网页内容链接层次语义树的恶意网页检测方法
2020-06-09陈本刚宋礼鹏
陈本刚,宋礼鹏
中北大学 大数据学院 大数据与网络安全研究所,太原030051
1 引言
攻击者通过网络钓鱼、垃圾邮件投放和恶意下载等方式欺诈用户,这些活动会在用户不知情的情况下访问攻击者提供的网页以达到攻击目的,这些网页被称为恶意网页[1]。为了避免用户访问恶意网页,及时有效地检测出恶意网页非常重要。
Ma J 等人[2]提出了基于URL 特征的大规模在线学习检测恶意网页方法,在平衡数据集上实现高达99%的分类准确度。李梦玉等人[3]提出了基于URL 的高斯混合聚类恶意网页检测方法,达到了较高的准确度。但以上方法都未考虑攻击者利用缩短服务隐藏攻击意图的问题。缩短服务是将长URL 映射为短URL 的服务,访问短链接即可重定向到原始的URL。被缩短后的URL不再具有原始URL 常见的特征,使得基于URL 特征相关特征失效,攻击者利用缩短服务隐藏攻击意图,从而导致仅依赖URL特征的学习方法。
目前存在许多针对恶意网页检测的研究方法,如黑名单[4]和启发式方法[5],随数据规模扩大和时效性要求提升,传统方法面临无法检测出新出现威胁的问题。因此,研究者提出机器学习的检测方法。朴杨鹤然等人[6]提出一种基于stacking 的恶意网页集成检测方法,获得了98.12%的高准确率。但未考虑实际恶意网页检测任务的高度类别不均衡问题,在恶意远小于良性网页数量的不均衡数据集上,简单将所有网页都预测为良性的分类器能达到很高的准确率。简单的优化分类准确率以及仅用准确率作为评价指标不适用于实际的恶意网页检测任务。
为了解决上述问题,本文提出了一种融合网页内容层次语义树特征的成本敏感学习的检测方法,考虑到URL缩短服务导致被缩短后的URL不再具有原始URL特征,通过构建网页内容链接层次语义树,并提取相应特征,这类特征在缩短服务前后具有不可变性,不受URL 缩短服务的影响,解决了利用URL 缩短服务导致检测失效的问题。通过优化两种成本敏感度量的目标函数,并构建成本敏感学习模型,解决恶意网页检测任务中数据类别不均衡问题。实验表明,与现有方法相比在检测性能和效率上都有所提升。
2 恶意网页检测方法
融合网页内容层次语义树特征的成本敏感学习恶意网页检测方法框架如图1 所示。在问题分析模块中给出了恶意网页检测中存在的两类问题:利用缩短服务躲避检测、恶意和良性数据类别不均衡。在解决方案模块中分别从特征工程角度和学习模型角度解决了上述两个问题。
