词长对中文阅读眼跳目标选择的影响:眼动证据 *
2020-06-12仝文任梦雪刘志方冯笑
仝文任梦雪刘志方冯笑
(1山西师范大学教育科学学院,临汾041000)
(2杭州师范大学教育学院,杭州311121)
1 引言
在阅读认知研究中,眼跳目标选择(即“where”问题)是眼动控制的一个基本问题(Rayner,2009)。已有研究发现眼跳落点位置与上一次注视位置到下一个注视词中心的距离密切相关(Cutter,Drieghe, & Liversedge, 2018),词内首次注视位置分布是起跳位置距离的函数。如果从距离下个词中心7 个字母远的地方起跳,注视点会落在下一个词的中心(McConkie, Kerr, Reddix, & Zola,1988),在这个位置阅读加工效率最高,因此被称为最佳注视位置(optimal viewing position, OVP)(O’Regan & Jacobs, 1992)。基于OVP 的重要性,当前两个主流的眼动控制模型(E-Z 读者模型和SWIFT 模型)都将词的中心作为默认的眼跳落点位置(Engbert, Longtin, & Kliegl, 2002; Reichle,Rayner, & Pollatsek, 2003)。但由于眼跳误差对眼跳计划及其执行造成了干扰,注视点通常会落在词的开头与中心之间的位置,即偏好注视位置(preferred viewing location, PVL)(Rayner, 1979)。
无论是E-Z 读者模型还是SWIFT 模型都假设存在一个固定的偏好眼跳长度(preferred saccade length, PSL),即眼跳在没有越标或脱靶情况下的预期眼跳距离,PSL 在英文阅读中一般为7 个字母的长度。但是实际阅读时,偏好眼跳长度会受眼跳误差和起跳位置与预期落点位置距离的影响,起跳位置每偏移一个字母,平均落点位置会随之偏移0.4 个字母(Cutter et al., 2018),从而表现出不同的眼跳长度。
研究证明在英文阅读中词长信息对眼跳目标的选择非常重要(Morris, Rayner, & Pollatsek,1990)。如果去掉词间空格或提供错误的词长信息,阅读会明显受阻,导致注视时间更长,眼跳距离更短(Inhoff, Radach, Eiter, & Juhasz, 2003;Rayner, Fischer, & Pollatsek, 1998)。但是如果有其他线索(如字体粗细)标记词长信息时,眼动模式和正常阅读条件非常接近(Perea & Acha,2009)。英文文本中词间空格的存在使读者很容易从副中央凹处获取词长信息,一般说来,英文读者可以获取词n 和n+1 的长度信息为下一次眼跳做准备。
通常读者阅读的材料中词长差异较大,且各种长度的词的分布没有规律,难以准确衡量词长对眼跳的影响。为此,Cutter 等人(2018)用长度全部为3 个、4 个或5 个字母的单词组成的句子以及这三种长度单词混合组成的句子考察被试的眼跳长度,结果发现3 个字母词长句子的眼跳长度最短,5 个字母词长句子的眼跳长度最长。该实验在句子材料随机呈现的条件下重复了他们之前分组呈现材料时(Cutter, Drieghe, & Liversedge, 2017)发现的结果,证明了偏好眼跳长度的灵活适应甚至可以出现在句子间或者词汇之间,读者并不需要根据以往的阅读经验来预估当前的眼跳长度,而是根据当前注视词和下一次注视的词汇长度来计划自己的眼跳长度。基于此发现,Cutter 等人(2018)提出了一个基于词中心的眼跳长度假设(centre-based saccade length, CBSL),认为眼跳长度的三个影响因素为:(1)当前起跳词的长度;(2)下一个注视词的长度;(3)当前词的注视位置到下一个注视词中心的长度。读者综合利用前两个因素决定一个基于词中心的眼跳长度,而第三个因素影响眼跳长度的偏差。
