基于深度学习的车辆跟踪算法综述
2020-06-11赵奇慧刘艳洋
赵奇慧 刘艳洋
(智慧互通科技有限公司静态交通技术创新中心 河北省张家口市 075000)
计算机视觉技术使计算机能够像人类一样“看世界”。它利用摄像机来模拟人眼的功能,从而实现对目标的提取、识别和跟踪。视觉跟踪是计算机视觉中最具挑战性的问题之一,它可以实现对指定目标的跟踪、定位和识别功能,并将目标的参数提供给控制器供后续使用。视觉跟踪在移动机器人、自动驾驶、人机交互、自动监控等机器智能领域有着广泛的应用。
智能交通是“智慧城市”的关键内容之一。在城市的主干道,尤其是十字路口,对车辆、行人等目标的自动检测与跟踪是智能交通系统的重要任务。目前基于深度学习的目标跟踪借助于云平台,能够及时有效地实现对交通状态的感知,从而提高整个城市的交通效能,因而起着越来越重要的作用。
1 车辆跟踪的研究背景
基于计算机视觉的车辆跟踪任务主要分为三个步骤,首先人为确定视频场景中的感兴趣区域,然后在后续视频帧中找出车辆的位置,最后通过一系列场景分析得出车辆运动的轨迹。
典型的车辆跟踪算法主要包括四个部分:初始化、运动模型、外观模型和更新模型。初始化的目的是确定要进行跟踪的车辆的初始位置和大小,通常由人工标注获得,而在实际应用中也可以由目标检测算法提供。运动模型是对车辆的运动状态进行建模,用来预测车辆在下一帧可能出现的位置或生成一组候选样本供车辆外观模型评价。外观模型是通过对车辆外观进行建模,用来评价候选位置或候选样本。更新模型是根据跟踪结果对外观模型和运动模型进行更新,以适应目标和背景的动态变化。
当前许多研究学者对车辆跟踪有研究,莫舒玥[1]提出了通过构建车辆动态目标位置的运动学模型,研究了车辆弯道保持系统中的动态目标位置跟踪问题,实现了自适应预测。胥中南[2]提出了一种快速分类尺度空间跟踪器,在核相关滤波算法的基础上融合了卡尔曼滤波器,解决了复杂路况下车辆多尺度变换的问题。王威[3]等人提出考虑控制延时的MPC控制器,实现了车辆路径的追踪。刘国辉[4]等人将庞大的VGG-M网络模型应用到实时跟踪中,并结合在线观测模型,实现了对前方车辆稳定精准的跟踪。杨妍[5]等人提出通过确定车辆的质心位置、最小外接矩形和运动方向,使用基于匹配特征的方法来实现对运动车辆的跟踪。范永昆[6]等人提出一种车辆目标的尺度搜索算法,通过比较目标区域上三个特定尺度相关滤波响应的平均峰值相关能量,推断出目标尺度的变化方向,有效解决车辆跟踪过程中尺度变化导致的模型漂移问题。宋士奇[7]等人提出了改进YOLOV3 网络,其采用了密集连接卷积网络的设计思想,实现了车辆的追踪,改善了雨雪天下车辆追踪精度不良的情况。
随着人工智能技术的不断发展,车辆跟踪算法的性能逐渐改善,但是在复杂的环境下对运动目标实现实时、稳定的跟踪,仍存在很大的挑战,面临的挑战主要有四点:
(1)形态变化。姿态变化是车辆跟踪中常见的干扰问题.运动目标发生姿态变化时,容易导致跟踪失败。
(2)尺度变化。由于跟踪框不能自适应跟踪,会将很多背景信息包含在内,导致目标模型的更新错误。
(3)遮挡与消失。车辆在运动过程中可能出现被遮挡或者短暂的消失情况。
(4)图像模糊,光照强度变化,车辆快速运动,低分辨率等情况会导致图像模糊。
2 适用于车辆跟踪的深度学习模型
