基于FPGA的飞行器关键点检测加速器设计与实现∗
2020-06-11
(国防科技大学计算机学院 长沙 410073)
1 引言
在航线监控、机场管理、敌军飞行器目标甄别等场景中遥感图像飞行器关键点检测起着重要的作用。近年来在关键点检测领域,人们从利用传统方法提取特描述并训练关键点检测流程[1~2],到利用深度学习、神经网络方法提取更加抽象的特征,该领域经历了短暂又迅猛的发展阶段,比较现有几个深度神经网络的性能,最终选择了VGG-19[3]作为关键点预测的深度学习框架。
FPGA以其高性能、高能效、高灵活性等优点,成为CNN加速平台研究的热点。近年来基于FPGA的CNN加速器被提出用来加速推理过程。本文中我们着重加速飞行器目标检测过程,并做出以下贡献:
1)提出了一种可扩展的飞行器关键点检测专用加速器框架,能够同时适应多种网络结构,例如VGG-S,AlexNet等。
2)开发了配套的软件工具链,支持参数提取,硬件性能预测评估、统计最优定点(16bit)格式、定位错误的层等,帮助快速完成上板工作。
3)在Xilinx Virtex-7 VC709上实现加速器,平均吞吐率达796.8GOP/s,性能功耗比为50.43GOP/s/W,吞吐率是CPU的2.95倍,性能功耗比是CPU的17.75倍。
2 背景
本节简要回顾下飞行器关键点检测的推理过程、神经网络加速器设计以及对加速器进行16位定点化的相关背景。
2.1 飞行器关键点预测
飞行器关键点预测的主体是一个VGG-19网络,首先将不同大小的飞行器图像缩放至224*224像素,输入网络进行特征提取,全连接层fc8的输出维度为10,得到飞行器的五个关键点检测主要包含四个主要操作:图像缩放(resize),卷积(conv),最大池化(max-pooling),全连接(fc)。Resize有五种插值算法,分别是:最近邻、双线性、双三次、基于像素区域关系、兰索斯插值。我们选择双线性作为缩放算法,因其在速度和上下采样两者间做了适合我们应用的折衷。卷积操作一共有五大层,卷积核的大小全部为3×3。最大池化和全连接操作此不赘述。VGG-19网络的每层输入特征和输出特征的规模如图1所示。

