基于烟花算法优化极限学习机的温室参考作物蒸散量预测研究
2020-06-12魏正英张育斌冯培存贾维兵
张 千,魏正英,张育斌,冯培存,张 磊,贾维兵
(1.西安交通大学机械工程学院,西安 710049;2.西安交通大学机械制造系统工程国家重点实验室,西安 710049)
0 引 言
灌水量是农业从业人员在农田灌溉过程中需要考虑的一个重要内容,灌溉量的多少对灌区水资源的合理分配以及灌区整体收益有着很大的影响。参考作物蒸散量ET0是计算作物需水量的重要依据,目前有很多估算ET0的方法[1],包括Penman-Monteith(P-M)法、Hargreaves法、Hargreaves校正法、Irmark-Alleen和Prisetley-Taylor法等,其中P-M法被联合国粮农组织(FAO)确定为参考作物蒸散量估算的标准方法[2],该方法以能量平衡和空气动力学为基础,综合考虑大量气象数据,计算结果较为准确,目前被广泛使用。国内外许多学者进行了多种工况下使用该公式进行参考作物蒸散量的计算的研究,相当一部分学者给出了该公式的修正模型,李振华等建立了基于自然气象条件下的逐时Penman-Monteith公式,对其空气动力项进行了修正,得到适合计算温室ET0的公式[3];张晓萍等使用聚类分析和下垫面参数对Penman-Monteith公式进行了优化,提高了公式在黄河中游地区的参考作物蒸散量计算精度[4]。但在实际使用过程中,Penman-Monteith公式需要使用大量的气象参数,完整气象数据难以获取造成该模型实时使用较为困难[5]。
随着现代农业的发展,信息技术广泛应用于农业,越来越多科研工作者将机器学习应用于农业信息的研究。王升等建立了基于随机森林和基因表达式编程算法的ET0预测模型,获得了较高的预测精度[6];张育斌等建立基于耦合模拟退火优化最小二乘支持向量机的参考作物蒸散量的预测模型,获得了阶段ET0和总ET0都较好的预测结果[7];周瑞等利用粒子群算法优化广义回归神经网络,并以此建立了参考作物蒸散量的预测模型,该模型在气象数据缺失情况下依然具有较好的预测精度[8];冯禹等建立基于极限学习机的ET0预测模型,获得了川中丘陵地区蒸散量较好的预测结果[9]。然而使用机器学习进行数据预测时需要的数据量较大,在数据量较少的情况下预测精度较低[10]。
本文提出了一种烟花算法优化极限学习机(FWAELM)预测参考作物蒸散量(ET0)的方法,该方法使用烟花算法对极限学习机的输入权值矩阵和偏置矩阵进行寻优,解决了极限学习机在小样本数据情况下预测精度较低的问题,并将预测结果与极限学习机的预测结果进行对比,实验表明,该模型获得了较高的预测精度。
