多局部约束自表示的谱聚类算法
2020-06-09蒋忆睿王文乐代江艳易玉根
蒋忆睿,裴 洋,陈 磊,王文乐,代江艳,易玉根
1.江西师范大学 软件学院,南昌330022
2.潍坊学院 计算机工程学院,山东 潍坊261061
1 引言
子空间聚类(Subspace Clustering,SC)是机器学习、模式识别和计算机视觉等众多领域中研究热点之一[1-3]。近些年,子空间聚类受到研究者的广泛关注,并提出了大量算法用于挖掘高维数据的低维结构[4-7]。根据采用方法的不同,大致可以将子空间聚类方法分为五类:基于代数方法、基于统计方法、基于迭代方法、基于矩阵分解方法和基于谱聚类的方法[8]。在上述方法中,由于基于谱聚类(Spectral Clustering)的方法具有较强的理论基础,并且在图像表示、图像聚类等实际应用领域中取得优越的性能,因此,它已成为目前子空间聚类的主流技术之一[9-10]。
谱聚类方法首先通过计算样本间的相似关系构建图,然后对图的拉普拉斯矩阵进行特征值分解得到相应的低维表示,最后利用k-mean 算法对其进行聚类[11-12]。因此,基于谱聚类方法的核心问题是如何有效地构建图。传统的图构建方法,一类是基于数据的距离(如余弦距离或热核距离),主要包括k-近邻和ε-球方法[12]。而另一类方法则是通过最小化局部样本重构误差的方式实现图的构建[13]。由于上述两类方法具有直观且易实现等特点,因此它们被广泛用于谱聚类和基于图的维数约简等方法中,并取得较好的性能。然而,这些方法所涉及的邻域参数和热核参数在实际问题中难以选择。参数一旦选取不恰当,将会导致聚类算法无法很好地挖掘数据的内在结构。另外,这些方法为所有样本设置相同的参数,这也将导致算法不能很好地反映非均匀分布样本的局部结构。
为了解决上述问题,相继提出了大量基于数据驱动的自适应图构建方法[14-15]。例如:Yang 等人[14]提出了样本依赖图(SG-graph)的方法,该方法根据计算每个样本与所有样本之间的平均相似性的差异寻找样本近邻。因此,它可以自适应地确定图中每个样本的近邻数。随着基于稀疏表示的方法在众多领域中的成功应用,基于稀疏表示的构图方法也相继被提出[15],也被称为L1图。如Elhamifar 等人[15]提出稀疏子空间聚类(Sparse Subspace Clustering,SSC)方法,该方法首先假设每个样本可以用其他样本线性表示,并对其表示系数加以基于l1-范数的稀疏约束。尽管基于稀疏表示的方法可以自适应选择样本的邻域和计算样本的权值,但该类方法需要分别求解每个样本的稀疏表示,从而增加了算法时间代价。另外,由于单独对每个样本进行求解将导致所构建的图不能很好地刻画数据全局结构信息。
于是,为了解决上述方法存在的问题,Liu等人[16]提出基于低秩表示(Low-Rank Representation,LRR)的谱聚类方法,该方法通过求解数据的低秩表示获取数据的全局结构。然而,由于LRR 方法在每次迭代求解过程中都需要进行奇异值分解并且收敛较慢,因此,该方法不适应于处理大规模高维数据。为了提高算法的效率,Lu等人[17]提出了一种基于最小二乘回归(Least Squares Regression,LSR)的谱聚类方法,该方法充分利用数据的相关性将高度相关的数据聚集在一起。与LRR算法相比,LSR方法的求解简单且高效。尽管通过LSR方法所构建的图可以获取样本的全局结构,但其样本的局部结构却被忽略。换句话说,LSR方法并没有考虑样本点之间的距离关系,将导致在线性重构时选择距离较远的样本进行重构,形成的图并不能很好地反映数据的局部结构。然而,大量研究表明,数据的局部性在数据聚类和分类等任务中起着非常重要的作用。因此,Chen 等人[18]结合局部约束和LSR 方法提出一种局部约束最小二乘回归(Locality-Constrained LSR,LCLSR)方法,充分继承LSR 方法和局部约束的优点。文献[18]中的实验结果验证LCLSR 方法的聚类性能要优于LSR 方法,但局部约束的选择将会影响LCLSR方法的性能。
目前,提出了大量的距离度量方法,如基于指数函数的方法[19]、基于欧式距离的方法[20]、基于内积的方法[21]等。这些不同的距离度量方法都是基于不同的假设或准则提出的,它们可能仅适用于表征特定类型数据的结构。因此,如何有效选择哪一种距离度量方法更适合特定任务和数据仍然是一个有待研究的问题。
本文为了解决上述方法存在的局限性,提出了一种多局部约束自身表示(Multiple Locality Constrained Self Representation,MLCSR)图构建方法用于谱聚类,MLCSR 算法具有如下优点:(1)MLCSR 方法继承了样本的自表示能力和局部约束的优点,并将数据的自表示和局部性集成到一个统一的框架中。(2)MLCSR方法能够自适应地将不同的距离度量函数组合到局部约束中,从而保证算法更具有灵活性和实用性。本文提出了一种基于迭代更新的优化策略来优化MLCSR 算法。另外,通过大量实验验证了MLCSR方法的有效性。
2 多局部约束自表示图构建方法
2.1 目标函数
假设矩阵X=[x1,x2,…,xN]∈RD×N表示样本集合,其中,包括N 个样本,每个样本的维度为D。
首先,假设集合中的任意样本都可以由其他样本线性表示。不同于LCLSR 方法,本文对表示系数加以非负约束使之更具有线性表示的物理意义,目标函数可定义为公式(1):

