基于时空聚类的职住分析研究*
2020-06-09肖跃雷
韩 卓 肖跃雷
(西安邮电大学物联网与两化融合研究院 西安 710061)
1 引言
随着科技的不断进步,人类的历史移动数据以GPS定位、签到位置信息及交通卡等形式得以持久化保存,经过数据的不断存留,从而形成了时空轨迹数据。通过具有时间、采样位置、运动速度等属性信息的采样点组成时空轨迹[1]。时空轨迹信息通过不断成熟的数据挖掘技术,如聚类、关联规则挖掘、分类等[2],处理得到一些有价值的信息并应用于旅游、交通、能源等领域。
时空数据挖掘是数据挖掘领域中一个重要的研究范畴,通过一些系列的轨迹点,进行时空数据挖掘,可以得到相关的职住空间分布、兴趣区域分布及出行特性分布等有用信息。而职住分析对旅游景点推荐、城市交通设施建设、城市产业规划布局等有着重要参考作用,对建设智慧城市有着深刻影响[3]。传统的聚类只分析处理在地理空间上的数据,为更好挖掘时空信息的地理空间数据、满足研究要求,故采用时空聚类[4]。目前时空聚类的方法主要有空间聚类和时空耦合聚类,空间聚类的方法忽视了时空观测值在时间维度上的动态性因而其捕捉时空动态的能力不足,故时空耦合的方法更加适合研究[5]。邓敏等[6]基于时空数据的基本特征构建时空邻域进而采用了密度聚类的方法。童晓君等[7]通过凝聚式层次聚类算法,基于乘客出行的空间特征,识别出乘客出行的空间热点区域及其时段特征。
近年来,居民出行特征、职住空间平衡及通勤行为研究等方面都有不错的研究进展。杨超等[8]提出了基于最小通勤理论的最优增长分布模型,用于职住平衡程度与通勤交通效率的研究。郑思齐等[9]提出了一种说明居住与就业实质性匹配的“职住平衡指数”,分析了造成职住空间差异的影响因子和作用机制。从目前的研究看来,职住地分析定位方面仍研究不足,现有研究仍偏向传统社会调查。这些方式不仅耗费人力物力财力且实时性较差。科学性的分析定位居民职住地显得尤为重要。许宁等[10]提出了一种基于短期规则采样的大量手机定位数据的居民职住地识别方法,通过规整的手机定位数据及相应的用地性质识别出职住地。ZangH 等[11]依据手机用户在自定义的职住时间段内分别产生的业务频繁程度来确定职住地。IsaacmanS 等[12]基于手机通话定位,通过空间聚类识别用户的重要活动地点,进而时间分析确定职住地。唐小勇等[13]提出一种职住计算框架,识别用户在一天内的多日稳定点和综合工作日与节假日稳定点,基于此来判断用户的职住地。赖见辉等[14]通过利用信令数据中职住地的各种通信特征建立隶属度函数,基于权重思想提出一种改进的识别方法。
综上所述,对于识别职住地的研究,有的识别方法不能很好适应数据集大小,有的结果验证比较薄弱。为了在不同数据量的情况下,职住地的识别结果更为可靠,本文利用采集到的基站信令数据,对轨迹点进行基于K-Means的时空聚类,聚类结果能够对职住地准确定位,此外也能够划分区域内常驻与非常驻人口,经过大量真实数据验证对比本文的模型有更好识别效果,且更够投入正常使用。
