基于递归神经网络人工智能技术的音乐创作
2020-06-11马鹏程卢树强王晓岸李晓东宋涵宇
马鹏程 卢树强 王晓岸 李晓东 宋涵宇
(1.北京脑陆科技公司 北京市 100083)
(2.前瑞丽杂志、寺库 北京市 100176)
(3.中央民族大学音乐学院 北京市 100081)
1 简介
音乐创作(music creation)是指音乐专业人员或作曲家创造具有音乐美的乐曲的复杂的精神与技能生产过程[1]。主要方式是按照不同音节对应时间序列关系进行组合,如旋律和和声,并配以相宜的节奏进行组织产生的具有特殊音色和纹理动态声波。音乐创作通常是由受过专业音乐培训和教育的作曲家创造具有音乐美的乐曲,是一项极其复杂的技术和任务。
随着人工智能深度学习算法在图像识别[2][3][4],视频检测[5],自然语言处理[6][7]及语音处理[8]等方面的优秀表现和对应行业的广泛应用,深度学习模型技术的发展完善及应用的场景正在越来越多地被挖掘。深度学习算法[9]是一种新兴的多层神经网络降维算法,通过组建含有多个隐层的神经网络深层模型,对输入的高维数据逐层提取特征,以发现数据的低维嵌套结构,形成更加抽象有效的高层表示。如图1所示,一个具有三层卷积连接层和两层全连接层的神经网络结构,每层对输入的数据自动实现了抽象特征提取,最后
实现分类目标。有鉴于此,这种端到端的数据模型技术能够极大地为不同的基于数据应用的场景和任务提供极大的便利和效率。而深度学习对于音乐创作与生成的场景任务,通过有效的进行音乐数据集的构造和模型的设计选择,从而生成新的音乐。这也将使得音乐创作对于更多的人能够完成,也能够为人类带来更多不同类型和不同风格的优美音乐。如文献[10]构建了一种基于神经网络结果的生成模型,能够生成像人类创作出的和谐和优美的音乐。文献[11]中基于RNN深度神经网络结构设计的模型结合音乐先验知识生成了pop music。文献[12]通过神经网络进行了序列建模,基于简单的音乐数据样本集进行了辅助音乐创作。文献[13]通过双向长短时记忆(BLSTM)网络结构模型和对应的数据集,进行了和弦音乐的生成。文献[14]中通过弱监督深度递归神经网络,以音频能量功率谱作为输入,进行了舞曲生成。文献[15]中基于深度学习中的自编码机(VAEs)和对抗生成网络模型(GANs),进行了音乐分格迁移生成。
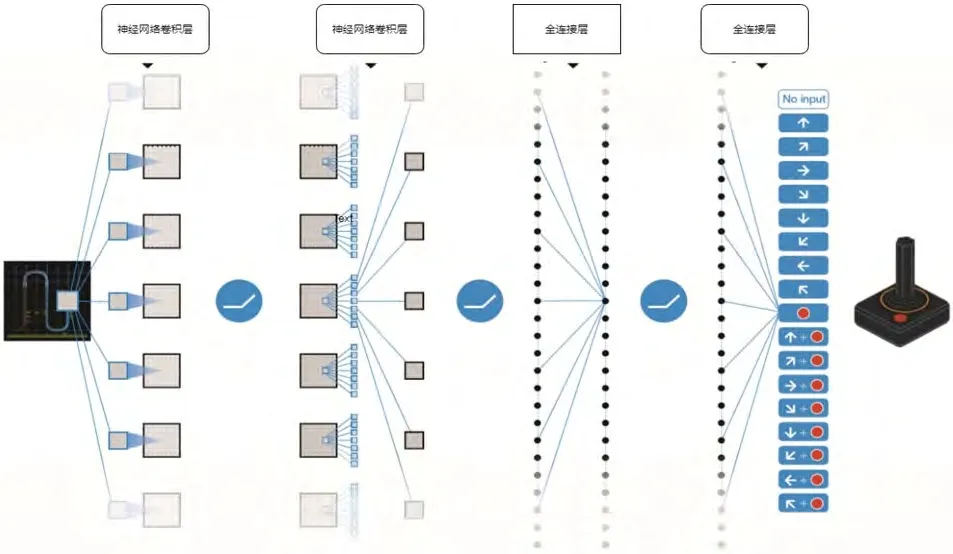
图1:神经网络结构示例

图2:Music-Coder音乐生成流程
2 本文工作说明
通过第一章我们看到对应于不同的音乐素材和类型及任务,可以选择不同的生成模型和方案。这篇文章中,我们主要实现通过神经网络模型生成特定作曲家类型音乐风格的音乐。由于音乐的载体是声音,而声音类型的数据可以看作是一种定长的时序数据。基于此,所以我们选择了可以处理时间序列数据类型的一种神经网络结构LSTM[16][17]来实现了通过一种附加约束的监管员机制的音乐生成器(Music-coder),并进行音乐生成,并且取得了优秀的音乐生成效果。Music-coder音乐生成器的主要工作流程如图2所示。本文主要工作为:
(1)通过应用一种LSTM深度学习模型,实现了对特定作曲分格的音乐生成。