其中,W=[w1,w2,…,wN]∈RN×N表示系数矩阵。
其次,为了在样本重构时考虑数据的局部结构性,本文定义局部约束项如公式(2)所示:

其中,D=[dist(xi,xj)]N×N表示样本间的距离矩阵,其元素dist(xi,xj)表示样本xi和xj之间距离,dist(⋅)表示距离度量函数,||⋅||1则表示矩阵的l1范数,符号⊙表示矩阵元素的点乘操作运算。通过最小化公式(2)可以尽可能选择距离与重构样本较近的样本进行重构。
同时,为了考虑不同距离度量函数对局部约束的影响,本文采用五种常用的距离度量函数[19-23]。如文献[20]定义的一种基于欧式距离的函数,如公式(3)所示:

文献[19]定义了一种基于指数的距离度量函数,如公式(4)所示:

其中,σ 是非零参数。在实验中,本文将其设置为所有样本欧式距离的均值。
文献[21]定义了一种基于内积的距离度量函数,如公式(5)所示:

文献[22]结合指数距离和内积距离函数定义为公式(6):
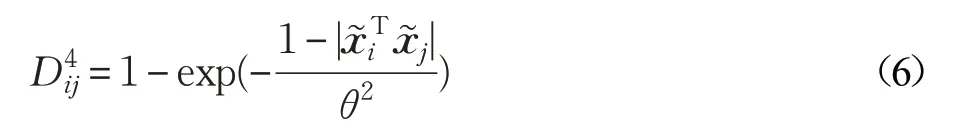
其中,θ 是非零参数。实验中本文将其设置为所有样本内积的均值。
文献[23]定义了一种基于l1范数的距离度量函数,如公式(7)所示:
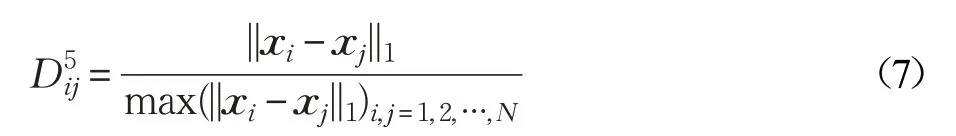
其中,max(||xi-xj||1)i,j=1,2,…,N表示所有样本的l1范数距离最大值。
然后,为了充分考虑不同距离度量函数之间互补性,本文将局部约束项重新定义为公式(8):
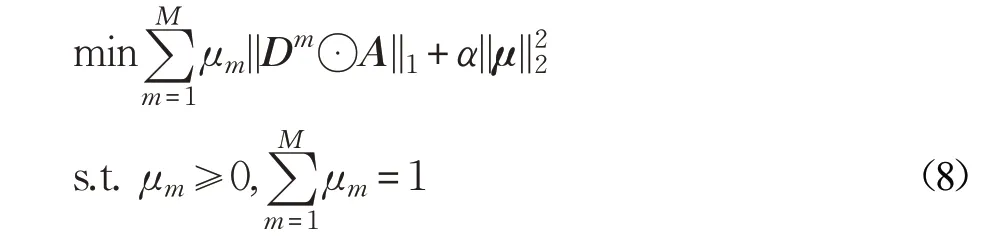
其中,M 表示采用距离度量函数的数量(本文M=5),μ=[μ1,μ2,…,μM]为权值向量,α >0 为平衡参数。
最后,结合公式(1)和公式(8),MLCSR方法的最终目标函数如公式(9)所示:
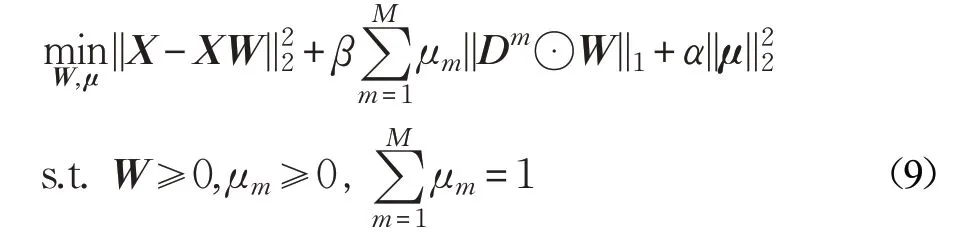
其中,参数α 和β 平衡各项在目标函数中的贡献。
2.2 优化求解
从目标函数公式(9)可以看出,有两个变量(W 和μ)需要优化,然而对于这两个变量而言,目标函数公式(9)为一个非凸函数,因此,无法给出目标函数的全局最优解。但对于单个变量而言,目标函数是一个凸函数,因此,本文给出一种基于迭代的优化算法对目标函数进行求解,即,固定其中一个变量,更新另一个变量。
2.2.1 固定μ,求解W
从目标函数中移除无关项,有关W 的优化问题可转化为公式(10):

对公式(10)进行运算,可简化为:

求解公式(11),需引入拉格朗日乘子矩阵Λ,则公式(11)的拉格朗日函数定义为公式(12):
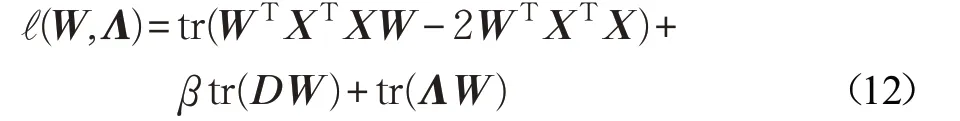
对公式(12)求导并令其导数等于零,则有:
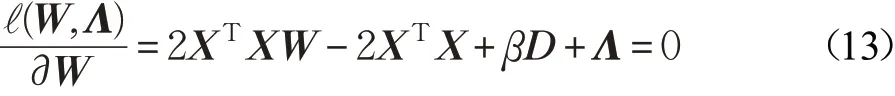
根据KKT条件ΛijWij=0[24],则有:

根据公式(14),W 更新如公式(15)所示:
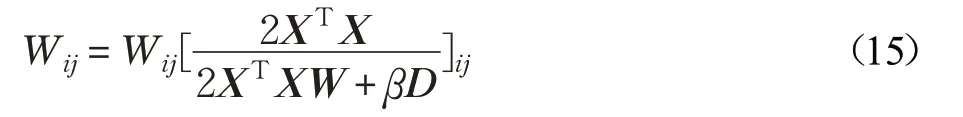
2.2.2 固定W,求解μ
从目标函数中移除无关项,有关μ 的优化问题可以转换为公式(16):
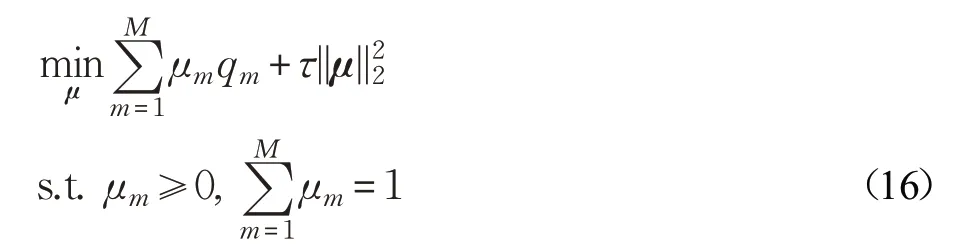
其中,qm=||Dm⊙W||1和。公式(16)是标准的凸二次规划问题,本文采用文献[25]的坐标梯度下降(Coordinate Descent Algorithm,CDA)方法求解。具体求解过程如下:考虑约束条件μm≥0 和,在每次迭代过程中仅更新权值向量μ 中的任意两个成对的元素,而固定其他元素。首先,假设需要更新的成对元素为μk和μl(k ≠l),固定其他元素μm(m ≠k,l),根据上述约束条件,则有:

令ρ(μk)为目标函数,表示如下:
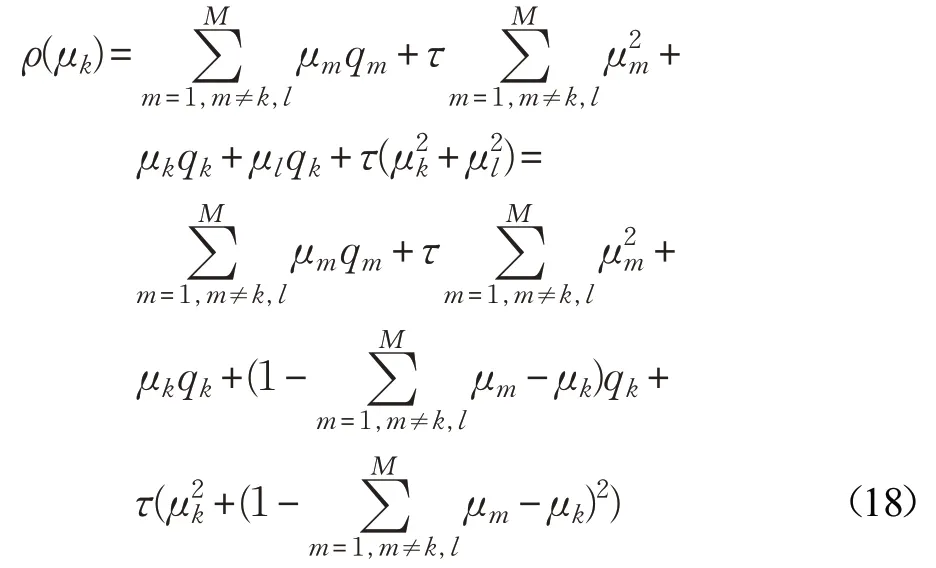
对公式(18)求导数,并令其等于零,则有:
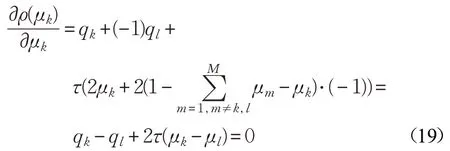
根据公式(19),则有:

