结合全局种子最优局部扩展的跨网络用户识别*
2020-06-11申德荣聂铁铮
李 想,申德荣,冯 朔,寇 月,聂铁铮
东北大学 计算机科学与工程学院,沈阳110819
1 引言
随着互联网的飞速发展,社交网络极大地改变了人们的生活方式。例如,微博为网民提供短消息分享发布服务,抖音为网民提供短视频分享服务,知乎为网民提供了问答知识服务,可见由于不同社交网络侧重于不同服务方式,用户通常选择活跃于多个社交网络中。然而,为准确高效地进行商业产品推荐、社交好友推荐、网络安全以及合并通讯录等用户服务,如何有效集成分散于不同社交网络中的用户数据,尤其是跨社交网络用户识别问题,是目前急需解决的关键问题。
针对跨社交网络用户识别问题,现有方法[1-7]主要基于已匹配用户的信息,包括属性信息、行为信息和结构信息。本文主要利用用户结构信息进行用户识别。
传统基于用户结构信息的方法通常迭代地对待匹配用户进行识别,在每次迭代过程中,仅识别部分相似度较高的待匹配用户,其中相似度函数通常利用用户共同邻居数量进行衡量,共同邻居数量越多,其相似性越大,反之越少。若用户相似性大于指定阈值,则可视为新匹配用户,并作为下次迭代过程的输入。
如何快速有效地选取用户候选集是传统方法中的关键性问题,主要有两种用户候选集选取方式[8]:
(1)枚举方式[9-10]:该类方法从剩余的待匹配的用户中选择候选匹配用户。枚举的用户候选集合选取方式在最坏情况的时间消耗是N×N(N为社交网络中用户的个数),虽然能处理大量待匹配用户,但是具有较高的时间代价。
(2)局部扩展:现有局部扩展方法[4-5,11-12]是从已知匹配用户的邻居中选取候选匹配用户。局部扩展的用户候选集合选取方式时间代价小,但是仅仅通过邻居进行扩展不能处理大量的潜在的匹配用户,准确性较低。
目前大部分方法在候选匹配用户集选取过程中,难以有效平衡时间代价与准确率召回率之间的关系,无法在较低的时间内精准选取候选匹配用户集合。
分析已有方法,具有如下几点不足:
(1)存在冷启动问题,当已知匹配用户数量过少时,难以区分匹配用户,将严重降低匹配结果的准确率与召回率。
(2)在候选匹配用户集选取过程中,难以有效平衡时间代价与准确率召回率之间的关系,无法在较低的时间内精准选取候选匹配用户集合。
针对上述不足,本文的贡献如下:
(1)针对已知匹配用户数量过少的问题,提出了全局种子扩充模型。根据已有的少量种子节点对网络中的其他节点进行表示,对含有丰富信息的节点进行匹配,丰富种子节点。
(2)针对无法在较低的时间内精准选取候选匹配用户集合,提出了最优局部扩展模型。给定种子节点,找到源网络中种子节点的邻居节点在目的网络中的最优匹配节点。
(3)提出了结合全局种子最优局部扩展的跨网络用户识别框架,并在真实数据集和模拟数据集上设计对比实验,证明了本文方法具有一定的优势。
2 相关工作
现有研究主要基于已匹配用户的信息,包括属性信息、行为信息和结构信息,建立二分类模型进行用户识别。
