中国各省份产能利用率测度
——基于随机前沿生产函数法的分析
2020-06-09周树伟赵彦萍
周树伟 赵彦萍/文
产能过剩不仅会导致资源浪费、企业恶性竞争、公司生产经营困难甚至破产倒闭,还会大幅度扰乱社会秩序,增加国际贸易摩擦风险。工业、制造业作为支持国家发展的基础性产业,其重要性不言而喻。然而,人们对当前经济表现所知甚少,因此本文将从产能利用率的角度出发,对当前中国各个省份的产能利用情况进行测度,并运用随机前沿生产函数对产能利用率进行估计分析。
一、文献综述
从定义上来讲,产能利用率是指观察到的实际产出y与潜在产出Y的比值,潜在产出是指在给定要素投入、技术水平,且要素被充分利用的情况下,企业/行业所能够达到的最大产出水平。所以,CU=y/Y。在现实社会中,由于企业在生产的时候经常需要考虑市场需求、资源限制、设备磨损等多方面因素,不能实现投入要素的充分利用,所以往往会出现实际产出小于潜在产出,既CU<1。目前国内关于测量产能利用率的研究工作尚处于起步阶段,所采用的方法也主要是借鉴国外的相关研究。国内外学者测算产能利用率的方法大致分为以下几种:
1.峰值法:在20世纪60年代,美国学者Klein就开展了对企业产能利用率的测量,其提出的“峰值法”可谓是开创了经济分析法的先河。Klein将产能定义为企业在一段时间内所达到的产出水平的峰值,即在一个经济周期中企业实际产出的最大值作为潜在产出。峰值法的最大缺陷在于我们无法确定企业在产出峰值是否实现了产能的完全利用。
2.函数法:由于峰值法限制较多,后续学者开始从产出的微观经济定义出发对产能利用率进行研究。根据现有要素的投入情况,构建相应的生产函数、成本函数或者利润函数,将产能定义为企业利润最大化或者成本最小化情况下的产出水平,将实际产出水平与计算得到的最佳产出水平的比值作为衡量产能利用率的标准。相对而言,函数法以微观经济基础作为理论支撑,但是对函数形式设定要求严格,一旦函数形式设定错误,所测算的产能利用率可信度也随之降低。
3.协整法:Shaikh and Moudud(2004)认为产出受到企业固定资本存量的影响,两者之间具有稳定的长期关系,所以提出了协整法测量产能利用率。相对而言,协整法能够避免函数设定的主观误差,但是忽略了一定的微观经济基础。
4.数据包络(DEA)和随机前沿分析法(SFA):都是对观察到的投入产出数据构建生产前沿面,估计出偏离生产前沿面的无效率部分。Banker(1984)采用DEA模型研究多投入多产出最优产出与收益之间的关系。Mastromarco和Ghosh(2009)应用SFA研究发展中国家全要素生产率的影响因素,研究结论表明:FDI、机械设备进口费用以及研究与开发进口费用(R&D)是影响发展中国家全要素生产率的主要因素。
二、理论框架与实证模型
SFA模型始于对生产最优化的研究,最早是由比利时学者Meeusen&Broeck(1977)以及美国学者 Aigner(1977)分别独立提出的,其核心思想在于企业未能达到生产前沿面的无效率是由随机误差和技术无效率两个因素影响的。SFA模型一般形式如下:

其中,y代表第i个企业在时期t的产出,x代表第i个企业在时期 t的投入,β 代表 x 的参数向量,v—N(0,σ2),是独立同分布的随机误差,表示任何不可控因素的扰动。u是非负随机变量,代表企业的技术无效率。若企业的生产状况完全有效率,即代表企业生产状况的点落在生产前沿面上,则u=0,否则,u>0。如果简单地以柯布道格拉斯生产函数的对数形式将模型表示出来,可以写为:
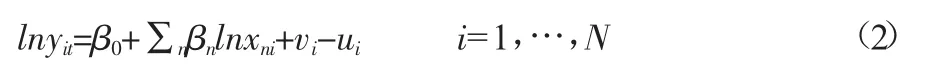
上述模型都假定技术效率不具有时变性,越来越多的学者认为该模型的假定不符合实际情况。Battese和Coelli(1992)提出SFA可以选用服从截尾正态分布的面板数据模型,且技术效率随着时间的变化而变化。模型具体形式如下:

其中,yit代表第i个企业在时期t的产出,xit代表第i个企业在时期t的投入,β为投入的参数向量,vit为随机误差项,服从独立同分布,既 vit—N(0,σ2v),uit=exp(-η(t-T))ui,假设 uit是时变的,其中ui为非负变量,代表技术无效率项的截断分布,满足uit—N(μ,σ2u),η为需要估计的参数。与常用的柯布——道格拉斯生产函数相比,避免了因为函数形式设定失误所造成的误差。因此本文选取超越对数生产函数对产能利用率进行分析,模型如下所示:

其中,Yit为产出指标,Kit为资本投入指标,Lit为劳动力要素投入指标,T是时间趋势;vit是随机变量,服从均值为零的正态分布。uit是非效率项,服从独立零处截尾的正态分布 N(mit,σ2u)。
三、基于随机前沿分析法的实证研究
(一)变量与数据说明
学者们在生产函数投入指标上一贯的选择是劳动和资本,而且通常都用员工数量表示劳动力投入,用固定资产投资表示资本投入。产出指标一般选取产值。综上,结合本文的研究目的、学者们的历史研究以及数据的可获得性,本文选择的总产出为中国2008—2017年规模以上企业的总产值。选取各地规模以上企业年度固定资产投资作为资本投入,选择各地规模以上企业全部从业人员平均人数作为劳动力投入。样本数据来自2008—2017年各年的《中国工业经济统计年鉴》。
(二)超越对数生产函数随机前沿模型估计
根据式(4),计算得出了2008—2017年中国各个省份的产能利用率,如附表所示。

附表 2008—2017中国各地区产能利用率
由附表可以发现:(1)大多数地区的产能利用率都呈现平稳上升的情况,说明整体工业经济形势向好。(2)从地域分布上看,东部地区的产能利用率水平高于其他地区,但是变化幅度略低于其他地区,这与东部地区存在大规模的制造业企业有关。(3)按照国际产能过剩分类标准,产能利用率低于79%即可认为存在产能过剩。可以看出中国各省份除了江苏、山东、广东之外,其余大部分省份都存在较强的产能过剩风险,主要集中在中部和西部地区。
四、研究结论与展望
从产能利用率指标来看,中国大部分地区的产能利用率基本都低于79%水平线,即中国大部分地区存在产能过剩,部分地区存在较为严重的产能过剩。其中东部地区的整体水平略高于中、西部地区,东部地区的变化幅度略低于中、西部地区。
本文虽然从产能利用率的角度对中国工业产能过剩的情况进行研究探索,但未能结合其他测算方法联合分析,只采用一种方法难以印证结果的准确性,而且未能深入探究造成工业产能过剩的影响因素,这将是今后进一步深入研究的主要方向。