与英文相比,中文作为一种表意文字有其独特之处。英文中,词长由组成词的字母数量决定。常用词汇中,词汇之间的字母数量差异很大;但是中文词汇的词长一般在1~4 个字符范围内变化。且汉语中大部分词汇是双字词(72%),其余主要由单字词(6%)、三字词(12%)、四字词(10%)以及其他词长的词(0.3%)组成(Wei, Li, & Pollatsek, 2013),词汇长度的变化范围相对较小。中文的基本书写单位是字,字与字之间紧密排列,缺乏提示词边界信息的词间空格。一个汉字既可以单字成词,也可以和其他汉字组合成词,读者在阅读时需要先进行词汇切分,且切分方式可能存在不一致性。这些文字系统间的差异是否会影响中文阅读眼跳目标的选择,从而表现出与英文阅读不一样的结果?目前还没有直接的研究证据。
中文文本中没有明显的词长信息,因此在副中央凹处不能直接获取指引眼跳目标选择的视觉线索。英文的PVL 在词首和词中心之间,大概位于单词的1/4 处(Hyönä & Bertram, 2011);中文阅读研究中没有发现读者将眼跳落在词的中心(Li &Shen, 2013; Liu & Li, 2014),也不存在固定的偏好注视位置。当目标词可预视时,跳入和跳出高频词的眼跳都更长,模拟结果显示眼跳长度存在一个动态调节的过程(Liu, Reichle, & Li, 2016),副中央凹加工所获取的信息在眼跳目标选择过程中具有重要的调节作用(王永胜, 陈茗静, 赵冰洁, 李馨, 白宇鸽, 2017)。关于中文阅读的眼跳目标选择问题,有研究者提出副中央凹加工中能否完成词切分影响随后的眼跳目标选择(Yan & Kliegl, 2016;Yan, Kliegl, Shu, Pan, & Zhou, 2010),即如果在副中央凹加工中完成了词切分,那么该词只需要一次注视,且注视位置更靠近词的中心;如果在副中央凹加工中没有完成词切分,那么该词需要多次注视,且首次注视位置更靠近词首(李玉刚, 黄忍, 滑慧敏, 李兴珊, 2017; Yan et al., 2010)。
有学者对这种观点提出了质疑,Li,Liu 和Rayner(2011)认为Yan 等人(2010)的实验结果也可以解释为:如果注视位置恰好落在词的中心附近,加工效率最高,也就不需要额外注视;如果落在词首,加工效率较低,才会产生多次注视。即使在词间插入空格作为外显词切分线索,也没有发现读者的注视点更倾向于落在词的中心位置,而是倾向于远离所插入的空格(Li & Shen,2013; Liu & Li, 2014; Zang, Liang, Bai, Yan, &Liversedge, 2013)。因此,这种假设可能并不能很好地解释眼跳目标的选择问题。
基于这种考虑,Wei 等人(2013)的研究中操纵实验一的目标区域分别为一个四字词和两个双字词,结果发现前者的眼跳出长度比后者更长,据此提出基于加工情况的眼跳目标选择策略假设,即在中文阅读中,读者会根据副中央凹信息加工的情况来确定下一次的眼跳目标(即能够获得新信息的位置)。根据这一理论可以推论:读者在副中央凹加工中获取的信息越多,随后的眼跳长度也就越长(Li, Liu, & Rayner, 2015; Liu et al.,2016; Liu, Reichle, & Li, 2015; Wei et al., 2013)。
