基于改进密集连接型网络的光场深度估计
2020-06-09苏钰生王亚飞李学华
苏钰生,王亚飞,李学华
北京信息科技大学 信息与通信工程学院,北京100101
1 引言
传统的成像设备与系统只能记录场景的二维平面信息,丢失了场景深度信息,如今在VR(Virtual Reality)技术的发展和应用中,传统设备存在着明显的局限性。光场相机的诞生,改变了成像方式,能够收集和记录光的强度和光的方向,这使得通过光场图像来估计场景深度信息成为可能[1]。
传统方法,比如立体匹配[2](stereo matching)结合随机场理论[3]和PCA[4],得到的深度图(depth maps)精度较低,已经无法满足对准确度和速度的需要。目前比较常用的算法主要分为两类:基于优化的算法和基于深度学习的算法。
基于优化的代表方法有:文献[5]根据相移理论提出了一种达到亚像素精度的多视角立体匹配方法,该算法克服了微透镜镜头畸变,且改善了传统匹配算法的准确度。基于EPI的深度估计方法不同于匹配的方式,它通过分析光场数据的结构,从而进行深度估计。只需要计算EPI 中的斜线斜率即可计算出对应点的深度。文献[6]采用了结构化张量来计算EPI中的斜率,得到初始视差图,并且使用全变差去噪滤波器来精细化视差图。还有考虑融合及散焦的深度估计方法[7],根据光场剪切原理,通过衡量像素在不同焦点堆栈处的“模糊度”来得到对应深度。这些传统的估计方法都无可避免地在算法性能和计算速度上进行折中,对于准确度和效率无法同时保证。
也有学者采用深度学习的方法进行光场的深度估计,文献[8]采用了EPI patch作为神经网络的输入,利用双输入流卷积神经网络提取特征,计算得到对应的深度信息,然后采用变分法,以中心视图作为先验结果优化初始深度信息。文献[9]也采用双流网络估计初始深度,通过基于能量函数的全局约束细化初始深度。虽然两篇文献采用了基于深度学习的方法,但是其执行一次前向传播运算只能得到一个像素的深度信息,要获取一张完整的深度图需要计算多次,并且都使用了细化处理(refinement),计算变得更加耗时。文献[10]采用RGB EPI Volume 作为输入,设计了一种U 型网络直接输出深度信息,计算较快。但是由于只考虑一个方向上的EPI,使得估计结果的准确度不高。
为了解决上述算法中暴露出的精度低、耗时长的问题,提出了基于EPI-DenseNet进行光场深度估计。该方法采用HCI 4D光场标准数据集,利用多个方向的EPI信息作为神经网络的输入,实现端到端的深度信息估计,一次计算即可得到完整的深度图,无需进行后处理等耗时操作,可实现快速准确的深度估计。并且该方法使用了密集连接的结构,解决了网络随着层数增加而出现梯度消失的问题。同时提出了适用于光场图像结构的数据增强方法,如随机灰度化,显著提升了训练数据的数量,加快了EPI-DenseNet的训练,改善了网络性能,提高了算法的鲁棒性。最终,通过对比实验,EPI-DenseNet在均方误差(Mean Squared Error,MSE)、不良像素率(Bad Pixel ratio,BadPixel)以及运算时间(runtime)上都取得良好结果。
2 DenseNet模型