但近年来,为了提高目标跟踪器的跟踪效率和鲁棒性,出现了一些深度学习模型。主要包括有CNN、GRU、GAN、Siamese network等。
2.1 CNN(Convolutional Neural Network)
CNN[7]是一种前馈神经网络,其中每个神经元与前一层感受野范围内的神经单元相关。卷积神经网络通常包含卷积层、激活函数、池化层以及全连接层,其中,卷积层由若干卷积单元组成,卷积运算是为了对输入图片进行特征提取,浅层的卷积神经网络提取一些低级的特征如边缘、轮廓和角点等,深层网络从低级特征中提取更为复杂的特征。池化层即降采样层,通常经过卷积层后会得到维度较大的特征,经过池化层后可得到维度较小的特征。全连接层把所有局部特征结合变成全局特征,代表性的CNN模型有 AlexNet[8]、VGGNet[9]、GoogLeNet[10]、ResNet[11]等。部分卷积网络基本结构单元如图1所示。
2.2 SNN(Siamese convolutional neural network)
Siamese network[12]是Yann Lecun提出来的,以两副图为输入,然后分别进行特征提取,最后判断两幅图的相似性。孪生网络是一种基于相似性度量方法的网络,适用于样本数少的多类别的识别和分类等情况。传统的方法由于类别的样本太少,所以无法训练出现有效的神经网络。SNN在过去几年被广泛用于视觉跟踪,所有的基于SNN的方法的目的是为了克服预训练的速度慢的缺点,充分实现端到端的学习,以达到实时跟踪的目的。孪生网络基本结构如图2所示。
2.3 GAN(Generative Adversarial Network)
GAN[12]主要包括生成器与判别器两部分。生成器通过学习真实图像从而生成的和真实图像极为相似的假图像,以欺骗判别器,判别器对接收的图像进行真假判别。在训练过程中,生成器努力地让生成的图像更加真实,而判别器则努力地去识别出图像的真假,随着训练的迭代,生成器和判别器在不断地进行对抗,期望网络达到一个均衡状态。最终生成器生成的图像越来越接近于真实的图像,使得判别器识别不出真假图像。GAN网络基本结构如图3所示。
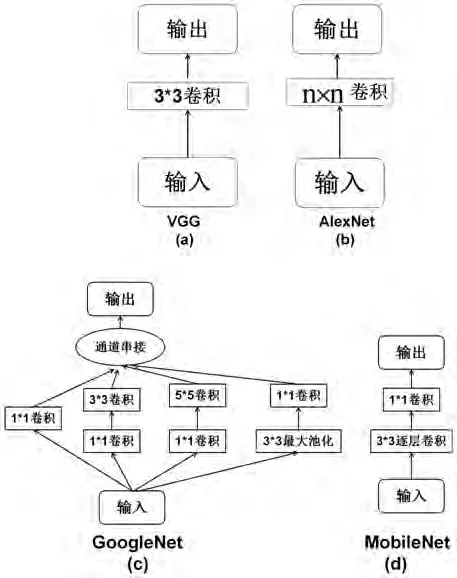
图1:部分卷积网络基本结构单元
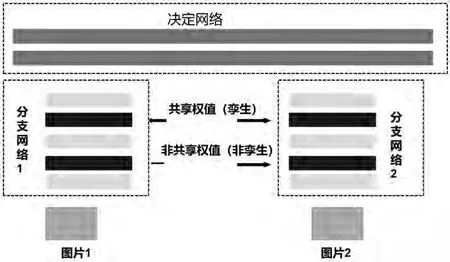
图2:孪生网络基本结构
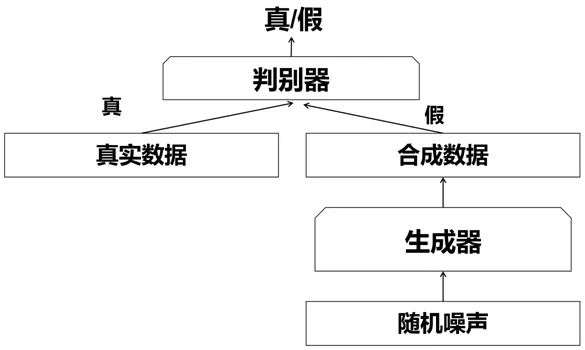
图3:GAN网络基本结构
2.4 RNN(Recurrent Neural Network)

表1:各种基于预训练模型的视觉追踪方法

表2:各种基于在线训练模型的目标跟踪方法

表3:各种基于离线训练模型的目标跟踪方法
由于视觉跟踪涉及到视频帧的空间和动态信息,因此采用基于RNN[14]的方法来模拟目标的运动。由于训练需要大量的参数导致训练过程较为复杂,因此基于神经网络的方法数量有限。此外,使用基于RNN方法的目的是避免对预先训练好的CNN模型进行微调,因为微调已经训练好的模型需要花费大量时间,而且容易出现过拟合的问题。基于RNN的方法的主要步骤是,首先利用金字塔型多向递归网络或长短期记忆网络(LSTM)合并到不同的网络中,然后确定目标并研究前后目标物的时间依赖关系。最后,对目标的自结构进行编码,以降低与相似干扰物相关的跟踪灵敏度。RNN网络基本结构如图4所示。