图1 VGG-19网络每层计算量规模
目前对网络算法进行优化的常用方法包括三种:1)采用傅里叶变换的方法,将时域运算转换为频域的乘法运算进行加速,由于基于傅里叶变换的卷积内存带宽需求很大,当卷积核尺寸较大例如7*7,9*9等才有速度优势。Jong等在文献[22]中使用了FFT算法实现了卷积运算用于神经网络的训练,由于反向传播计算梯度时卷积核尺寸比较大,因此对于训练过程的加速非常明显。还可以在此基础上添加OaA方法进行进一步优化,降低算法复杂度[17]。2)Winograd算法。Lu等在文献[23]中采用了基于快速Winograd算法的CNN加速器设计,利用线性缓冲结构实现对特征图像的复用,通用的逐元素相乘的PE,并设计多个PE增加并行性。Winograd算法特别适用于卷积核尺寸特别小的情形,其原理是通过矩阵变换减少乘法操作的次数。3)矩阵乘法。将卷积运算转为矩阵乘法则是一种非常通用的实现方式,TensorFlow等深度学习框架在GPU和CPU平台上实现卷积运算也是采用这种方式。文献[24]将卷积计算转化为矩阵乘法操作进行加速,文献[25]采用乘法脉动阵列对矩阵乘法进行加速。卷积转化为矩阵乘法时,会引起额外访存压力,所以要注意对于存储的优化。
2.2 加速器16位定点化
考虑到神经网络的训练过程需要高精度的浮点运算,但在前向推理过程可以允许较低的计算精度而不会影响最终的关键点预测或分类性能。基于这一特点,采用半精度运算部件、定点运算部件甚至位运算部件的加速器被纷纷提出。将高精度的浮点数类型量化为低精度的定点数类型,好处主要有两个方面:一是通过有效减少了数据位宽降低了对于数据存储空间和带宽的需求;二是简化了计算部件,在相同的资源限制下可以部署更多的计算部件增加并行性。二值化和三值化网络推理实现的研究成果颇多,例如文献[9~14],利用0和1表示权值和神经元的值来平衡准确性和访存效率。文献[15]中以AlexNet和VGG为例分析了采用定点运算对于网络分类性能的影响,在其实现的加速器中,所有层的网络权重参数被表示为统一规格的8位位宽的定点数,计算过程采用定点运算,相较于浮点实现的版本,网络分类正确率损失不到1%。文献[16]中采用了动态定点数的表示方法,允许不同层的网络采用不同的量化范围,从而在不增加位宽的情况保证了更高的数据精度。我们通过HLS工具链统计出精度最优的一种16位的定点格式,将之运用在加速器中。
3 加速器设计
这一部分我们首先描述系统的总体设计,在此基础上描述了加速器的工作方式。
3.1 系统总体架构及工作方式
飞行器关键点预测的系统总体架构如图2所示。主要包括四部分:主机端(Host),关键点预测专用加速器模块(Accelerator),控制模块(Control)和片外存储模块(DDR)。控制模块和主机端以及加速器模块连接,从主机端接收加速器执行所需的参数,然后传递至加速器实施控制。DDR和主机端以及加速器连接,接收从主机端传入的图像和权值等数据,将其提供给加速器进行处理,同时接收加速器的运行结果,重新传至主机端。加速器主要实现了卷积网络的部分,图像的预处理resize放在主机端实现。
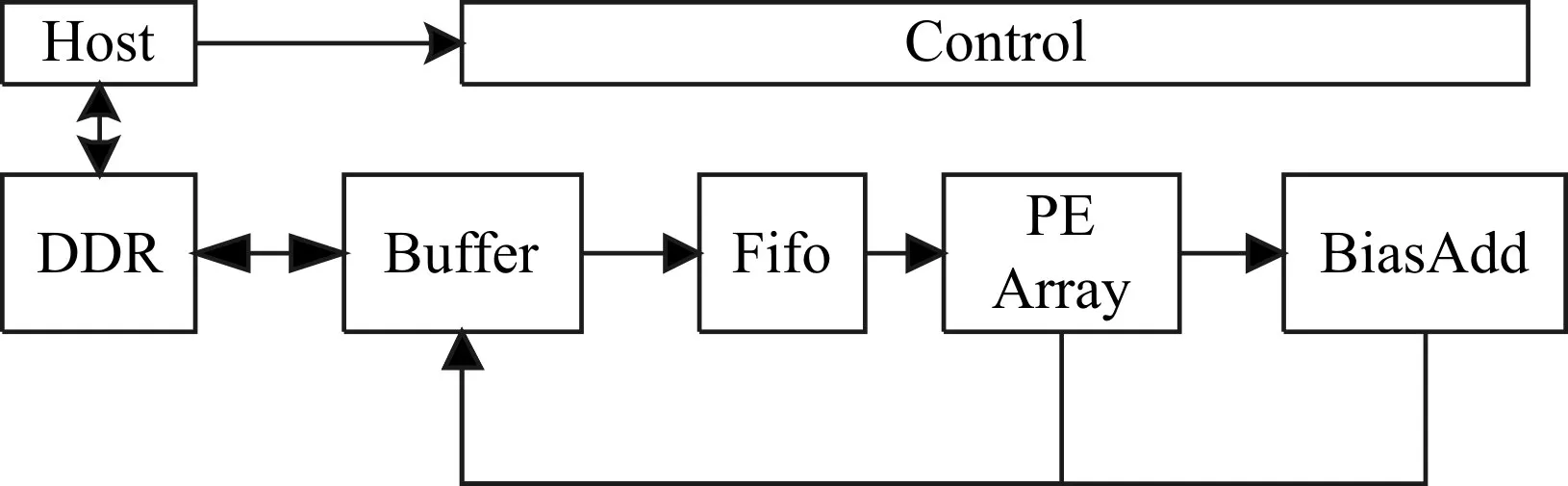
图2 系统总体架构
3.2 加速器结构及工作方式
加速器一共包含四部分:片上数据缓冲(buffer)、FIFO、计算单元(PE)阵列和偏置加法(BiasA-dd)阵列。片上数据缓冲接收DDR传入的数据,送至FIFO,FIFO将数据传送给计算单元阵列和偏置加法阵列处理,计算结果输出至片上缓冲,然后送至DDR。加速器整体架构如图3所示。

