基于改进SVM 的电力企业信息系统异常检测方案的优化*
2020-06-09王逸兮查志勇王敬靖
王逸兮 余 铮 查志勇 冯 浩 王敬靖
(国网湖北省电力有限公司信息通信公司 武汉 430077)
1 引言
随着我国进入了大数据时代以来,各类型企业的发展速度陡然提高,其中电力企业的业务规模也出现了大幅增加。国家电网公司由于各分部、省公司在资源配置方面差异较大,使得大规模数据协调处理的复杂度呈几何级数上升,系统异常出现的概率大幅度增加,且故障排查效率相对低下,对信息系统的正常运行构成了严重的影响,因此必须采取有效措施,对网络性能异常进行精确快速的监测[1]。
目前网络异常检测技术已经研究出多种技术成果。如Roy 提出了提高检测技术鲁棒性的设计思路,指出流量规模在一定范围内的突变,不应当作为明确的异常指征,而仅可以作为参考标准[2];Jun Jiang 等人提出了网络性能检测的预判概念,采用预测算法对当前的网络性能波动进行计算,一定程度上实现了对异常情况的提前判定[3];Amon Goldman 等人将网络性能指标的变化数据用统计学中的迭代统计算法进行分析,实现了动态调节性能指标阈值的目标[4];以上检测方法均为被动统计方法,存在滞后程度较高的问题,而网络性能监控却需要将实时性作为首要指标,因此这些方法均不能实现对当前大规模网络的及时调控。
主动监控技术将原先针对某区域的总流量变化进行监控的方法,转变为针对区域内预设的一系列性能参数的异常变化进行检测和分析,即以网络区域内是否出现了相关类型的异常点为依据,判定当前该区域内是否出现了对应的问题[5~6]。在该类型的检测过程中,主要依据两个重要的参数来进行判定,其分别为基线和阈值。基线是指网络在通信过程中的性能基础值,反映网络在不同环境下的平均性能,而阈值则是以基线为中心动态调整的,指明了某一时间段内网络性能波动的正常范围。本文针对被动检测方法的缺点进行改进,提出采用SVM机制参与到性能评价过程中,实现了对基线参数的实时动态调整,同时利用训练残差的方法辅助确定网络性能指标的置信区间,从而提高了阈值计算的可靠性和精确性。
2 SVM算法原理
支持向量机SVM 属于智能型自适应优化算法,其特点是通过对解群体的分类与回归,很好的提高了算法的泛化性。其基本算法流程如下。
首先根据分析对象特征设定初始样本群体{xi,yj},i,j=1,2,…n;xi与yj分别为算法的n维输入量和输出量。式(1)给出了SVM 算法的基本函数形式:
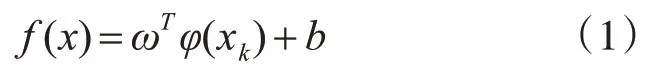
上式中φ(·)为算法的特征映射函数,将其视为被测对象的回归函数,将式(1)表述为
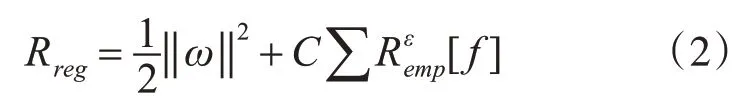
式(1)中的 ‖ω‖2为复杂度参数,用以描述f(·)的复杂度;C 为惩罚系数,用以设定算法对错误分类的惩罚程度,从而提高全局最优解的存在概率;为经验风险值,用来描述算法分类结果与真实结果之间的差值,其中ε为不灵敏损失函数,其作用等价于算法中的松弛变量[7],用以清除真实值在某范围内的误差,其满足式(3)。
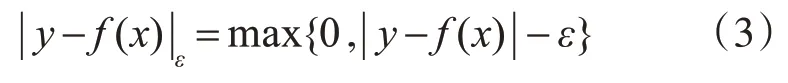
而经验风险可描述为
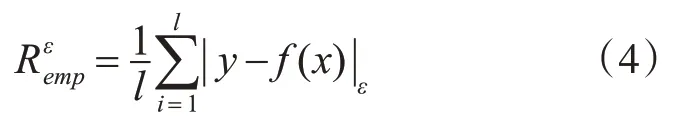
通过式(3)和式(4)代入,可将式(2)转变为
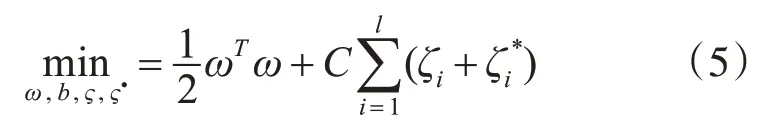
将拉格朗日乘子法用于上式,可将其转变为对偶优化问题的求解,如式(6)所示。

上式中,K(xi,xj)为核函数,这也是确定算法有效性的关键函数,尤其在针对线性不可分的数据进行SVM优化的过程中,必须根据被测对象的特征选取合适的K(xi,xj) ,目前常用的核函数有线性核函数、多项式核函数、Sigmoid 核函数和高斯(RBF)核函数等[8-9],此处选取高斯(RBF)核函数,即高斯径向基函数为例,如式(7)所示。
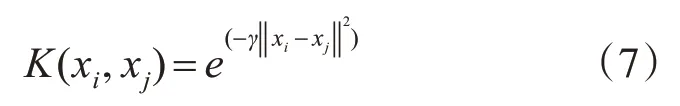
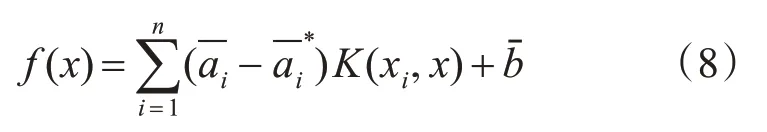
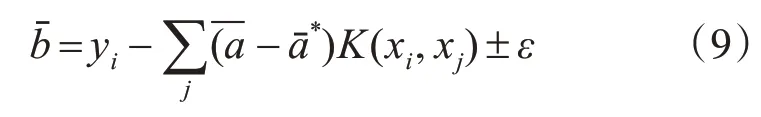
将代入后,式(8)即转变为以下形式:
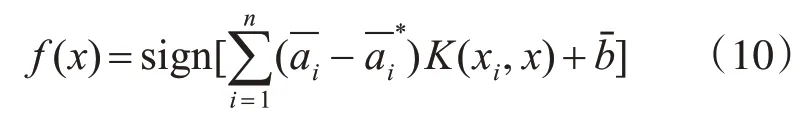
上式的求解即为二元分类问题的求解,f(x)的值有两种,分别为+1 和-1,前者表示x归为一类,后者则表示其归为二类,根据分类的结果,就可以对被监测对象的变化趋势进行预判,如网络性能参数是否会在时间序列中的下一时间点上出现异常。
3 基于SVM 的异常点检测方案的优化
3.1 网络性能指标模型的构建
