近似最近邻大数据检索哈希散列方法综述
2020-06-11费伦科秦建阳滕少华刘冬宁
费伦科,秦建阳,滕少华,张 巍,刘冬宁,侯 艳
(广东工业大学 计算机学院,广东 广州 510006)
1 相关方法介绍
1.1 数据检索方法
随着互联网的快速发展,网络信息以指数级的速度增长。近年来Google每年的搜索量达2万亿次以上,Twitter每日上传的信息量达4亿条,Youtube的上传速度达到400 h/min。此外,不仅数据量快速增长,数据的维度也随着多媒体的发展而快速增加。面对如此庞大的信息,如何更好地利用信息,从而提高互联网利用效率,解决信息有效存储、索引与查询的问题迫在眉睫。目前主要有精确检索[1]和近似最邻近检索[2]两种数据检索方法。
1.1.1 精确检索
精确检索在数据库中依次计算训练样本与查询样本之间的距离,抽取出距离最小的样本即为所要查找的最近邻。最早的精确检索方法包括线性搜索[3]等,这是一种穷举搜索方法,当样本数量巨大时搜索效率急剧下降。后来发展出k-d trees[4],metric trees[5]和混合型索引结构[6]等基于空间分割的方法,但这些方法随着样本的特征维度增加效率急剧下降,表现甚至不如线性搜索。因此精确检索实际应用有限。
1.1.2 近似最近邻检索
近似最近邻检索利用了数据量增大后数据之间会形成簇状聚集分布的特性,通过分析和聚类对数据库中的数据进行分类或编码,并根据目标数据的特征预测其所属类别,返回类别中的部分或全部作为检索结果。近似最近邻检索的核心思想是搜索潜在的近邻数据而不局限于返回最近邻的数据,在牺牲可接受范围内的精度的情况下提高检索效率。近似最近邻检索主要分为两类方法:一类是哈希散列方法,另一类是矢量量化方法。矢量量化需要先建立码本然后搜索码字,码本建立和码字搜索的复杂度都会随着矢量维数的增加而增加,为此带来巨大的计算开销。尽管Jégou等[7]提出的乘积量化(Product Quantization)方法对此进行了改善,在此只关注更加高效简便的哈希散列方法。
1.2 哈希散列方法介绍
1.2.1 哈希散列方法过程
哈希散列方法是一种数据检索方法,实现过程如下:首先构建一个映射矩阵将高维的训练数据投影成低维的连续数据,然后将低维连续数据量化成二进制数据;测试数据使用相同的映射矩阵投影量化成二进制数据;最后通过比较训练数据和测试数据的二进制代码,实现快速检索。
哈希散列方法的训练过程一般分成两步,对于训练数据 X,有:第一步,投影:Y =XP,将高维的训练数据 X通过映射矩阵 P投影成低维的连续数据Y ,本质上属于降维过程;第二步,量化: B=sgn(Y),一般使用符号函数s gn(·)将 连续数据Y 量化成二元哈希数据 B。在投影和量化过程中,引用损失函数 L衡量原始数据与二元数据间的信息损失,确保二元哈希数据仍然保持原始数据的相关结构和信息。
1.2.2 哈希散列方法的难点
哈希散列方法的难点有3个:第一,构建一个良好的映射矩阵将高维数据投影成低维数据;第二,减少量化的损失,即减少二进制数据与原始数据之间的差异;第三,用于学习二进制代码的参数和用于编码新测试图像的算法应该是非常有效的。
1.2.3 哈希散列方法的优点
哈希散列方法的优点主要在于,将高维的数据转化成低维的二进制数据,即将欧氏距离转换成汉明距离后,依旧能较好地保留数据之间的原始相似性;通过基于快速二进制操作的汉明距离排序或在某个汉明距离内的哈希表查找,可以在子线性甚至恒定时间内完成近似数据点的检索,不必像高维的数据需要进行复杂耗时的方程式求解;再者,原始数据的二进制压缩可以减少大量存储空间,即使使用大数据集,依旧有可能调用到内存中进行操作。
2 距离计算
哈希散列方法通过距离计算比较两个数据样本之间的相似度。本节主要介绍不同形式的距离计算方法以及它们的特点。对于数据 X=(x1,x2,···,xn),其中列向量 xi是d 维的数据特征,有以下的距离定义。
2.1 欧几里得距离
欧氏距离计算 n 维空间中两个点之间的实际距离,也可以计算图像的相似度。欧氏距离越小相似度越大。欧氏距离的定义如式(1)所示。
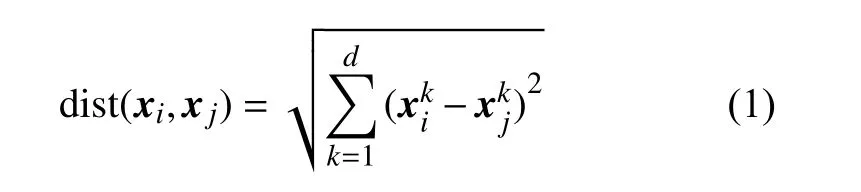
2.2 汉明距离
汉明距离通过比较二进制每一位是否相同来计算二进制数据的相似度,若不同则汉明距离加1。汉明距离定义如式(2)所示。