URL缩短服务使得被缩短后的URL不再具有原始URL 常见的特征,导致仅依赖于URL 特征的检测方法失效,攻击者可利用URL 缩短服务的这类特性躲避检测。针对这一问题,从特征工程角度,构建网页内容链接层次语义树并提取相关特征,与网页其他相关特征一并归类为结构、语义和统计特征,确保在URL缩短时部分特征仍然有效。
在学习模型的构建过程中,常规的监督学习方法不适用于数据类别不均衡的恶意网页检测任务。针对这一问题,从学习模型的角度,通过优化两类成本敏感的目标函数,提升恶意网页的误判代价,解决了简单将所有网页判定为良性网页即可获取高准确率的问题。
基于上述相关特征和所构建的成本敏感学习模型组成了融合网页内容层次语义树特征的成本敏感学习恶意网页检测方法。使用带标签数据集训练模型,分别在带标签和不带标签的测试数据上评估了方法的性能。
2.1 恶意网页特征提取
针对缩短服务导致仅基于URL特征的恶意网页检测方法失效的问题,恶意网页特征从URL(如图2)和HTML 源文件中提取相关特征。并对网页内容中的超链接及相应的锚文本进行语义分析,并对网页内容中的超链接及相应的锚文本进行语义分析,构建层次语义树描述网页中的超链接行为。受到相关工作[7]的启发,共提取了513维均属于轻量级静态特征,不依赖于预先计算、先验知识以及特定自然语言,只需从单条原始数据中提取特征向量,摆脱了传统方法需要上下文信息的特征,适用于在线学习检测任务,且不损失检测准确性。
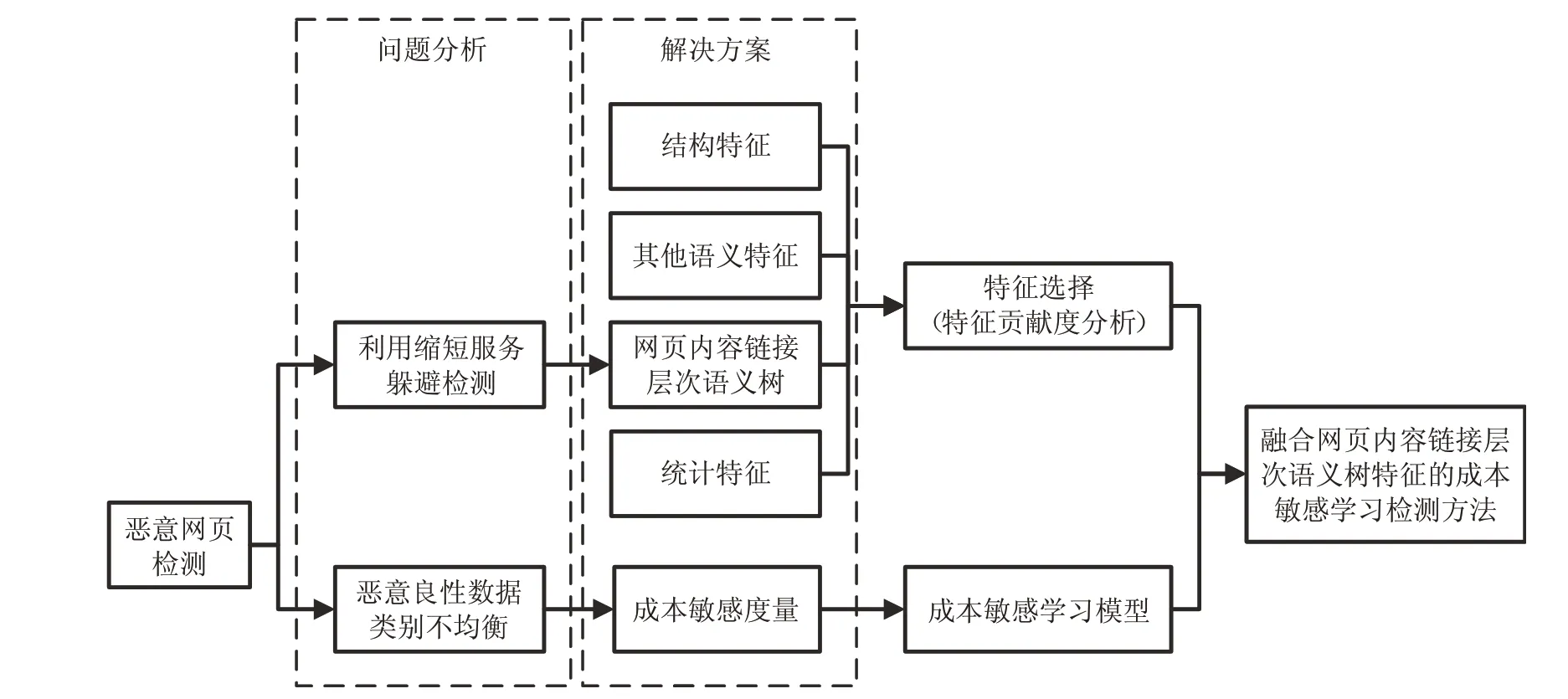
图1 融合网页内容链接层次语义树特征的成本敏感学习检测方法框架

图2 特征提取URL源
便于恶意网页特征的特征选择和贡献度分析,从恶意网页目标、行为表现以及属性的角度,将特征归类为结构特征、语义特征和统计特征,特征值的类型包括离散型(binary)、比值型(rational)、整型(integer)和向量型(vector),并对部分特征的领域知识和相关因素统计分析和描述。从特征贡献度的角度分析这三类特征,并根据贡献度进行特征选择,所提出的特征具有较强的辨识度,其中语义类特征的贡献度相对高于统计特征和结构特征,特征预处理和贡献度分析的具体过程在3.2节中。
2.1.1 结构特征
结构特征侧重于提取原始数据中的结构信息,包含URL、HTML 源文件以及源文件中的JS 片段的结构特征。结构特征中的包含IP地址、查询键值对数、JS最长字符串长为新增加的特征。部分结构特征的列举如表1和领域知识的分析如下。
(#1)URL长度。攻击者使用长URL隐藏地址栏的可疑部分。目前无可靠URL长度阈值区分恶意和良性网页,文献[8]中给出良性长度为75,但未给出证明。为了确保特征的准确性,计算数据集中的良性和恶意的URL 长度的均值。分析得出,若URL 的长度小于或等于54,则被归为良性,若大于74,则URL 被归为恶意。其中URL长度大于等于54的实例有1 220个,占48.8%。