传统基于用户结构信息的方法通常迭代地对待匹配用户进行识别,在每次迭代过程中,仅识别部分相似度较高的待匹配用户,若用户相似性大于指定阈值,则可视为新匹配用户,并作为下次迭代过程的输入。在传统识别方法中,用户候选集选取方法是关键环节,主要有两种用户候选集选取方式:(1)枚举方式;(2)局部扩展。
有关枚举方式候选集选取,文献[9]基于网络中的邻居属性,先只匹配两个网络中度高的用户,让度高的用户成为候选匹配用户,之后逐渐降低可成为候选匹配用户的阈值条件,度较低的用户也可进行匹配;文献[2]提出了一种半监督多目标框架,基于用户属性、用户话题和用户风格的异构网络,建立多目标的用户匹配模型;文献[10]提供了一个用于分析社交网络中的隐私和匿名化的框架,并开发一种针对匿名社交网络图的去匿名识别算法。
基于枚举方式候选集选取方法[9-10]建立的用户匹配模型作用于两个网络中待匹配的用户。这种方法在最坏情况的时间消耗是N×N(N为网络中的用户个数),当社交网络中的用户量是百万级甚至是千万级别,枚举方式候选集选取方法虽然保证了准确性,但是具有较高的时间代价。
有关局部扩展候选集选取,文献[4]从社交网络的用户关系、概要属性和时空信息中抽取特征,基于稳定婚姻匹配约束用户的映射关系;文献[11]提出一种基于规则的传播算法,首先根据用户的网络拓扑属性的邻居属性生成两个网络中的候选匹配用户,然后根据用户的属性信息识别匹配的用户;文献[12]提出了一种基于能量模型综合考虑局部一致性和全局一致性的用户识别模型;文献[13]提出了基于朋友关系的用户识别框架,基于用户网络属性中的邻居建立半监督传播算法。
文献[5]在选取候选匹配用户时候,从已经匹配用户的两层内的邻居选取候选匹配用户,准确性有一定的提高,但是没有考虑如何给出适合的扩展范围。
上述局部扩展候选集选取方法大多选取已知匹配用户的邻居作为候选匹配用户,但是存在一个问题:在寻找源网络中已匹配用户的邻居对应于目的网络中的匹配用户时,未知的匹配用户不一定在目的网络中已匹配用户的一层邻居上,可能存在于已匹配用户的一层、两层、三层甚至多层邻居。因此该方法虽然节省时间,但是准确性有待提高。
有关基于迭代的用户匹配方法存在着冷启动问题,主要解决思想是优先匹配能传播更多信息的用户来加快迭代过程。文献[14]将用户的度作为用户含有信息量的评判标准,在识别两个网络中的用户时,优先识别一些度较高的用户;文献[15]挖掘了用户社区信息,先将两个网络中划分好的社区进行社区级别的匹配,然后在两个网络间匹配好的社区进行用户级别的匹配,最后去除社区概念将两个网络之间的用户进行全局匹配。
综上,目前大部分方法在候选匹配用户集选取过程中,难以有效平衡时间代价与准确率召回率之间的关系,无法在较低的时间内精准选取候选匹配用户集合。同时由于已匹配节点和用户信息稀疏,导致冷启动问题严重和识别准确性低。
本文提出结合全局种子最优局部扩展的跨网络用户识别方法,能够有效改善冷启动问题,并且在显著提高用户识别的召回率和准确率同时具有较低的时间开销。