2 基于K-Means的时空聚类
对于轨迹点的聚类,通常有基于密度的聚类、基于网格聚类以及基于模型的聚类等方法[15]。由于基于划分的聚类方法的实现复杂度较低,故而被主要应用于大规模数据聚类。这里采用的是基于划分方法的K-Means 聚类。它是一种基于距离的非层次聚类算法。在最小化误差函数的基础上,将数据分为K 个集合,以距离作为相似度的评价指标,即认为两个对象的距离越近,其相似度越大[16]。算法过程描述如下:
1)随机选取K 个点作为初步迭代的聚类质心点a1,a2,…aK。
2)计算其余样本点到K 个聚类点的距离,选择距离质心aj最近的类别j,更新质心aj为该类全部样本的平均值,并标记。
3)属于同一类的点进行取质心运算,计算新的簇质心点。
4)重复步骤2)、3)直到簇质心点不再发生变化。
2.1 目标函数
目标函数又称为失真代价函数。当目标函数达到最优或者达到最大的迭代次数时算法结束。对于样本集D={x1,x2,…,xm} ,K-Means 针对聚类划分为C={C1,C2,…,CK},最小化平方误差:
其中,ui是簇Ci的均值向量(质心),表达式为。
从上述公式中可以看出,簇内样本围绕簇均值向量的紧密程度,最小化平方误差E 值越小簇内样本的相似度越高[17]。
2.2 距离量度
不同的距离量度下的聚类结果不尽相同。像欧几里得距离度量会受不同单位刻度的影响,因此一般需要先进行标准化。余弦相似度倾向给出更优解。常用的距离度量表达式如下所示:
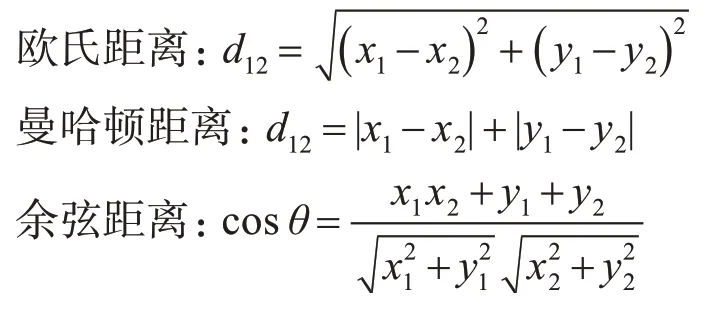
用户的信令数据包含信令产生时间及产生信令所处地理经纬度坐标。通过用户的经纬度数据可得到用户活动范围及常驻点信息。由于是地理位置聚类,坐标采用的是国际地心坐标系WGS-84,因此此次研究选取的距离度量是经纬度计算的球面距离。球面距离公式:

其中,A,B是球面的坐标;点A:经度α1、纬度β1;点B:经度α2、纬度β2;R是地球半径(约6371km)。
2.3 K值的确定
K-Means 通常需要迭代十几次甚至上百次。每次迭代时,随机地从不同位置开始初始化,最终初始化位置就是最小的代价函数对应的重心位置。据目前研究,K值的选择有以下方法:
1)K个初始点是随机地在训练数据中抽取选定。
2)当K值确定,迭代n次,最终的聚类结果是最小代价函数值的K,从而避免随机造成的局部最优。
3)手肘法则选取K 值:绘制出K-代价函数闪点图,有明显拐点所对应的数值,设为K 值,并把对应不同值的代价函数值画出来。平均畸变程度随着代价函数的增大而减小;每类包含的样本数慢慢减少,样本离会更接近其簇质心。平均畸变程度的聚类效果因代价函数值增大而减弱。在值增加过程中,畸变程度下降幅度最大时所对应的值即为肘部位置。