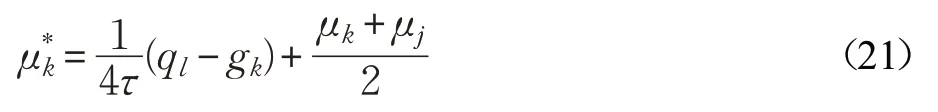


(3)否则有:
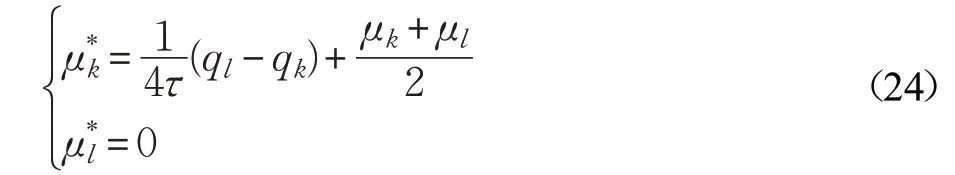
通过公式(22)至公式(24),成对更新μ 中的所有成对元素,直到目标函数达到收敛。
2.3 算法流程
本文提出的基于多局部约束的自表示图构建算法如算法1所示。
算法1 基于多局部约束的自表示图构建算法
输入:样本集X=[x1,x2,…,xN]∈RD×N,参数α 和β
1.通过公式(3)至(7)计算距离矩阵
2.循环迭代执行步骤3和4直到达到收敛条件
3. 通过公式(15)更新W 矩阵
4. 通过CDA方法求解权值向量μ
输出:矩阵W ,权值向量μ
2.4 计算复杂度分析
本节主要对算法1 的计算复杂性进行分析。假设M 为本文所采用距离度量的数量,则其计算复杂度为O(MDN2)。根据文献[25],更新权值向量的计算复杂度为O(M2),更新W 矩阵的计算复杂度为O(DN2)。因此,算法的总体计算复杂度为O(MDN2+T(M2+DN2)),其中T 表示算法的迭代次数。表1 给出不同图构建算法的计算复杂度的对比结果。从表中可以看出,KNN算法的计算复杂度最小,L1、LRR 和MLCSR 三个算法的计算复杂度要高于其他方法。

表1 不同算法的计算复杂度
2.5 参数设置
从目标函数公式(9)中可知,本文方法包括两个参数,分别为α 和β。参数α 主要用于控制局部约束项重要性,而参数β 用于控制不同拉普拉斯矩阵的权值。因此,参数的取值应根据数据库特征进行设置。更为详细的说,当来自同类的样本具有较高的相似性,并与其他类样本可以较容易分开,此时应该将参数α 设置较大的值使之能够很好地保持数据的局部结构信息。相反,当样本的邻域样本来自于不同类的样本,此时将参数α 设置为较小值。对于参数β 而言,当β →∞,所有拉普拉斯矩阵的权值相同,此时,忽略了不同拉普拉斯矩阵的差异。当β 设置为零,权值向量μ 中仅有一个元素有值,也是说仅仅一个拉普拉斯矩阵被利用。因此,参数β 应该设置为适中的值。
2.6 算法收敛分析
本节主要对算法收敛性进行分析。首先,将目标函数公式(9)标记为φ(W,μ),则有如下理论:
理论1 目标函数φ(W,μ)其函数值是递减的。
证明 令φ(Wt,μt)表示目标函数在第t 次迭代时的目标函数值。首先,在第t+1 迭代时,固定μt,再求解子优化问题。对于该子优化问题的收敛性证明可以参阅文献[26]。因此在每次迭代W 时,目标函数值随着降低,故有如下不等式成立:

然后,固定Wt,继续求解子优化问题对于求解此优化问题,本文采用CDA算法求解,可以获得最优的μt+1。由于该优化问题属于一个凸优化问题,故有如下不等式:

最后,结合不等式(25)和(26),可得到如下不等式:

综上所述,理论1 已被证明。而且,由于目标函数公式(9)中的所有项都是大于等于零,因此,目标函数具有最小值。因此,根据柯西收敛准则[27],本文提出方法的目标函数是收敛的。并且在数值实验中也验证了目标函数值随着迭代次数的增加能够快速趋于收敛。
3 实验及分析
为了测试本文提出的MLCSR 算法的有效性,在3个标准的人脸图像数据库进行实验(如Yale[28]、AR[29]和CMU PIE[30])。三个图像数据库的具体信息如表2 所示,以及每个数据库中的部分实例图像如图1所示。
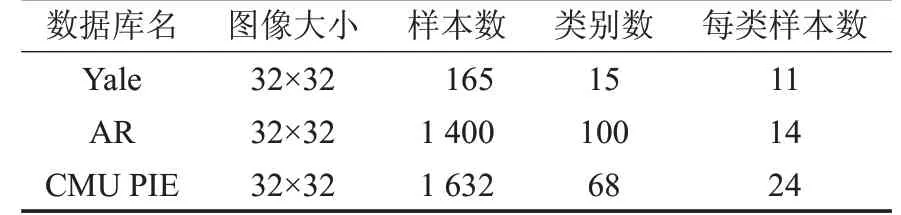
表2 数据库详细信息