3 问题定义
给出两个网络和已知的匹配用户集合(下面描述中用种子集合描述),目标是找到两个网络之间的匹配用户集合(下面的描述中用节点替代用户)。本章主要介绍跨社交网络的用户识别的定义和问题描述。
定义1(社交网络)给定G(V,E) 来表示社交网络,其中v节点表示用户,V代表节点的集合,E代表用户节点间的关系(边)的集合。Gs表示源网络,Gt表示目的网络。
定义2(跨网络用户识别)给定两个网络:源网络Gs和目的网络Gt,跨网络用户识别的任务是预测分别属于两个网络的用户是不是现实一个人。

当是一个人时,函数值为1,否则为0。
定义3(种子节点)在源网络和目的网络两个网络之间已经匹配出来的节点,例如源网络中的节点和目的网络中的节点是已匹配节点,则是一对种子节点,A表示种子集合。
4 跨社交网络用户匹配模型
本文从两方面来提高用户识别的准确性。首先,将节点根据到少量种子的距离进行向量表示,将向量中含有丰富信息的节点作为候选节点进行匹配,将稀疏的种子节点进行扩充来解决冷启动问题。然后,在保证较低时间复杂性的情况下,基于已匹配的节点进行最优局部扩展,来匹配大量潜在的候选匹配节点。
此模型包括全局种子扩充和最优局部扩展两个阶段,如图1 所示。
在第一阶段,基于节点到种子节点的距离进行向量化表示,对两个网络中含有丰富信息的节点进行相互匹配,以此来扩充种子节点对的数量。

Fig.1 Cross-network user matching model图1 跨网络用户匹配模型
在第二阶段,基于种子节点进行最优局部扩展来提高局部扩展的范围的同时降低时间开销。寻找源网络中的已匹配用户的邻居中的待匹配用户是从目的网络的已匹配用户的n层邻居中寻找,其中提出全局最优节点和局部最优节点的概念降低n层邻居的层数和分支达到分支限定的作用。
在第一次匹配完成后,更新种子节点的集合,再次进行第二阶段的最优扩展,实现节点匹配的迭代过程。
5 全局种子扩充模型
根据已知的少量种子节点,对网络中的其他节点进行向量表示。将向量中含有丰富信息的节点作为候选节点进行匹配,将大于阈值的节点添加到种子集合中,完成全局种子节点扩充。
5.1 基于种子节点的节点向量化表示
将网络中的节点到种子节点的距离进行向量化表示。
初始给定有少量种子节点aij(源网络中节点和目的网络中的节点是已匹配的用户),将这些种子节点作为参照点,将网络中的待匹配节点到种子节点的距离进行向量化表示。如式(1)所示,将用户v到已匹配用户ai的距离进行向量化表示,表示为vec(v),其中d(v,a)代表用户到已知匹配用户的距离。

从种子节点逐层扩展,在扩展的过程中丰富节点的向量信息,如图2 所示。
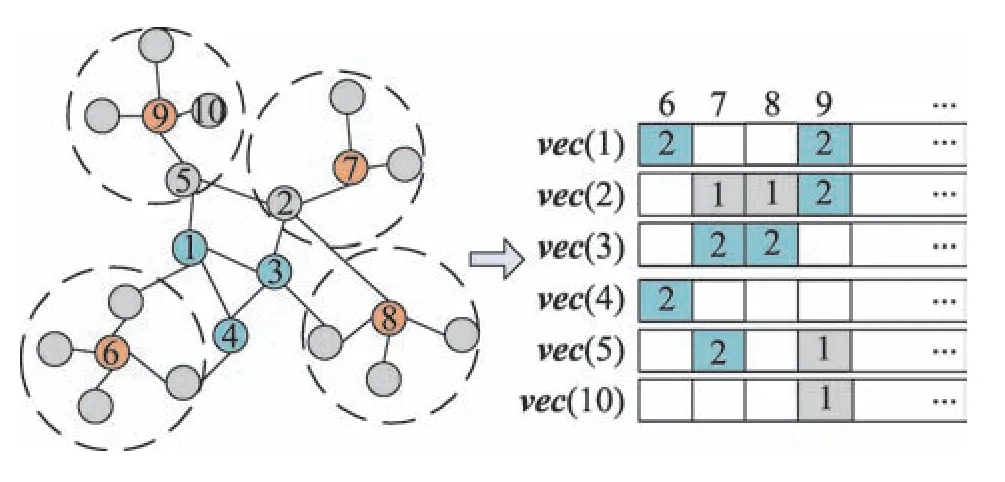
Fig.2 Node representation process based on seed nodes图2 基于种子节点的节点表示过程
