NFV中单节点启发式资源分配方法
2020-06-09畅海峰杨雅婷
畅海峰,嵩 天,杨雅婷
北京理工大学 计算机学院,北京100081
1 引言
网络功能虚拟化[1](Network Functions Virtualization,NFV)的目标在于:使用基于x86 的通用标准服务器代替传统网络中的专用电信网元设备,通过虚拟化技术实现软硬件解耦,使网络功能不再依赖于专用硬件。
然而,与传统专用电信设备相比,将网络功能(Network Functions,NFs)以软件形式部署在虚拟环境中会导致网络功能报文处理能力下降。虚拟化技术的固有性能损失会直接影响NFs性能。此外,基于通用设备的软件NFs 与专用电信设备之间的报文处理能力仍存在较大差距。DPDK[2](Intel Data Plane Development Kit)是Intel 提供的数据平面开发工具集,专注于网络数据包的高性能处理,已在很多场景中被用来加速虚拟网络功能。
NFV使用通用标准服务器作为统一计算平台,在有限物理资源条件下,如何在合理分配资源的前提下部署虚拟网络功能(Virtual Network Function,VNF),以满足用户各种业务需求,是网络功能发展过程中重要的挑战之一。现有网络功能虚拟化资源分配的相关研究多数是从编排层面提出部署方案,决定VNFs 的物理部署位置。本文则考虑实际部署环节,针对单物理节点部署多VNFs场景,采用DPDK加速虚拟网络功能,并研究网络功能虚拟化中的单节点资源分配问题(NFV Single Node Resource Allocation,NFV-SNRA)。
2 网络功能虚拟化发展现状
NFV将网络功能从专用网元设备中抽象出来,以软件形式实现,并部署在通用标准服务器上,从而实现网络功能的灵活部署。NFV架构[3]由三部分构成:网络服务、网络功能虚拟化基础设施(Network Functions Virtualization Infrastructure,NFVI)以及网络功能虚拟化管理和协调控制器。
运营商通过软件方式定制网络功能,通过组织一系列VNFs 实现特定的网络服务,从而更灵活快速地部署新服务。NFV 架构使用通用标准服务器作为统一计算平台,运营商能够更灵活高效地利用虚拟化基础设施物理资源[4]。
2.1 网络功能虚拟化面临的挑战
目前NFV已被学术界广泛接受,具有美好的前景,但NFV技术整体上仍处于起步阶段,在性能、资源分配等方均面临挑战。
2.1.1 性能
VNFs通常运行在虚拟环境中,相较宿主设备,虚拟设备(例如,虚拟磁盘、虚拟网卡)的访问性能明显下降。Passthrough 技术可以支持虚拟机直接访问外围设备,提高虚拟机对外围设备的访问性能。但该技术下,设备以独占方式分配给某个客户域,无法在多客户域之间共享。SR-IOV[5](Single Root I/O Virtualization)规范定义了一个标准化的硬件虚拟化机制,原生地支持多客户机共享物理设备,使设备资源得到充分利用。