自ResNet 提出以后,卷积神经网络的深度不断加深,ResNet 的变种网络层出不穷,性能也不断提升。CVPR2017提出的DenseNet[11]是一种具有密集连接的卷积神经网络,在该网络中,任意两层之间都有直接的连接,即每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接转递给其后面所有层作为输入。这种做法可以缓解由于网络层数增多在训练时引起的梯度消失的问题,加强特征传播,鼓励特征复用,并且极大地减少了参数量。
图1为DenseNet的一个Dense Block示意图,与ResNet中的BottleNeck 基本一致:BN-ReLU-Conv(1×1)-BNReLU-Conv(3×3),一个DenseNet 由多个Dense Block组成,每一个Dense Block 之间的层称为transition layers,由BN-Conv(1×1)-averagePooling(2×2)构成。在图像分类任务上,使用3 个数据集:CIFAR、SVHN 和ImageNet进行测试,DenseNet-100的测试误差为22.3%,已经优于ResNet-1001 的测试误差22.71%,并且后者的参数量为10.2×106,而前者只有0.8×106,可见DenseNet结构设计的优越性以及其优秀的特征抽取能力。
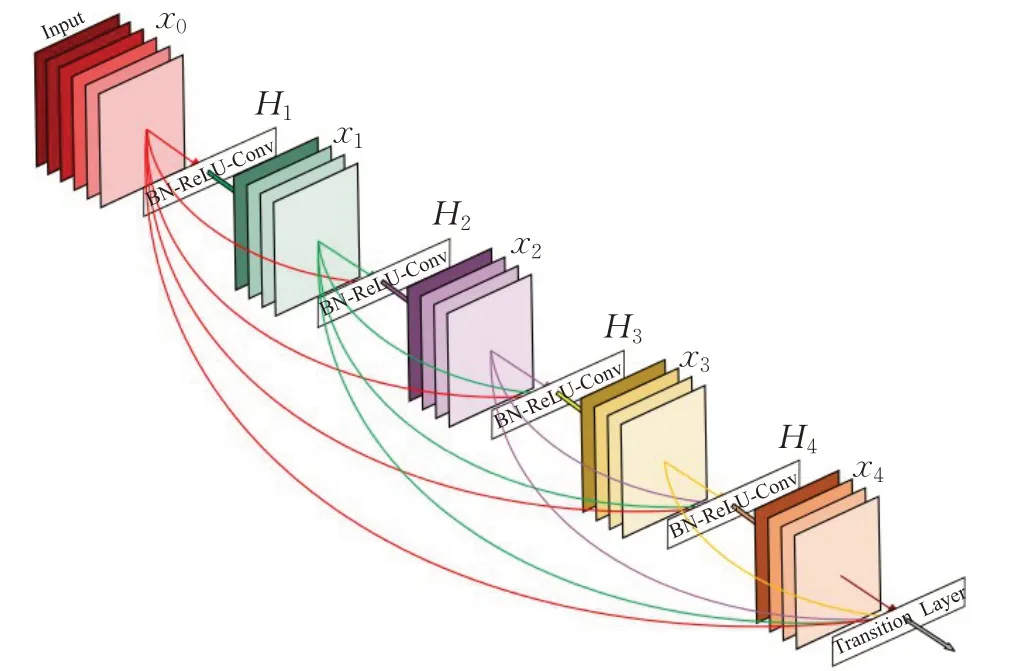
图1 Dense Block结构
3 EPI-DenseNet模型
本章将从模型结构设计,输入数据预处理,数据增强和训练细节来介绍EPI-DenseNet 进行光场深度估计的方法。
3.1 模型结构设计
设计一种端到端的深度全卷积网络[12]EPI-DenseNet,以光场的EPI 结构作为输入,以视差图(Disparity map)作为标签(label)训练网络。为了获得更加准确的估计结果,考虑使用水平、竖直和对角线4 个方向上的EPI Volume通过4条输入分支输入到网络的4个流中,完成低阶特征的提取,再将提取的特征融合,由网络的后半部分继续进行高阶特征抽取,最后转化为视差图,完整结构如图2所示。
前半部分采用的“Conv Block 1”结构如图3所示,考虑到视差图精度需求较高(像素级甚至是亚像素级),因此卷积核大小不宜过大,而EPI估计深度需要计算同一点在不同视角下的位移量,即需要跨通道搜索同一点,1×1 的卷积核由于其尺寸太小,无法感知点的位移量,因此,使用2×2的卷积核,步长为1,这样设置就可以测量±4的视差,并且全部使用valid-padding以加快训练速度。BN表示批归一化层(Batch Normalization),其作用是将批处理(mini-batch)输入的数据X:{X1,X2,…,Xm}的分布通过平移伸缩变为均值为0,方差为1 的正态分布,归一化处理的计算式为:
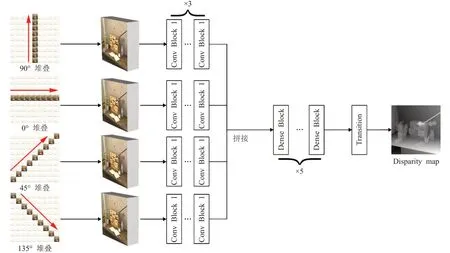
图2 EPI-DenseNet结构
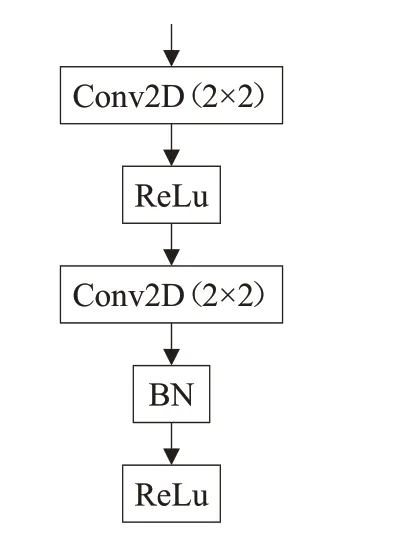
图3 Conv Block 1结构