如成对数据00和01、01和11的汉明距离都为1,00和11的汉明距离为2。二进制数据相似度越高,对应的汉明距离越小。
2.3 汉明亲和度
汉明亲和度计算两个二进制数据的内积。亲和度是距离的非线性函数,因此均匀地近似亲和度将导致近似具有不均匀的距离。但是近似亲和度矩阵可以化为二元矩阵分解问题。汉明亲和度定义如式(3)所示。
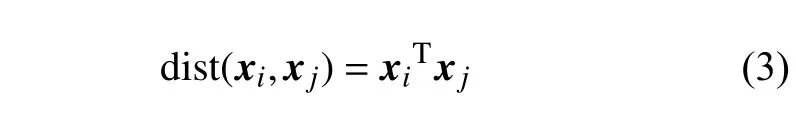
2.4 余弦相似度
余弦相似度利用两个向量夹角 θ的余弦值来衡量两个向量之间的相似度。两个向量越相似夹角越小,余弦值越接近1。余弦相似度定义如式(4)所示。
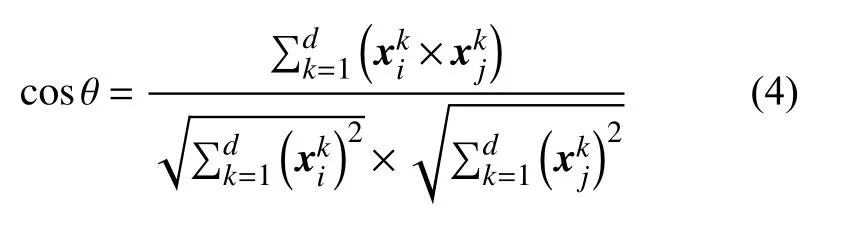
2.5 Jaccard相似度
给定两个集合 A,B ,Jaccard系数定义为A 与 B交集大小与并集大小的比值,Jaccard值越大说明相似度越高。Jaccard相似度定义如式(5)所示。
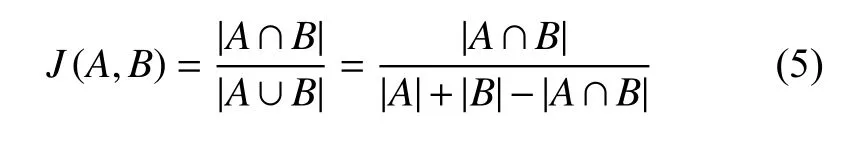
其中| ·|表示集合中元素的个数。
3 损失函数
由于高维数据映射到低维数据过程,或者量化过程都会丢失一定的信息。为了尽量保证信息的完整,以及提高哈希检索的效率,将更多的相似数据映射到相同的二进制代码中,通常需要使用损失函数对映射和量化过程进行约束和判断。
现有方法倾向于优化单一形式的哈希散列函数,其参数针对整体损失函数直接优化。优化过程与所选择的哈希散列函数族相结合。不同类型的哈希散列函数提供了测试时间和排名准确度之间的权衡。例如,简单线性感知器函数与核函数相比在评估效率上相对较高,但在最近邻检索的准确率上相对较低。
本节对不同的损失函数进行分类介绍。
3.1 按照计算距离的方法分类
根据前文介绍的距离计算方法,哈希散列方法的损失函数主要用到汉明距离和汉明亲和度两种度量方式控制信息损失。
3.1.1 基于相似和不相似数据对的汉明距离
比如二元重构嵌入(Binary Reconstructive Embedding)[8]方法。BRE损失函数定义如式(6)所示。
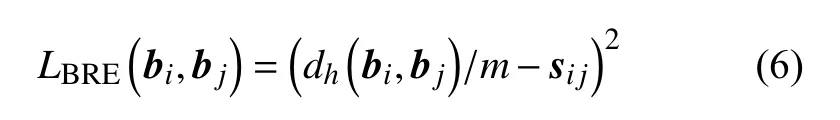
其中, bi和 bj表示二进制代码,dh表示汉明距离计算。利用汉明距离比较二进制代码之间的差异位数,并除以二进制代码长度 m将数值控制在[0,1]的范围内。sij是有监督模型下对应数据样本 xi和 xj的相似度标签,若两者相似则 sij=1, 否则 sij=0。最小化有监督模型标签与二进制代码相似度的欧氏距离,即可最优化二进制编码的信息损失。但有监督模型标签并不是必要的,在无监督模型下只需最小化二进制代码的汉明距离即可最优化信息损失。
3.1.2 基于汉明亲和度
比如核监督哈希(Kernels Supervised hashing)[9]方法。KSH损失函数定义如式(7)所示。
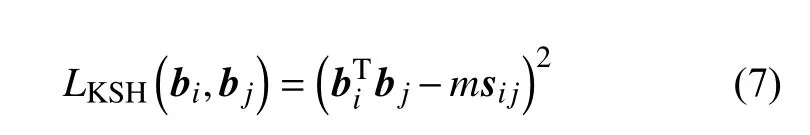
汉明亲和度还会结合其他方法,比如ℓ2-损失,指数损失,铰链损失。比如半监督连续投影学习哈希(Semi-supervised Sequential Projection Learning Hashing)[10]。SPLH损失函数定义如式(8)所示。
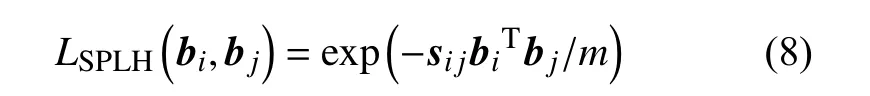
其中, exp 表示指数损失, bTibj表示汉明亲和度值,sij是半监督模型下的相似度标签。当二进制代码越相似时,指数损失的值越小。最小化指数损失值即可最优化二进制编码的信息损失。
3.2 按照形式分类
哈希散列方法的损失函数按照形式划分主要有3类,分别是线性感知器函数,核函数和特征函数。
3.2.1 线性感知器函数
比如均衡哈希(Harmonious Hashing)[11]方法。HH损失函数定义如式(9)所示。
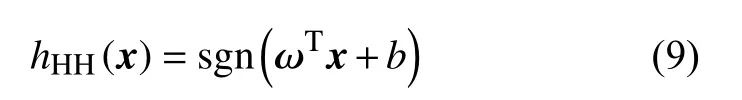
其中, sgn表示符号函数,若值大于零则返回1,否则返回-1。 ω表示映射矩阵,将高维数据 x映射成低维连续数据。 b表示偏置参数,不是必须设置的。线性感知器函数由于其计算快速的特点,是哈希方法中常用的损失函数类型。
3.2.2 核函数
比如可伸缩核哈希(Scalable Kernel Hashing)[12]。SKH方法损失函数定义如式(10)所示。