网络I/O 能力是VNF 性能的核心关键。传统模式中,Linux 内核态网卡驱动基于异步中断模式处理网络读写事件。DPDK 则采用用户态网卡驱动基于轮询(PMD)或者轮询中断混杂模式处理网络读写事件。相较中断方式,轮询方式避免了上下文切换造成的性能损失。另一方面,用户态PMD 驱动将网卡设备直接映射到用户空间,通过旁路Linux内核网络协议栈,减少内存拷贝次数,进而提升报文转发能力。
Passthrough 技术、SR-IOV 技术以及DPDK 从多个不同方面缩小了基于通用设备的VNF与专用电信设备之间的性能差距。
2.1.2 资源分配
网络功能虚拟化资源分配问题[6-9](Network Functions Virtualization Resource Allocation,NFV-RA)一直是NFV发展过程中的研究热点之一。相关研究以QoS、利润最高、容错、负载平衡、节省能源等为目标,同时考虑性能、能耗、安全等多方面因素,解决构建虚拟网络功能链[10-12]、部署虚拟网络功能[13-15]、调度虚拟网络功能[16]等方面的资源分配问题。
其中,部署虚拟网络功能阶段解决如何将VNFs 映射到NFVI 中的物理节点,虚拟网络功能部署问题已被证明是NP 难问题。在网络规模较小时,使用线性规划能够得到最优解。但网络规模越大,线性规划模型越复杂,无法在可接受时间内得到全局最优解。使用启发式算法或元启发式算法能够在线性时间内得到近似最优解。
2.2 相关工作
为解决网络功能部署和编排问题,Chi 等[17]提出一种基于3-tire 树形结构的VNF 部署和流量调度算法。Cohen等[18]对VNF部署问题进行线性约束建模,提出一种近似最优的部署算法;Sang 等[19]将VNF 部署问题规约为集合覆盖问题,基于贪心算法提出一种可验证的高效部署方案。段通等[20]考虑硬件加速资源,提出一套VNF硬件加速资源编排机制。然而,上述研究都是从编排和部署方案层面分析NFV 资源分配问题,却鲜有涉及VNF 具体部署环节,即对于部署到同一个物理节点上的所有VNFs,如何更高效地共享该节点的物理资源。毕军等[21]考虑VNF并行加速,根据网络功能之间的依赖性,提出一个高性能编排框架,但仍属于编排设计层面,未解决具体的节点资源分配问题。
本文考虑实际部署环节,针对单物理节点部署多VNFs场景,使用DPDK加速虚拟网络功能,研究虚拟网络功能的资源分配问题,使用最少的物理资源满足所有VNFs性能需求。
3 DPDK性能测试与分析
通过实验深入分析DPDK 对虚拟网络功能的加速效果,测试内核协议栈方式和DPDK方式的网络包转发性能及CPU资源消耗情况。
基于2 台配备有两块Intel®Xeon®E3-1220 v3 @3.10 GHz CPU,32 GB 内存和一块双端口Intel®82599 10 Gbit网卡的服务器组成实验平台,进行性能测试。虚拟机以Passthrough 方式获得网卡的访问权限。内核协议栈发包程序采用Linux 内核发包模块pktgen,内核协议栈收包程序基于libpcap实现;DPDK收发包程序基于DPDK-16.11.3实现。