1 研究方法
1.1 作物参考蒸散量
在本研究中,采用P-M模型的计算结果作为FWAELM的学习数据以及评价标准,其公式为:
(1)
式中:ET0为参考作物蒸散量,mm/d;Δ为饱和水压-温度曲线的斜率;Rn为作物表面净辐射,MJ/(m2·d);G为土壤热通,MJ/(m2·d);γ为温度表常数;T为2 m高处日平均温度,℃;μ2为2 m高处平均风速;es为饱和水汽压;ea为实际水汽压。
1.2 极限学习机
极限学习机是黄广斌于2004年提出的一种单隐含层神经网络,是一种基于前馈神经网络的机器学习算法[10]。传统神经网络在训练过程中通过梯度下降法来不断调整输入权值和输出权值,存在训练时间长、容易陷入局部最优解等问题。极限学习机可以随机初始化输入权值矩阵和偏置矩阵,通过计算得到相应的输出矩阵,并得到唯一解,从而使得极限学习机能够做到在保证学习精度的前提下获得更快的学习速度,具有更好的泛化效果。极限学习机的网络结构如图1所示。

图1 极限学习机网络结构Fig.1 Network structure of extreme learning machine
该算法具有三层结构,分别为具有j个输入神经元的输入层、n个隐含神经元的隐含层和1个输出神经元的输出层。给定一组样本数据(xi,ti),其中xi=[xi1,…,xin]T∈Rn,ti=[ti1,…,tim]T。对于图1具有n个隐含神经元的极限学习机,其网络结构可以表示为:
(2)
式中:j=[1,2,…,n];βi=[β1,β2,…,βn]为输出权重矩阵;g(x)为激活函数;ωij为输入权重;bi为隐含神经元的阈值;oj为极限学习机的输出结果。数据拟合回归算法的学习目标是要使得输出结果与真是值误差最小,即:
(3)
也即存在βi、ωij和bi,使得:
(4)
转换为矩阵表示为:
Hβ=T
(5)
式中:H为隐含节点的输出;β为输出权重;T为期望输出,即可求出极限学习机的输出矩阵为:
(6)
式中:H+为H的Moore-Penrose广义逆,求出输出权重即可根据式(2)求出极限学习机的输出值。
1.3 烟花算法
烟花算法(FWA)由谭营受到烟花爆炸启发提出的一种群体智能算法,通过模拟烟花在空中爆炸的行为建立数学模型,引入随机因素和选择策略形成一种并行爆炸式搜索,进而演化成为一种能够求解复杂问题最优解的全局概率搜索方法[11]。烟花算法主要包含以下几个部分:
(1) 爆炸算子。烟花算法对初始化随机产生的N个烟花应用爆炸算子,产生新的烟花,主要包括爆炸强度[式(7)],爆炸幅度[式(8)]和位移操作[式(9)]3个操作,爆炸强度确定烟花爆炸差生的火花数量,爆炸幅度确定烟花爆炸的范围大小,位移操作确定烟花在爆炸范围内的位移。
(7)
(8)
(9)
式中:Si为第i个烟花产生的火花个数;m为限制火花总数的常数;Ymax为种群中适应度最差的个体的适应度值;f(xi)为个体xi的适应度值;ε为防止出现零分母的极小常数;Ai为第i个烟花的爆炸范围;A′为常数,表示最大爆炸幅度;Ymin为种群中适应度最好的个体的适应度值
(2) 变异算子。变异算子能够提高种群的多样性,可以避免局部极值点,以达到全局最优。这里使用的是高斯变异。
(10)
式中:g服从均值和方差均为1的高斯分布,即g~N(1,1)。
(3)选择策略。烟花爆炸后需要在产生的火花中选择满足要求的火花作为下一代烟花,选择策略使用基于距离的选择策略,即采用欧式距离[式(11)]度量两个个体之间的距离,采用轮盘赌[式(12)]的方式选择个体:
(11)
式中:K为爆炸后产生的火花位置集合。
(12)
烟花算法的流程如图2所示。
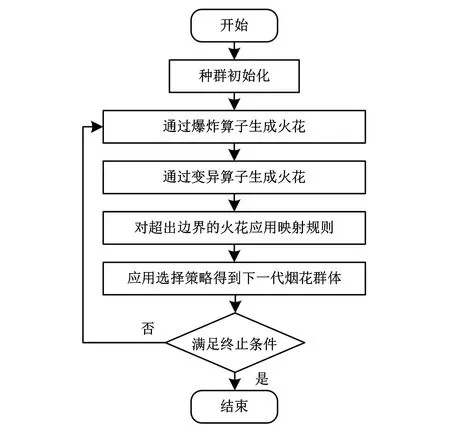
图2 烟花算法流程图Fig.2 Flowchart of fireworks algorithm
1.4 烟花算法优化极限学习机
本文中使用数据通过极限学习机进行拟合回归存在以下问题[13]:
(1)由于极限学习机输入矩阵及偏置矩阵随机产生,导致输出结果出现数据波动;
(2)本文使用数据为温室甜瓜种植环境数据,数据量较少,样本丰富性较差极限学习机预测结果较差。
烟花算法具有强大的并行搜索能力以及良好的收敛性能,基于此提出通过烟花算法优化解决上述问题,将ELM的训练误差作为烟花算法的适应度函数,构建烟花算法优化极限学习机(FWAELM)烟花算法优化极限学习机的主要步骤如下:
(1)随机产生N个烟花,每一个烟花代表解空间中的一个解;
(2)以ELM的训练误差作为烟花算法的适应度函数,计算每一个烟花的适应度值,并根据适应度值计算产生子代火花的数量、爆炸幅度以及爆炸位移;
(3)通过变异操作扩大种群的多样性;
(4)计算烟花产生的子代火花适应度值,从中选择适应度值最好的火花作为下一代烟花;
(5)计算种群的最优解,判断是否满足要求,或者是否到达最大迭代次数,若成立则搜索结束,否则继续迭代。