本次优化方案选取时间点序列作为监测和分析对象,在构建数据模型时,训练集(样本群)中的每个个体均为时间序列中某一点上网络性能的对应指标[10],传统的建模方法是按照连续时间间隔的采样得到初始训练集,如式(11)所示。上式中,U 和V 分别为算法的输入和输出向量;t 表示时间序列的末尾点;l表示元素数量;m 表示嵌入维数;该方法缺点是基线和阈值的设定往往存在较大的滞后情况,无法对网络中各种性能指标快速且频繁变化状况进行实时的分析与识别,这就导致了许多异常点没有被及时检出,最终使得监测系统经常出现误报和漏报的情况。
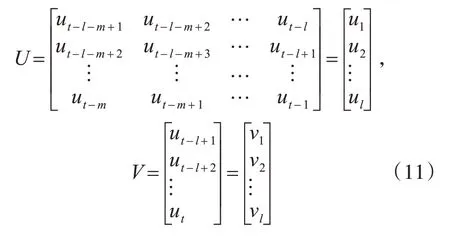
在检索了电力企业累积的大量网络性能监测数据后发现,各个区域内网元的性能波动规律虽然在短时间内是无序的且随机变化的,但在较长的监测周期内依然是遵循一定规律的,尤其在1d 的时间单位内,同时间段的变化规律相似性极高,因此本文提出采用同点时间序列构建网络性能变化模型的设计思路,即多日内同一时间点进行采样的方式,以更好的贴合电力企业网络性能的变化规律,如式(12)所示。

上式中U和V同样为系统的输入及输出向量,t、l、m与式(11)设定相同,n 为一日内时间点设定数量。根据电力企业信息传输异常事件的特征分析,当网络出现异常点时,其造成的持续影响往往覆盖了多个时间点,导致了评估结果的偏差;而在本模型中,所有的时间点均为分散的,时间点之间的间隔也并不固定,这就显著地减少了异常点多发的时间段内的采样次数,提高了系统异常检测与评价方案稳定性与客观性。
3.2 核函数的选择及参数优化
如前文所述,在SVM 算法中,起到关键影响作用的是核函数的选定与使用,针对电力企业网络性能波动特点,本文选取了高斯径向基函数为SVM算法的核函数,在设置参数的过程中,最关键的两个参数即为惩罚参数c 和核函数参数g[11]。本文对SVM 算法的改进也主要体现在对这两个参数的选定过程中,提出将参数寻优的工作分为两步进行,并通过交叉验证的方式快速逼近最优的c 和g 组合。
1)粗略寻优环节的验证与分析
图1 给出了粗略寻优环节的分析结果,本次参数寻优采用台湾林智仁教授研发的LibSVM软件来完成,x、y轴分别表示c、g取以2为底的对数后的值,而选定参数后的SVM 分类器输出结果的准确率则通过z 轴上的值来表示。利用LibSVM 软件中的SVMcgForClass 函数进行计算,在粗略寻优环节中,参数c 的估值区间确定为(2-2,24),随机选择为2.3965,而参数 g 则估值在 (2-4,24)之间,随机选定为4。将此组参数带入SVM 算法,实现对训练集的二元化分类,通过大量的真实数据验证,其结果的准确率略超过93%。