图1(a)为普通虚拟网络功能配置结构,图1(b)为经过Passthrough、DPDK加速后的虚拟网络功能配置结构。普通配置结构中,物理网卡和虚拟网卡均由Linux内核驱动控制;后者以Passthrough方式将网卡直接分配给虚拟机,并通过DPDK用户态驱动将网卡直接映射到用户空间。
3.1 转发性能测试
网络包发送测试结果如图2所示。
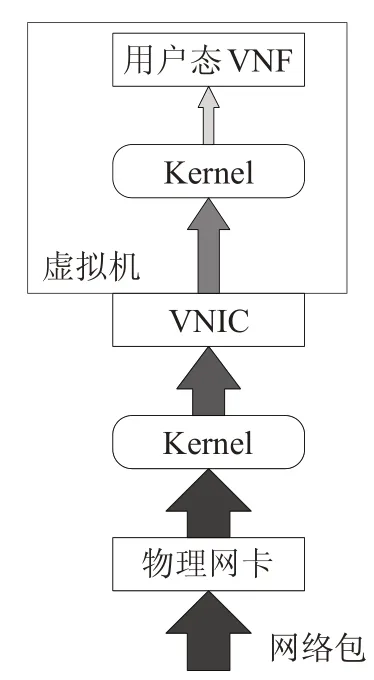
图1 (a) 普通配置

图1 (b) 经Passthrough和DPDK加速的配置

图2 不同包长的网络包发送性能
对比虚拟机中DPDK 和pktgen 的网络包速发送速率。不同包长情况下,pktgen 发送速率均处于较低水平;而DPDK发送速率在不同包长情况下变化显著。包长越小,pktgen与DPDK的性能差距越明显。发送64 B小包时,DPDK 网络包发送速率为pktgen 的7.7 倍。发送1 500 B 大包时,DPDK 发送速率提升约2.5%。实验结果表明,在虚拟机中,包长越小,DPDK对网络包发送性能提升越大,当包长达到最大时,二者性能间几乎不存在差距。
对比物理机中DPDK 的网络包发送速率与10 Gb链路的理论带宽值。物理机中DPDK 的发送速率接近10 Gb链路的理论带宽。最差情况是发送64 B小包,此时DPDK的发送速率为10 Gb链路理论带宽的97.2%。实验结果表明,物理机中DPDK 的发送速度几乎达到10 Gb链路的理论带宽。
图3 显示libpcap 与DPDK 在不同环境、不同包长情况下的网络包接收速率。与图2 中规律相似,相较libpcap,DPDK 处理小包的优势明显。在虚拟机中,DPDK接收64 B小包速率是libpcap的18倍。

图3 不同包长的网络包接收性能
上述实验结果表明,DPDK能够显著提升虚拟网络功能的网络包转发性能。
3.2 CPU资源消耗测试
测试pktgen和DPDK的CPU资源消耗情况,对比在虚拟环境中不同包长、不同发送速率情况下,两种方式的CPU占用率。
如图4所示,pktgen的CPU占用率随发送速率增加而升高,当发送速率超过9.95 kp/s 时,其CPU 占用率为100%;DPDK的CPU占用率始终为100%。

图4 pktgen和DPDK的CPU占用率
综上,DPDK 能够更好地处理高负载网络,但在处理低负载网络时,CPU 有效利用率低。基于以上发现,针对不同网络负载大小,采用不同方式(Linux 内核或DPDK)实现的VNF 实例。负载较低时,采用传统基于Linux内核实现的实例,使用较低CPU资源即可满足网络负载;负载较高时,传统方式VNF实例的CPU占用率升高,并发生频繁丢包,此时切换采用基于DPDK 实现的VNF实例。
4 启发式资源分配方法