橙色节点代表网络中的种子节点,从橙色的种子节点逐层扩展(最多扩展6 层)。例如,灰色节点和蓝色节点分别为距离种子节点为1 和2 的节点。在扩展的过程中,将对应的距离信息记录在遍历到的节点的向量中。节点表示的算法如下:
算法1基于种子节点的节点向量生成算法
输入:社交网络G种子集合A,阈值k。
输出:社交网络G。

在第2 行、第3 行,读取已知种子节点中的一个,并将这个已知的种子节点初始化;第8 行、第9 行计算其他节点到已知的种子节点的距离;第10 行~第12行记录节点信息的丰富程度(Info),Info值高的节点被认为是节点的向量信息丰富的节点,第5.2 节对Info指标进行说明。
5.2 全局种子扩充模型
在两个网络中,选取含有丰富信息的节点作为候选匹配节点,进行相互匹配,将大于阈值的节点添加到种子节点集合。
评价节点的信息的丰富度有三个指标:节点向量所具有的有效维度dim、节点连通的种子节点的个数link_nodes和节点连通种子节点的方向个数dir。下面分别定义并且介绍这三个指标。
节点向量所具有的有效维度dim见式(2):
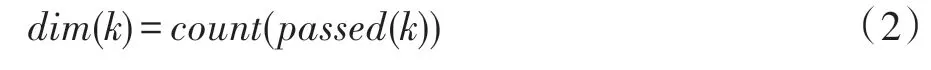
其中,passed(k)为节点k被种子节点遍历时,被遍历节点k记录下来的所有经过k节点的种子节点集合。节点向量所具有的有效维度dim为passed(k)的个数。
节点连通的种子节点的个数link_nodes见式(3):
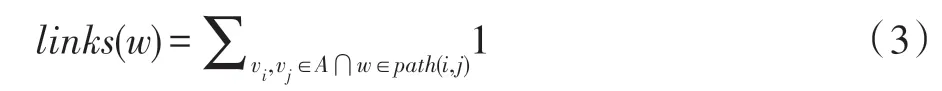
其中,path(i,j)为种子节点i到种子节点j路径上的节点的集合;link_node(k)为种子节点之间被节点k连接的次数。
节点连通种子节点的方向个数dir见式(4):
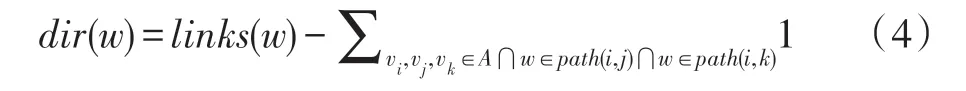
如果节点在两个种子节点连接的路径上没有其他种子节点的出现,节点连通种子节点的方向个数dir就是节点连通的种子节点的个数link_nodes,一旦在两个种子节点连接的路径上出现其他种子节点,相应的方向数就减1。例如图3 所示。
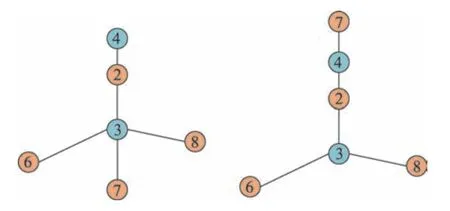
Fig.3 dir calculation example diagram of node图3 节点的dir 计算示例图
左侧图中的节点3 出现在种子节点2 到6,2 到7,2 到8,6 到7,6 到8 和7到8的连接路径共6次,link_nodes(3)和dir(3)都是6。而右侧图中的节点3 出现在种子节点2 到6,2 到8,6 到7,6 到8 和7 到8 的连接路径共5 次。link_nodes(3)的值为5,因为种子节点2 在6 到7 和6 到8 之间出现,所以dir(3)的值是3。
节点的信息丰富度用变量Info表示,见式(5):
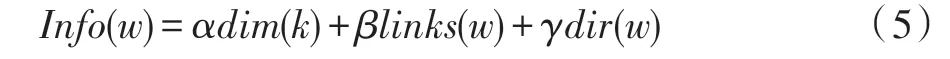