图1 数据库中部分实例图
本实验中将MLCSR方法与不同的图构建方法比较,如KNN[12]、LLE[13]、L1[15]、LRR[16]、LSR[17]和LCLSR[18]。本文提出的方法和所有对比方法都是基于Matlab2016 编程实现的。实验平台为Intel®Core™i7-4790,双核GPU,频率为3.60 GHz,内存为8 GB,系统为64 位Windows 10 系统。此外,MLCSR 方法采用公式(3)至公式(7)的五个距离度量函数。在实验中采用网格式搜索方式寻找各个方法中参数的最优取值。由于谱聚类中的kmeans 聚类算法的性能依赖于初始化,因此,实验中将随机执行50 次不同的初始化,然后统计其平均值和标准差作为最终结果。本文采用三个常用的度量准则:聚类准确率(ACC)、归一化互信息(NMI)和纯度(Purity)评价聚类算法的性能。不同方法在三个人脸数据库上的实验结果,如表3至表5所示。
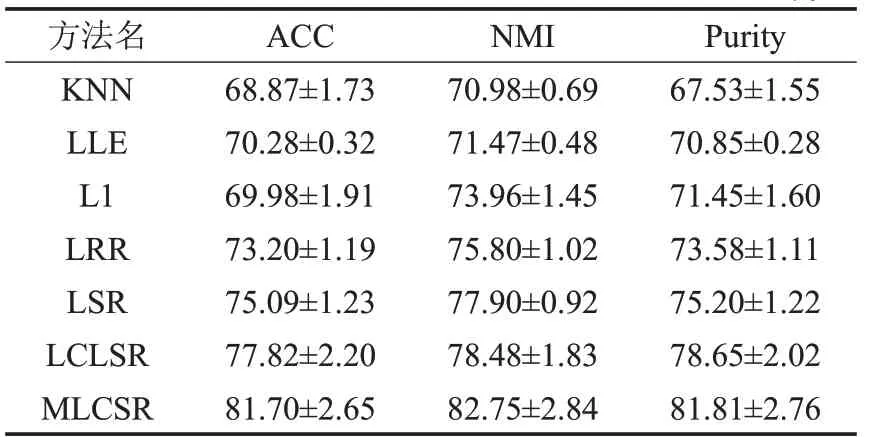
表3 不同方法在Yale数据库上聚类结果 %
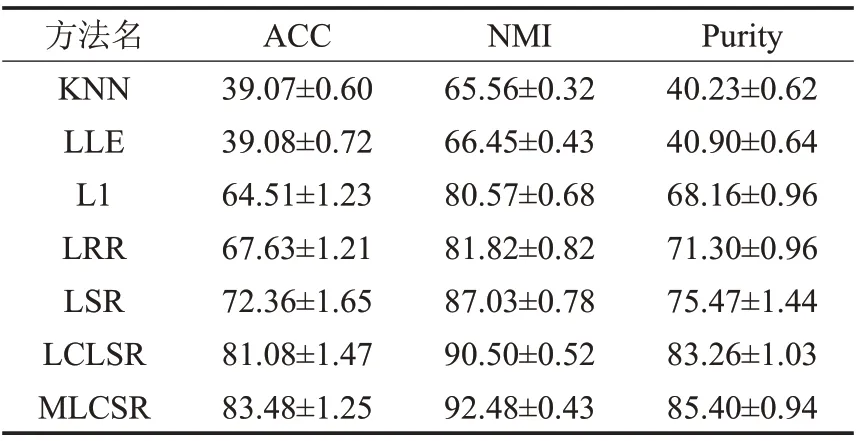
表4 不同方法在AR数据库上聚类结果 %
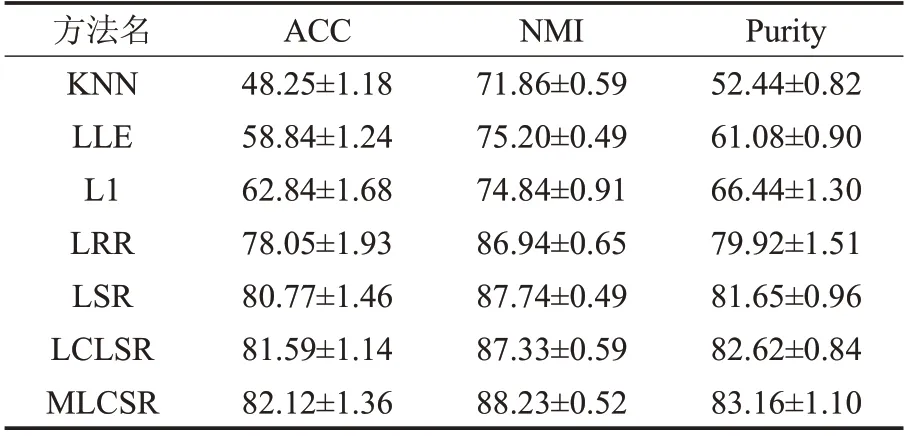
表5 不同方法在CMU PIE数据库上聚类结果%
从表3至表5的实验结果中可得到如下结论:
(1)基于KNN 和LLE 图的聚类性能要低于其他构图方法,其主要原因是基于欧式距离的KNN 和LLE 图对数据中的噪声点、局外点以及参数取值非常敏感。
(2)因为基于LRR 和LSR 的方法在构图过程中考虑数据的全局结构,所以,它们的性能要优于L1 图的方法。
(3)由于基于LRR和LSR的图构建方法忽略了数据的局部结构,因此,它们聚类效果要低于LCLSR方法。
(4)由于本文提出的MLCSR 方法融合了多个距离度量准则,可以充分挖掘数据的局部结构特性,所以它的性能要优于所有对比方法。
其次,为了验证采用不同距离度量的必要性。实验中将测试单独采用一种距离度量函数的算法聚类性能,其结果如表6所示。从表中可观察到,仅仅用单一的距离度量函数的聚类正确率要低于融合使用多个距离度量函数的。因此,实验结果说明了本文采用多个距离准则是有必要的。为了进一步验证不同距离函数的权值对算法性能的影响,在实验中将所有距离函数的权值设置为等同值,其结果如表7 所示,实验结果验证了权值分配对算法性能也有一定的影响。