其中,Xi表示批归一化层的输入数据,μ 为输入数据的均值,δ 是输入数据的标准差。归一化的目的是为了缩小输入空间,从而降低调参难度,加快网络的训练速度,由于目前训练网络常用的方法是批量随机梯度下降(mini-batch stochastic gradient descent),归一化可以防止梯度爆炸或梯度消失,从而加快网络收敛。激活函数采用线性整流函数(Rectified Linear Unit,ReLU),其表达式为:

ReLU 函数相比较其他激活函数,在随机梯度下降过程中能快速收敛,在计算机视觉领域运用广泛。
图2 后半部分在低阶特征融合之后,设计了一种“Dense Block”来提取高阶特征,其采用shortcuts 连接结构(Concatenate),使浅层和深层的特征可以更自由地组合,对于第l 层的输出来说,其输出Xl=Hl([X0,X1,…,Xl-1]),即网络的每一层输出都是之前层的组合,让网络去学习它们之间的组合方式,使得网络模型能充分利用每一层提取到的特征,提升鲁棒性,并且在训练深层的网络时可以减少梯度消失可能性,提升收敛速度,如图4所示,这是由于在传统网络执行反向传播时,输出层的梯度在不断向前传递时,梯度值逐渐减小,若网络层数较深,梯度传递到浅层时由于太小使得浅层网络参数无法得到很好的训练,在ResNet提出后,使用残差学习可以有效方便地传递梯度,如图5 所示,此时梯度计算式为:


图4 改进的Dense Block结构

图5 残差学习
对比传统的卷积神经网络,采用这种设计在网络深度相同时,需要训练的参数的数量会减少很多,从而使得网络训练难度较低,同时计算所需资源也会降低。
“Dense Block”中的特征提取采用了“BN-ReLUConv”的结构,如图6(a)所示。其中卷积核大小依然是2×2,步长为1,考虑到要将特征进行连接,特征的尺寸应该保持一致,故采用same-padding保证每一级特征的尺寸不变。为了将所有组合在一起的特征再进行压缩融合,使用了一种“Transition”的结构,如图6(b)所示,“Transition”中使用卷积核为1×1,步长为1,其目的是在保留特征形状不变的情况下,降低特征维度,压缩通道,通过非线性的激活函数可以为输入的特征添加非线性变换。与原始的DenseNet不同,EPI-DenseNet没有采用池化层(pooling)进行降采样,这是为了满足对不同分辨率的光场图像均可以进行深度估计。
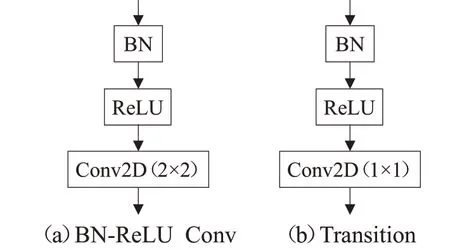
图6 Dense Block组成
通过采用Dense Block,网络的参数可以得到大幅减少,对比不采用密集连接的常规CNN(卷积层数相同,通道数相同),参数量对比如表1。
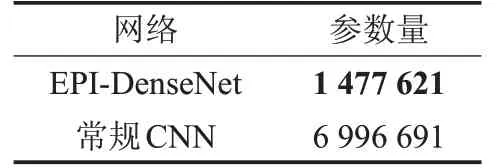
表1 参数量对比
从表1 中可以看出,EPI-DenseNet 的参数量远少于常规CNN,则其训练难度较低,且由于参数量较少,所需的计算资源也较低,具备一定优势,执行耗时对比如表2所示,可以看出EPI-DenseNet在效率上比常规网络高。

表2 对比常规CNN执行时间s
EPI-DenseNet最终将EPI特征转化为一张高精度的视差图,根据光场成像原理中视差与深度之间的几何关系,可以通过以下公式快速计算深度值:

其中,f 为相机焦距,Z 为P 点的深度值,Δx 表示P点在不同视角下的位移量(视差),Δu 为相机镜头阵列的基线长度。
3.2 输入数据预处理
使用的数据集为HCI 4D标准光场数据集,数据集提供共计20个人工合成的光场场景的RGB图像以及其对应的视差图和深度图,如图7 所示,其中16 个作为训练集用于算法模型的训练,4个作为验证集用于验证模型的泛化能力,每个场景的物体、纹理均不相同。该数据集是基于标准全光相机设备参数进行设计合成的,因此其光场图像具有基线较短,分辨率较低的特点。该数据集所提供的图像分辨率为512×512,有9×9 个不同视角的RGB图像。
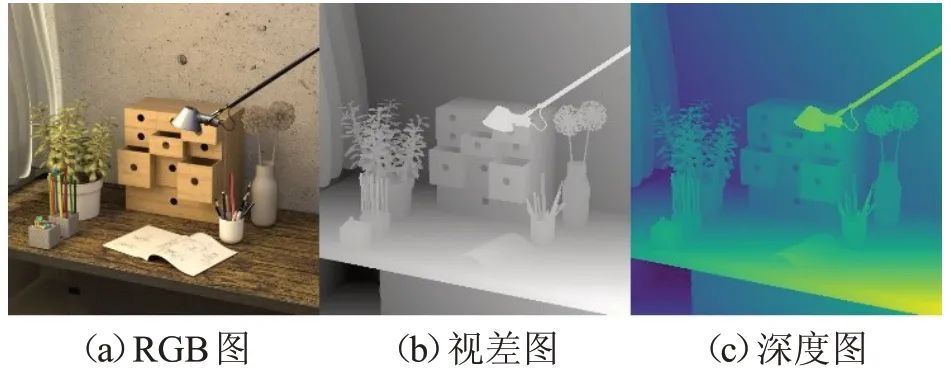
图7 HCI 4D光场数据集
与文献[10]采用RGB EPI Volume 作为输入不同,对于视差以及深度信息来说,对颜色信息是不明感的,因为采用EPI 进行深度估计时,不论是彩色的EPI 还是灰度化的EPI,其极线的斜率均是可以准确求出的,因此,为了降低网络对数据的计算量,对于RGB图首先进行灰度化处理,将RGB值压缩为灰度值,其操作为:

式中,R(i,j),G(i,j),B(i,j)为(i,j)像素点的三种颜色通道的分量。然后将得到的灰度图按照图8中左侧箭头所示顺序堆叠,得到一个512×512×9的EPI Volume,表示9张分辨率为512×512的灰度图的叠加,以此作为一个输入流。EPI-DenseNet使用了4个方向上的EPI Volume,如图1 左侧所示,采用多个方向的EPI 可以利用更多的视差信息,用于提高网络估计的准确性。

图8 水平方向EPI Volume输入
3.3 数据增强
采用深度学习的方法要求训练集必须具备一定大的规模,但是原始训练集只提供了16个场景,远远无法满足深度学习的要求,因此,除了对数据做基本的预处理操作,还需要进行数据增强的操作,以达到训练卷积神经网络对数据的需求。
结合文献[13]中针对单目深度估计提出的一系列数据增强的方法,考虑到HCI 4D光场数据集拥有多张不同视角的图片,拥有更多的深度线索,并且目前网络规模较大,需要大量训练数据,因此采取了如表3 的数据增强方式来扩充训练数据,以达到网络可以训练的基本要求。

表3 数据增强表
随机灰度化采用的方式如下:

其中wR,wG,wB分别为RGB 三通道的权重,这三个数值是随机生成的,且满足以下条件:

使用无随机灰度化训练网络作为对比,当两个网络收敛到同一水平时,在测试集上的4 个场景预测,计算不良像素率,结果如表4 所示,采用随机灰度化会显著提高模型的泛化能力,而无随机灰度化的网络训练结果出现了过拟合问题,导致在测试集上表现不佳。