在全局种子丰富的过程中选取Info达到阈值k的节点进行匹配。参数α(α为关于种子节点个数的可变参数)、β、γ和阈值k的选取在实验部分第7 章进行讨论。
下面给出全局种子节点扩充算法。
算法2全局种子扩充算法
输入:社交网络Gs和Gt,分数阈值scr,Info阈值k,种子集合A。
输出:种子集合A。

在第1 行~第5 行,选取源网络中向量信息丰富的节点,即节点的Info值大于阈值k的节点;在第6行~第10 行,选取目的网络中向量信息丰富的节点,即节点的Info值大于阈值k的节点;在第11 行~第15行,将两个网络中信息丰富的节点进行匹配,将匹配结果大于阈值的节点加入到种子集合中,相似度分数由式(6)给出。
6 基于种子节点的最优局部扩展模型
给定种子节点,找到源网络中种子节点的邻居节点在目的网络中的最优匹配节点。
6.1 基于种子节点扩展的搜索范围
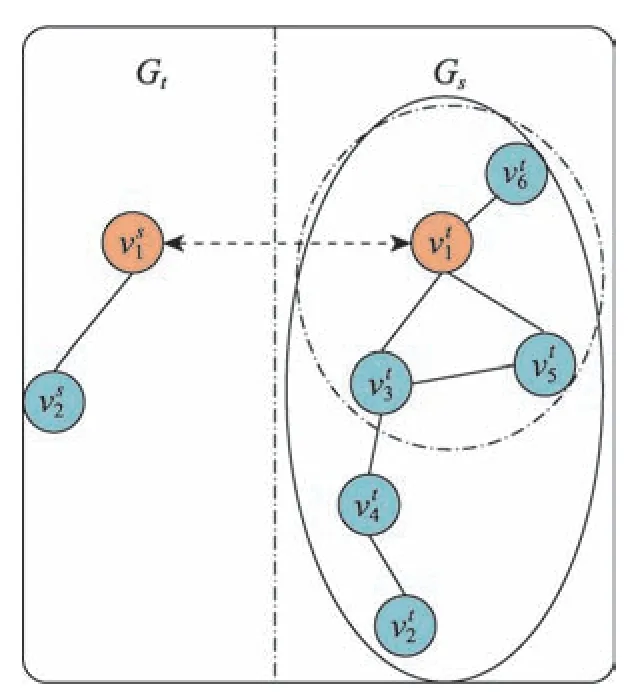
Fig.4 Search range based on seed node extension图4 基于种子节点扩展的搜索范围
6.2 最优局部扩展模型
基于种子的最优局部扩展模型找出在目的网络中以种子节点为根的树的最优搜索范围,并且在范围内找到最优的匹配节点。
在现有基于种子扩展的算法中都是基于直接邻居进行扩展的,但是这样存在一个问题。如图5,图中<A,a>是一对种子节点,从Gs中A的邻居E向Gt中a的邻居识别。由于只能在a的邻居中识别,因此可能错误匹配到其他节点或者是匹配不到。因为在真实世界中,存在A中第一跳邻居E和a的第二跳邻居e对应的事实。
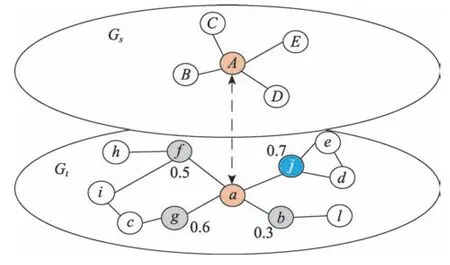
Fig.5 Process of expansion of the first layer图5 第一层扩展匹配过程
为解决上述存在的问题,在匹配过程中,需要将目标网络的种子节点的搜索范围进行扩大。但是考虑到简单扩大带来的时间损失和扩展如何收敛的问题,下面提出了最优局部扩展策略。本文不同于已有算法,采用局部历史最优和全局最优的思想来进行剪枝的决策,进行节点的匹配。其中,局部最优节点是在每个分支路径中分数最高的节点;全局最优节点是在上一次扩展中分数最高的节点。
下面通过例子说明,如图6 所示。
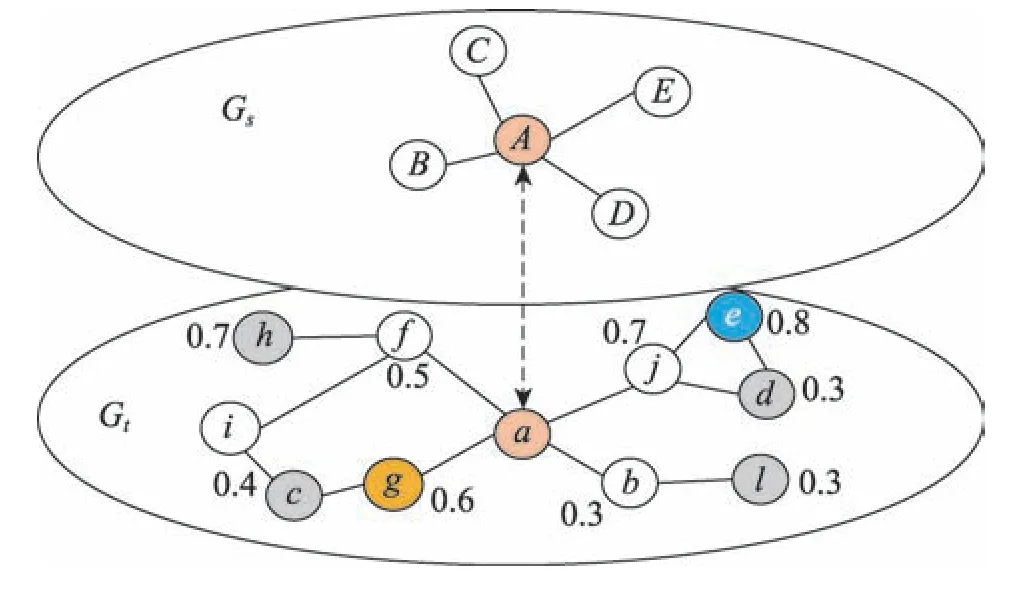
Fig.6 Process of expansion of the second layer图6 第二层扩展匹配过程
假设给定源网络Gs、目标网络Gt和种子集合,目的是找Gs中A的邻居E在Gt中的对应节点。
节点匹配过程:
第一次扩展:令a的邻居f、j、g、b四个节点分别计算和E的相似性,j的分数最高为全局最优,下一次扩展时,所有节点向它靠近。