图3 加速器架构
3.2.1 计算单元阵列与偏置加法阵列
神经网络的运算有卷积、最大池化和全连接三种。卷积运算为矩阵乘法,全连接运算为向量乘法,最大池化是求矩阵最大值,所以将PE设置为实现乘累加的运算单元,一个端口srca接收输入特征数据,另一个端口srcb接收权值数据,供给卷积和全连接层使用,并且将求最大值运算额外添加到PE中,此时srcb端口不接收数据,这样VGG-19的所有运算操作均可以在PE中完成。分析图1中VGG-19每层网络的运算规模,输入特征行/列分别是:224,112,56,28,14,权值矩阵的输出通道分别是3,64,128,256,512,我们将PE阵列的列取输入特征的行/列的约数,PE阵列的行取权值矩阵输出通道的约数,并且尽可能利用完板上的DSP资源,所以将PE阵列设置为64×56大小,每周期读取64个权值参数,56个特征矩阵像素。然后判断当前层网络是否为池化,如果是则跳过偏置加法输出结果,否则当计算单元阵列完成计算,64×56个元素在64个周期内被传输至偏置加法,完成计算后将结果输出。
3.2.2 片上数据缓冲与FIFO
片上缓冲分为三部分:输入缓冲,权值缓冲和输出缓冲。权值缓冲用于存储权值矩阵、输入缓冲用于存储部分输入特征图像、输出缓冲用于存储部分输出特征图像。每组数据缓冲中都设有多个独立的存储单元,可提供多个数据访存接口,存储单元的数量取决于PE的阵列规模。鉴于计算单元阵列在每个时钟周期都需要读取64个权值参数,56个输入特征像素,所以在权值缓冲中部署了64个存储单元,在输入缓冲中部署了56+2×pad个存储单元,额外的2×pad个存储单元对应于卷积窗口滑动到输入特征图像左右边界的情况。计算单元阵列并行计算64×56个输出特征图像的元素,在输出缓冲中部署了56个存储单元,若当前层完成的是池化运算,当计算单元阵列完成计算,64×56个元素在64个周期内被写入到输出缓冲中;若当前层完成的是卷积或全连接运算,则每个周期接收从偏置加法传入的56个输出特征像素结果。
4 工具链设计
基于第三节的加速器体系结构,我们采用高级综合技术HLS实现加速器配套的工具链,本节将介绍HLS工具链的设计及如何利用HLS优化加速器性能的具体工作。

