利用Logistic 回归和神经网络分析乳腺癌的预后因素*
2020-06-09章鸣嬛
章鸣嬛 陈 瑛 郭 欣 张 璇 季 萌
(上海杉达学院大数据分析与处理研究中心 上海 201209)
1 引言
乳腺癌是女性最常见的恶性肿瘤,其死亡率高居女性癌症的第二位。据2018 年统计数据显示,全球每年有超过50万妇女死于乳腺癌,超过120万妇女罹患乳腺癌[1]。因此,对于乳腺癌的预后判断十分重要。基于大量高质量的、可信度较高的乳腺癌数据对于设计患者的预后评价模型显得非常必要。
美国国立癌症研究所“监测、流行病学和结果”数据库(Surveillance,Epidemiology and End Results,SEER)是北美最具代表性的大型肿瘤登记注册数据库之一,为临床医师的循证实践及临床医学研究提供了系统的证据支持和宝贵的第一手资料[3]。
近年来,国内外有很多学者利用机器学习方法对 SEER 数据进行挖掘分析。Kim 等[8~9]分别应用支持向量机和朴素贝叶斯方法来分析乳腺癌患者术后的情况。刘雅琴[10]利用三种机器学习算法,对SEER数据库中的乳腺癌数据进行预后分析。尹玢璨等[11]利用贝叶斯网络构建并分析亚洲肿瘤患者预后的模型。牟冬梅等[12]通过提取电子病历信息来构建妊娠高血压综合征危险因素预测模型,建立了优化的决策树模型。
Logistic 回归(Logistic Regression,LR)和神经网络(Artificial Neural Network,ANN)是两种常用的机器学习方法,在包括医学辅助检测在内的诸多领域具有广泛的应用[13~18]。本文基于 SEER 数据库1990~2014 年间乳腺癌患者的有效数据,分别利用logistic回归和神经网络算法建模分析,找出对乳腺癌预后影响最大的若干因素,为临床医师开展乳腺癌的治疗和预后判断提供理论依据。
2 数据采集及预处理
2.1 数据采集
本研究以SEER 中1990~2014年间乳腺癌患者的数据记录作为研究对象。原始数据中每条记录共有133字段。由于SEER 中的字段设计是面向多种肿瘤的,很多字段与乳腺癌没有直接关联,故在乳腺外科医生的指导下,选取了12 个与本课题相关的字段。如表1所示。

表1 输入字段
肿瘤患者5 年生存情况是评价预后效果的重要指标[11]。以乳腺癌患者手术后5 年的生存情况作为输出变量。此为二分类变量,1 为尚存活,0 为死于乳腺癌。
2.2 数据预处理
预处理是使得数据尽量满足模型输入要求的过程。在满足要求的前提下,应尽可能简化数据形式,以降低建模的复杂度。[19]。
“肿瘤分期”(Stage)为分类型变量,主要有I、II、III、IV 四大类,其严重程度依次增加。除上述四大类之外,Stage 的取值还涉及到某些大类中的细项。如II 型又可细分为IIA 和II B,III 又可细分为IIIA、III B、III C 和 IIINOS 等。为降低建模复杂程度,只保留 I、II、III、IV 四大类,而对其余细项加以合并。“年龄”为连续型数值变量,为降低分析难度和复杂度,以5 年为一个区间,将年龄数据划分为18个区域。