表4 随机灰度化对BadPixel的影响 %
此实验采用的数据增强方式是表1 中各种方式的随机组合,因此,将原始训练集可以扩容到满足EPIDenseNet训练的需求。
需要注意的是,在图像旋转之后,灰度图的叠加顺序和输入网络的顺序也要相应地改变,如图9,例如:旋转90°,此时竖直方向上的图像叠加之后需要输入到网络的水平方向的输入流中;旋转180°,此时竖直方向上的所有图像的叠加顺序也要对应地变化。
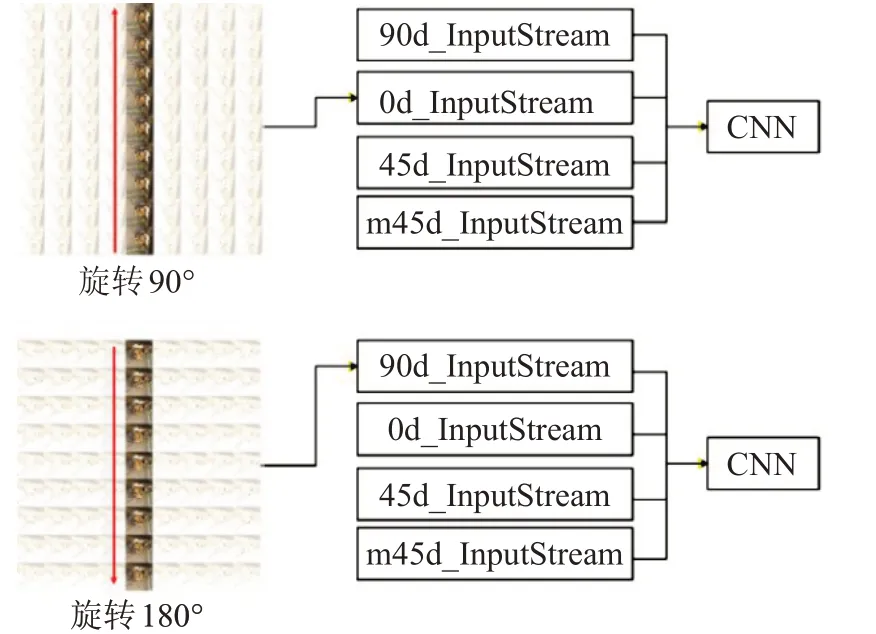
图9 图像旋转后的调整
3.4 训练细节
由于EPI-DenseNet是全卷积神经网络的结构,没有池化层(pooling),因此,可以接受任意大小的输入图像,不用要求训练图像和测试图像具有相同的尺寸。如果将512×512 的图像直接输入网络,由于像素过多,会无法训练,因此采用25×25 的随机裁剪图像进行网络训练,再用512×512的图像进行验证。
在使用512×512的图像作为输入时,网络前半部分采用尺寸为2×2的卷积核进行卷积,步长为1,没有采用padding,因此其特征提取过程中的特征图尺寸会减少,而后半部分的采用2×2卷积核,步长为1,并且使用padding来维持特征图尺寸不变,最终网络输出的视差图尺寸为506×506。
在部分场景中,存在镜面反射的区域,对于训练网络会产生不良影响,因此在训练时将这部分区域去除,以保证网络训练的准确。
网络训练采用的损失函数(loss function)是平均绝对误差(mean absolute error),表达式如下:

其中,yi表示真实值,表示估计值,m 为视差图的像素点数。
训练使用的是小批量随机梯度下降,批次大小(batch-size)设为16,优化器(optimizer)采用RMSprop,初始学习率为10-4。
训练的机器CPU 为E5-2650 v4,GPU 为NVIDIA TITAN V,采用Tensorflow 为训练后端,Keras 搭建网络,训练时间大约1~2天即可得到良好的结果。
训练每完成一次迭代(iteration),就采用512×512分辨率的图像作为验证集(validation set)验证训练结果,评价的标准为均方误差和不良像素比率(bad pixel ratio)。均方误差用于描述估计结果的平滑度,均方误差越小,表示结果越好。均方误差的计算式如下:

当一个像素点的估计结果与实际数据相差超过一定阈值时,这个估计得到的像素点就是不良像素,不良像素的数量占总像素数的比重则称为不良像素比率,不良像素比率用于描述估计结果的准确度,其值越小表示估计准确度越高。其计算式为:
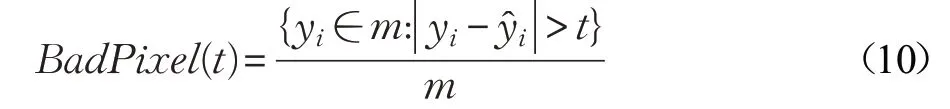
式中,t 表示阈值,这里采用的阈值为t=0.07。
最终实验的迭代过程如图10、11。