4)K 值有时需要针对不同的应用场景选取,而不能完全地依靠评估参数来决定[18]。
此次研究采用第二种方法,即手肘法则来确定K 值。由于每个用户的信令数据不一,或多或少,因此每个用户K 的取值是不同的。正常情况下用户一个月的信令数在400 条左右,在信令数较少的情况下大概在几十条左右。数据较少不足以分成太多簇,对聚类中心点也会有所影响。手肘法则能够准确选取K 值且不受信令总数极值(极大或者极小)的影响。在信令总数处于几条或几万条这种极值情况下仍能选取合适的K 值,达到更好的聚类效果。
2.4 时间特性标签
据调查,近年来居民出行的早晚高峰集中在7至8 点及17 至18 点,依据居民白天工作、晚上休息的一般作息时间规律,结合信令数据,时间阈值可以选定为白天时段(9:00~18:00)和夜间时段(20:00~8:00),其余时间定为闲时时段。鉴于用户在上班路上或下班途中也有可能产生通话短信业务,且有交通、通勤的因素影响,上下班的路途时间可能有延长,故除白天和夜间时段外需划分出另一时间段。为白天、夜间和闲时时段分别给出0、1、2的时间特性标签。每个轨迹点都有对应的进入时间,根据该点进入时间所在的时间段来判定该点类属的时间标签。白天时段的常驻点可能为工作地,夜间的常驻点可能为居住地,闲时时段的常驻点可能为非事务性常驻地。本文仅研究正常上班制,不考虑夜班等特殊情况。
2.5 基于时空聚类
用户信令中的每个轨迹点,表示着曾在该点逗留,在一段时间内轨迹点的频次大小预示着该点是否是用户的常驻点。频次高,说明用户在此轨迹点曾多次出现,可视为用户的常驻点之一。频次低,说明用户可能在此轨迹点偶然经过。由于K-Means 算法在迭代过程中使用所有样本点的均值作为新的质心,如果簇内存在异常点,将会导致质心点偏离。用户偶然经过或是非频繁性去往某地所留下的轨迹点又称离群点,这些点会影响到质心点的最终位置,故在聚类中加入频次维度,保证聚类过程中尽量避免离群点的影响,使得聚类结果更加逼近实际常驻点。加入频次维度后,在信令数据预处理中不需删减剔除离群点。时间段是用户在轨迹点出现时的时间,白天、夜间或者闲时。频次和时间段有利于对常驻点性质的判断,具体分清职驻地。
对于居住地的判定:通过连续多天的信令数据,根据手机用户在居住时段逗留的轨迹点及在此轨迹点出现的次数,多天累计逗留频次最高的一点。利用用户每天的手机出行轨迹,分析每位用户单天的出行目的地。当每位手机用户离开居住地后,出现频次最高的且在时间段具有周期性即作为其工作目的地,视为出行地的判定。