其中 sgn表示符号函数,ω 表示映射矩阵,b 表示偏置参数。表 示核函数表示数据中心点。核函数通常定义为空间中任一点 x 到某一中心之间欧氏距离的单调函数。核函数有许多类型,比如高斯核函数κ (x,y)=exp(-‖x-y‖2/2σ2)、 线性核函数κ(x,y)=xTy等等。低维空间线性不可分的数据通过非线性映射到高维特征空间可以实现线性可分。为了得到线性可分的结果,常常需要对低维数据进行非线性变换。但是非线性变换计算是复杂的。为了简便计算,可以使用核函数直接得到高维数据非线性变换的内积,从而得到线性可分的结果。
3.2.3 特征函数
比如谱哈希(Spectral Hashing)[13]方法。SH方法损失函数定义如式(11)所示。

其中, tr(·)表 示迹函数, L 表示图拉普拉斯矩阵,Y 表示连续的哈希代码。 Y的解是图拉普拉斯矩阵 L的最小k 个特征值对应的特征向量。具体的算法将会在第6.2节介绍。
3.3 按照数据对分类
3.3.1 仅考虑相似数据对之间的相关性
比如上文提到的损失函数都是仅考虑相似数据对之间的相关性。
3.3.2 同时考虑不相似数据对之间的差异性
比如弹性嵌入方法(Elastic Embedding)[14]。EE方法的损失函数定义如式(12)所示。

4 离散约束
由于哈希散列方法的学习结果是二进制代码B,因此最终的二进制代码一般具有离散约束,离散约束的定义如式(13)所示。
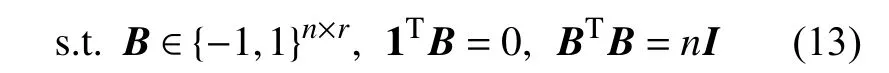
其中,约束的第一项表示二进制代码 B遵循二值化约束;第二项表示二进制代码 B遵循平衡性约束,即每位编码可能为1或者0的概率为50%;第三项表示二进制代码 B遵循不相关性约束,即每位编码与其他编码互不相关。
到目前为止,很少有方法直接工作在离散空间中。参数敏感哈希(Parameter-Sensitive Hashing)[15]和二元重构嵌入方法通过逐步调整由函数生成的代码来学习预定义哈希散列函数的参数。迭代量化哈希(Iterative Quantization)[16]迭代地学习代码过程中明确地施加了二进制约束。虽然迭代量化哈希和二元重构嵌入方法工作在离散空间中并生成哈希代码,但它们不能很好地捕获代码空间中原始数据的局部邻域。迭代量化哈希的目标是最小化二进制代码和主成分分析(Principle Component Analysis)[17]结果之间的量化误差。二元重构嵌入训练汉明距离来模拟有限数量的采样数据点之间的 ℓ2-距离,但由于复杂的优化程序,无法训练整个数据集。
由于离散约束的不连续问题,在优化时非常困难。因此对离散约束的处理方法有3种,分别是:忽略离散约束,放松离散约束和保持离散约束。
4.1 忽略离散约束
忽略离散约束通常指忽略平衡性约束或不相关性约束,其中主要忽略平衡性约束。比如迭代量化哈希为了减少数据之间的量化误差,使用了旋转矩阵将投影矩阵旋转到量化误差最小的方向。最终二进制代码的定义如式(14)所示。
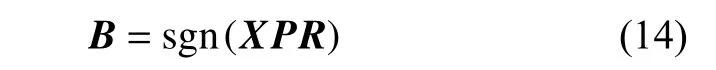
其中 X 表示训练集, P表示由主成分分析对训练集分解得到的投影矩阵, R表示正交旋转矩阵。从式(14)可得,直接使用符号函数导致二进制代码正负值并不均等,完全忽略了平衡性约束。而即使PCA分解得到的特征向量(投影矩阵) P是不相关的,正交矩阵R 也是不相关的。但与训练集 X相乘后,不能保证其不相关性,故也忽略了不相关性约束。
4.2 放松离散约束
放松离散约束通常指对离散约束进行松弛优化,围绕连续解来获得二进制代码。放松离散约束是常见的两步法哈希,即先投影后量化。投影的结果是连续值(实值) Y 。投影过程中保持Y 的平衡性和不相关性。最后量化成二进制代码 B 时能较好地保持 B的离散性。比如谱哈希通过图拉普拉斯的特征分解得到连续矩阵Y ,该结果使用符号函数量化后可得到二进制代码 B。由于各特征向量是线性无关的,因此连续矩阵Y 中的每个向量保持不相关性。通过量化后的二进制代码 B也 能保持不相关性。但在求解 B的时候使用了符号函数,依然忽略了平衡性。因此该算法是属于放松了离散约束,先围绕连续解 Y进行求解,最后量化成二进制代码 B。
4.3 保持离散约束
保持离散约束是指将投影和量化结合起来进行交替求解。比如离散图哈希(Discrete Graph Hashing)[18]方法。DGH方法的定义如式(15)所示。