(#2)包含IP 地址。若用IP 地址替代URL 中的域名,例如http://125.98.3.123/fake.html,则几乎可确定该网页试图窃取个人信息。统计数据集显示,570个URL使用IP地址作为域名。
(#3)查询的键值对数。URL 可分解成通用格式如图2,包括协议、域名、路径、query和fragment,其中query由键值对组成。攻击者可能修改任意一个部分以发起攻击。当前特征主要关注恶意修改query部分的攻击的执行情况。
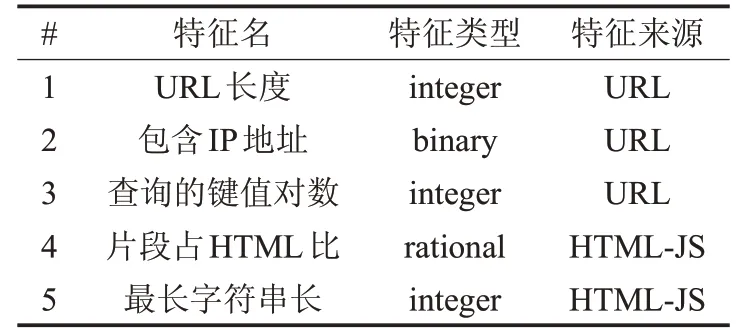
表1 部分结构特征的描述
(#4)JS片段占HTML文件比。JS脚本相对于HTML源文件总体的大小。源文件中JS 脚本越多,实际可见内容越少,执行越多,更易用JS发起攻击。
(#5)JS最长字符串长。恶意JS通常使用混淆隐藏攻击意图。混淆JS 代码通常包含长字符串,它表示编码或者加密,用于像eval 函数的参数。有很长(例如超过350个字符[9])的字符串的脚本更有可能被混淆。图3的混淆代码中包含814个字符,计算最长字符串大小。

图3 混淆的JS代码
2.1.2 语义特征
侧重于从恶意网页领域知识的语义角度提取特征,包括对URL、HTML 源文件以及JS 片段进行语义分析提取的特征。另外,受DOM结构树的启发,对超链接及锚文本进行语义分析,分析链接关系来描述超链接跳转行为。语义特征中的URL使用缩短服务和层次语义树新增加的特征。部分特征的详细描述如表2。

表2 部分语义特征的描述
(#1)使用缩短服务。攻击者通常使用缩短服务隐藏URL 中的攻击意图,长的URL 通过缩短服务映射到短地址,是通过短域名的“HTTP重定向”实现的,该域名链接到长URL 的网页。例如,http://portal.hud.ac.uk/可缩短为bit.ly/19DXSk4,通过特定域名后缀判定。
(#2)使用”-”分割增加域名前后缀。下划线符号很少用于合法网址。网络钓鱼者倾向于将“-”分隔的前缀或后缀添加到域名中,给用户一种合法网页的视觉欺骗。例如http://www.Confirme-paypal.com/。
(#3)URL子域名和多重子域名。假设有以下链接:http://www.nuc.edu.cn/students/。域名可能包括顶级域名,edu.cn称为二级域,“nuc”是实际域名。先从URL中去掉(www.),删除顶级域名(如果存在),计算剩余的点数。若大于1,则URL为可疑,因为有一个子域。但是,如果点大于2,则将其归类为恶意,因为有多个子域。否则,若URL无子域,则为良性。