图4 工具链结构
工具链一共由五部分组成:解析Caffe[8]网络描述文件(ParseCaffe),生成硬件执行网络需要的参数(GenParam),包括指令(GenInstruction)以及数据存放内存的地址(GenAddrParam),生成硬件执行所需的数据(GenSimData),加速器原型系统(ProcessLayer),在执行网络的过程中统计了每层的数据范围(GenRange)方便后期做定点化,网络层结果对比(CompareLayer),图4给出了工具链的结构。
4.1 解析Caffe网络描述文件
代码的软件版本是基于Tensorflow框架[4],但是基于Tensorflow的python代码不易解析,故我们将Caffe框架的下的VGG-19网络描述文件prototxt作为程序的输入,将解析得到的网络数据存放到一个描述网络的向量vec_layer中,向量的每个元素代表一层,记录了该层的名字,输入特征大小,权值矩阵大小,输出特征大小,步长等所有相关信息。后面所有的操作都是在vec_layer的基础上进行操作。
4.2 生成硬件执行网络需要的参数
硬件执行网络所需的参数有两部分,一是指令序列,要配置出当前层执行需要的参数,有的可以直接从vec_layer向量中获取,例如步长,卷积核的大小,输入特征的大小等,另一些参数需要结合硬件架构计算得到参数。二是生成内存地址供上板使用,vec_addr是网络地址参数向量,每个元素记录一层网络中的输入特征地址,权值地址,输出特征地址,他们由vec_layer向量中的值计算得到。
4.3 生成硬件执行需要的数据
将每层的输入特征按照Ix,Ic,Iy的顺序、每行56个数据、以十六进制形式存储到文件中(Ix是输入特征的行,Ic是输入特征的通道数,Iy是输入特征的列)。将每层的权值矩阵按照Oc,Ic,kx,ky的顺序、每行64个数据、以十六进制形式存储到文件中(Oc是输出特征的通道数,Ic同上,kx是权值矩阵的行,ky是权值矩阵的列)。
4.4 实现加速器原型系统
神经网络加速器的主要操作分为三类:卷积操作,池化操作,全连接操作,我们分别实现这三类操作,然后依次读取vec_layer的层类型以及层参数,将之传递至函数进行运算,并保存每层的计算结果。
4.5 定点格式设计
神经网络在前向推理过程可以允许较低的计算精度而不会影响最终的关键点预测或分类性能,基于这一特点,我们尝试使用16位的定点代替32位浮点数进行推理。好处主要有两个方面:一是通过有效减少了数据位宽降低了对于数据存储空间和带宽的需求;二是简化了计算部件,在相同的资源限制下可以部署更多的计算部件增加并行性。
在实现加速器原型系统的基础上,对卷积层计算和全连接层计算模块添加了统计输入特征,输出特征,权值矩阵的模块,分析结果发现,所有层的权值矩阵范围都介于-1和1之间,我们将16位的权值格式类型设置为1-3-12(分别对应:符号为-整数位-小数位),而对于VGG-19网络的每层输入和输出特征的范围来讲,从conv1到fc8层,先逐层增加,带conv4达到最大,然后逐层减小,并且经过实验发现,对于不同类别的飞行器以及相同类别不同角度的飞行器,范围也会不同,我们统计了数据集中所有种类所有角度的飞行器conv4卷积层输入输出特征,发现其范围在2799~8684之间,取范围的上限,下限及中间的一个随机值6447,取这三张图像做实验。
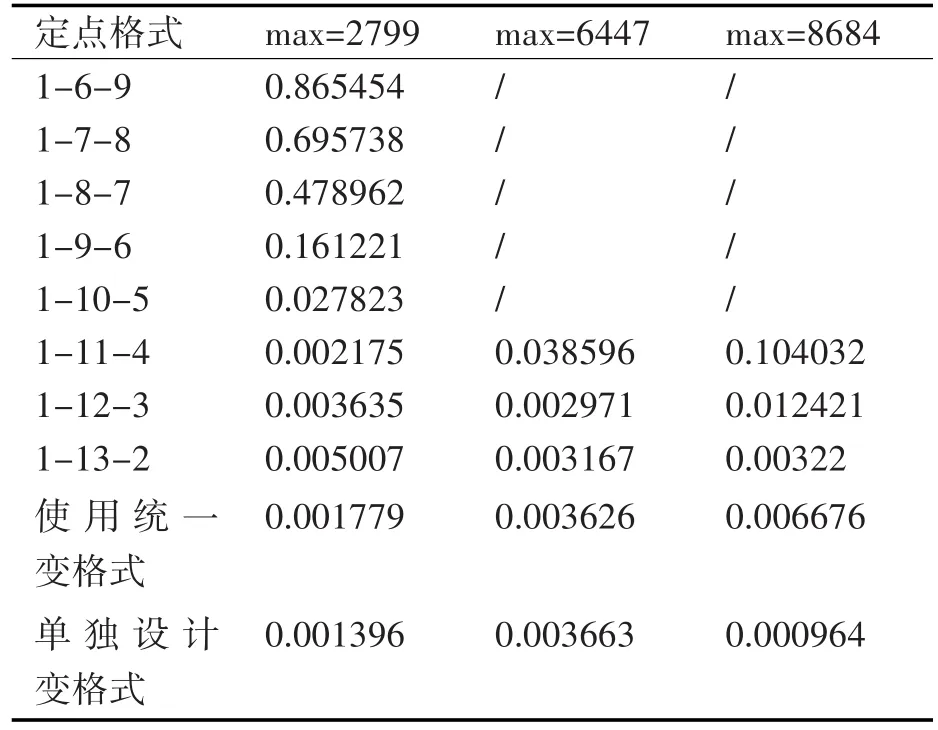
表1 不同格式下不同图像的欧式距离结果