其中, B 表示二进制代码,Y 表示近似于 B的连续代码。即使保持离散约束,还是需要求解连续代码Y ,然后通过最优化二进制代码 B 和连续代码Y 之间的信息损失,来获得最优解的二进制代码 B。上述公式中第一项表示谱哈希的图拉普拉斯构造,第二项表示通过欧氏距离量化二进制代码 B 和连续代码 Y之间的信息损失。在一步法中,即使需要求解连续代码 Y,但因为交替迭代求解过程中保持了二进制代码 B的离散约束。这样能减少过度优化离散约束带来的信息损失。
5 外样本学习
面对庞大的数据集,一般无法直接学习所有数据的哈希散列函数和二进制代码。通常选取少量的样本进行训练得到投影矩阵,对于新的样本或者测试集,利用投影矩阵可以直接生成二进制代码,这称之为外样本学习。如何加快外样本学习,是提高在线哈希检索的关键。几种常用的外样本学习方法包括:直接学习投影矩阵,引入期望学习测试数据的分布,近似投影矩阵和机器学习算法学习投影矩阵。
5.1 直接学习投影矩阵
很多哈希散列方法并不直接学习二进制编码B,而是学习高效的投影矩阵 P。这样不仅可以快速地对外样本进行投影得到新的二进制代码,还可以在学习过程中通过添加不同的约束实现不同的特征选择效果。比如迭代量化哈希直接对训练数据进行主成分分析,求解出投影矩阵 P对高维的训练数据进行降维。这样新测试样本也可以直接通过投影矩阵P 编码成二进制代码 B。
5.2 引入期望学习测试数据的分布
引入期望学习测试数据分布的前提是认为数据遵循某种分布,通过学习训练数据后,可以根据数据分布情况编码出测试数据的二进制代码 B。比如谱哈希认为数据是均匀分布的,故图拉普拉斯的特征向量(投影矩阵)和特征值都是均匀分布下的期望值,定义如式(16)所示。

其中,数据均匀分布在 [a,b]范 围内。特征向量Φk(x)表示训练样本 X对应的第k 位二进制编码。特征值λk为特征向量Φk(x) 对应的第k 小的特征值。
5.3 近似投影矩阵
近似投影矩阵是指不直接学习训练数据 X对应的投影矩阵 P,而是对训练数据 X进行变换得到新的数据 X~ ,然后学习新数据 X~ 对应的投影矩阵 P~。由于变换后的新数据 X~具有更良好的特征,比如维度更小、数据间的区分度更大,通过学习这些数据 X~的投影矩阵 P~,将会更好地线性区分不同的样本,获得更好的二进制代码 B。
比如锚图哈希(Anchor Graph Hashing)[19]方法。AGH方法对训练集 X 进行聚类获得聚类中心U (也称为锚点),然后计算训练集与锚点之间的相似矩阵 Z,定义如式(17)所示。
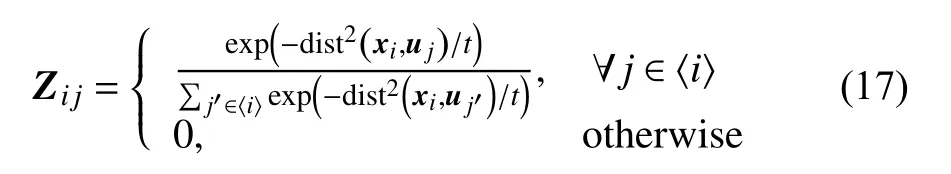
并通过相似矩阵 Z 构建锚图 A(类似于谱哈希中的拉普拉斯图)。锚图 A的定义如式(18)所示。


5.4 机器学习算法学习投影矩阵
如果哈希散列函数无法直接求解投影矩阵 P或者近似投影矩阵 P~, 可以先求解出二进制代码 B或者连续代码Y ,然后通过机器学习算法对原始数据和二进制代码 B或连续代码Y 进行学习,进而求解出投影矩阵 P。定义如式(20)所示。
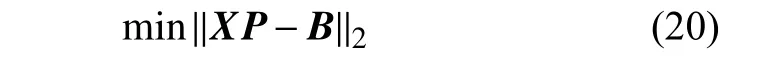
典型的方法比如稀疏哈希(Sparse Hashing)[20]。稀疏哈希无法直接学习投影矩阵,利用字典进行外样本学习的效果也不好。因此使用机器学习算法典型相关分析(Canonical Correlation Analysis)[21]学习投影矩阵。
6 哈希散列算法介绍
哈希散列算法可分类为无监督哈希、有监督哈希和半监督哈希。有监督哈希和半监督哈希的学习需要数据的标签信息,由于标签的采集和学习需要额外的消耗,因此本文主要关注更简便的无监督哈希算法。本节中将详细介绍几个典型的无监督哈希算法以及它们的相关方法。
6.1 局部敏感哈希
局部敏感哈希(Locality-Sensitive Hashing)由A.Gionis等[22]于1999年在VLDB数据库会议(Very Large Data Bases)上提出,首次引入了哈希散列的概念。
局部敏感哈希是与数据不相关的哈希检索算法。数据不相关是指将原始高维数据 X映射成低维二进制代码 B过程中并不探索数据的内部结构,因此通过投影得到的二进制代码 B的数据区分度并不明显。局部敏感哈希的算法通过随机构造一个投影矩阵 P ,将原始数据映射成短编码的二进制数据 B。局部敏感哈希方法的定义如式(21)所示。