第二次扩展:扩展全局最优节点j的所有邻居,扩展非全局最优节点f、g、b中距离上一次全局最优节点j距离最近的节点h、c、l。此时,在分支扩展中从g到c出现分数降低,g为这个分支上的局部历史最优,从c回退到g。
不断扩展,最后当全局最优节点不变时,算法结束。
算法3最优局部扩展算法
输入:社交网络Gs和Gt,种子节点,种子节点集合A。
输出:更新后的种子节点集合A。

第1 行,找到源网络中种子节点的全部邻居和目的网络中对应的节点;第2 行、第3 行,初始化,将种子节点入栈作为全局最优节点;第4 行~第15 行,基于种子节点找到源网络中种子节点的邻居在目的网络中对应的节点;第4 行,如果全局最优节点不变时,算法收敛,匹配结束;第8 行、第9 行,如果是全局最优节点,则扩展全局最优节点的所有邻居,入栈;第11 行~第13 行,如果是局部最优节点,则只扩展一个分支;在第14 行更新全局最优节点是根据匹配函数得到的分数进行评价的,相似度分数根据共同邻居确定,相似度分数由式(7)给出。
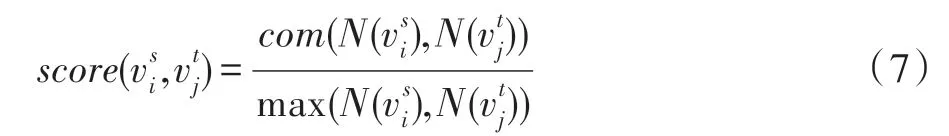
7 实验与结果
本章分别在模拟数据集(S_DS:simulated data set)和真实数据集(R_DS:real data set)上对提出的方法进行实验评估。
7.1 实验数据集
实验采用的数据集分为两种:S_DS 和R_DS。
由于一组R_DS 具有特征性不具有普遍性,因此通过GNP(generate a graph withNnodes and edges with probabilityp)算法生成S_DS 来模拟真实网络,保证提出的方法得到更具备普遍性的实验结果。
GNP 算法以概率p将N个节点进行连接,生成一个无向图G,在无向图G的基础上,以概率v1删除G上的节点并且以概率e1删除G上的边生成图G1。同时,以概率v2删除G上的节点并且以概率e2删除G上的边生成图G2,表1 为S_DS 的基本信息。

Table 1 Simulated data set表1 模拟数据集
真实数据(R_DS)来自于社交网络facebook。其中,facebook_links 是facebook 上的好友关系的数据集,facebook_wall是facebook 照片墙功能模块的数据集。表2 为R_DS 的基本信息(https://pan.baidu.com/s/1OHxljahQWOh6JRjUGX4Bkw,提取密码15lv)。

Table 2 Real data set表2 真实数据集
7.2 对比实验与评估
本文提出的方法GLE(global seed extension and optimal local extension)与MNA(multi-network anchoring)[4]、ALLEN-MLP(ALLEN based on multilayer perceptron)[5]算法进行对比实验。
MNA:从社交网络的用户关系、概要属性和时空信息中抽取特征,基于稳定婚姻匹配约束用户的映射关系。