针对单物理节点部署多VNFs场景,如图5所示,在考虑利用DPDK加速虚拟网络功能的基础上,提出一种基于贪心算法的启发式资源分配方法,保证虚拟网络功能性能的同时,降低CPU资源消耗。
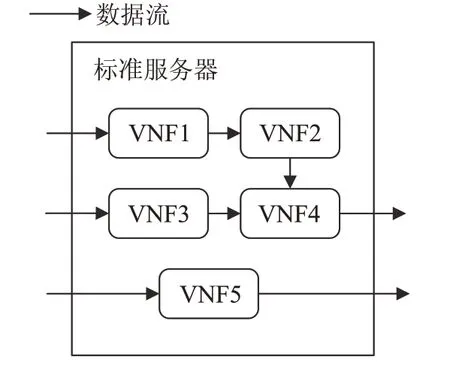
图5 单节点部署多个VNFs
针对网络流量负载的潮汐现象,提出一种基于网络负载的VNF 实例自动切换方案,根据实时网络负载自动切换VNF实例,满足网络负载需求的同时,降低CPU计算资源消耗。
4.1 基于贪心算法的虚拟资源分配方法
DPDK 能显著提升VNF 的转发性能,其CPU 亲和性特点要求特定任务只在特定CPU 核上运行。然而,普通部署方法中,虚拟CPU 核与物理CPU 核之间的对应关系具有不确定性,这导致DPDK特定任务实际绑定的物理CPU 核不固定,违背了DPDK 的CPU 亲和性原则,从而造成性能损失。
基于上述发现,提出一种基于贪心算法的启发式资源分配算法,确定虚拟CPU与物理CPU的对应关系,并在保证虚拟网络功能性能需求的同时,将CPU 资源占用降低到最小。
4.1.1 问题描述
NFV-SNRA问题相关定义如下:
(1)F={f1,f2,…,fm} ,F 表示部署在一个物理节点上的所有虚拟网络功能集合。|F|=m ,表示该物理节点共部署m 个虚拟网络功能。
(2)R={r1,r2,…,rn},R 表示物理节点各CPU 核的计算资源量,可用CPU核数为n 个。
(5)Xij表示是否将虚拟网络功能fj部署在CPU核i 上,1表示是,0表示否。
(6)L={l1,l2,…,ln},L 表示一个可行解,li表示CPU核i 上部署的虚拟网络功能集合。
(7)E(i)表示CPU 核i 上是否部署了虚拟网络功能。若CPU 核i 没有被分配给任何虚拟网络功能,则E(i)为0;否则为1,表示CPU 核i 上至少部署了一个虚拟网络功能。

NFV-SNRA 所解决的问题是,在满足所有VNF 需求的前提下占用最少CPU资源,形式化描述如下:
目标:

满足:

其中,公式(3)表示,部署在CPU核i 上所有虚拟网络功能的CPU 需求量之和不超过该CPU 核的CPU 资源量。公式(4)表示,所有虚拟网络功能都应得到资源分配,即满足所有虚拟网络功能的CPU资源需求。目标是使用最少CPU核。
4.1.2 困难性分析
集合覆盖问题是一个经典NP 难问题,通过将集合覆盖问题规约到NFV-SNRA 问题,证明NFV-SNRA 问题是NP难类型。
集合覆盖问题中,集合U={e1,e2,…,em}共有m 个元素,Φ={u1,u2,…,un}是集合U 的n 个子集,Φ 中所有子集的并集等于集合U 。其目标是使用最少子集ui,使其并集等于U 。
以下证明NFV-SNRA是NP难问题。