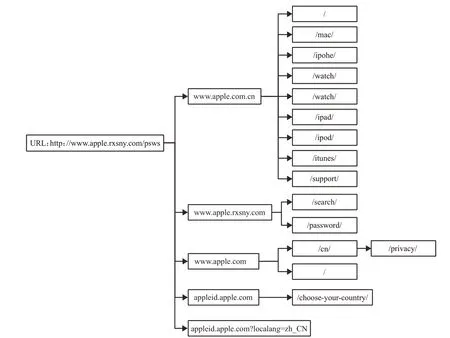
图4 网页链接层次语义树
(#4)网页内容链接的层次语义树特征。对数据集的超链接及其锚文本进行语义分析,发现恶意网页多个链接指向同一外域,对锚文本语义拆分后提取关键词发现同一批字符同时出现的概率高。通过构建网页链接层次语义树,描述网页的超链接的跳转行为:(1)先提取网页中的所有超链接以及相应的锚文本;(2)链接及其锚文本作为语义树的节点,链接如图4的层次结构的语义解析;(3)利用链接的层次结构将多个节点构造成语义树,从语义树提取特征。语义树每节点为一个三元组,定义为集合{URL|(x,y,z)},其中x y z 参数分别表示链接层次字符、链接对应的锚文本、链接频次,例如图4中的/password/节点取值为{URL|(“/password/”,“重设密码”,11)}。以URL 作为根节点,提取语义树的相关特征,例如图4中链接层次语义树的特征向量(树深,树宽,总节点数,叶节点数,子树数,子树深,外域子树数)的取值为(4,15,22,15,6,2,5)。结合这类特征以及网页内容相关特征,可解决缩短服务导致地址栏URL特征失效的问题。
2.1.3 统计特征
侧重于统计分布特征,描述统计分布规律,如URL的域名部分的n-gram 字符频率分布,HTML 源文件和JS片段的信息熵等,其中域名1-gram为新增加的特征,如表3所示。

表3 部分统计特征的描述
(#1)域名1-gram。用N-gram[10]模型对域名提取字符序列特征,N-gram 假设序列中第N 个字符只与其前的N-1 个字符有关,与其他字符无关。1-gram表示每个字符独立,提取域名的字符频率分布。正常域名都会偏向选取可读性好的字母或拼音组合,抽象成数学语言,即为英文的元音字母的比例较高。而恶意网页域名这方面特性不明显。
(#2)HTML 熵值。熵值是信息内容不确定性的指标,被用来分析不同文本的字符分布,一般恶意网页比良性网页具有更小的熵值。
(#3)JS熵值。与HTML-熵值的计算方式类似。混淆代码包含重复字串,所以混淆JS 代码一般具有比正常JS 代码更低的熵值,统计表明混淆JS 代码的熵值小于1.2,而正常JS代码为1.2~2.1。
2.2 成本敏感学习
2.2.1 成本敏感学习方法

图5 成本敏感学习的流程