基于时空轨迹数据进行数据挖掘,主要是以时间、空间、业务特征等属性作为聚类纬度,在对所有的属性维度聚类后,定期实现基于新增的轨迹数据实现二次聚类,进而更新为新的类[19]。将用户的经度、纬度、频次、时间段四维数据进行基于时空的K-Means 聚类。聚类后的K 个聚类中心并不是作为用户的常驻点直接输出的,还需进一步分析判定。常驻判定1:由于聚类是传统意义上距离的聚类,时间标签是用数字来表示其含义的,对于时间标签聚类后肯定是有所偏差的,所以聚类后的时间标签值要根据其落入区间来识别哪一时间段。普遍地,信令数据中夜晚时段的信令要远远多于白天时段,由于聚类的影响,聚类结果的时间标签会有偏差,对在时间标签0的影响会偏大,故时间标签0的区间设定会比较大,时间标签1 设定的区间会相对比较小。常驻判定2:聚类结果中,当几个常驻点具有相同的时间属性时,按其频次大小赋予“常驻点1、常驻点2”的标签。一个人可能有一个或两个或以上的工作地,例如常驻工作地、非常驻工作地、出差地等。随着生活水平的提高,居民可能拥有几处房产,另外由于亲缘关系等内部原因,因此居住地可能不止一处。模型设计如图1。

图1 K值平均畸变程度
3 实验分析与讨论
3.1 数据来源
研究的数据集来源于某运营商2017 年2 月13日到2017 年3 月15 日的近一个月的基站信令数据。该数据集包含了669 万个用户约8 亿条信令。样例数据如图2 所示。基站信令数据各字段的具体含义见表1。

图2 样例数据

表1 信令数据各字段及其含义
3.2 数据处理
3.2.1 数据存储
在该数据集中抽取2017年2月13日到2017年3月15日的相关信令数据,且各用户间信令总数不均等。由Spark 平台执行提取操作后按用户存储,删除替换除字段外含有其他多余字符后保存为本地的.txt形式的文件[20]。
3.2.2 数据预处理
原始文件以.txt形式存储,对数据进行预处理:原始数据中的业务发生时间(Time Stamp)的转换,将字符串编码形式替换为北京时间;将每位用户数据按照产生信令的时间先后进行排序;对于字段经度和纬度,有个别经纬度调换的现象,将其对调修正。
3.3 参数验证
取500 用户信令数据作为参数验证集。选取某位用户作为展示:通过手肘法则判定K=4,如图3所示。K 值从1 至4 变化过程中,递减程度最为剧烈,平均畸变程度下降程度最为明显。K 值超过4之后,递减缓慢,平均畸变程度变化显著降低,因此肘部K=4。
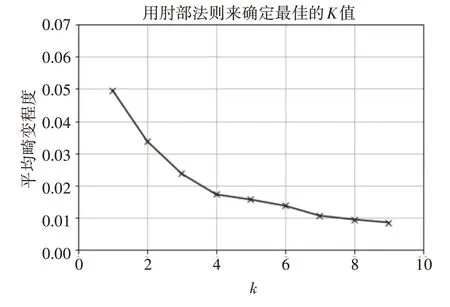
图3 K值平均畸变程度
K 值选取3 和4,距离分别采用欧氏距离和球面距离。于是得到四种组合:K=3&欧氏距离、K=3&球面距离、K=4&欧氏距离、K=4&球面距离。经过不同参数设置得到聚类后每一类的质心点,将质心点作为常驻点输出。根据聚类后的分类结果,取每一类中频次最高的信令位置作为聚类(频次)常驻点进行比较。不同参数下的常驻点统计结果如图4所示。

图4 不同参数下的常驻点距离对比(某用户)
