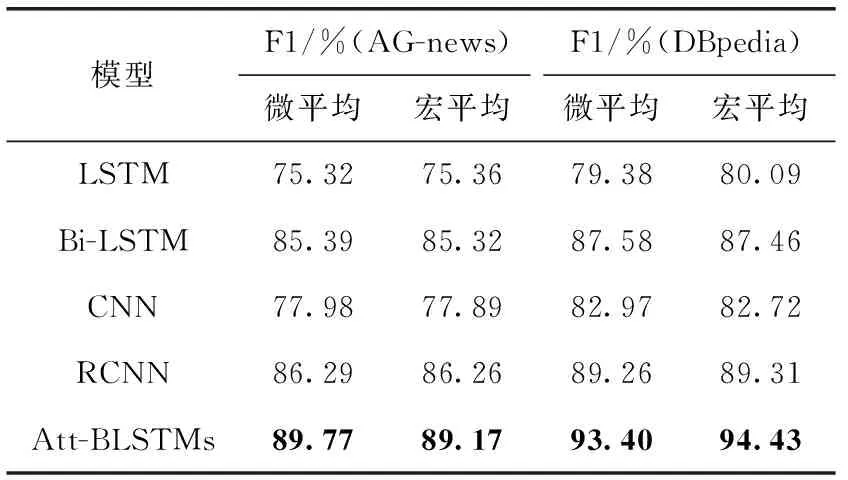
表5 Att-BLSTMs与其它模型对比
由表5可知,在AG-news网页新闻数据集和DBpedia数据集上,LSTM和Bi-LSTM模型相比,Bi-LSTM模型在文本分类任务中的性能优于LSTM模型,这是因为Bi-LSTM模型在LSTM基础上增加了一个反向LSTM。正向LSTM用于捕获上文特征信息,反向LSTM用于捕获下文特征信息,然后将上下文特征信息相加,从而可捕获文本全局上下文信息,因而扩展后的Bi-LSTM模型在文本分类上的性能要优于LSTM模型。Att-BLSTMs模型与Bi-LSTM模型相比,Att-BLSTMs模型,结合了stack Bi-LSTMs和自注意力机制的优点,利用2层stack Bi-LSTMs模型前向LSTM捕获上文特征信息,后向LSTM捕获下文信息交替传播,利用自注意力机制加大关键信息语义特征表达,因而,Att-BLSTMs模型要优于Bi-LSTM模型。
由表5可知,在AG-news网页新闻数据集和DBpedia数据集上,CNN与RCNN和Att-BLSTMs相比,在文本分类任务中反映模型性能的微平均F1值和宏平均F1值均有所下降,这是因为CNN模型利用局部卷积思想,虽然能够捕获文本序列的局部特征,但是缺乏了对全局上下文信息的考虑。而RCNN和Att-BLSTMs模型则可以捕获全局上下文隐藏依赖关系特征。RCNN模型利用最大池化原理来突出关键特征表达。Att-BLSTMs模型,用stack Bi-LSTMs来捕获全局隐藏依赖关系信息,结合自注意力机制来进一步挖掘关键信息,所以CNN在性能上要低于RCNN模型和Att-BLSTMs模型。RCNN模型与Att-BLSTMs模型相比,在RCNN模型中CNN用来进行文本表示,只是利用一层最大池化层来找到文本中最关键的语义信息,具有局限性,并且未曾考虑加大关键信息的注意力,而自注意力机制不仅能很好表达文本,而且可以加大关键信息的注意力。因而,Att-BLSTMs模型的整体性能优于RCNN模型。
由表5可知,在DBpedia数据集中各个模型微平均F1值和宏平均F1值都要优于在AG-news数据集中验证的结果。分析原因为:DBpedia数据集中各个类别的语料更加丰富,并且DBpedia是从维基百科的词条里撷取出结构化的资料,便于模型处理。
5 结束语
本文针对目前的短文本分类算法没有综合考虑文本中隐含的依赖关系和局部关键信息这一问题,利用深度学习的方法,提出了一种结合自注意力机制的stack Bi-LSTMs模型。该模型可以很好捕获上下文隐含的依赖关系特征信息,并且加大对文本关键信息的注意力,从而提高了文本分类的准确性。在AG-news网页新闻数据集和DBpedia数据集上,实验结果表明了Att-BLSTMs模型从性能上优于LSTM模型、Bi-LSTM模型、CNN模型及RCNN模型。下一步将把该模型应用到突发事件内容的演化和跟踪任务上,从而有利于政府对突发事件的内容进行良好的分析,达到对突发事件演化进行有效监控的目标。