由于随机投影方法需要增加编码长度来提高准确率,因此局部敏感哈希的实际应用有限。但局部敏感哈希提出的两点思想奠定了哈希散列方法的基础:
(1) 数据通过投影变换后,相邻数据点在新的数据空间中仍然相邻的概率很大,而不相邻的数据点被映射到同一个桶的概率很小。
(2) 如果原始空间中相邻的数据落入相同的桶,那么在超大集合内查找相邻元素的问题转化为在一个很小的集合内查找相邻元素的问题。
为了提高局部敏感哈希的性能,Datar等[23]提出了p-稳态分布哈希,在欧氏空间下使用 ℓp-范数代替ℓ2-范数计算数据相似度,提高了计算效率,投影的结果服从p-稳态分布。Kulis等[24]提出核化局部敏感哈希(Kernelized Locality-Sensitive Hashing),使用核函数求解哈希函数而不是随机投影。Lin等[25]提出了密度敏感哈希算法,该算法使用K-均值聚类(Kmeans)方法构建相邻组探索数据的局部结构,并根据熵值选取信息量最大的超平面进行投影。
6.2 谱哈希
为了改进局部敏感哈希对数据进行随机投影产生的低效二进制代码,谱哈希提出使用无向图探索数据内部结构,见图1。谱哈希认为数据可以根据其相邻程度构造成无向图,如图1(a)所示。根据无向图可以构造出邻接矩阵 W,如图1(b)所示,若 xi和 xj相邻则Wij=1, 否则Wij=0。利用邻接矩阵可以构造出图拉普拉斯矩阵 L= D-W ,其中 D是邻接矩阵的行的和的对角阵,如图1(c)。 L矩阵是一个对称方阵。通过对图拉普拉斯矩阵 L进行特征分解,得到图1(d)中的特征值和特征向量,舍弃0特征值,选取最小的特征值0.4对应的特征向量并将其按照正负进行划分。可以看出相似的A、B、C被分成了一类,而D、E、F、G被分成了另一类。结果符合预期。

图 1 谱哈希的使用无向图探索数据内部结构演示Fig.1 Undirected graph (a), affinity matrix (b), graph Laplacian (c) and eigendecomposition of graph Laplacian (d) of Spectral Hashing

其中,约束的第一项表示二进制代码 B遵循二值化约束;第二项表示二进制代码 B遵循平衡性约束,即每位编码可能为1或者0的概率为50%;第三项表示二进制代码 B遵循不相关性约束,即每位编码与其他编码互不相关。在离散约束下直接求解问题(22)是个NP难问题,可以在连续空间中对其进行谱放松,定义如式(23)所示。

其中, L= D-W是图拉普拉斯。问题(23)的解就是连续空间中图拉普拉斯的最小k 个特征值对应的特征向量,但需要使用符号函数量化 Y后才得到目标的二进制代码 B。
谱哈希通过构造相似度矩阵,学习了数据的局部结构。而Su等[26]在主成分分析的启发下,提出在图拉普拉斯中添加全局方差约束,同时考虑数据的全局和局部结构,使得二进制编码保留了更多的有效信息。
谱哈希学习数据分布的期望函数,对外样本进行编码。但实际应用中,数据的分布并不均匀,因此使用期望函数编码外样本的性能较低。为了改进这个问题,Bodó等[27]提出了线性谱哈希(Linear Spectral Hashing),通过寻找图拉普拉斯特征空间中的最优超平面,将原始高维数据映射成低维二进制数据。但线性谱哈希要求相似矩阵必须是非负的,因此限制了它的应用。Xia等[28]提出引用量化误差最小化,同时求解图拉普拉斯特征问题和哈希函数,哈希函数可以直接用于外样本编码。
6.3 锚图哈希
尽管谱哈希在学习数据的内部流形结构上取得不错的效果,但当样本数量n 很大时邻近矩阵的构建非常耗时,不适合在线检索。
为了克服这个缺点,Liu等[19]提出了锚图哈希。锚图哈希对训练集 X 进行聚类获得m 个聚类中心[u1,u2,···,um], 也称为锚点。由于m ≪n,聚类的速度很快。接着锚图哈希计算所有数据样本和锚点之间的截断相似度 Z。


总而言之,锚图哈希相对谱哈希在学习过程中内存和计算量需求都很小,并且保持了数据的流形结构,因此它的实际应用更广泛。因此许多哈希散列算法都基于锚图进行学习[29-30]。
然而锚图哈希存在过分依赖聚类结果的情况,错误的聚类结果会降低锚图哈希的检索性能。因此,Takebe等[31]提出基于数据的锚图选择方法(Data-Dependent Anchor Selection),认为锚图是完整数据集的低维表示,通过主成分分析降维学习锚图的效果比聚类学习更好。
6.4 迭代量化哈希
迭代量化哈希是另一个经典的哈希算法。迭代量化通过主成分分析得到投影矩阵 P,但它认为该投影矩阵不能很好地区分数据间的差异。它希望通过交替最小化方案,找到零中心数据的旋转,以便最小化该数据映射到零中心的二进制超立方体顶点的量化误差,从而得到最优的二进制代码。迭代量化哈希的定义如式(25)所示。其中旋转矩阵Q 是随机构造正交矩阵。迭代量化哈希不仅可以与主成分分析进行耦合,还可以与正交基础上的任何投影耦合,提高算法的结果[32-33]。比如,可以将迭代量化分析与典型相关分析相结合,以整合干净或嘈杂的类标签中的信息,提高代码的语义一致性。