成本敏感学习的恶意网页检测流程如图5,对训练数据提取第2.1 节中的结构、语义和统计特征,在3.2 节中分析其贡献度并证明有效性。训练成本敏感及其他学习模型,在带标签数据和不带标签测试集中评估各模型的性能,训练好的模型用来检测新出现的网页。该检测方法分别从特征工程和模型构建的角度解决了实际的恶意网页检测任务中出现的缩短服务及数据类别不均衡问题。
实际的恶意网页检测任务中,恶意网页数量远小于良性网页的数据不均衡问题极其严重,使得模型偏向于预测为良性网页或者出现简单将所有网页都预测为良性的分类器能达到很高的准确率的情况。与常见的有监督学习相比,成本敏感学习更适用于实际的恶意网页检测任务。针对恶意网页数据类别不均衡问题设计算法时必须考虑不同类别实例的误报代价,在目标函数的构建过程中,通过优化两个成本度量解决不均衡问题。并引入扩展性好的在线学习,可随网页的到达频繁更新有效应对新出现的威胁;通过主动学习在传入网页的分类置信度低或正确预测存在高度不确定性时才会主动查询标签,节省了大量数据的标注成本。基于成本敏感学习恶意网页检测流程如图5。方法旨在解决两个问题:(1)分类器必须决定何时该查询传入网页实例的标签;(2)如何有效地更新分类器。探索主动学习解决第一个问题,研究成本敏感的在线学习策略解决第二个问题。
2.2.2 成本敏感度量的定义
使用xt∈ℝd表示第t 轮传入网页特征向量,wt∈ℝd是前t-1 训练样本学习得到的模型。使用=sign(wt⋅xt)表示t 轮实例的预测结果, ||wt⋅xt表示预测置信度。 xt相应实例的真实标签为yt∈{ }-1,+1 ,若,则模型误判。
假设网页集合(x1,y1),(x2,y2),…,(xT,yT) 训练恶意网页在线检测模型,其中标签yt的显示取决于该网页是否需要查询标签。训练过程中,常规的监督学习方法优化准确率,对数据集类别不均衡的恶意网页检测任务不适用。因此优化更合适的性能指标,如敏感度(sensitivity)和特异性(specificity)的线性加权,即:

其中,0 ≤ηp,ηn≤1 分别为恶意和良性实例的正确识别的权重参数,且ηp+ηn=1,其中sensitivity 为所有恶意网页中被正确识别的比例,specificity 为所有良性网页中被正确识别的比例。当ηp=ηn=1/2 时,sum 为平衡精度。sum 越大,模型性能越好。另一合适的评价指标为模型错分总代价cost,即:

其中,Mp和Mn分别为正样本和负样本的误判数量,0 ≤cp,cn≤1 分别为恶意和良性实例的误判代价参数,且cp+cn=1。cost 越小,模型性能越好。
2.2.3 成本敏感学习算法
通过优化上述的sum 和cost 两个成本敏感度量[11],构建在线恶意网页检测模型。介绍算法之前,需要证明嵌入成本敏感度量的目标函数。为了解决成本敏感分类问题,优化目标sum 最大化或cost 最小化等价于以下目标函数最小化:

其中,ρ 为成本敏感因子,当ρ=ηpTn/ηnTp时,上述目标函数最小化表示sum最大化。当ρ=cp/cn时,上述目标函数的最小化表示cost 最小化。||(s)为指标函数,满足条件s 时值为1 否则为0,其他变量描述如2.2.2 节。两类成本敏感度量的目标函数的证明过程如下:


其中,Tp和Tn分别为训练集中恶意网页的数量和良性网页的数量,其他变量的描述如2.2.2节,上述需要优化的目标函数为非凸函数,转化为凸优化问题,改进后的hinge损失为:

在线学习原始目标函数如下:
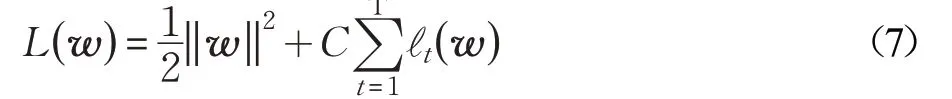


算法中惩罚系数C 和偏差系数ρ 设置为C=ρ=Tn/Tp,sum 优化目标中的正确识别权重参数以及cost优化目标中的误判代价参数设置为ηp=cp=Tn/(Tp+Tn),ηn=cp=Tp/(Tp+Tn),为了保证训练初期需要更多的训练实例,采样因子δ 的初始设置为0.5。算法描述如下:
算法 成本敏感在线主动学习
输入惩罚系数C,偏差系数ρ 和采样因子δ。
初始化w1=0
for t=1,2,…,T do
传入网页实例xt∈ℝd
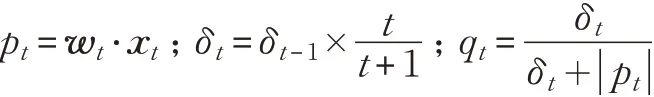
if Zt=1 then
查询标签yt∈{ }
-1,+1
wt+1=wt+τtytxt
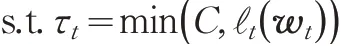
else
wt+1=wt+τtytxts.t.τt=0
end if
end for
3 实验
3.1 实验数据
训练模型所用数据集包含带标签的网页4万条,恶意与良性网页的比例为78.8∶1。测试实际模型泛化能力的数据集包含不带标签网页25万条。数据集中的一部分为2017 网络信息安全对抗赛[14],均为真实的URL及其网页源代码,一部分来自于Phishtank[15]发布的恶意网页黑名单,还有一部分是从Alexa中收集到的良性网页。
3.2 贡献度分析
第2 章中提取的恶意网页检测相关特征共513 维,所有特征均为静态轻量级特征。将这些特征归类为结构、语义和统计三类,做特征选择和贡献度的分析,尤其对新提出的链接层次语义特征贡献度进行分析,特征选择流程如图6。
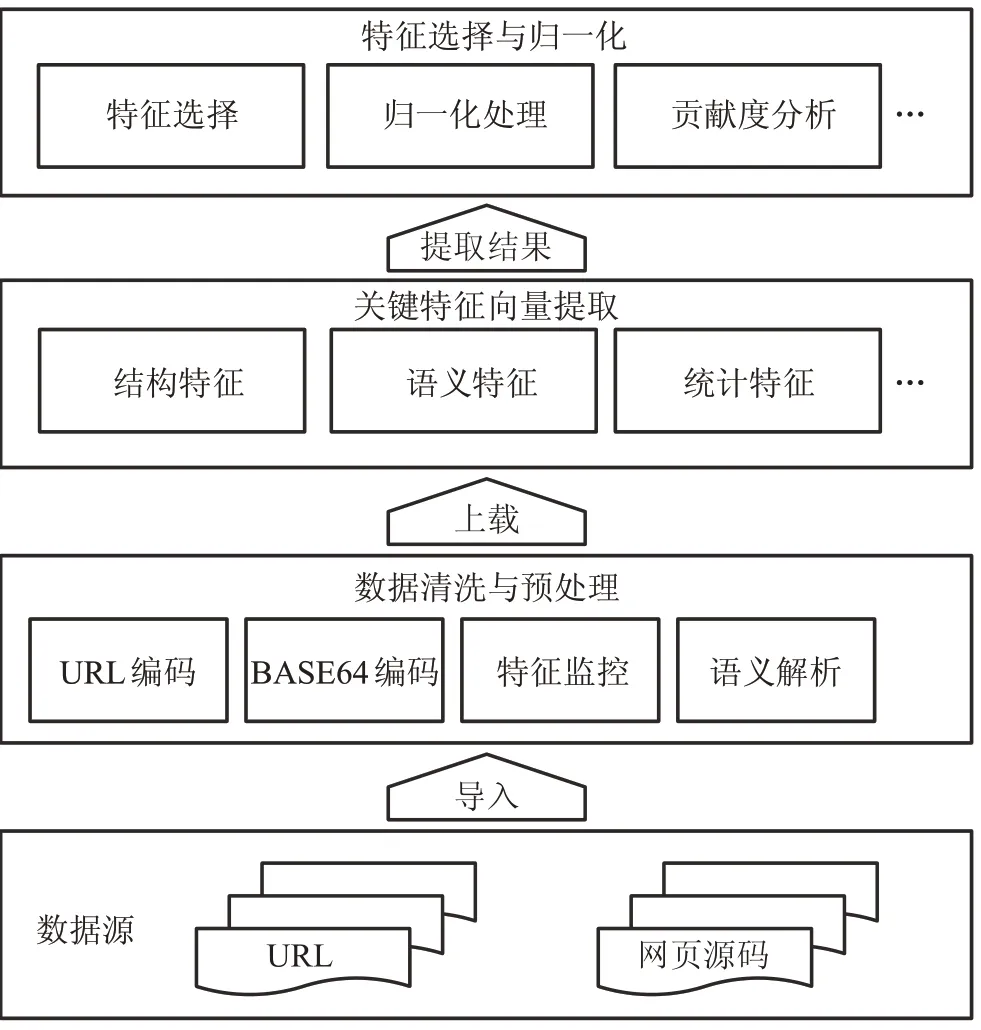
图6 特征处理流程图