基于加工的眼跳目标选择策略假设和基于词中心的眼跳长度假设在中文阅读中并不对立。副中央凹的加工包含预视的过程(白学军等, 2011),在此过程中会对词长信息进行简单加工,而副中央凹加工的结果又为眼跳提供了依据(王永胜等,2016, 2017)。综合前人的研究可以推论:中文阅读中,读者眼跳目标选择可能建立在副中央凹对词长信息加工的基础之上。句子中通常包含各种长度的词汇,这种条件下眼跳目标选择可能表现为基于加工的眼跳目标选择策略;而当构成句子的词长度一致时,眼跳目标选择可能表现为基于词中心的眼跳长度假设。但是目前仍没有研究对这一推论进行直接验证。因此,探究不同词长类型的句子对中文阅读眼跳目标选择的影响,这对进一步认识中文阅读的眼动控制机制有着重要意义。
综上所述,为探讨不同词长类型的句子对中文阅读中眼跳长度的影响,本研究采用Cutter 等人(2017, 2018)的等词长句子阅读范式,采用3 种不同词长的句子类型:即全部由单字词构成的句子(单字词句),全部由双字词构成的句子(双字词句)和由1~4 个汉字长度的词汇构成的句子(混合句),考察不同词长句子类型对中文阅读眼跳目标选择的影响。如果中文阅读中的眼跳目标选择支持基于词中心的眼跳长度假设,那么在所有类型的句子中,眼跳长度均会随词长的增加而增加;如果支持基于加工情况的眼跳目标选择策略,那么在等词长句子中单字词和双字词的眼跳长度没有显著差异,混合句中的某一词长的词与等词长句子中对应词长的词的眼跳长度也没有显著差异。
2 方法
2.1 被试
42 名山西师范大学本科生参加了实验,平均年龄21.6 岁(SD=1.8)。所有被试母语为汉语,视力或矫正视力正常,无色盲色弱问题。所有被试均未参加过类似实验,未评定过实验材料,实验结束后获得一定报酬。
2.2 实验材料
正式实验材料为长度为18 个字的单字词句、双字词句和混合句各60 句。单字词句指的是完全由单字词组成的句子,即句中任意相邻两个或多个字在词典中都不是作为一个词来收录的;双字词句指的是完全由双字词组成的句子;混合句由单字词、双字词、三字词和四字词组合而成(如图1 所示)。请30 名大学生对句子的通顺性进行7 点评分(1=“非常不通顺”,7=“非常通顺”),单字词句、双字词句和混合句的通顺性评分差异不显著(单字词句M=6.36,SD=0.25;双字词句M=6.18,SD=0.37;混合句M=6.40,SD=0.21;且差异均不显著,ps>0.05)。另外请30 名大学生对句子的难度进行7 点评分(1=“非常容易”,7=“非常困难”),单字词句、双字词句和混合句句子的难度评分差异不显著(单字词句M=1.3 2,SD=0.15;双字词句M=1.55,SD=0.28;混合句M=1.39,SD=0.20;且差异均不显著,ps>0.05)。针对句子陈述的内容,每类句子另外编制12 个简单判断题,用以检验被试是否认真阅读,判断题的答案中“是”和“否”各占一半。正式实验时每个被试共阅读180 个句子。正式实验中所有句子均随机呈现。

图 1 实验材料举例
2.3 实验设备
实验采用加拿大SR research 公司生产的Eyelink II 眼动记录仪,采样频率为500 Hz,被试机屏幕刷新频率为75 Hz,分辨率为1024×768 像素。实验时,三类句子都以宋体20 号字单行呈现在屏幕中央,被试距离屏幕约54 cm,每个汉字约为0.9 度视角。
2.4 实验程序
对每个被试单独施测。被试进入实验室坐下后,首先调整座椅和下巴托高度,使被试视线与屏幕中央保持水平,然后给被试佩戴头盔。实验开始前呈现指导语,在确保被试理解整个实验程序后调整镜头位置并校准,三点校准结束后呈现练习句让被试熟悉实验过程。被试需要完成10 个句子的练习实验,每完成一个句子后,被试注视屏幕中央偏左位置的黑色小圆圈并按翻页键进入下一句的阅读,确认被试熟悉实验程序后进入正式实验。练习句中5 个句子后带有问题,正式实验中有36 个句子带有问题,要求被试根据前面刚读过的句子内容进行判断并按键做出反应。主试实时监控整个实验进程,并在任何需要的时候重新校准。整个实验过程持续大约40 分钟。
3 结果
被试回答问题的准确率为92%,且各类句子间差异不显著(Fs<1, ps>0.05),表明被试很好地理解了句子。