证明 给定一个集合覆盖问题实例(U,Φ),构造一个NFV-SNRA问题实例(F,S,C)。对集合U 中的每个元素ej,构造一个虚拟网络功能fj。对Φ 中的每个子集ui,构造一个VNF集合li,表示在CPU核i 上部署集合li中的所有VNFs。集合S 表示CPU 核负载情况,si表示CPU 核i 当前可用资源量。NFV-SNRA 问题的目标是,使用最少CPU 核满足所有VNFs 需求,即使用最少集合li覆盖所有fj。这与集合覆盖问题使用最少子集ui覆盖U 中所有元素ej的目标一致。由此证明,NFV-SNRA是NP难问题。
4.1.3 基于贪心算法的启发式资源分配算法
对于集合覆盖问题,贪心算法能够在多项式时间内得到近似最优解,本节提出一种基于贪心算法的启发式资源分配算法。
假设,某物理节点需部署m 个虚拟网络功能,用集合F 表示。物理节点当前CPU 负载为S0。各虚拟网络功能的最大CPU 占用率为C0。集合L 表示CPU 资源分配方案,初始值为空。集合U 表示未被分配的虚拟网络功能集合,初始值为F。
基于贪心算法,每次选择包含未分配VNFs 最多的集合,直到所有VNFs都得到资源分配。
算法1 VNF-SNRA启发式资源分配算法
输入:虚拟网络功能集F、虚拟网络功能最大CPU 占用率C0、物理节点CPU核负载情况S0。
输出:VNF资源分配方案L。
1. 令集合Φ 为集合F 的所有子集集合。
2. 对于Φ 中的元素uk,若所有CPU核si都无法满足uk中所有VNFs的CPU需求之和,则将uk从Φ 中移除。
3.令U 为未分配的VNFs 集合。初始化U=F。令li∈L,i=1,2,…,n 为空集。
4. while U ≠Ø do
5. 选择元素个数最多的子集u*,依据S0判断是否存在CPU 核能够满足u*中所有VNFs 的需求,若存在一个或多个满足需求的CPU核,选择数值最小的核i*。
6. 令li*=u*,更新
7. 更新集合Φ,删除Φ中所有包含子集u*中元素的子集。
8.更新集合U ,移除子集u*所包含的所有元素。
9.end while
4.2 基于网络负载的VNF实例自动切换方案
由3.2节实验结果可知,网络负载较低时,传统方式在保证VNF性能的同时,消耗CPU资源更少,但随着网络负载升高,传统方式将消耗更多CPU资源,同时会产生可靠性问题,例如频繁丢包;而DPDK 能更加可靠地处理高负载网络,但在网络负载较低时,CPU 有效利用率低。
综上所述,考虑到网络功能流量负载的潮汐现象,提出一种基于网络负载的VNF实例自动切换方案。网络负载较低时,采用基于Linux 内核方式的VNF 实例,以较少CPU资源处理低负载网络。当网络负载超过一定阈值时,使用DPDK方式的VNF实例,高速处理网络包。基于网络负载的VNF实例自动切换方案相关定义如下:(1)Ht={},表示t 时刻虚拟网络功能fj的网络负载。
(2)H*={} ,表示虚拟网络功能fj的实例切换阈值。
切换VNF 实例后,该VNF 对应的CPU 资源需求量随之改变。更新集合C 后,根据算法1 对该节点的VNFs重新进行资源分配。
5 实验与评估