(2)并对生成的音乐集进行了与原创音乐集相似度计算,在生成音乐特征分布于相似度2个指标上都达到了较好的效果。
(3)通过真实音乐人与作曲家对生成音乐数据进行双盲监测,平均通过率达到了80%以上。
3 音乐生成方案设计
3.1 数据集选择与处理
我们收集了著名音乐人周杰伦(由于周杰伦的作曲风格具有个人特色,且类型相对较丰富)的midi格式作曲素材,总共250首,平均每首时长约2-4mins,从其中选择了满足3-4Mins时长的60首作为训练数据集1(DataSet1)。除此之外,对60首midi作曲进行了分轨提取与处理,总共提取XXX轨,将轨音乐作为训练数据集2(DataSet2)。
3.2 数据预处理与算法设计
3.2.1 音乐数据结构分析与模型选择
音乐数据结构是一种标准化的时序数据,不同的时刻数据对应的是一个有限集,即如定义1所述。同时,音乐又是一种时序关联数据,所具有的特性如定义2所述。最后,由于音乐的生产最后是需要满足一定美学和艺术功能和需求的,所以音乐数据本身最后得需要对应的约束条件,如定义3所述。

图3:RNN模型结构示意
定义1:如果M为音乐数据,则Mt∈N,N为有限数集,Mt为t时刻该音乐的音节;
定义2:如果M为序列数据集,则Mt=f(M(t-1),M(t-2)…….M(t-n);
定义3:如果M为音乐数据,则f(M)≤C,C为约束条件集;
基于上述定义1,定义2,定义3的音乐数据结构的特性,潜在的满足处理该类特征数据的模型方案有基于RNN结构的深度学习模型[18],基于专家设计的音乐规则组合模型的生生成模型[19],基于神经网络进行音乐生成的模型[20],基于隐马尔科夫HMM的音乐序列生成模型[21],基于神经网络和搜索树结合的音乐生成模型[22],基于蒙特卡洛模拟采样进行的音乐生成模型[23],基于对抗生成网络GAN进行的音乐生成[24]等。

表1:LSTM结构设置

表2:生成音乐集G测试结果

表3:专业音乐人员测试结果
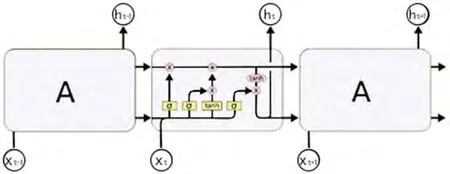
图4:LSTM模型结构
结合文章生成音乐任务需求,除了满足时序特征处理的功能,还需要基于处理建模后进行音乐生成,本文选择能够捕捉更多时序信息的RNN结构的LSTM模型进行音乐生成。
基于RNN机制的深度学习模型将是可行的音乐处理与生成选择,鉴于此,在各类时序任务上比较常用的Long Short Term Memory networks(以下简称LSTM)模型架构将成为非常有希望的模型之一。LSTM,是一种特殊的RNN网络,该网络设计出来是为了解决长依赖问题。该网络由Hochreiter和Schmidhuber(1997)引入,并有许多人对其进行了改进和普及。他们的工作被用来解决了各种各样的问题,直到目前还被广泛应用。所有循环神经网络都具有神经网络的重复模块链的形式。在标准的RNN中,该重复模块将具有非常简单的结构,例如单个tanh层。标准的RNN网络模型如图3所示。