ALLEN-MLP:结合用户的家乡的位置信息,基于种子节点的二层邻居进行局部扩展。
GLE:基于少量种子将种子节点丰富,然后进行最优局部扩展。
本文提出的第一阶段的应对冷启动的GSE(global seed expansion)方法与ECRN(emergence of scaling in random networks)[14]、CED(community-enhanced de-anonymization)[15]算法进行对比实验。
ECRN:将用户的度作为用户含有信息量的评判标准,在识别两个网络中的用户时,优先识别一些度较高的用户。
CED:挖掘了用户社区信息,先将两个网络中划分好的社区进行社区级别的匹配,然后在两个网络间匹配好的社区进行用户级别的匹配,最后去除社区概念将两个网络之间的用户进行全局匹配。
评估指标有种子扩展率Rate、准确率Accuracy和召回率Recall。其中种子扩展率Rate(扩充的种子节点的个数除以所有种子节点的个数)作为第一阶段种子扩充效果的评价指标,准确率和召回率作为第一阶段和第二阶段总体效果的评价指标。
7.3 实验和结果
本节设置多个实验来验证本文方法的有效性和正确性。
(1)阈值参数k的选择
在基于种子进行扩展的过程中,节点形成向量同时节点保存Info信息。然后选取含有丰富信息的节点作为候选匹配节点,即Info值大于阈值参数k的节点。下面通过实验观测选取不同阈值对结果的影响。实验结果如图7、图8所示。
在S_DS和R_DS上分别选取占节点总数的0.1%、1%、5%和10%的种子节点。统计节点关于Info值的分布信息如图7 所示,图7(a)是在S_DS 上的结果,图7(b)是在R_DS 上的结果。从图7 可看出,节点的个数随着Info值的增加而减少。Info值小的节点虽然多,但是可以被识别为种子节点的却很少。图8 所示为能够被识别出来的候选匹配节点比例随着不同的Info阈值k的变化曲线。图8(a)是在S_DS 上的结果,图8(b)是在R_DS 上的结果。
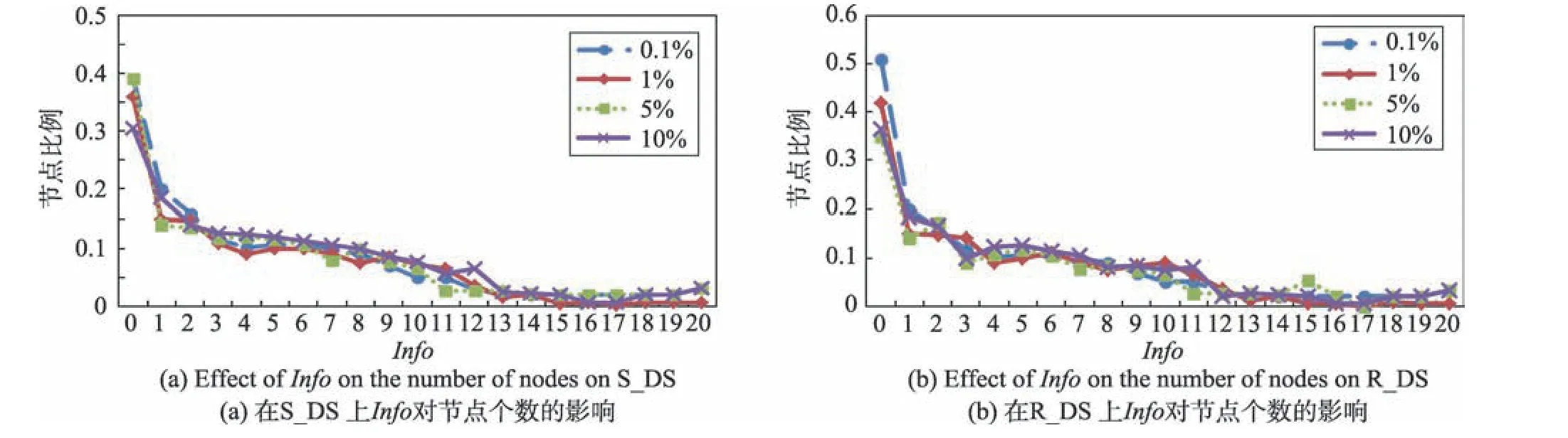
Fig.7 Effect of Info on the number of nodes图7 Info 对节点个数的影响

Fig.8 Proportion of identifiable nodes at different thresholds图8 不同阈值的节点的可识别比例
实验表明节点Info的值越小,这个节点所带有的信息越少,越不容易识别。综上,在选取Info的阈值时,选取Info阈值为8,即只有Info值大于等于8 的节点,才能作为候选节点进行跨网匹配,来丰富种子节点。
(2)不同算法的种子扩展率Rate对比
在S_DS和R_DS上分别选取占节点总数的0.1%、1%、5%和10%的种子节点。统计不同算法扩展种子节点的比例Rate 如表3 所示,从表3 中可以看出在种子节点稀疏的时候,GSE 模型明显好于其他模型。
