双通道混合神经网络的文本情感分析模型
2020-06-09杨长利鲁明羽
杨长利,刘 智,鲁明羽
大连海事大学 信息科学技术学院,辽宁 大连116026
1 引言
文本情感分析是自然语言处理(Natural Language Processing,NLP)领域一个重要的分支,通过对含有情感倾向的文本评论进行分析,帮助研究机构、信息咨询组织和政府部门掌握社会情绪动态。
传统的文本情感分析方法主要是基于情感词典的方法和基于机器学习的方法。昝红英等[1]将支持向量机与规则方法相结合并在KNN 和Bayes 分类器上进行对比实验,证明其有效性;王志涛等[2]通过利用统计信息和点间互信息增加新感情词扩充已有情感词典来识别微博新词并理解其情感含义,并提出了基于词典和规则集的方法利用附加信息辅助文本情感分析;Turney 等[3]提出一种半监督方法,即标记一部分种子词,通过计算一个词与种子词同时出现的概率来决定情感倾向。基于机器学习的算法相较于基于情感词典的方法有了一定的进步,但需要人工和领域知识对文本特征进行标记,特征扩展性不灵活。
深度学习(Deep Learning,DL)在不同领域都取得了优异成绩[4-9],卷积神经网络(Convolutional Neural Networks,CNN)和循环神经网络(Recurrent Neural Networks,RNN)是深度学习中的两大主流应用。随着胶囊网络在图像处理领域表现出的良好性能[10],Zhao等[11]首次将胶囊网络应用在情感分析任务上,减少了CNN在池化层的特征信息丢失,分类性能超过了CNN[12];Cho等[13]提出了GRU的基本结构,解决了长距离依赖问题,消除了梯度爆炸或梯度消失的问题,而且模型结构较LSTM 更加简单,训练速度更为快速,BiGRU 能够获得双向上下文信息。
本文提出双通道混合神经网络(Two-Channel Hybrid Neural Network,TC-HNN)的文本情感分析模型。混合神经网络将基于注意力机制的胶囊网络和Bi-GRU拼接融合,通过注意力机制关注文本关键信息,结合提取局部特征和全局特征的优势,将两种不同的词向量经过混合神经网络的结果进一步进行拼接融合。
2 相关工作
近年来,随着深度学习技术在计算机视觉方面取得巨大成功,也成为文本情感分析的主流技术。Kim[12]利用word2vec 预训练的词向量,通过单层卷积神经网络来处理文本情感分析取得了较好的成绩。Lai等[14]提出使用双向卷积神经网络提取上下文的信息,不需要通过设定窗口大小来决定对上下文的依赖长度。CNN 和RNN在文本情感分析方面各有优势,将两者结合使用,取两者的优势,也逐渐成为流行的方法,Lai 等[14]使用RNN 捕捉上下文信息,然后用CNN 来捕获文本中的关键信息;Zhang等[15]利用单词级CNN来提取每个单词的特征,同时用BiGRU获得语境的语境信息和语义分布,分类性能得到提升;王汝娇等[16]提出了卷积神经网络与多特征融合的方法大大提高了情感分类的准确性。
基于注意力机制的神经网络模型在各项任务中都取得了较好的结果,文本情感分析也不例外。Bahdanau等[17]将注意力机制与循环神经网络结合应用到机器翻译的任务,是NLP领域的第一次尝试;Wang等[18]提出了基于注意力机制的LSTM,加强了提取特征信息的能力;Yang等[19]在字词层面和句子层面分别使用注意力机制,给予重要程度不同的字词和句子以不同关注程度。
本文用胶囊网络、BiGRU、注意力机制和双通道模式来进行文本情感分析,胶囊网络提取文本局部空间信息,减少CNN池化层信息的丢失,BiGRU提取文本全局空间信息,并利用注意力机制捕获关键信息,将两个结果拼接。同时,使用两种不同的词向量表示,将其经过混合神经网络的结果在融合层进行拼接融合,从而获得更多的文本特征,提高分类准确性。
3 双通道混合神经网络模型
为了进一步提高情感分类准确性,本文提出双通道混合神经网络的文本情感分析模型。先将文本序列向量化,用Glove和Fasttext两种预训练的词向量作为混合神经网络的输入,分别将经过基于注意力的胶囊网络和BiGRU 的结果进行拼接输出,再将两种不同词向量经过混合神经网络的结果进行拼接,进一步丰富文本输入特征,提高文本情感分析效果。
TC-HNN的文本情感分析模型结构如图1所示。
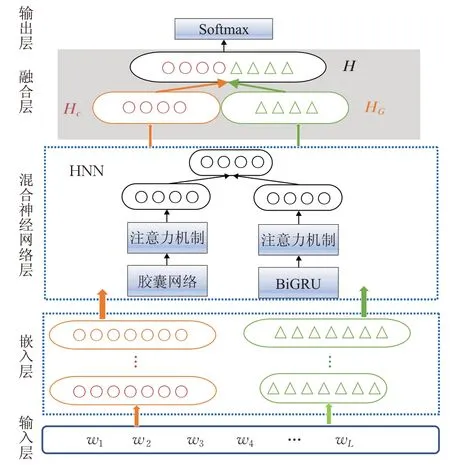
图1 双通道混合神经网络模型
3.1 词向量
首先,将文本内容表示成深度学习能够处理的形式。离散表示(One-hot Representation)将文本中的每个单词用一个长向量表示,向量的维度就是词表的大小,但这种表示方式无法反映词之间的联系,忽略了单词的上下文语义,而且还会导致特征空间非常大。分布式表示(Distributed Representation)则考虑了单词的上下文语义信息和刻画语义之间的相似度,并且是维度较低的稠密向量表示,常用的词向量表示有Word2Vec、Glove和Fasttext等。
为了丰富文本特征,本文采用双通道输入策略,将Glove 和Fasttext 词向量分别放入本文提出的混合神经网络,将得到的两个结果进行拼接融合,从而达到丰富输入特征的目的。
3.2 混合神经网络模型
混合神经网络结构结合了胶囊网络和BiGRU的优点在学习局部特征的同时还可以学习上下文信息,并且通过注意力机制进一步提取文本的关键信息,提高情感分类的准确度。
3.2.1 胶囊网络
原始CNN池化层会丢失大量的信息使得文本特征大大减少,并且神经元节点只是一个标量。而在胶囊网络(Capsule Network,CapsNets)中使用矢量“胶囊”来替换表示传统神经网络的神经元节点,并通过动态路由来学习单词之间的上下文语义关系。
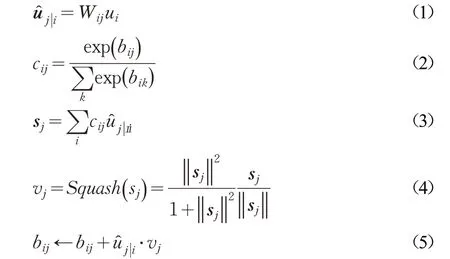
其中,vj是胶囊j 的矢量输出,sj是胶囊j 的输入,Squash()是非线性激活函数将向量sj转化成vj,是预测矢量,ui是上一层胶囊的输出,cij为耦合系数,用来预测上层胶囊和下层胶囊之间的相关性,值越大表示相关性越强,反之,值越小表示相关性越弱。bij在胶囊i 连接到更高级别胶囊的所有耦合系数的新值之前进行更新。从而得到局部特征:

3.2.2 BiGRU模型
GRU 相对LSTM 来说结构更加简洁、参数更少、收敛性更好。GRU中更新门控制前一时刻的状态信息被带入到当前状态中的程度。重置门控制忽略前一时刻的状态信息的程度。具体结构如图2所示。
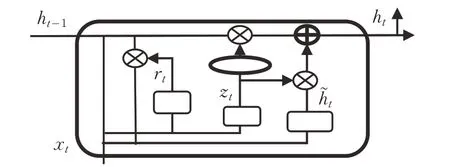
图2 GRU模型结构
GRU模型的更新方式如下:

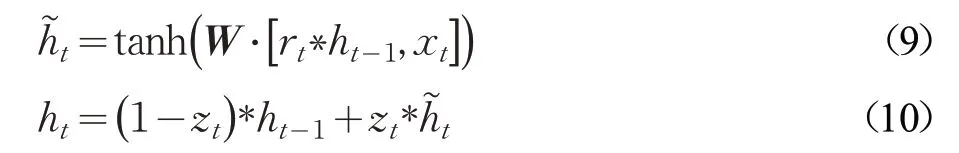
其中,xt表示t 时刻给定的输入,ht-1表示在(t-1)时刻隐藏层状态,zt表示t 时刻的更新门,rt表示t 时刻的重置门,是控制信息选择性通过的机制,由一个Sigmoid神经网络层和一个向量点乘组成。表示需要更新的信息,ht表示t 时刻隐藏层状态,W WzWr表示权重矩阵,σ 和tanh 为激活函数。
给定文本中单词wi,i ∈[ ]1,L ,L 是文本长度,文本单词向量化xi=We⋅wi,i ∈[1 ,L] ,
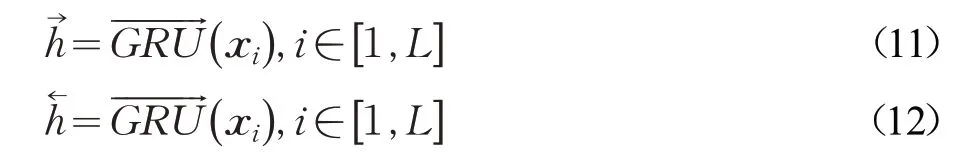