对应的LSTM结构是基于RNN结构的改良模型,LSTM网络能通过一种被称为门的结构对细胞状态进行删除或者添加信息,门能够有选择性的决定让哪些信息通过,本身可以实现遗忘和记忆机制。所以利用其在进行音乐时序数据处理时,是可以将以前的信息与当前的任务进行连接,例如使用以前的音乐帧来帮助网络理解当前音乐帧。有时我们需要利用近期的信息来执行来处理当前的任务。例如,考虑用一个音乐模型通过利用以前的音乐序列信息来预测下一个音节和音符,有时我们不需要其他的信息,通过前面的音乐风格就能知道最后一节的音节。在这种情况下,相关信息与需要该信息的位置距离较近,而LSTM能够学习利用以前的信息来对当前任务进行相应的操作。
不管是RNN还是LSTM及其衍生主要是随着时间推移进行顺序处理,长期信息及t-n时刻信息需在进入t时刻单元前顺序遍历所有单元,这会存在梯度消失的问题。同时,LSTM能够记住长期的信息,但是它们只能记住100个量级的序列,或者更长的序列,这对长序列音乐生成会有一定的限制。同时,对LSTM模型的训练它们对硬件的要求非常高,即对计算单元要求比较多,这使得计算时间会较慢。
所以本文以选择以LSTM作为主要模型架构并结合,并通过监管器机制(Monitor Mechanism)来进行音乐条件约束,从而使得LSTM处理序列要求降短,从而能够在音乐生成效率上进行提高,以此来在满足音乐生成性能的规避LSTM模型本身的局限。
为了机器算法计算方便,我们将Dataset1和Dataset2数据集从MIDI格式转换为ABC文件格式,提供给人工智能模型进行训练计算。
3.2.2 模型结构设计与配置
(1)LSTM结构。LSTM的关键是元胞状态(Cell State),这种传送带结构直接穿过整个流程链,同时只有一些较小的线性交互。上面承载的信息可以很容易地传递到下一个计算单元而不改变。同时LSTM有能力对元胞状态添加或者删除信息,这种能力通过门结构来控制[24],它们由一个Sigmoid神经网络层[25]和一个元素级相乘操作组成,能够选择性让信息通过。一个完整LSTM有3个门结构,来保护和控制元胞状态,如图4所示。
LSTM用两个门来控制单元状态c的内容,一个是遗忘门(forget gate),它决定了上一时刻的单元状态有多少保留到当前时刻。另一个是输入门(input gate),它决定了当前时刻网络的输入有多少保存到单元状态。LSTM用输出门(output gate)来控制单元状态有多少输出到LSTM的当前输出值。W为计算过程权重矩阵,tanh为激活函数,C为单元状态,f为遗忘门,h为隐藏信息,x为特定时刻的输入信息。基于此,最后我们使用的LSTM结构如表1所示。
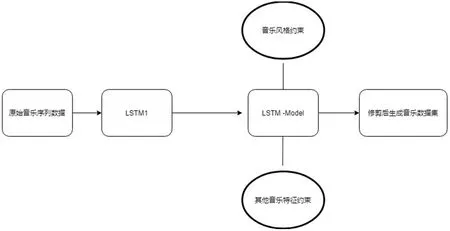
图5:监管员机制
(2)Music Coder结构的监管员机制。监管员机制(Monitor mechanism)主要是为了对LSTM的中间生产序列结果(中间计算音乐序列)进行一次检查,对不满足监管规则(音乐特征约束,主要配置为音调约束和音乐风格约束)的序列进行剔除,这种机制会使得LSTM的输入单个音乐序列不用过长,就能够达到特定的生成效果。这种模式使得LSTM处理速度和效率提升,从而使得生成训练过程更快收敛,如图5所示。
3.3 模型训练与音乐生成
我们在人工智能模型训练过程中使用4卡英伟达TitanXP GPU深度学习服务器,进行了10000次迭代训练,通过控制模型损失函数(Loss Function)和Softmax函数进行模型准确率优化提高,最后使得模型有效率达到90%以上,模型训练整个耗时35小时。基于数据集1和数据集2训练的深度学习模型,我们得到混轨音乐和单轨音乐,通过音乐修剪,将单轨作为整体音乐的补充合并,最后得到生成的音乐。