使用feature_important[16]对特征选择之后的114 个特征做贡献度分析,计算并平均每个特征的基尼杂质的减少,根据此值排序特征的贡献度。贡献度top20 的特征如表4,分数为每个特征对分类的贡献度。结果显示,新提出的链接层次语义树特征贡献度分数相对较高。语义类特征的贡献度相对高于统计特征和结构特征。
3.3 分类器
测试提取的特征和成本敏感在线主动学习方法在恶意网页检测任务中的有效性,考虑了SVM、RF和XGBoost 算法。使用默认的参数配置这些分类器,详细介绍这些分类器超出本文范围,成本敏感在线主动学习方法也在第2章中详细介绍过,所以仅提供简介如下:
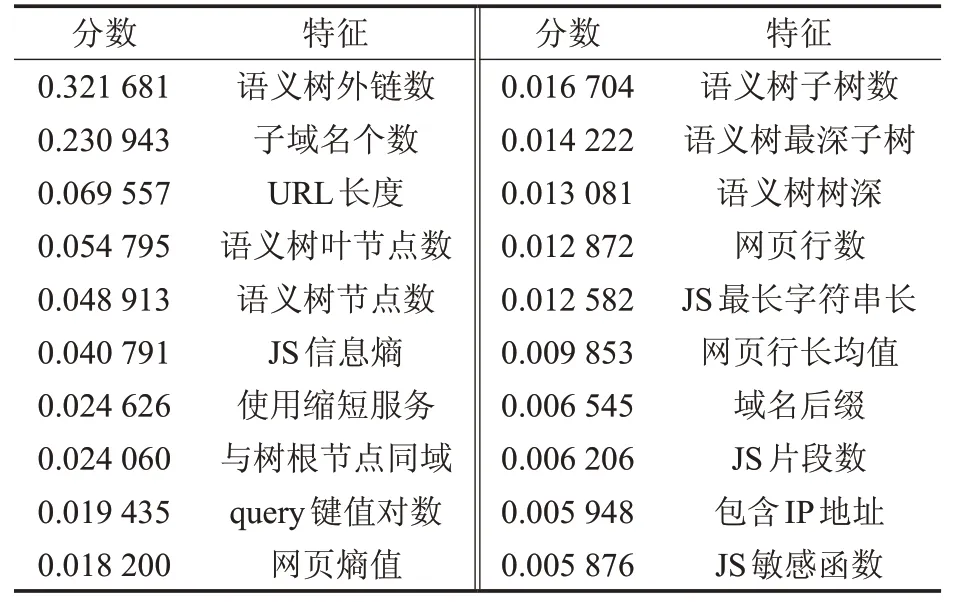
表4 特征贡献度top20
RF:使用多个决策树训练一个非概率分类器,多数投票预测类别。
SVM:训练几何间隔最大化的最优分类超平面,通过核函数解决线性不可分问题。
XGBoost:梯度提升决策树的一种变体,引入正则项防过拟合,对损失函数二阶泰勒展开使目标函数更精确收敛到全局最优。使用可并行近似直方图算法,高效生成候选分割点。
成本敏感在线主动学习:构建优化两类成本敏感度量目标函数。训练过程中,对每个传入的实例采用主动学习判断是否查询标签,然后决定是否用该实例更新模型。不仅适用于类别不均衡数据集,且模型只需一定数量的训练数据即可达到使用所有训练样本的常规监督学习的性能,更适用于解决恶意网页检测任务。
3.4 评估
评估本文方法和现有方法的效率和性能,从训练数据集中提取上述特征向量,训练上述四个分类器。在带标记的数据集中,对各分类器的性能和效率进行了评估。另外,测试模型实际泛化能力,训练好的分类器在25万条无标签数据集中检测恶意网页。
3.4.1 带标签数据集上的评估
评估分类器在带标签测试数据集上分类效率和性能,避免在训练集测试集的随机分区中可能引入错误,采用10折交叉验证策略训练上述分类器。考虑到数据集类别不均衡对准确率的影响,除了accur(准确率),表5中还引入了sens(sensitivity,灵敏度)、spec(specificity,特异性)及query(训练所需数据占训练集的比例)和time(预测耗时)等评价指标,计算公式如下:
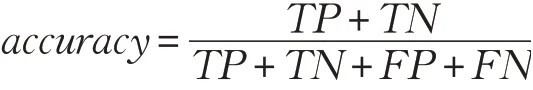
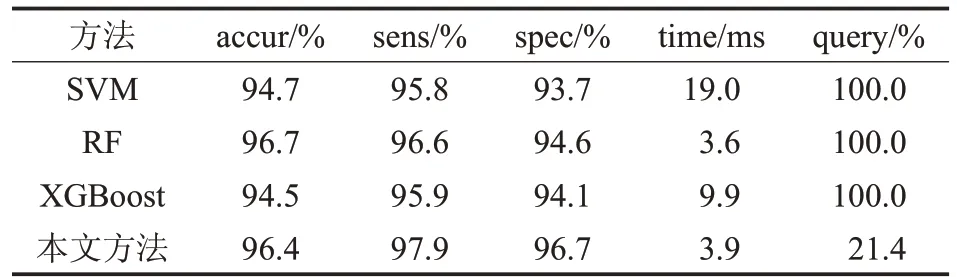
表5 各学习方法的性能对比
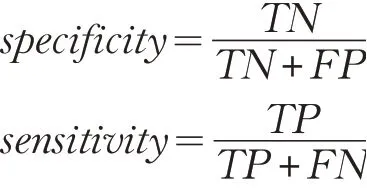
其中TP FP TN FN 分别表示真正、假正、真负、假负网页数。除了time 和query,以上评价指标值越大则分类器性能越好。
各学习方法在带标签数据集表现如表5,使用特征选择后的114 维特征训练分类器。上述各分类器整体分类准确率超过了94%。