3.2.3 注意力机制
在文本评论中,并非所有的单词对文本意思的表达同等重要,对于重要的语义信息给予更多的注意力,反之,其他部分分配相对较少的注意力。例如,“well,it was nice while it lasted.”中的单词“nice”,它对文本意思的表达相对于其他单词来说更加重要,要对其给予更多的注意力。因此引入注意力机制(Attention Mechanism)从大量信息中选择对当前目标更为重要的信息。公式如下:

经过一层MLP(Multi-Layer Perception)得到hi的隐藏层表示ui,Wwbw是注意力的权重和偏置项。通过Softmax函数获得每个单词的标准化权重ai,最后通过加权计算得到文本表示r 。将BiGRU和CapsNets结果作为输入经混合神经网络分别得到:

3.3 融合层
混合神经网络中将基于注意力的胶囊网络和BiGRU模型结果进行融合,既能够提取局部特征、减少池化层的信息丢失,又有处理文本序列全局特征的能力,兼顾两者的优势。

⊕表示将结果进行拼接。
用不同的词向量来表示文本内容,可以对文本特征进行补充,将混合神经网络的输出进行融合,从而丰富输入特征。将两种不同的词向量Glove 和Fasttext 作为输入,经过混合神经网络得到H'g和H'f,再将结果进行拼接。

3.4 输出层
将融合层的结果H 输入到输出层,利用Softmax函数对输入进行相应的计算,进而进行文本分类,计算方式如下:

4 实验结果与分析
4.1 数据集
本文采用三个标准英文数据集:MR、Subj和MPQA对模型进行评估,基本信息如表1所示。
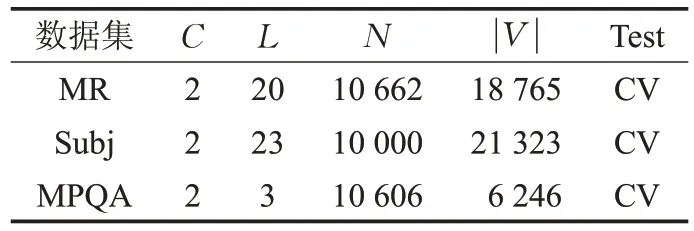
表1 数据集信息
C 为类别个数,L 为文本平均长度,N 为数据集大小, ||V 为词汇数量,CV表示10-foldCV。
MR(Movie Reviews):电影评论语句极性数据集v1.0,每个评论一句话。它包含从Rotten Tomatoes网站页面提取的5 331个正片段和5 331个负片段。
Subj:主观性数据集包括主观评论和客观情节摘要。主观性数据集是将文本分类为主观或客观。
MPQA:MPQA数据集的意见极性检测的子任务。
4.2 神经网络模型参数设置
神经网络模型的参数设置如表2所示。
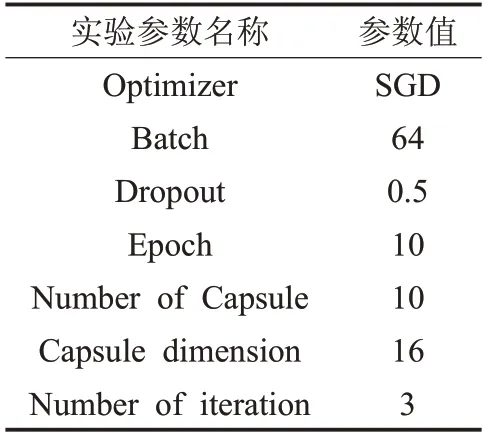
表2 参数设置
4.3 结果分析
本文所提方法的分类准确率与其他方法的比较如表3所示,“—”表明该模型未在该数据集上评估。
实验结果如表3 所示,从表中可以看出,本文提出的基于深度学习的模型相对基于传统机器学习算法的模型显著提高了分类效果。在上述深度学习网络中,CNN-rand 取得相对较低的分类效果,这是因为忽略了词的上下文含义和词之间的前后依赖关系,而Capsule取得相对CNN 较好的分类效果,说明Capsule 比CNN有更好的提取特征的能力,准确率分别提高了5.2%和3.7%。ACNN(BiGRU)有很好的效果,既能获得长距离的依赖信息,双向结构又能很好地包含每一个单词的上下文信息。本文提出的模型准确率达到86.65%、95.39%、94.0%,与其他模型最高准确率相比提高了3.25%、1.19%、3.20%,可以看出本文提出的模型结构在三种数据集上的实验结果,较其他基准模型和先进模型有较大幅度的提升,实验结果也证明了本文模型有效性。
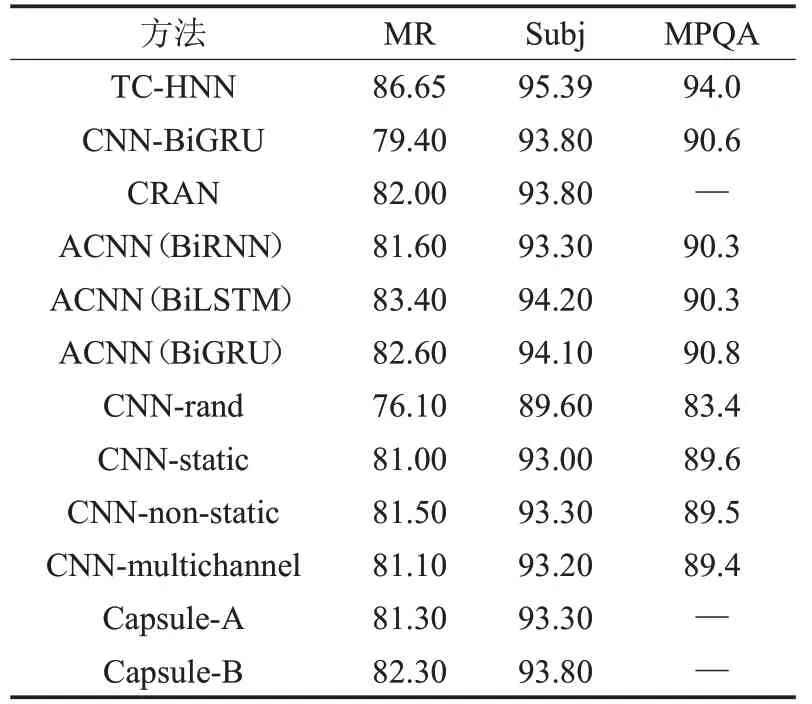
表3 实验结果对比(准确率-Accuracy)%
为了进一步证明本文所提出的双通道融合模型的有效性,设置模型对比实验,进行分类性能验证。将本文所提模型TC-HNN 与基于Glove 混合神经网络的单通道模型和基于Fasttext混合神经网络的单通道模型进行对比实验。比较结果如表4所示。

表4 各对比实验结果(准确率-Accuracy)%
由表4可知,本文提出的双通道融合模型在三个数据集上,较基于Glove混合神经网络的单通道模型分别提高了0.58%、0.09%、0.48%,较基于Fasttext 混合神经网络的单通道模型分别提高了1.32%、0.97%、10.77%,由此说明本文所提出的双通道融合模型比单个模型能够提取更多的文本特征,提高文本情感分类的效果。
用混淆矩阵对实验结果进一步分析,数据集实际分类情况如图3所示。
图3纵向表示文本的实际类别,横向表示模型预测文本的类别,右混淆矩阵右侧的颜色深浅表示文本的数量多少。TN(True Negative)表示本身是负样本,被分类为负样本的样本数,TP(True Positive)表示本身是正样本,被分类为正样本的样本数,本文将标记1 表示为正样本,标记0 表示为负样本。由图3 可知,TN 值为486,占比93.8%,TP 值为531,占比96.9%,可以很清楚地看出两者差距较小,证明了该方法的有效性。

图3 MR测试集实际分类效果
5 结束语
本文提出了TC-HNN 模型。混合神经网络利用胶囊网络处理CNN 池化层丢失特征信息的问题,更好地提取局部文本特征,BiGRU 模型能够有效地提取全局文本特征,分别在胶囊网络和BiGRU 后引入注意力机制,进一步提取文本的关键信息,用并行的方式结合两种模型,将结果进行拼接融合,取两者优势,丰富特征信息。用不同的词向量来表示文本内容,可以对文本特征进行补充,将两种不同的词向量经过混合神经网络的结果进行融合,从而达到丰富输入特征的目的,实验结果证明了本文模型的有效性。下一步研究工作将对模型进一步优化,在保证精度的同时缩短模型运行时间,以便适应大规模的文本情感分析。