2 数据获取及评价方法
2.1 数据来源
本研究中气象数据为浙江农科院温室甜瓜种植一季过程中的环境数据,共87组数据。包括日最高气温Tmax、日最低气温Tmin、日平均温度Tave、日平均空气相对湿度RH、日有效光照时长n、日平均光照强度I11,结合当地纬度、海拔等信息,利用彭曼公式计算得到ET0。
烟花算法优化极限学习机流程如图3所示。

图3 烟花算法优化极限学习机流程图Fig.3 Flow chart of the FWAELM algorithm
2.2 模型的评价
本研究中,模型的评价采用均方根误差(RMSE)、平均绝对误差(MAE)和模型可决系数(R_Square),其计算公式如下:
(13)
(14)
(15)
式中:N为总样本数;Yi为FWA_ELM的预测值;Xi为依据气象数据利用彭曼公式计算得到的ET0值;Ymea为Yi的平均值。
3 结果与分析
以常规、方便获取的气象参数:Tmax、Tmin、Tave,RH、n、I11以及计算得到的ET0作为ELM和FWAELM的输入进行训练,以总数据的80%作为训练集,20%作为测试集,极限学习机和烟花算法优化极限学习机的预测结果结果分别如图4和图5所示。由图可知FWAELM的预测结果要明显好于ELM的输出结果,说明小样本数据量情况下,FWAELM更适合用于ET0的预测。
使用前述评价方法对模型进行评价,得到评价指标如表1所示。

表1 ElM与FWAELM预测结果对比Tab.1 Comparison of prediction results between ElM and FWAELM
由表1中数据对比可知,FWAELM的均方根误差为0.115 6,明显低于ELM的0.403 5,平均绝对误差也由ELM的0.346 7下降到0.143 6,模型可决系数由ELM的0.839 0上升到FWAELM的0.943 8。数据表明,烟花算法对极限学习机的优化效果十分显著,提高了极限学习机在小样本数据量情况下的预测精度。
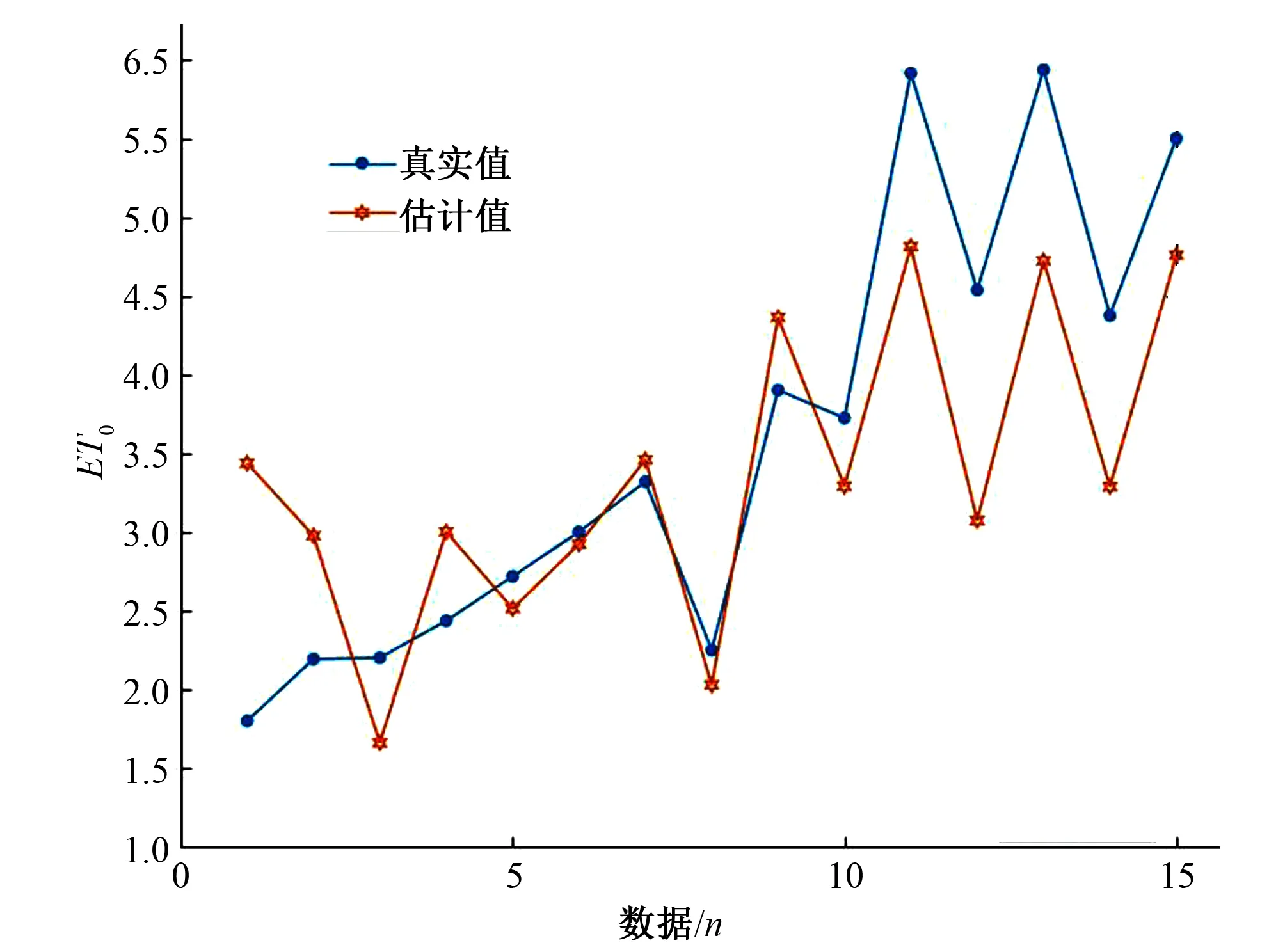
图4 ELM预测结果Fig.4 ELM prediction results

图5 FWAELM预测结果Fig.5 FWAELM prediction results
4 气象数据缺失情况下模型精度计算
在实际使用中,有些数据较为难以获取,为了研究气象数据缺失情况下模型的精度, 将不同变量因子进行组合,建立相应的FWAELM模型,分组进行数据训练与预测,分析缺失不同数据时,FWAELM的模型精度[14]。结果如表2所示。