(3)不同匹配算法的准确性和召回率的对比
在S_DS 和R_DS 上,选取0.1%、1%、5%、10%的种子节点进行实验,评估结果的准确性如图9 所示,图9(a)是在S_DS 上的结果,图9(b)是在R_DS 上的结果。评估结果的召回率如图10 所示,图10(a)是在S_DS 上的结果,图10(b)是在R_DS 上的结果。

Table 3 Rate of seed expansion of different algorithms表3 不同算法的种子扩展比例Rate
实验结果显示,在种子节点稀疏的时候,GLE 效果明显比MNA 和ALLEN-MLP 要好,主要是GLE 种子扩充发挥了作用。随着种子节点的增多,GLE 的效果比MNA 和ALLEN-MLP 要好,是因为最优局部扩展比MNA 的一层局部扩展和ALLEN-MLP 两层局部扩展具有优势。而那些没有被识别出来的节点主要是因为这些节点相对孤立,和其他节点之间的连接过少,无法进行两阶段的扩展模型。
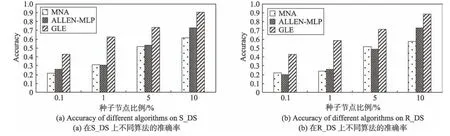
Fig.9 Accuracy of different algorithms图9 不同算法的准确率
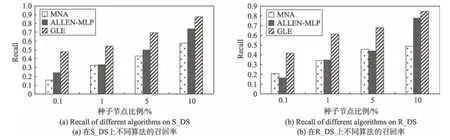
Fig.10 Recall of different algorithms图10 不同算法的召回率
(4)不同算法的运行时间对比
不同算法随着种子个数增加的运行时间如图11所示,图11(a)是在S_DS 上的结果,图11(b)是在R_DS 上的结果。
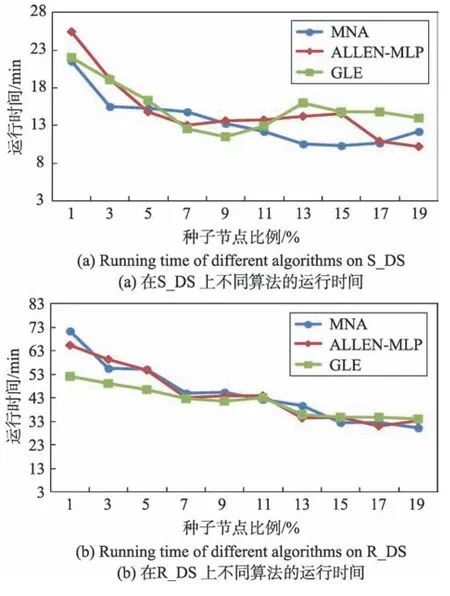
Fig.11 Running time of different algorithms图11 不同算法的运行时间
从图11 中可以看出在种子节点个数稀少的时候,GLE 的运行时间低于MNA 和ALLEN-MLP 的运行时间,说明第一阶段的种子扩充起到了降低时间的作用。随着种子节点的增多,GLE 的运行时间也没有超过局部扩展方法MNA 和ALLEN-MLP。
GLE 的第二阶段局部最优扩展模型是基于MNA和ALLEN-MLP 的准确性方面做出的改进。除此之外,GLE 有较低的时间复杂性,穷举方法的一次扩展的时间复杂性是N×N,明显高于GLE,ALLEN-MLP方法的单次扩展的时间复杂性是n×n(n为节点的平均度数),GLE 算法的单次扩展的时间复杂度为n×n+4n。
8 结束语
本文提出了结合全局种子最优局部扩展的跨网络用户匹配模型,通过全局种子扩充来增加种子数量,解决冷启动问题;根据最优局部扩展模型,有效地处理大量的潜在的候选匹配节点。同已有方法比较,本模型具有较高的准确性和召回率,且具有较低的时间开销。下一步,将结合全局种子最优局部扩展的跨网络用户匹配模型应用到多个社交网络,使其应用更加广泛。