迭代量化哈希的投影结果是各向异性的,即每个哈希函数映射的结果方差各不相同,方差大的向量将会携带更多的信息。为了平均每个哈希函数的效率,Kong等[34]提出了各向同性哈希(Isotropic Hashing),通过添加各向同性约束保证每个哈希函数的映射结果方差相等,提高了哈希检索的效率。此外,Xia等[35]对投影矩阵 P施 加了 ℓ0-范数约束,提出了稀疏投影哈希(Sparse Projection Hashing),投影矩阵的稀疏性可以提高特征选择能力和计算效率。Xu等[36]提出了双线性迭代量化哈希(Bilinear Iterative Quantization Hashing),使用了两个投影矩阵进行投影,减小了投影矩阵的维度并提高了计算的效率,投影效果与迭代量化哈希相匹配。
6.5 联合稀疏哈希
谱哈希和锚图哈希都存在两个缺点:第一是学习哈希函数过程中忽略了特征选择;第二是投影和量化是一个两阶段过程,采用了谱松弛,无法减少数据从高维到低维的信息损失。
根据数据降维和聚类领域的研究,提高哈希函数特征选择能力的一种可行方法是增加哈希函数的稀疏性。因此,Zheng等[37]结合了稀疏表示和图拉普拉斯,提出了图正则化稀疏编码(Graph Regularized Sparse Coding)。Zhu等[20]提出稀疏哈希,在图正则化稀疏编码的基础上增加解的非负性约束,进一步提高原始数据与二进制编码间的语义相似性。Ding等[38]提出了稀疏嵌入哈希(Sparse Embedded Hashing),利用线性嵌入方法将稀疏表示和主成分分析的结果结合起来,使得结果同时保留了主成分分析的有用信息和稀疏性。
然而以上的方法学习稀疏字典的过程较慢,并且没有解决谱松弛带来的信息损失问题。因此,联合稀疏哈希(Joint Sparse Hashing)[39]提出使用 ℓ2,1-范数来提高投影矩阵的特征选择能力,并且采用一步法模型交替求解投影和量化两个子问题。
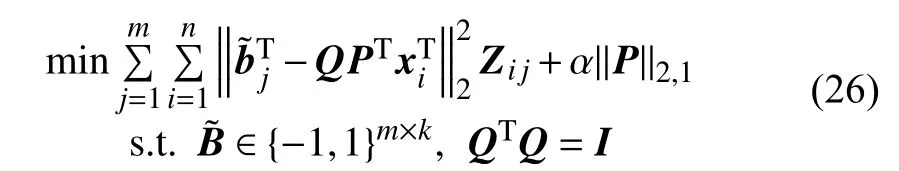

6.6 离散谱哈希
根据本文第4部分提出的离散约束问题,上文介绍的各种算法都存在一定程度的离散松弛问题。在连续空间中求解原始数据的投影或者哈希代码然后量化成二进制代码的过程增加了原始空间到离散空间的信息损失。
尽管离散约束难以求解,但Liu等[18]通过惩罚离散代码与引入的连续变量之间的距离直接求解离散代码,提出了离散图哈希。但离散图哈希的平衡约束和不相关约束依然工作在连续空间中。Hu等[40]提出了类似离散图哈希模型的角度重构嵌入方法(Angular Reconstruction Embedding),但使用了余弦距离计算二进制代码与原始数据的距离,并且可以同时学习投影矩阵。角度重构嵌入方法在离散空间中保持了离散约束,但没有保留原始数据的局部结构。
为了更好地求解离散代码,Hu等[41]提出了离散谱哈希(Disctrete Spectral Hashing),结合了谱哈希和迭代量化哈希的思想,将两步法合成一步,交替求解问题。具体算法如式(27)所示。