正式分析之前各实验条件分别按以下标准删除数据以保证结果的可靠性:(1)实验过程中因出现头动导致追踪失败的项目或连续按键导致句子被跳过的项目;(2)注视点少于5 个或大于40 个的句子数据;(3)单个注视点注视时间小于80 ms 或大于1000 ms 的数据;(4)3 个标准差之外的数据,最大删除比例为2.2%。
分析数据时首先将所有句子按词汇长度划分兴趣区。因此,单字词句共划分18 个兴趣区,双字词句共划分9 个兴趣区,而混合句则按组成句子的词汇个数划分了最多13 个兴趣区。根据已有研究(Ma, Li, Xu, & Li, 2019),结果分析采用的眼动指标有平均首次注视位置(initial landing position,在目标区上的第一次的注视位置,不管在该目标区上总共有多少次注视),单次注视中首次注视位置(目标区只有一次注视时注视点的位置),多次注视中首次注视位置(目标区有两次或两次以上的注视时首次注视的注视位置),同时还计算了眼跳入长度(incoming saccade length,从前一个目标区到当前目标区的眼跳长度)和眼跳出长度(outgoing saccade length,从当前目标区到随后目标区的眼跳长度)。
本研究采用基于R 语言环境下的线性混合模型(LMMs)进行数据分析,使用lme4 统计软件包中的lmer 程序进行统计。在分析时指定被试和项目作为随机效应,将词频和笔画数作为协变量以便更好地考察词长对眼跳目标选择的影响。线性混合模型中,报告回归系数、标准误以及t 值(t=b/SE),t>1.96 就代表p<0.05。按照混合线性模型的需要,分析时各眼动指标变量均做了对数转换。
在具体分析之前,本研究比较了三类句子的总阅读时间,三者之间均没有显著差异(单字词句M=3039ms, SE=26;双字词句M=3007ms,SE=27;混合句M=3118ms, SE=27;且差异均不显著,ts<1),说明三类句子间难度的控制是成功的。
按词汇长度对单字词句和双字词句进行兴趣区划分。各眼跳参数的平均值如表1 所示。
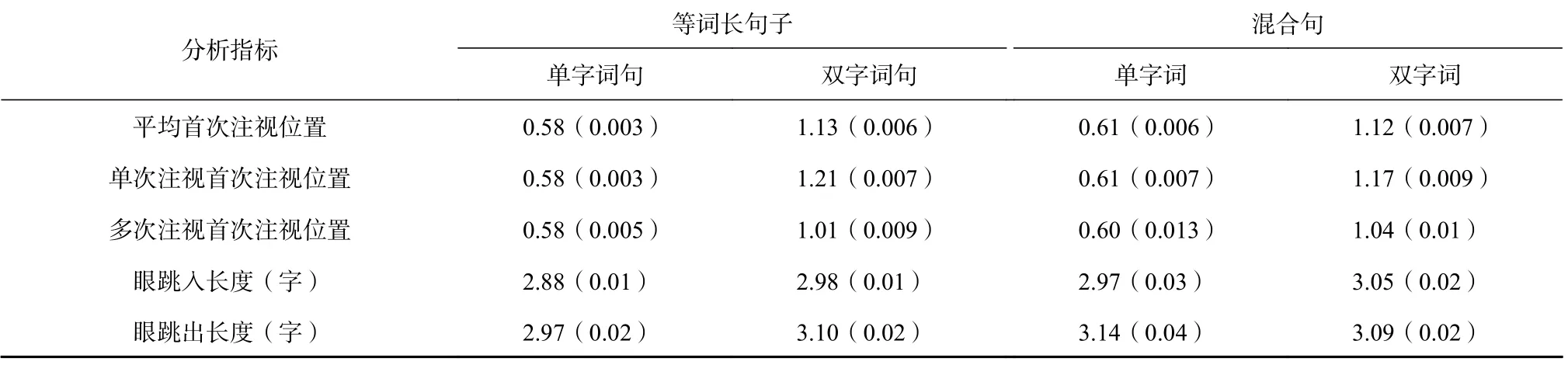
表1 各类句子眼动参数平均值
由结果可知,在平均首次注视位置上,单字词句和双字词句之间差异显著(b=0.64,SE=0.02,t=30.79)。单字词句的首次注视位置比双字词句距离词首更近,在单次注视和多次注视的情况下依旧保持了当前的结果趋势(b=0.7 6,SE=0.02,t=34.34;b=0.51,SE=0.03,t=15.70)。在最重要的眼跳长度指标上,双字词句的眼跳入长度和眼跳出长度均显著长于单字词句(b=0.08,SE=0.02,t=4.48;b=0.05,SE=0.02,t=1.99)。
本研究将混合句也按词长划分了兴趣区,比较了等词长句子(单字词句和双字词句)和混合句里面的单字词和双字词的眼动指标差异,具体结果如表1 所示。
由结果可知,在注视位置上,混合句和单字词句里的单字词在平均首次注视位置上均没有显著差异(b=0.02,SE=0.02,t=1.05),而且在单次注视和多次注视时的首次注视位置也没有显著差异(b=0.03,SE=0.02,t=1.35;b=−0.01,SE=0.04,t=−0.30);同样,混合句和双字词句里的双字词在所有的首次注视位置指标上也没有显著差异(平均首次注视位置: b=−0.01,SE=0.03,t=−0.26;单次注视首次注视位置: b=0.01,SE=0.03,t=0.41;多次注视首次注视位置: b=0.01,SE=0.04,t=0.23);在眼跳入长度和眼跳出长度上,混合句中的单字词眼跳长度显著长于单字词句中单字词的眼跳长度(眼跳入长度: b=0.06,SE=0.02,t=3.61;眼跳出长度: b=0.09,SE=0.02,t=4.37),双字词句和混合句中,双字词的眼跳入长度和眼跳出长度均没有显著差异(眼跳入长度: b=0.03,SE=0.03,t=1.04;眼跳出长度: b=0.03,SE=0.04,t=0.67)。