预初实验显示,数据预处理后共保留样本445 575 条,其中术后5 年生存情况为存活的样本有407 114条,死亡样本有38 461条,样本数量之比为10.6∶1,两类样本极不平衡。若不处理该问题就直接分析,则试验结果不具有合理性。多次试验后确定采用三种重抽样方式,即,过抽样、欠抽样,及综合过抽样和欠抽样技术,以保证两类样本的数量基本均衡。
2.3 建模方法
本试验采用Logistic 回归和神经网络两种建模方法。
具有P 个自变量的Logistic 回归模型如式(1)所示:
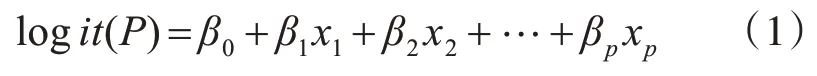
从形式上看,当Logistic 回归方程与一般线性回归方程的形式相同,可用类似的方法解释方程中系数的含义[20]。即,当其他解释变量保持不变时,解释变量xi每增加一个单位,将引起logi(tP)平均增加(或减少)βi个单位。本试验中的因变量是患者术后5 年的生存状态,为二分类变量,故采用二项logistic回归分析。
人工神经网络是(ANN)一种模拟人脑思维的计算机建模算法。结构上可划分为输入层、隐含层和输出层。隐含层的层数和每层节点数决定了ANN 的复杂程度。本研究需对患者术后5 年的生存状态进行二分类判定,这就要确定一个超平面,位于超平面上部的所有样本点属于一种情况,位于下部的属于另一种情况。超平面可由式(2)确定。
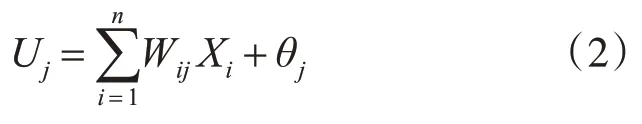
式中,n 表示上层节点的个数,Xi为上层第i 个节点的输出,Wij为上层第i 个节点与本层第j 个节点的连接权值,qj为线性组合中的常数项。其中网络权值Wij最为关键。最初,神经网络的所有权重均随机生成,因此该网络的输出结果可能无意义。网络通过不断地向训练样本学习来改变网络权值,使超平面不断地向正确方向移动,最终得到期望的输出结果[21]。本试验采用多层感知器神经网络进行建模分析,设置单隐层,以双曲正切函数作为激活函数。
就输入变量的形式来看,Logistic 回归和神经网络要求输入变量为数值型。因此,需考虑如何处理分类型变量:对于二分类变量,可转换为取值为0/1的数值型变量;对于多分类变量,应将其转换成哑变量。
3 结果
分析12 个输入与输出变量的相关性可知,除了婚姻状态和组织学形态与输出的相关性不太明显(P>0.05),其余10 个输入变量均与输出之间有较高的相关性(P<0.05)。因此,首先将全部输入变量全部纳入建模过程,分别使用Logistic 回归和神经网络算法建立模型,考察在所有变量的交互作用下,输入是如何影响乳腺癌的预后情况的。
3.1 样本组织方法和模型评价指标