表2 根据范围取定的格式
如表1所示,首先测试了所有层都使用统一的定点格式时这三张图片的结果误差,表中的结果为欧式距离。横轴表示这三个conv4层输入输出特征最大值的三张图像,纵轴表示格式,前8行是所有层都使用统一的格式得到的结果,可以看到这三张不同图像结果最优的格式并不一致(我们并没有展示出来当max=6447和max=8684在表中前几行格式的结果准确度,因其欧式距离误差过大不具备可比性)。第9行采用表2中前三列所示的统一的变格式得到的结果,这三个结果表示了所能达到的最好结果。但是实际的硬件实现不可能采取每类飞机用不同的方法,所以这只是表示最理想的一种情况。综合前两个实验的结果,选取了折衷的一种格式,即表2的第5列,进行实验得到表1最后一行的结果,满足项目工程的需求。
4.6 网络层结果对比
首先取软件版本的代码每层运行结果,将之作为基准,然后运行半精度或定点格式情况下的每层网络得到结果,设置一个β因子作于临界值,例如β=0.1或β=0.01,这样可以统计每层结果中两个值的绝对值差大于β的数有多少个,比例是多少,能够更加直观地看到从哪一层精度开始掉下了。另外,取硬件代码执行的结果与基准进行对比,也可以定位错误的层,易于排错。
5 实验结果
5.1 实验设置
我们分别在CPU和FPGA开发板上实现了飞行器关键点预测VGG-19网络加速器。实验选择的CPU平台是Intel Core i7-8700k,运行频率为@3.7GHz;软件版本是在深度学习框架Tensorflow上实现的,执行推理任务时采用的batch数为1,测试了数据集中的所有飞行器图像,共26种类别4560张飞行器图像,数据集是我们在Google地图上搜寻带有飞行器的区域,并将飞行器剪裁下来组成飞行器数据集。实验选择的加速器平台为Xilinx VC709开发板,开发板上有2个DDR3存储器,峰值带宽均为14.9GB/s;开发板上的芯片型号为Xilinx Virtex7 VX690T,芯片上集成了3600个DSP计算单元和6.5MB片上存储空间。加速器的实现基于高级综合技术,借助Vivado HLS工具首先完成加速器的功能验证,然后利用Vivado工具进行代码编写,对封装好的IP进行综合、布线和实现。
5.2 结果分析
表3展示了在CPU和FPGA上平均运行一张图像时VGG-19网络每层所用时间及总时间,由表计算得:CPU执行推理任务的平均吞吐率为270.048 GOP/s,加速器的平均吞吐率为796.8GOP/s。加速器的资源使用情况如表4所示,从表中可以发现,加速器充分使用了片上的计算资源,使用了较少的存储资源。

表3 CPU和FPGA执行推理任务花费时间
图5展示了VGG-19网络模型在加速器及CPU上执行推理任务时每层的吞吐率性能,首先对于加速器,在150MHz的时钟频率下,对卷积层来说,conv1_1和conv5的吞吐率较低,这是由于conv1_1的输入通道数较小,PE阵列的列利用不充分,conv5各层的输入特征较小,PE阵列的行利用不充分。fc层吞吐率最低,首先是PE阵列只使用了一列,但是瓶颈并不在于PE利用率低,而是受访存受限影响。而对于CPU的执行,每层的吞吐率几乎都是加速器吞吐率的1/2。

图5 VGG-19神经网络各层的吞吐率性能

表4 加速器片上资源使用情况

表5 加速器与CPU平台实验结果对比

表6 与以前的加速器实现进行比较
表5列出了运行VGG-19网络加速器与CPU平台上的实验结果对比。加速器的吞吐率性能是CPU平台的1.98倍。另外,CPU的热设计功耗(TDP)为95W,根据Vivado工具给出的功耗报告,加速器的热设计功耗为15.8W。从表中看出,我们的加速器性能功耗比是CPU的17.75倍。
表6选择了几个在FPGA上实现的VGG网络加速器作为对比。由于FPGA平台不同,我们列出了性能密度以便进行比较,性能密度定义为一个DSP在一个周期内执行的算术操作数,消除了时钟频率的影响。我们的PE被计算为两个操作。如表6所示,就性能密度而言,我们的加速器优于文献[15,21],比文献[20]低5%,从吞吐率角度看,我们的加速器吞吐率是文献[21]的1.24倍,是文献[15]的6.75倍,而文献[20]加速器使用了比其他加速器高得多的时钟频率获得最佳的吞吐率性能。
6 结语
本篇论文针对飞行器关键点检测过程进行加速,更进一步地,重点提出了关于VGG-19神经网络的加速器体系结构设计。首先分析了VGG-19深度神经网络卷积层、池化层、全连接层的计算特点,提出了通用矩阵乘法的加速器体系结构,采用乘累加单元阵列高效地执行矩阵乘法计算;接下来基于高级综合技术实现了加速器,并利用HLS指导语句优化了加速器的吞吐率性能;最后对加速器进行了验证实现。