其中,第一项是图拉普拉斯,第二项是类似迭代量化哈希的旋转操作。式(27)中虽然使用了连续值 Y,但是离散代码 B并没有单独求解,依然保持了二值性和平衡性的离散约束。而不相关性约束,放松到连续空间Y 中。由于 Y和Q 都是不相关的,它们相乘的结果也是不相关的,则 B的求解结果也是不相关的,因此B也能保持不相关约束。从而较好地保持了离散约束。此外,由于连续值依然在谱哈希中求解,故能保持原始数据的流型结构。
7 实验
7.1 评估标准
采用传统的评估指标,包括汉明排名和哈希查找。具体来说,汉明排名侧重于整个检索项目的质量,而哈希查找只处理检索到的最高项目。
平均精度(MAP)是汉明排名评价。平均精度判断每个测试数据是否检索到正确的邻近数据。此外,哈希查找根据查询的半径为2的汉明球内的检索项来计算{召回率,F-值}分数。其中召回率(recall)是哈希查找评价,判断检测到的正确数据与总的正确数据的比例。F-值(F-measure)是哈希查找评价,由于精度和召回率评估存在偏差情况,F-measure是综合两者进行加权判断。此外,还可以通过精度(precision)进行量化。精度是哈希查找评价,侧重于近似最邻近数据的检索质量。在汉明半径为2的范围内,判断最邻近的数据是否检索正确。由于本文研究的哈希方法是无监督方法,因此哈希投影之后直接评估保留的最近邻的数据。
7.2 常用数据集
哈希检索常用的数据集包括MNIST[42-43]、CIFAR-10[44-45]、Caltech-101[46-47]、SUN397[48-49]、YouTubeFaces[50-51]和NUS-WIDE[52-53]。
7.2.1 MNIST
MNIST数据集由70 000个手写数字图像组成,从“0”到“9”。这些图像都是28×28像素,不进行预处理,直接使用784维特征向量用于表示。
7.2.2 CIFAR-10
CIFAR-10由60 000个微小图像组成的集合,共10个对象类别(每个类别6 000个图像)。每张图像提取512维的GIST矢量[54]作为图像特征。
7.2.3 Caltech-101
Caltech 101数据集包含9 145张训练图像,由102类对象类别组成,包括一个背景类。每张图像使用稀疏编码技术将缩放不变性特征变换(Scale-Invariant Feature Transform)[55]预处理后的数据压缩成1024维数据作为表示。
7.2.4 SUN397
SUN397数据集由102类对象类别组成,包含106 953张训练图像(每个类别的图像个数80~2 000张不定)。每张图像使用主成分分析从12 288维深度卷积激活特征(Deep convolutional activation features)[56]提取的数据中提取出1 600维特征向量作为图像特征表示。
7.2.5 NUS-WIDE
NUS-WIDE由269 648个多标签图像组成。与MNIST等数据集每张图片都具有唯一标签不同,NUS-WIDE中每张图片都拥有多个标签,两张被认为相似的图片中至少共享一个相同标签。一般选取常见的21个标签,比如动物、人类、建筑物等,构成训练集和测试集样本。每个样本使用缩放不变性特征变换将图像表示为500维数据。
7.2.6 YouTubeFaces
YouTube Faces数据库包含1 595个不同人物的3 425个面部视频。一般选择具有至少500张面部图像的样本来构建子集,总共370 319个样本。每个样本预处理成1 770D维的LBP向量[57]作为图像特征表示。
7.3 实验结果
本文在MNIST、CIFAR-10和YouTubeFaces上进行了实验。MNIST随机选取了6 900张图片(每类690张)作为训练集,以及1 000张图片(每类100张)作为测试集。CIFAR-10随机选取了5 900张图片(每类590张)作为训练集,以及1 000张图片(每类100张)作为测试集。YouTubeFaces随机选取了图像数目大于2 000张的类别共38个类,总共103 390张图片,其中每类选取100张图片构成测试集,其余图片作为训练集。
本文选取谱哈希[58]、锚图哈希[59]、迭代量化哈希[60]、联合稀疏哈希[61]和谱旋转谱哈希(Large Graph Hashing with Spectral Rotation)[62-63]作为对比算法。
MNIST 数据库上的结果如表1、图2和图3所示。从表1中可以看出联合稀疏哈希和谱旋转谱哈希表现最好。由于联合稀疏哈希具有稀疏特征选择能力,因此随着编码长度的增加,它的检索平均精度也逐步增加,优于其他算法。而谱旋转谱哈希由于保持了离散约束,因此在短编码尤其是12 bits的时候表现优异;但它不具备稀疏特征选择能力,因此随着编码长度增加效果不如联合稀疏哈希。从图2和图3中,可以看出联合稀疏哈希获得最好的召回率。但值得注意,联合稀疏哈希在短编码的召回率过高,存在将大量的图像都映射成相同的编码的情况,这种情况在CIFAR-10数据库中表现更加明显。

表 1 MNIST数据库下各算法的平均精度结果Table 1 Results of MAP of different algorithms on the MNIST database
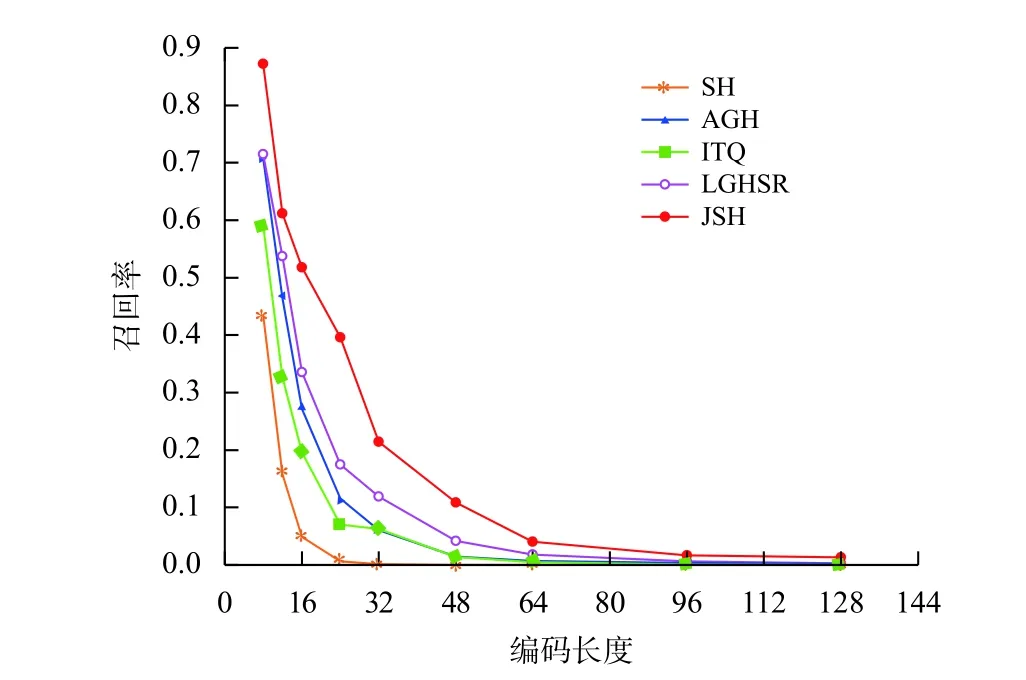
图 2 MNIST数据库下各算法的召回率Fig.2 Results of recall of different algorithms on the MNIST database