分别采用过抽样、欠抽样,以及联合使用以上两种方法,设置合适的抽样比例,保证两类样本数基本平衡。抽样技术仅针对训练样本,对于测试样本则不使用该技术。样本的组织方式均采用十折交叉验证[22],采用灵敏度(Sensitivity)、特异度(Specificity)及分类准确率(Accuracy)来衡量实验判定所有受试者被正确分类的能力。以TP代表真阳性,FP代表假阳性,TN代表真阴性,FN代表假阴性,则有:Sensitivity=TP(/TP+FN);Specificity=TN/(TN+FP);Accuracy=(TP+TN)(/TP+FN+ TN+FP)。这三个指标的取值均在[0,1]之间,取值越接近1则效果越好[23]。受试者工作特征(ROC)是基于灵敏度和特异度引出的一种直观的评价方式。ROC以 Sensitivity 为纵坐标,以(1- Specificity)为横坐标,其曲线下面积(AUC)的取值大于0.7 时诊断价值较高。AUC越大则效果越好[24]。
试验流程如图1。
3.2 三种重抽样技术下的试验结果
1)过抽样
存活样本数为407 114,死亡样本数为407 659(过抽样比为1006%),总计814 773 条记录。分别利用Logistic回归和神经网络两种算法进行建模分析后,得到测试集上的灵敏度(Sensitivity)、特异度(Specificity)、准确率(Accuracy)以及ROC下曲线面积(AUC)如表2所示。
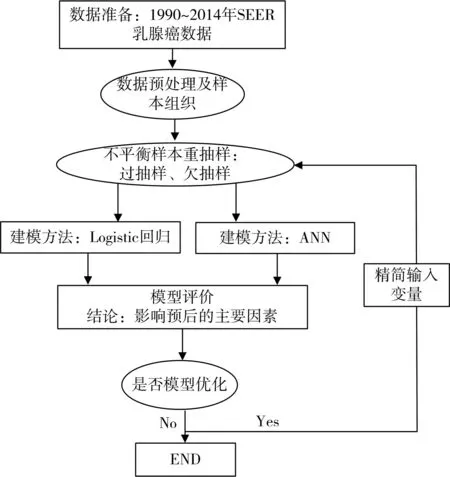
图1 试验设计流程

表2 过抽样技术下两种模型的性能比较
2)欠抽样
存活样本数为38 461(欠抽样比为9.6%),死亡样本数为38 828,总计77 289 条记录。分别利用Logistic 回归和神经网络两种算法进行建模分析后,得到测试集上的性能指标如表3所示。
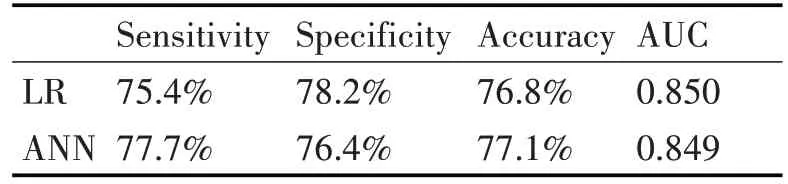
表3 欠抽样技术下两种模型的性能比较
3)过抽样与欠抽样相结合
存活样本数为203 879(欠抽样比为50%),死亡样本数为203 541(过抽样比为530%),总计407 420 条记录。分别利用Logistic 回归和神经网络两种算法进行建模分析,得到测试集上的性能指标如表4所示。
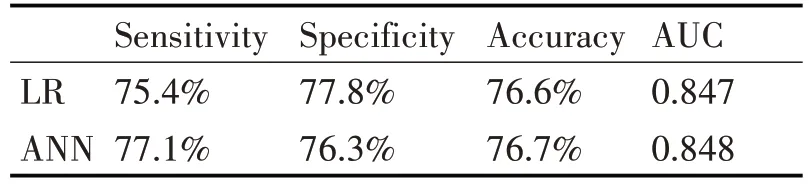
表4 “过&欠”抽样技术下两种模型的性能比较
该抽样技术下,基于Logistic 回归模型的乳腺癌生存预测最优模型的部分结果见表5。以肿瘤分级Grade和肿瘤分期Stage为例,二者均为多分类型变量(分类数为4),需转换成哑变量处理。其中B为回归系数,S.E.为回归系数的标准误差,Wald为Wald 统计量,df 为自由度,Sig 为显著性水平。Exp(B)为一元优势比估计值,可用于近似判断不同组的相对“风险”。
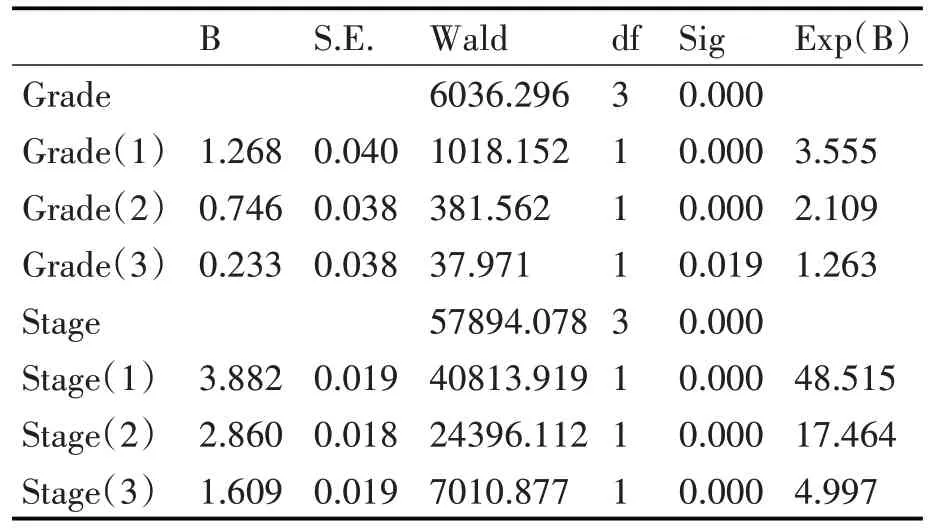
表5 Logistic回归模型的生存预测部分结果(过抽样+欠抽样)