成本敏感指标最好的分类器为成本敏感在线主动学习,其灵敏度为97.9%,特异性为96.7%,本文方法在灵敏度和特异性上均优于其他监督学习方法。通过主动学习,仅使用21.4%训练数据的分类器,即可达到较好检测性能,能在保持检测效果的同时节省大量数据标注成本。
为了对比减少训练数据对其他监督学习方法性能的影响,正负样本分层随机选取训练数据中的21.4%,训练SVM、RF 和XGBoost 模型,在带标签的数据集表现如表6,显示减少训练数据会极大地降低其他有监督学习模型的性能。
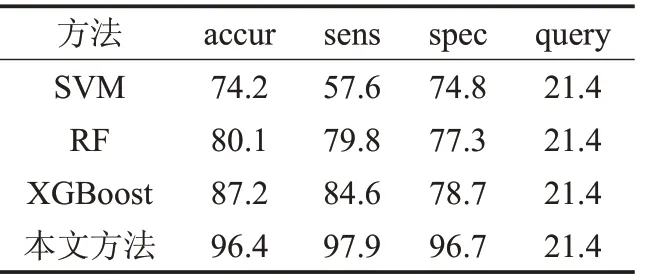
表6 各学习方法的性能对比(随机选取21.4%训练数据) %
3.4.2 无标签数据集上的评估
评估上述分类器从无标签数据集中检测恶意的网页的实际泛化能力,使用主流反病毒工具VirusTotal 和人验证方式做进一步验证。人工验证方法为从攻击者角度进行,先找出该网页的仿制对象,再采用人工对比确认其是否为恶意网页。实验结果如表7 所示,其中malicious 为分类器检测为恶意的网页数,rest 为未被VirusTotal所验证出网页数,manual为rest中被人工验证为恶意网页数,即VirusTotal所漏报的恶意网页。
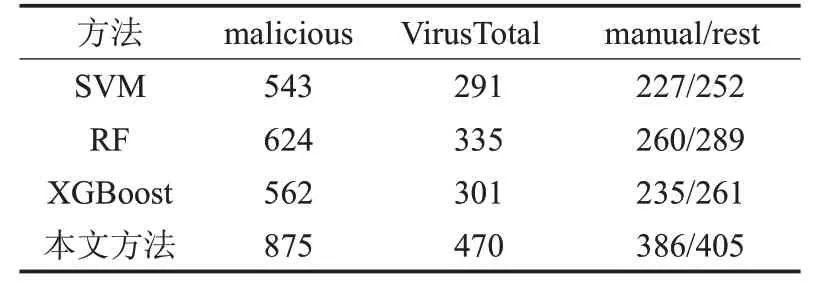
表7 各学习方法在25万条无标签数据集的表现
如表7显示,本文方法从25万条无标签数据中检测出875个恶意网页,VirusTotal仅验证其中470个为恶意网页,人工验证剩余的405 条中的386 为恶意网页。结果显示本文方法优于反病毒工具VirusTotal和常规监督学习方法。
3.4.3 评估集成为恶意检测插件的潜力
目前存在浏览器插件的恶意网页检测方法,为了评估本文方法作为浏览器插件的在线实时检测器的潜力,分析恶意网页检测中每一步的耗时。网页特征向量提取耗时与分类器的预测耗时总和为单个网页的检测时间,表5 中最差的分类器SVM 平均单个网页预测耗时只需要0.006 ms,相比于网页特征向量提取耗时,预测耗时可忽略不计。平均每个网页的特征向量提取耗时78 ms 可作为集成为浏览器插件检测恶意网页的真实时间开销。
4 结束语
本文提出的网页链接层次语义树特征可有效解决URL缩短服务带来的威胁,与常规监督学习方法相比成本敏感在线学习解决了恶意网页检测任务中数据类别不均衡问题。本文方法在恶意网页检测中优于主流的反病毒工具VirusTotal。未来研究中将尝试成本敏感多分类恶意检测方法和基于浏览器插件的恶意网页检测的集成。