图 3 MNIST数据库下各算法的F-值Fig.3 Results of F-measure of different algorithms on the MNIST database
CIFAR-10数据库上的结果如表2、图4和图5所示。由于8~24 bits的编码中,联合稀疏哈希的召回率都为100%即将所有的编码映射成同一个编码,因此它的平均精度并不正确。所以8~24 bits的编码中认为谱旋转谱哈希的平均精度更高。但随着编码长度的增加,联合稀疏哈希的平均精度超过了谱旋转谱哈希。从图4和图5中,可以看出联合稀疏哈希和谱旋转谱哈希都获得了最好的表现。
YouTubeFaces数据库上的结果如表3、图6和图7所示。由于YouTubeFaces数据库的庞大,而且人脸数据库适合稀疏特征选择,因此联合稀疏哈希的表现远远超过了其他算法的表现,获得了最佳的结果。在YouTubeFaces数据库下,迭代量化哈希的表现在所有编码长度上超过了谱旋转谱哈希,这一方面表现出迭代量化哈希可以平衡数据的方差的优势,另一方面说明了谱旋转谱哈希过于考虑离散代码的平衡性情况下有时候会失去效率。
8 总结
本文介绍了哈希检索方法的基础知识以及经典的基于数据的无监督的哈希算法。此外,进行了一系列实验,以比较现有各种基于哈希的方法的性能。这些方法都是在线检索方法,表现了哈希检索算法的效率和可行性。往后,将继续研究新颖的哈希散列方法以便在保留更多局部信息、减少信息损失的同时,保持二进制代码的离散约束,避免哈希检索性能对于二进制代码长度的敏感性。为了提高哈希检索方法的应用性,将继续探索提高哈希散列学习的离线训练和在线编码的效率,以及短二进制编码的准确率来达到时间和空间上的高效性。

表 2 CIFAR-10数据库下各算法的平均精度结果Table 2 Results of MAP of different algorithms on the CIFAR-10 database

图 4 CIFAR-10数据库下各算法的召回率Fig.4 Results of recall of different algorithms on the CIFAR-10 database
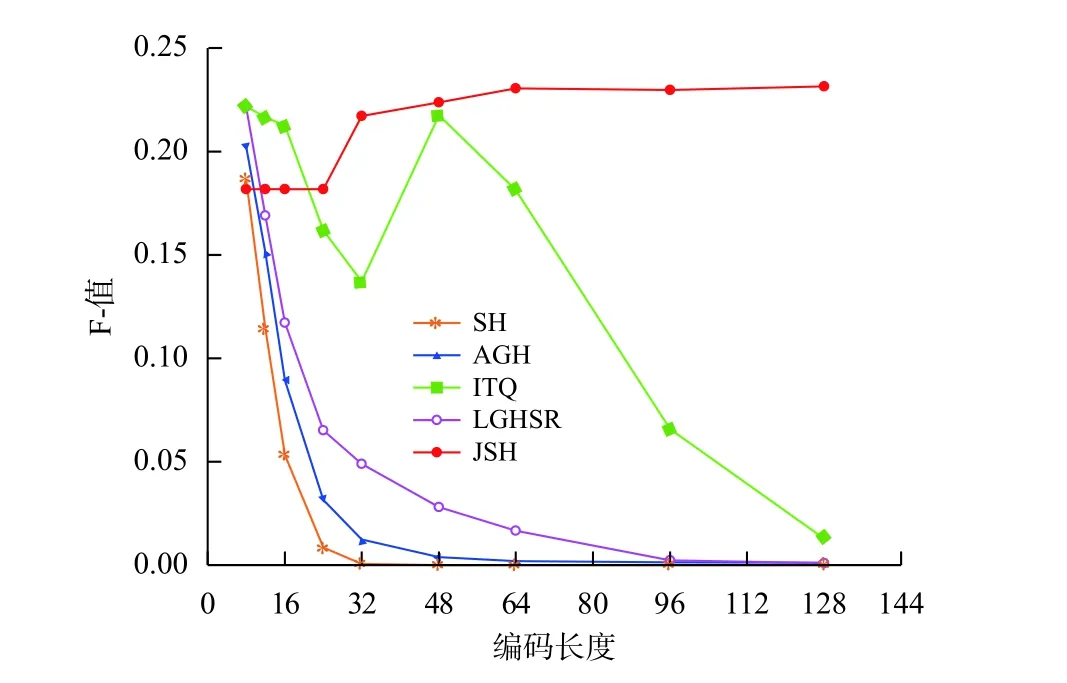
图 5 CIFAR-10数据库下各算法的F-值Fig.5 Results of F-measure of different algorithms on the CIFAR-10 database

表 3 YouTubeFaces数据库下各算法的平均精度结果Table 3 Results of MAP of different algorithms on the YouTubeFaces database
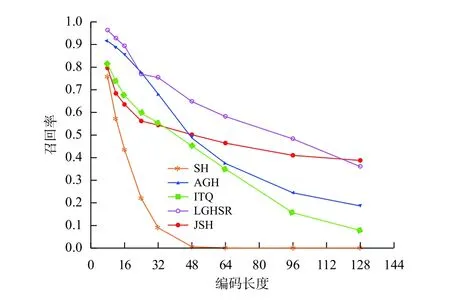
图 6 YouTubeFaces数据库下各算法的召回率Fig.6 Results of recall of different algorithms on the YouTubeFaces database

图 7 YouTubeFaces数据库下各算法的F-值Fig.7 Results of F-measure of different algorithms on the YouTubeFaces database