4 讨论
本研究采用等词长句子阅读范式探究了词汇长度对中文阅读眼跳目标选择的影响。和英文阅读得到的结果类似,中文阅读中的眼跳长度也会随着词长的变化而变化,双字词句的眼跳入长度和眼跳出长度均显著长于单字词句,支持了基于词中心的眼跳长度假设(CBSL);应当注意到,当构成句子的词长度一致时,基于词中心的眼跳长度假设提到的影响眼跳长度的前两个因素(当前起跳词的长度和下一次注视词的长度)都是固定的,因此眼跳目标的选择主要决定于第三个影响因素,即当前词的注视位置到下一个注视词中心的长度。这其实就是基于加工情况的眼跳目标选择策略所提到的基于副中央凹对词长信息加工情况来确定随后的眼跳长度,这个结果实际上是支持基于加工情况的眼跳目标选择策略的。同时,实验也发现混合句中的双字词的眼跳长度和双字词句中双字词的眼跳长度没有显著差异,也支持了基于加工情况的眼跳目标选择策略。综合这两点,说明中文阅读中,读者眼跳目标选择可能建立在副中央凹对词长信息加工的基础之上,即基于加工情况的眼跳目标选择策略。
本实验最重要的结果是发现词汇长度对中文阅读的眼跳长度的影响。单字词句和双字词句的眼跳长度存在显著差异,说明中文读者也会依据词长信息来进行眼跳目标选择。阅读时读者在副中央凹处进行切词加工,获取的单字词句和双字词句词长信息不同,因此预估的下一次注视能够有效加工的位置也不尽相同,双字词句的词长更长,因此随后的眼跳长度也相应增加。而且这种眼跳目标的选择方式在不同类型的句子中具有一致性,在等词长句子(即单字词句和双字词句)和混合句中,词长信息都可以为下一次的眼跳目标选择提供依据。实验结果发现混合句中单字词的眼跳长度长于单字词句中单字词的眼跳长度,这可能是由于混合句是由单字词、双字词、三字词和四字词混合组成,单字词相对较少,词长的不确定性增大了眼跳误差,长词数量相对较多,导致越标的可能性增加。而且混合句的词长构成更符合平时的阅读习惯,混合句中的单字词因为词长最短的原因更容易被跳读,因此混合句中单字词的眼跳长度要长于单字词句中单字词的眼跳长度。英文中也有类似的情况,短词在混合句中相对于在等词长句子中更容易被跳读,较长的词有更准确的较长的眼跳(Cutter et al., 2017)。
从以往研究结果来看,英文阅读中采取基于词中心的眼跳长度策略有着天然的物理基础。与单词有关的低水平视觉线索(如词长和词间空格)是决定下一次眼跳计划的主要因素,读者也基本以“词”为基础选择注视位置,即读者选择一个词,而不是字母作为下一次眼跳的目标。在知觉广度范围内,读者可以获取当前词和随后加工的副中央凹词的词长信息。为了获得更高的阅读效率,在制定眼跳计划时会选择词中心作为下一次的注视位置,并依据当前注视词到下一个词中心的距离计划执行眼跳。
在中文书写系统中没有明确的视觉线索(空格或者其他切分方式)来标记一个词的开始和结束,Inhoff 和Liu(1998)研究发现,在中文阅读中,词长对眼跳计划的影响不大。但是在他们的实验中并没有操纵词长变量,难以直接得出词长对眼跳计划影响不大的证据;另外,他们实验中所用的材料也不是等词长句子材料,词长的不确定性会导致在眼跳时产生更大的误差,因而难以得到词长不影响眼跳计划的可靠证据。而在本实验中,系统操纵了词长变量,直接验证词长对眼跳长度的影响,结论更加可靠。先前的研究已经发现,在副中央凹加工过程中会对词汇进行切分,这种切分加工可以获取一些简单的词长信息,读者可能依据这些信息选择下一次的眼跳位置。