对单物理节点部署多VNFs 进行模拟实验,评估资源分配算法和自动切换方案的效果。基于两台配备有两块Intel®Xeon®E3-1220 v3@3.10 GHz CPU,32 GB内存,一块双端口Intel®82599 10 Gbit网卡和一块四端口Intel®I350 1 Gbit网卡的服务器组成实验平台,进行模拟实验。服务器运行环境为CentOS7,使用KVM 虚拟化技术运行VNF。
5.1 资源分配算法评估
在单节点启发式资源分配算法实验中,以一个物理节点部署6个VNF为例,每个VNF实例分别部署在独立的虚拟机中。每个虚拟机分配4个CPU核,以Passthrough方式访问网卡端口,其中VNF1和VNF2对应万兆网口,VNF3~VNF6 对应千兆网口。以网络包发送速率作为VNF性能测量指标。
实验采用普通部署方法和算法1两种方式进行VNFs部署。对两种不同的部署方法,分别进行10次实验,每次实验持续10 min,记录VNFs实例的网络包发送速率,取10次实验数据的平均值。
实验结果如图6 所示,使用启发式资源分配算法,VNF1的性能提高了30%,VNF2、VNF3和VNF4的性能提高了10%。普通部署方法中,由宿主操作系统决定虚拟CPU与物理CPU的绑定关系,但这种绑定并不固定,在绑定关系发生变化时,会产生上下文切换、cache 失效,从而造成性能损失。VNF5 和VNF6 的性能略有下降,但都不超过3%。需要说明的一点是,凡是完成部署的VNFs 实例,分配给VNFs 实例的CPU 资源总能满足其当前所需。
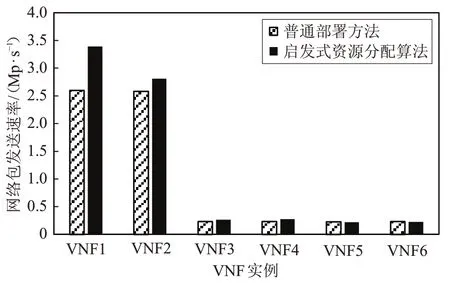
图6 两种部署方案的VNF网络包发送性能
5.2 VNF实例自动切换方案评估
在VNF 实例自动切换方案实验中,发送端使用基于DPDK-16.11.3 实现的发包工具,模拟潮汐规律产生网络流量,发送流量从100~600 kp/s潮汐变化,如图7所示。接收端使用基于libpcap 和DPDK 实现的收包工具模拟VNF 实例,记录虚拟网络功能实例的网络包接收速率、丢包率以及CPU占用率。
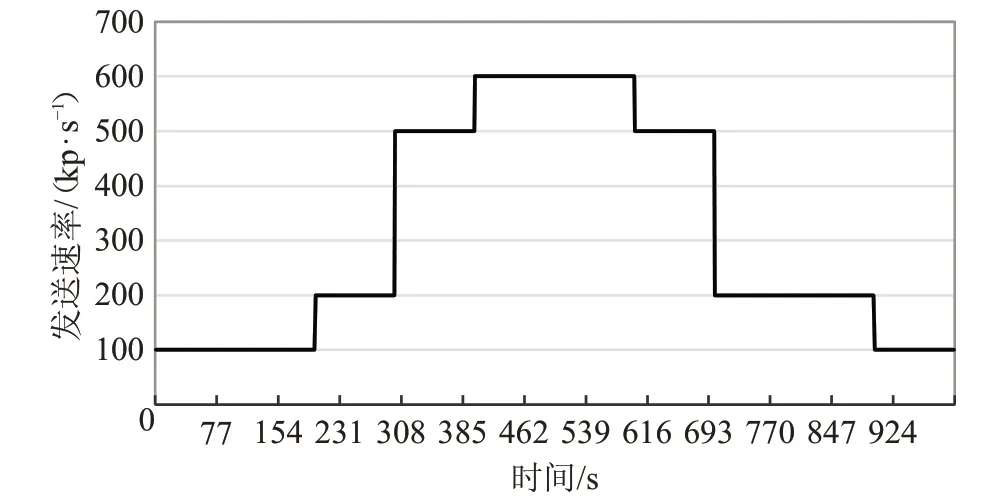
图7 发送端发送潮汐流量
分别进行以下三组实验:
(1)VNF实例全部采用libpcap方式实现;
(2)VNF实例全部采用DPDK方式实现;
(3)VNF实例根据流量负载自动切换。
如表1 所示,数据包长为1 500 B 时,libpcap的最大接收速率为287 656 p/s,仅为10 Gb 链路理论带宽的35.0%;当数据包长为64 B 时,libpcap 的最大接收速率756 550 p/s 仅为10 Gb 链路理论带宽的5.1%。本实验以300 kp/s 作为切换阈值,确保VNF 实例能够处理300 kp/s 以上的高速网络。切换阈值可以根据具体场景、具体目标进行设置。

表1 libpcap网络包接收性能
图8 显示接收端使用libpcap 方式VNF 实例的收包情况,负载为500~600 kp/s区间时,平均丢包率为16.9%;负载为100~200 kp/s区间时,平均丢包率为1.7%。