在地图上实测不同参数下的常驻点到最终常驻点的距离。其中,信令位置的经纬度是国际上通用的地心坐标系WGS-84 坐标系,而高德地图等目前普通地图采用的是加密处理后的火星或者百度坐标系,所以对应到实际地图测量实际距离需要坐标系转换。据不同参数下的常驻点统计结果得到其常驻点距离对比图。
在常驻点2和常驻点3,K=3比K=4条件下的聚类中心点的效果更佳;但在常驻点1,K=3条件下聚类中心点效果太差,相距太远。这是因为由于用户轨迹点分布不均,聚类的簇较少,有些簇跨度较大,噪声点无法排除,导致选取的质心点与常驻点会有明显出入。论整体效果而言,在K=4条件下聚类中心点的效果好些,与前面提到的肘部法则的结果一致。明显地,不论K 值大小,距离度量选取球面距离比欧氏距离的效果更佳。因此,距离度量选取球面距离是可行的。经对比验证,K 值的选取根据手肘法则聚类效果更佳,而距离度量选取球面度量比聚类默认的距离度量更加精确。
3.4 模型检验
随机选取5 个已知测试用户进行模型检测。其中,用户1~5的聚类结果图如图5~9所示。
图5 用户1-基于时空聚类结果
图6 用户2-基于时空聚类结果
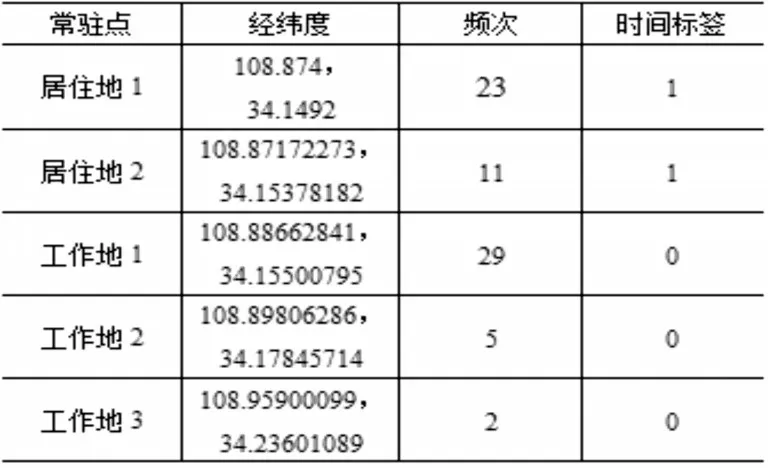
图8 用户4-基于时空聚类结果

图9 用户5-基于时空聚类结果
将5 个随机用户通过基于K-Means 时空聚类模型输出待有时间性质的常驻点,经与实际地理位置计算得到距离误差(单位:m)。距离误差如图10。
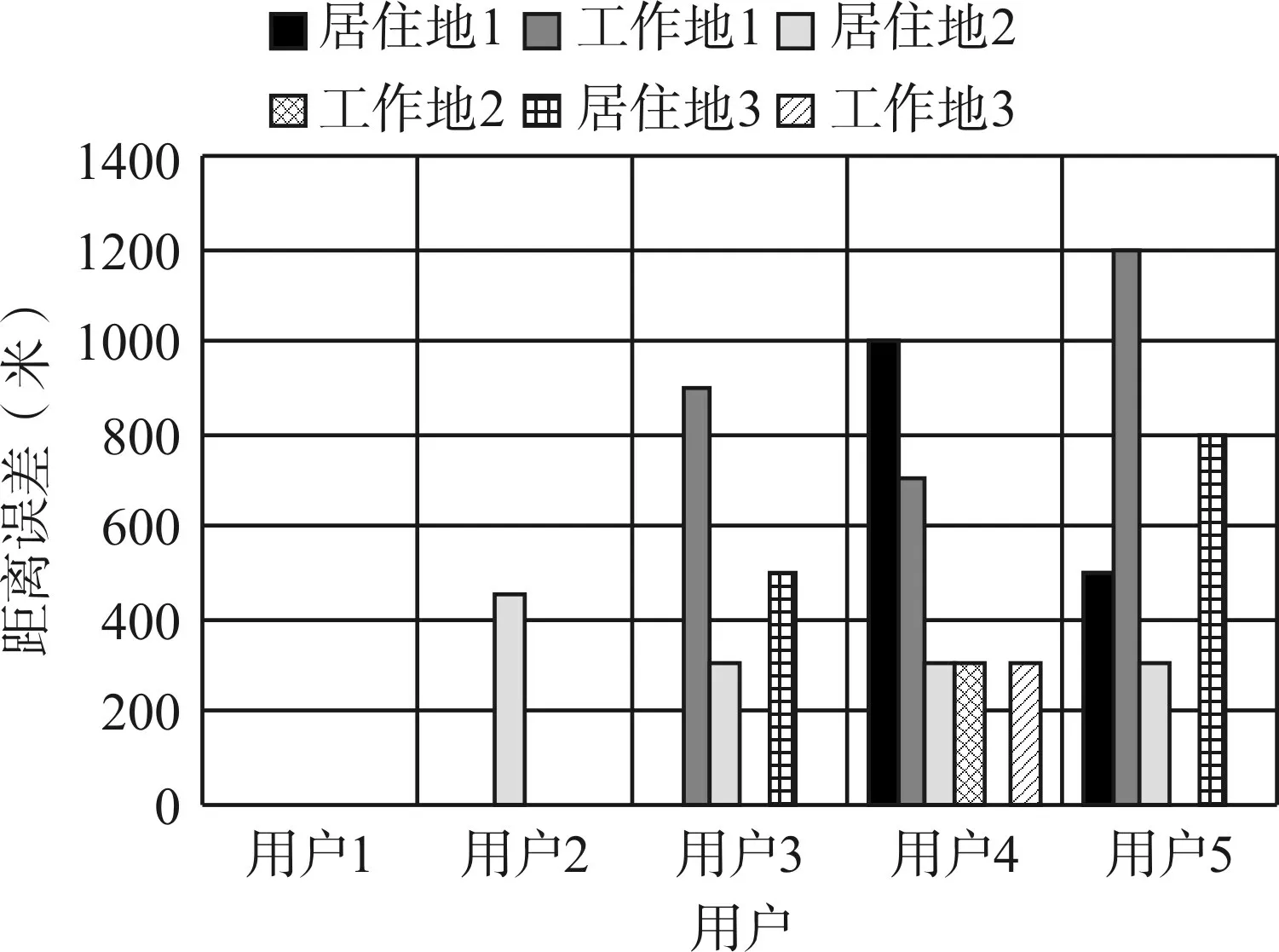
图10 用户1-5常驻地误差对比图
由图10所知,在5个用户的常驻地中的最大距离误差是1200m。用户1 和用户2 准确度较高,几乎能精准定位,在于这两个用户信令少避免了一些无用数据的影响。由于每个用户数据不一,特征不同,因此每个用户输出的常驻点数量不一且性质也不同。市区的基站覆盖范围半径在大约为100m~500m,郊区的大约为400m~1000m。与真实位置相比,只要距离误差小于该范围,就可默认职住地能够被准确识别到。移动基站定位在城区可能存在约800m的误差,由于受基站负荷、信号被建筑物遮挡等因素的影响,用户连接的基站可能不一定是距离其最近的基站,而且在乒乓效应的影响下,可能在两个相距比较近的基站间来回跳动,故在1000m的距离误差允许值内即可[21]。这5 个测试用户都能达到职住地的准确定位,因此该模型结果能达到可观要求,可投放使用。
4 结语
本文对具有时空信息轨迹点的各属性维度进行基于K-Means的时空聚类,经过一系列判定方法得到不同性质的常驻地。经实验验证,通过基于时空信息的K-Means聚类模型,能够识别出居民的职住地,且不受乒乓效应和离群点的影响,该模型的距离误差在客观范围内,且运行结果接近真实职住地。