3 基于深度学习的车辆跟踪算法
目前基于深度学习的跟踪方法主要是利用深度特征强大的表征能力来实现目标跟踪。按照训练方法不同,可分为基于预训练的目标跟踪、基于离线训练的目标跟踪和基于在线训练的目标跟踪三种类型。
3.1 基于预训练的目标跟踪
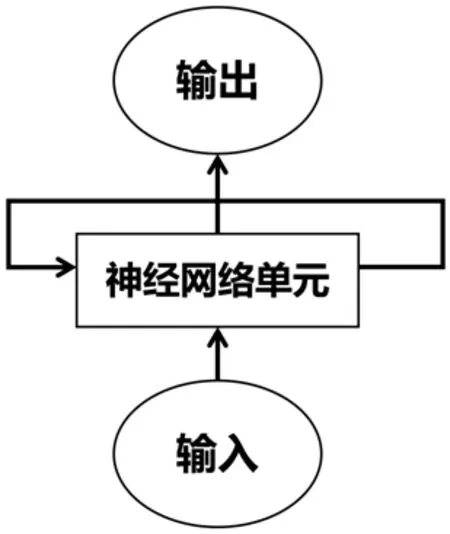
图4:RNN网络基本结构
基于预训练的目标跟踪方法主要是利用现成的深度神经网络模型对数据进行预训练,是基于深度学习的视觉跟踪方法中的最简单方法。在结构方面,叠加了一个简单的适用于车辆跟踪的深度学习神经网络模型,如AlexNet[8],VGGNet[9]。或叠加了一个有向无环图拓扑,如GoogLeNet[10],ResNet[11],Siamese convolutional neural network[12]等,可以设计出更复杂的深层结构,包括多个输入/输出层,使用不同的特征模型便可设计出不同的方法,这些特征图和模型主要是在ImageNet数据集等大型静态图像上预先训练过的,用于目标的检测和跟踪任务。
从表1的对比数据可以看出,基于预训练模型的跟踪方法大多运行速度较快,该类型方法中预训练网络为大多VGG网络,其中运行速度最快的方法是TADT,其预训练模型为孪生匹配网络。
其中:置信度图(CM),显著性图(SM),边界框(BB),目标评分(OS),特征图(FM),分割蒙版(SGM),旋转边界框(RBB),动作(AC),深度外观特征(DAF),深度运动特征(DMF)
采用预训练的目标跟踪方法有很多优点:一方面,完全使用预训练网络,节省了大量的训练时间,而且无需在线更新网络,可以取得较快的跟踪速度;另一方面,预训练网络可以利用预训练样本中大量图像分类的标注数据,解决了目标跟踪中训练样本不足的问题。缺点有两个,一是训练的网络不能完全适应目标跟踪这个任务; 二是目标在跟踪过程中会发生很多形变,跟踪精度会不足。
3.2 基于在线训练的目标跟踪
基于在线训练网络的目标跟踪方法能更好的进行目标跟踪,其优点是可以适应目标尺度的变化。该训练方法主要分为三步,首先采用预训练的网络对视频进行初始化,然后用第1帧的标注样本训练目标检测部分和特征提取部分,最后根据预测结果,生成一定的正、负样本,微调整个网络。
从表2的对比数据可以看出,基于在线训练模型的跟踪方法大多在运行速度上同样不是很理想,该类型方法中预训练网络大多为VGG网络。
这种方法可以进一步提高网络的跟踪精度,较好地适应目标尺度的变化,显著提高跟踪性能。但是,基于在线训练的目标跟踪方法的跟踪速度十分有限,一般很难达到实时要求。
3.3 基于离线训练的目标跟踪
基于在线训练的目标跟踪方法跟踪速度十分有限,特征的提取和更新很难做到实时。为解决这一问题,提出基于离线端到端训练的全卷积孪生网络的跟踪方法 SiamFC。SiamFC 主要学习相似度函数,用于目标匹配。SiamFC 主要学习相似度函数,用于目标匹配。孪生网络分别输入初始帧模板以及当前帧的搜索区域,分别使用相同的全卷积网络提取特征,再用相关操作进行模板匹配,生成响应图。响应图中最大值的位置即是目标在搜索区域内的相应位置。网络训练时,SiamFC 采用 ImageNet VID的视频数据,选取视频中相隔不远的两帧输入网络进行相似度函数学习; 跟踪时,训练好的网络无需调整,目标模板也无需更新,从而实现实时跟踪。基于离线训练的目标跟踪方法不仅提高了跟踪的精度,还能通过改善训练过程中的过拟合现象来达到较好的跟踪速度。