图10 MSE随迭代下降

图11 BadPixel随迭代下降
如图10 和图11,EPI-DenseNet 在训练时,随着网络训练次数的增加,均方误差和不良像素率在不断下降,说明EPI-DenseNet的网络结构较好,能够很快速地收敛。
4 实验结果与分析
本章主要介绍采用文中算法模型得到的深度估计信息结果,并且与其他深度估计算法在同一个测试场景中的结果进行比较。
4.1 算法结果
采用的测试集为HCI 4D 光场标准数据集中的test分类下的4 个不同场景Cotton、Dino、Sideboard、Boxes,其场景的复杂从左到右依次增大,Cotton场景中是一个雕像,场景较简单,估计难度较低;Dino场景增加了许多多边形边缘信息以及阴影的干扰,估计难度有所提高;而Sideboard在墙体部分使用了复杂的纹理,且在书架的部分由于书本高度不齐,其边缘信息较为复杂;Boxes场景中在镂空的盒子中装有书本,对书本进行了部分遮挡,估计难度较高。这4个场景的中心视角视图如图12所示。

图12 测试场景
将测试集的图像数据进行预处理之后,输入已经训练收敛的EPI-DenseNet 中,预测得到的视差图,与其他文献结果对比,最终对比结果如图13所示。

图13 实验结果对比
从图中可以看出,在左侧两个场景Cotton 和Dino中,EPI-DenseNet 估计结果准确,图形边缘处也较为平滑,在复杂场景Sideboard 和Boxes 中,边缘处的锯齿相对较少,对于Boxes中网格遮挡情况的估计结果也好于图13(c)、(d)。
4.2 算法性能分析
本节将EPI-DenseNet 与现有的文献算法进行性能比较,计算估计结果的均方误差和不良像素率。文献算法分为基于深度学习的和非基于深度学习的,算法比较结果如表5所示。

表5 实验结果对比
由此可见,EPI-DenseNet在4个测试场景中,均取得了比较良好的成绩,说明本文算法估计结果平滑,并且准确度比较高。其中LF[5]、EPI1[14]和BSL[15]是基于匹配或稀疏编码的方式进行的光场深度信息估计,EPIDenseNet 在MSE 和BadPixel 指标中均优于这三种算法。由此,可以说明采用基于深度学习的方式也可以获取精度较高的深度信息。对比常规CNN,由于层数较多,参数量较大,训练耗时较长,在精度上表现不佳。
在计算效率上,匹配算法需要进行大量的计算,且很多情况下要对匹配结果加入精细化后处理,计算时间会大大增加;而EPI-DenseNet只需进行一次前向传播计算即可得到完整的深度图,计算效率得到了很大的提高,具体比较结果如表6所示。
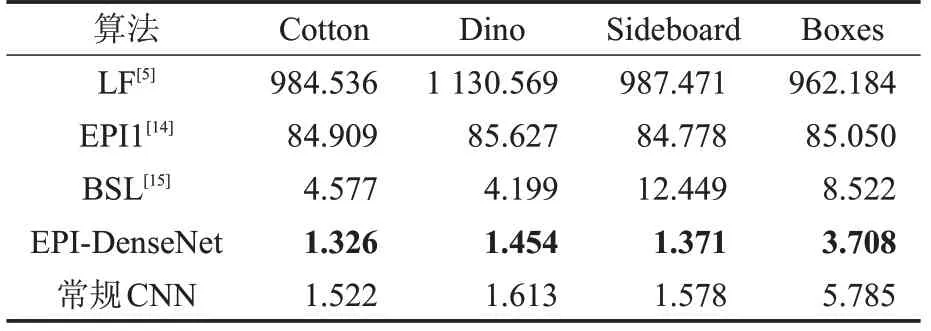
表6 计算时间对比s
可以看出,在所有测试场景中,EPI-DenseNet 在计算效率上体现出了巨大的优势,计算速度远超其他算法,对比常规CNN,在精度上取得了更好的结果。综上所述,EPI-DenseNet在计算精度和时间上做了很好的权衡,在保证了计算结果准确的前提下,大幅减少了计算所需时间。因此,可以说明本文算法是有效且快速的。
5 结束语
本文采用深度卷积神经网路进行光场深度信息估计,通过随机灰度化等数据增强方法有效地扩充了训练数据,使得网络模型可以正确地学习光场的EPI结构,提取所需特征转化为深度信息,并且采用了密集连接型的结构来减少网络参数,节省了计算资源。最终,对比其他文献算法,EPI-DenseNet在光场图像深度估计的准确率和精度上显示出了优势,在计算效率上也有很大提高。