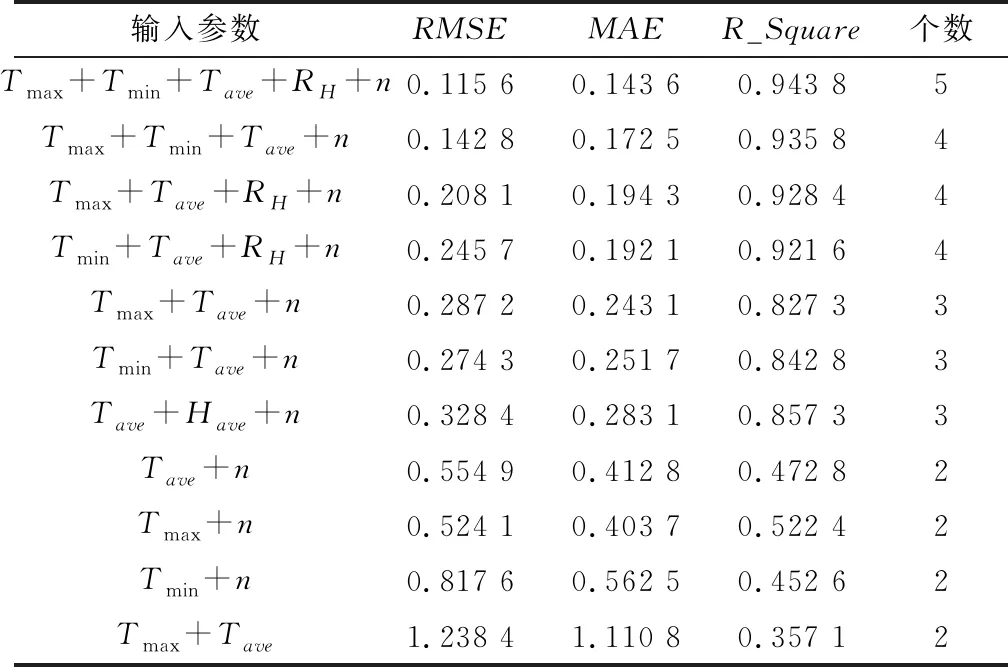
表2 不同气象参数组合条件下模型精度Tab.2 Model accuracy under different meteorological parameter combination conditions
由表2分析可知,气象因子个数对模型有着较大的影响,气象因子越多,模型精度越高。当气象数据降为两个时,模型的均方根误差大于0.5,平均绝对误差也增大到0.4以上,模型可决系数降到0.5附近,模型精度较差,而保留气象因子个数在3个及以上时,模型的均方根误差最大为0.328 4,平均绝对误差最大为0.283 1,模型可决系数最小为0.857 3,模型精度较好,所以使用时应保证该模型的输入气象因子个数大于等于3个。当模型输入参数个数由5个变为4个时,缺少RH相对于缺少Tmax或Tmin模型精度变化较小,说明日平均空气相对湿度RH对模型精度影响较小;缺少参数Tmax时,模型精度变化较大,RMSE由0.115 6变为0.245 7,MAE由0.143 6变为0.192 1,R_Square由0.943 8变为0.921 6,说明最大温度Tmax对模型有较大的影响。当模型输入参数个数变为2个时,缺少因子n时,模型误差最大,说明日照时长对模型精度影响较高。说明在使用时,为确保模型拥有较高的精度,尽量保证输入的气象因子中包含最大温度和日照时长。
5 结 论
本文从优化极限学习机在温室蒸散量ET0预测的应用入手,完成了:
(1)建立了烟花算法优化极限学习机的温室蒸散量预测模型(FWAELM),并将其与极限学习机(ELM)预测模型进行对比,FWAELM模型精度相对于ELM有很大提高,RMSE、MAE、R_Square三个评价指标的值分别由0.403 5、0.346 7、0.819 0优化到0.115 6、0.143 6、0.943 8。
(2)研究了气象参数缺失对FWAELM模型精度的影响,计算了不同气象参数输入情况下模型的评价指标,结果表明温度参数和日照时长参数对模型精度影响较大,其中温度参数中,最大温度对模型精度的影响程度较大,当参数缺失不超过3个时,模型的RMSE小于0.328 4,MAE小于0.283 1,R_Square大于0.857 3,模型精度较高,因此使用FWAELM模型进行ET0预测仍能取得较好的结果。
□