表6 不同度量函数在数据库上聚类准确率ACC %

表7 不同权值本文方法在数据库上聚类准确率ACC %
接着,为了验证算法收敛性,图2 给出MLCSR 算法在3 个人脸图像数据库上的目标曲线图。从图中可以看出,MLCSR 算法在较少的迭代次数下就能达到收敛。

图2 不同数据库上的目标曲线图
最后,表8给出不同算法在各个数据库上的运行时间。从表8中看出,基于KNN、LLE和LSR和LCLSR的图构建方法的运行时间总体要低于其他方法,但本文提出的构图方法的运行时间要低于基于L1和LRR的构图方法。
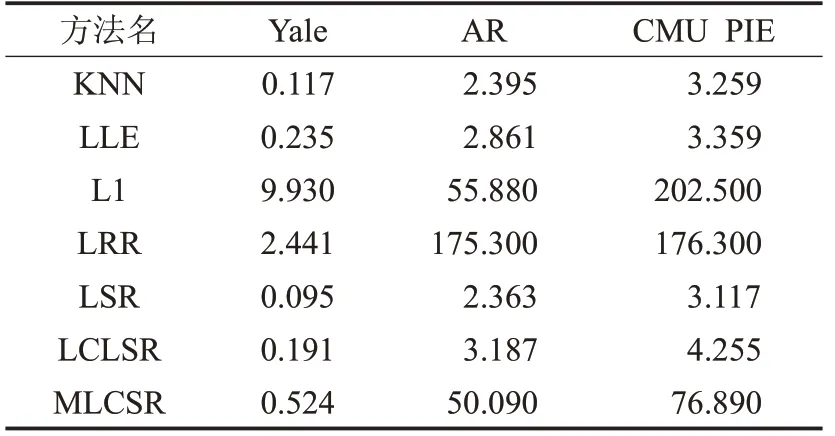
表8 不同方法在三个数据库上运行时间 s
4 结论
通过融入多个距离度量准则,本文提出一种基于多局部约束的自表示图构建方法用于谱聚类。不同于现有的方法,该方法不仅继承了样本间的自表示特性,同时还能充分挖掘数据的局部性。为了有效地求解目标函数,本文基于迭代思想提出一种优化算法,并在理论方法和数值实验中验证该优化算法的收敛性。最后,在三个数据库上的实验验证了本文方法有效性。