而且从阅读加工的基本单元来讲,中文阅读中也有颇多证据表明词在阅读中发挥重要作用,词汇属性(如词频和预测性)会影响注视时间,高频词汇和高预测词汇的注视时间均更短(Kliegl,Grabner, Rolfs, & Engbert, 2004; Rayner, Reichle,Stroud, Williams, & Pollatsek, 2006);且词边界信息(如空格)也会对阅读产生重要作用,已有研究发现在词间加入空格不会阻碍阅读,但是阅读有字间空格的句子时读者的阅读速度明显变慢(Bai,Yan, Liversedge, Zang, & Rayner, 2008),侧面证明词汇更可能是阅读的基本信息单元,所有支持词单元的证据都说明了中文阅读中存在切词的过程,所以读者依据词长来确定眼跳长度是有据可循的。
目前的两个主流阅读模型E-Z 读者模型和SWIFT 模型均探讨了阅读中“when”和“where”问题,也就是何时眼跳,跳往何处的问题。在E-Z读者模型中,假设存在一个早期视觉加工阶段,它是完整整合单词信息之前的“前注意”阶段,作用在于收集词长等低级视觉线索信息来帮助制定眼跳计划。而在SWIFT 模型中,同样存在一个词汇的“前加工阶段”,此阶段主要加工单词的一些自然属性,如词长、首字母等。也就是说,眼跳问题的解决可以基于这种不需要深入加工的低水平信息进行,为英文阅读中词汇长度影响眼跳目标选择提供基础,而由空格标记的词长信息对于眼跳目标选择和早期词汇通达都是有帮助的。在中文文本中词间没有空格这种低水平的物理边界,但是读者依旧可以在“前注意”或“词汇的前加工阶段”从副中央凹获取简单的词长信息,根据对词长信息的加工情况进行眼跳选择。即中文阅读时眼跳目标选择是建立在副中央凹对词长信息加工的基础之上的。本研究发现无论是在等词长的句子还是不等词长的句子中,相同词长对眼跳长度都有相同的影响,支持了中文阅读中的眼跳目标选择建立在副中央凹对词长信息加工基础上的假设。
实验还发现词长影响了中文阅读中的首次注视位置,按词长划分兴趣区的结果显示长词的首次注视位置较短词距词首更远,这和以往研究一致(Zang, Fu, Bai, Yan, & Liversedge, 2018)。结果还发现多次注视时比单次注视时的首次落点位置要更靠近词首。说明和英文阅读中固定的偏好注视位置不同,中文阅读的眼跳落点位置有一个动态调整的过程(Liu et al., 2016)。对此有几种可能的解释。第一种可能是由于偶然的因素,注视点落在了词的开始或者中心位置,导致不同的注视情况。如果眼跳正好落在词的中心,那么只需要一次注视词汇就可以被有效识别;如果注视点落在了词首,那么一次注视不能完成对该词的加工,词汇识别效率较低,需要再注视。第二种可能的解释为副中央凹加工影响眼跳落点位置。如果读者在副中央凹已经对词汇进行识别,那么随后可能跳读该词(尤其是短词),也可能根据其长度将注视点落在其中心;如果在副中央凹没有被识别,读者会将注视点落到其词首位置,重新对该词进行加工。之前的研究表明汉语阅读中副中央凹加工确实影响了眼跳目标的落点位置。在Li 等人(2015)的研究中,被试的注视点越过边界之后只呈现接下来的两个字,结果发现注视点落在第二个字比落在第一个字的情况下词汇识别的速度更快。
英文等拼音文字阅读时可能依赖空格等低水平视觉信息提供的词长线索选择眼跳目标,确定眼跳长度;而中文这种紧密排列的文字可能依赖副中央凹对词汇的加工获取词长信息来确定眼跳目标和眼跳长度。这种规律可能隐藏在自然语料中词长的不确定性和眼跳误差的掩蔽之下难以发现。
5 结论
实验发现词汇长度确实影响中文阅读的眼跳目标选择,词汇长度显著影响了随后的眼跳长度,双字词句的眼跳入长度和眼跳出长度均长于单字词句,且混合句中的双字词的眼跳长度和双字词句中双字词的眼跳长度没有显著差异,证明了中文阅读中,读者眼跳目标选择可能建立在副中央凹对词长信息加工的基础之上。