从表3的对比数据可以看出,基于离线训练模型的跟踪方法较在线训练的方法运行速度快很多,该类型方法中效果较好的,其特征提取网络大多为AlexNet。
基于离线训练的目标跟踪可以很好的平衡准确率和跟踪速度,但是基于离线训练的模型应用于在线跟踪的任务时仍有困难,因为在提取特征时,非深度学习的方法都是人工手动提取特征,而SiamFC等深度学习方法因为没有使用注意机制,导致目标跟踪精度不够。
在现阶段,视觉跟踪的关注点主要分为两大类:第一类关注于提高准确性,但是速度非常慢(无论是CPU还是GPU),无法满足机器实时应用的需求。第二类侧重于速度,但是准确性有所缺陷。目前来看,跟踪效果较好是基于ECO-HC的预训练目标跟踪王法,主要因为其使用了卷积,具有卷积的跟踪方法性能优于仅具有手工特征的跟踪方法,但该类型跟踪方法的速度并不理想。虽然随着深度学习的发展,跟踪方法的性能越来越好、越来越快,但当前仍然不能应用于移动端(基于ARM或CPU)。
4 数据集与评价指标
4.1 数据集
目标跟踪数据集的创建,目的是对各种跟踪算法进行性能比较。第一个建立的用于对象跟踪数据集为OTB2013[14],包含由51个经过注释的视频序列。OTB2015[15]是OTB2013数据集扩展而来,其包括100个经过注释的视频序列。OTB 数据集的出现也促进了其他视频数据集的发展。为了评估基于颜色信息的目标跟踪算法,建立了TempleColor128[16]数据集。该数据集共包含128个彩色视频序列,部分序列与 OTB 数据集重合。BDD100K数据集在计算机视觉领域,是样本量和数据规模最大的车辆视频数据集,包括了不同情景的车辆视频,数据集包括了一天中不同时刻、不同的天气条件下的图像,总时长超过1,100小时。总的来说,该数据集囊括了接近10万个视频,每个时长约40秒,其中样本图片是每个视频的第10秒截取的,以此来作为关键帧,总共捕获了10万张照片。
4.2 评价指标
为了比较各个算法的性能,通常使用三种指标进行度量:第一个指标是精准度 (Precision),在图像中跟踪目标的中心与标准中心的差值小于某一个阈值所占视频总帧数的比例。

其中,N表示一个视频序列中的帧数,CLE表示心位置误差,d表示一个特定阈值,dis表示两点之间的欧氏距离,p1表示检测到的跟踪目标的中心,p2表示该目标物真实的目标中心。
第二个指标是成功率 (Success rate)。将当前帧中跟踪框和标准框的重叠部分的面积与其覆盖总面积做比值,得到数值 (VOR)。成功率是指计算跟踪成功的帧数所占总视频帧数的比例。

其中,BT表示生成的跟踪区域;BG表示实际的目标区域;
第三个指标是表示跟踪算法的速度,采用帧/秒 (FPS)表示。
5 总结与展望
车辆跟踪算法发展至今,在特征表达、处理尺度变化、解决遮挡问题等方面都取得了长足的进步,显著提升了算法的跟踪精度和跟踪速度。目前,车辆跟踪算法在目标跟踪领域存在的主要问题:
(1)如何提升深度特征跟踪速度。
(2)如何训练出更适合于车辆跟踪问题的端到端模型。