4 生成音乐结果分析
4.1 定量分析-生成音乐相似性计算
本文通过生成音乐与原始音乐的相似度计算来进行音乐生成效果量化评估,通过计算每首生成音乐与原始音乐集中的每一首音乐的相似度,选取相似度最高的一首对应的相似度作为最终相似度。基于训练好的生成模型,我们生成50首乐,每首约2-3分钟,生成速度为10s以内,同时选择皮尔森相似度对生成音乐数据集与测试数据集(原创音乐)进行相似性计算与效果评估。
从原有真实创作音乐100首随机选取50首为种子集S,编号S1,S2……S50,进行相似计算基准。对于生成音乐,随机从50首生成音乐选取生成30首为生成集G,编号G1,G2……G30,进行与种子集相似度计算,并作为参考计算种子音乐集S自身的相似性。分别计算G音乐集对应的最大相似度,最小相似度以及平均相似度,检测结果统计如表2所示。
4.2 定性分析-生成音乐专家测评统计
除上文的量化相似性计算我们也通过人工领域专家的测试来评估我们生成音乐的有效性。我们对生成数据集进行音乐领域专家交叉测试,通过对种子音乐集S(S音乐集包含50首)与生成音乐数据集G(G音乐集包含50首)进行随机混合处理,作为整体测试集T,编号为T1,T2……T100。我们邀请了3位音乐专业音乐人员分别是中央民族大学音乐学院音乐专业学生,海蝶音乐制作人,瑞丽时尚音乐人依次编号为A,B,C,通过试听来判断测试T中音乐是否为原创音乐,测试结果如表3所示。音乐参与者完成了随机混合了原始音乐集合生成音乐集共100首音乐,每个测试者分别试听100首音乐,并对每首音乐是否为周杰伦原创音乐做出判断。测试结果如表3所示。
通过表2和表3,我们发现原始音乐数据集本身的音乐风格变化差异较大,分布较广包含多种个人不同风格的音乐(平均相似度60.64%,差异度98.9%)。而基于Music coder生成的音乐集本身相对原始音乐集来说特征和风格分布较为集中,但也存在较好的风格多样性(平均相似度82.80%,差异度达69.63%)。对应的生成音乐集与原始音乐集平均相似度为60.13%,最大差异度为88.84%,平均相似度为60.13%,较为接近原始音乐集的风格与特征分布,并且能够较好的通过专业音乐人的检测。
5 总结与讨论
本文主要基于深度学习模型LSTM构造的音乐生成器,进行了特定音乐风格的音乐生成,并且在不同的测试方案上取得了良好的表现。根据测试结果评估来看,该模型能够较好的进行音乐创作,从而为未来更多的基于人工智能算法进行音乐创作的可行性提供了有力的支持。
当前本文实现了基于单类音乐风格进行的音乐生成创作,未来我们将尝试根据用户不同心情下的机器实时作曲。进一步实现对抑郁、焦虑等心情的量化有效的音乐干预方案,以创作出根据用户个人喜好而促进大脑多巴胺分泌的性能优良的音乐生成器,通过音乐+人工智能提高人类幸福感。
致谢:本文研究得到了皓橙娱音文化传媒有限公司的王乐然先生等专家及单位鼎力支持,为本文音乐规则设计及性能测评提供了宝贵的意见。特别鸣谢周杰伦先生和无数音乐人,创作出各种类型的歌曲,陪伴一代代人的成长,鼓励我们探寻人生和科学高峰,是机器永远无法替代的,特此致谢。