经比较三种抽样技术下Logistic 回归和神经网络的算法评价指标可知,模型的灵敏度、特异度及准确率均在75.4%~78.2%之间,AUC 均在0.847~0.850之间,模型具有较好的性能。
分析三种重抽样技术下的建模过程可发现,在12 个输入变量中,对于模型影响最大的变量均为肿瘤分期、肿瘤分级、肿瘤尺寸、雌激素水平、孕激素水平、年龄分组。
模型显示,在其他输入变量保持不变的前提下,肿瘤的四种分期(Stage:I、II、III、IV)严重程度依次递增。IV期是I期严重程度的48.5~51.3倍,III期是 I 期严重程度的 17.4~18.6 倍,II 期是 I 期严重程度的4.9~5.2倍。从某种意义上反应了肿瘤不同分期的量化程度。
在其它输入变量保持不变的前提下,肿瘤的四种分级(Grade:I、II、III、IV)严重程度依次递增。IV期是 I 期严重程度的 3.4~3.6 倍,III 期是 I 期严重程度的 2.0~2.2 倍,II 期是 I 期严重程度的 1.2~1.3倍。从某种意义上反应了肿瘤不同分级的量化程度。
4 讨论
重抽样过程中,分别采用了过抽样、欠抽样以及两者结合抽样的方式。试验设置了一系列抽样比例,存活样本与死亡样本的比例为5∶1~1∶1。结果证明,当抽样比例使得正负两类样本数量趋于平衡时,模型的性能最佳。
由前文结论可知,在12 个输入变量中,对模型影响最大的变量为:肿瘤分期、肿瘤分级、肿瘤尺寸、雌激素水平、年龄分组和孕激素水平。为降低模型的复杂程度,只选用这6 个变量作为建模输入,且三种抽样比例仍保持不变。建模后的性能评价如表5。
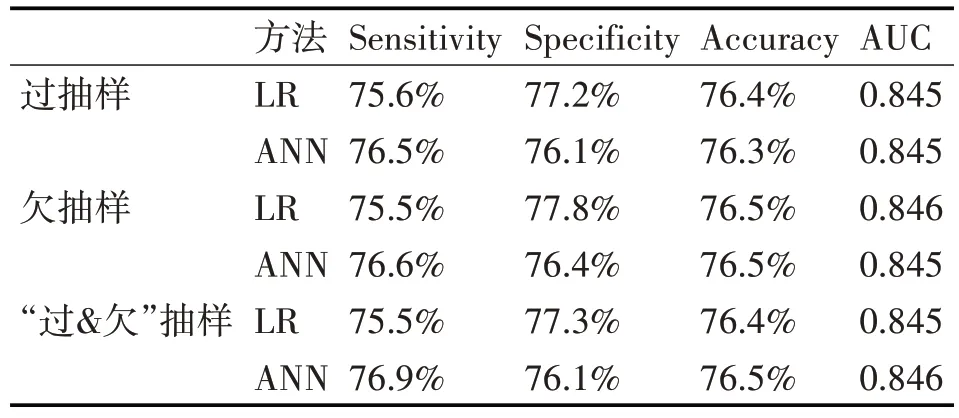
表5 精简输入变量后的模型性能
由表5 可看出,精简变量前后,模型的灵敏度、特异度及准确率分别介于75.4%~78.2%和75.5%~77.8%,二者差异不大。同时,精简前后的模型AUC 分别介于 0.847~0.850 和 0.845~0.846,也几乎无显著性差异。故可得出结论:模型分析所得的这6 个变量,是影响乳腺癌5 年预后最显著的因素。该结论也符合临床医生的认知。
此外,试验还利用CRT 决策树进行了建模分析,得出了近似的结论。决策树方法筛选出对乳腺癌患者预后影响最大的因子分别是:肿瘤分期、肿瘤分级、肿瘤尺寸、雌激素水平、年龄分组和孕激素水平。可知,除了年龄分组和孕激素排序的位序略有差异,基于决策树方法的建模结论与本文结论完全一致。
5 结语
选用SEER 数据库中1990~2014年的乳腺癌数据,以术后5 年的存活状态为观察点,分别利用logistic 回归和神经网络构建模型,以寻求对于对于乳腺癌预后影响最大的因素。研究结果表明:模型在测试集上的灵敏度、特异度及准确率介于75.4%~78.2%之间,AUC均介于0.847~0.850之间,且试验结论与临床诊断经验相吻合。本研究可为乳腺癌治疗及预后评价提供理论依据,对于临床诊断具有一定的辅助作用。