图8 接收端使用libpcap实现的VNF实例
图9 显示接收端使用DPDK 方式VNF 实例的收包情况,在实验期间均未发生网络包丢失。
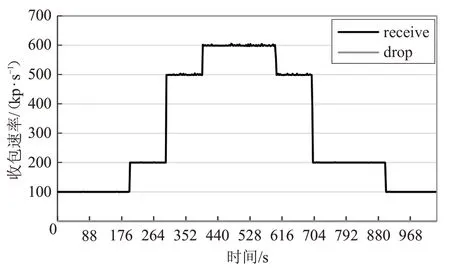
图9 接收端使用DPDK实现的VNF实例
图10 显示接收端基于网络负载自动切换VNF实例的收包情况。实验中,切换阈值设为300 kp/s。网络负载在100~200 kp/s区间时,采用libpcap方式实现的VNF实例;负载在500~600 kp/s 区间时,采用DPDK 方式实现的VNF 实例。实验结果显示,在高负载区间内未发生网络包丢失。
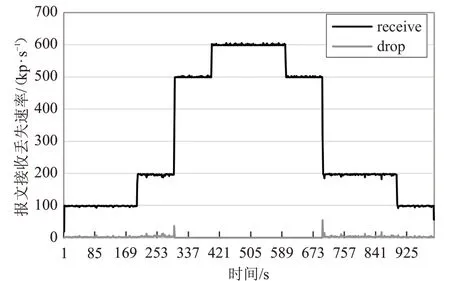
图10 接收端自动切换VNF实例
图11 为三种方式的CPU资源消耗情况。libpcap方式下,CPU 占用率随网络负载线性变化。DPDK 方式下,CPU 占用率始终为100%。自动切换方式下,使用libpcap方式VNF 实例时,CPU 占用率较低,使用DPDK方式VNF实例时,CPU占用率为100%。
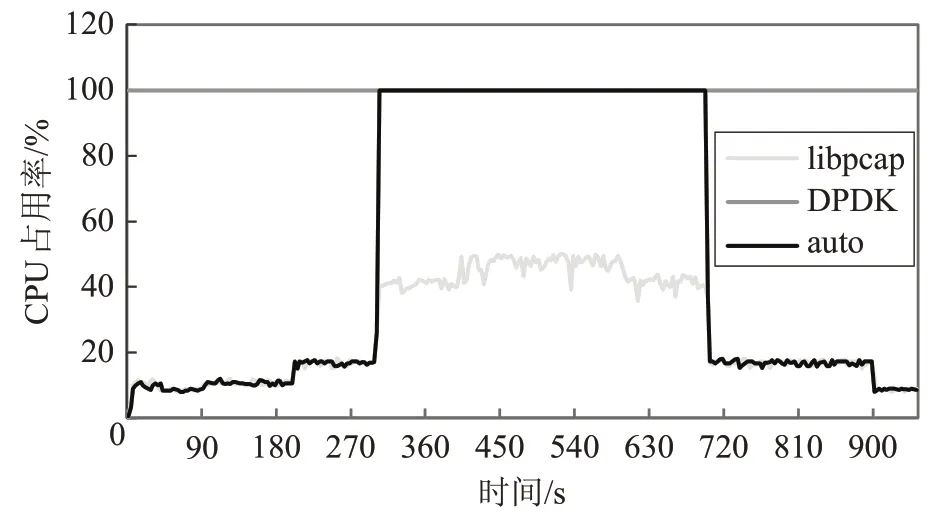
图11 三种方式的CPU占用率
基于上述实验结果,得出以下结论:
(1)网络负载较高时,libpcap方式的VNF实例会消耗更多CPU资源,且伴随频繁丢包现象。
(2)DPDK 方式实现的VNF 实例CPU 占用率始终为100%,在网络负载较低时浪费CPU资源。
(3)自动切换方案在网络负载较低时采用libpcap方式的VNF 实例,以较低CPU 资源消耗处理低负载网络;网络负载较高时,采用DPDK 方式的VNF 实例,以较高CPU资源消耗高效处理高网络负载,相较libpcap,性能提升了20%。
综上所述,本文所提基于网络负载的VNF 实例自动切换方案能够在保证VNF 报文处理性能的同时,降低CPU资源消耗。
6 结语
首先分析了NFV技术在性能和资源分配方面遇到的挑战。然后,通过实验测试了DPDK 对VNF 的加速效果及对CPU 资源的利用情况。实验结果显示,在虚拟环境中使用DPDK,网络包接收速率是传统方法的18倍,网络包发送速率是传统方法的7.7倍。
在此基础上,针对单物理节点部署多VNFs场景,提出了一种基于贪心算法的启发式资源分配算法。实验结果显示,所提算法能够显著提升VNF实例性能,提升10%~30%。
考虑到网络负载的潮汐现象,提出了一种基于网络负载的VNF 实例自动切换方案。实验结果显示,该方案能够在保证VNF 报文处理性能的同时,降低CPU 资源消耗,在高网络负载情况下,VNF性能较普通方式提高了20%。
总的来说,本文以高效利用物理节点CPU 计算资源为优化目标进行方法设计。在未来的工作中,将会引入存储资源、带宽资源等其他资源因素,进行更全面的资源分配研究。