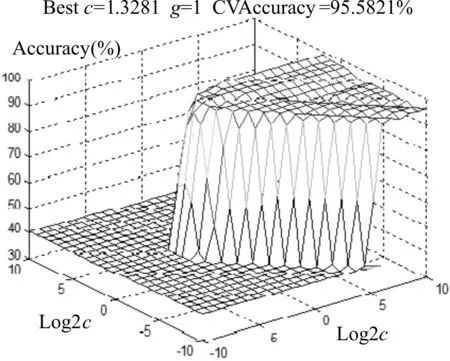
图1 参数两步寻优效果-粗略寻优环节
2)精细寻优环节的验证与分析
在完成粗略寻优的基础上,通过精细寻优环节进一步参数准确性。将参数c和g分别在其估值区间内执行离散化操作,随后再次执行SVMcg-ForClass函数,进一步缩小了两个参数的取值范围,最终得到的最优参数组合为c=1.3272,g=1,将其分别带入惩罚系数与核函数后,SVM分类器输出结果的准确性上升至了95.58%,优化效果较为明显,如图2所示。
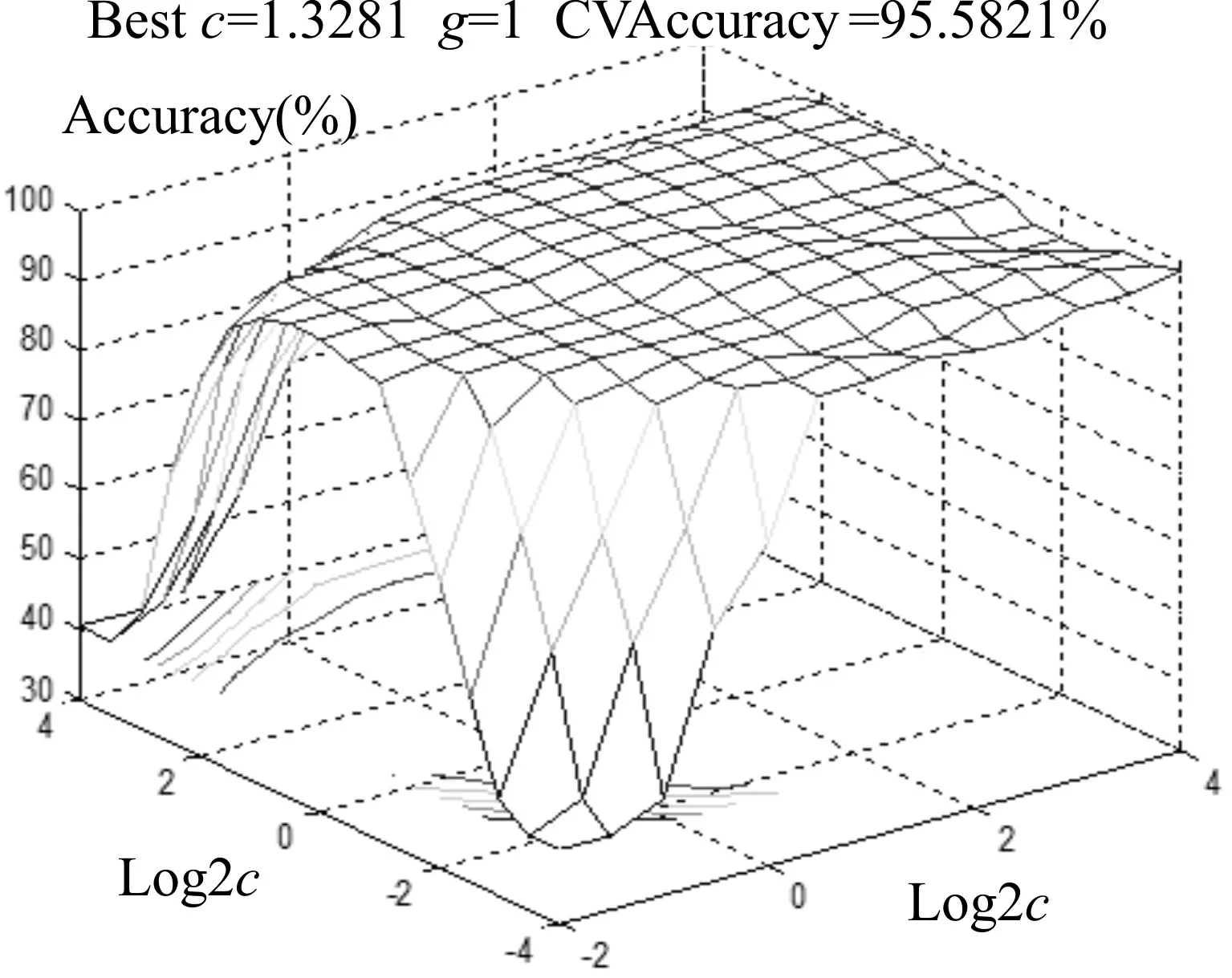
图2 参数两步寻优效果-精细寻优环节
3.3 置信区间的确定
在完成了参数优化的工作之后,即可根据训练参差计算得到网络性能指标在时间序列模型上的置信区间。为了提高算法的真实度,在确定置信区间的过程中添加高斯白噪声干扰e~N(0,σ2)作为算法约束条件,并将其代入式(10)可得:
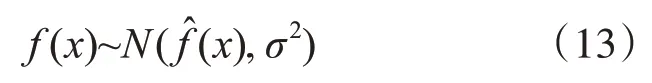
考虑到样本训练集的规模足够庞大,因此可将样本方差近似等价与总体方差,简化可得:
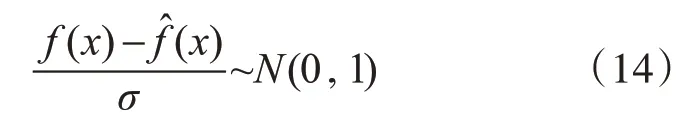
由于高丝白噪声是服从标准正态分布的,因此根据分位点α的定义可将上式转变为

进一步推导得到:
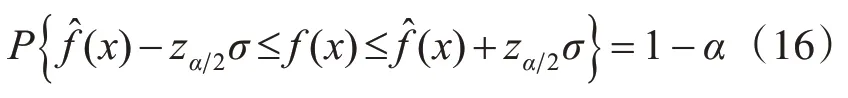
上式中的1-α即为根据被控对象预先设定的置信度,根据式(16)则可计算出给对应的阈值波动范围。分别以选定置信度为95%和97%为例,前者通过检索正态分布表,得z0.052=1.96 ≈2,对应的阈值波动范围则为后者同理查询可 得z0.032≈3 ,计算出阈值波动范围为。
4 仿真实验及结果分析
电力企业信息系统中需检测的性能指标有多种,本次仿真实验选取服务器节点的CPU负荷作为检测对象,所有的信息数据均来自电力企业系统服务器自 2018年3月31日17:00至4月2日16:50 的监控记录,样本群规模为316 个采样点。通过对监测记录的逐一筛查,总共发现并核实了17 个异常点,其中4 个异常点较为分散,而其余异常点则连续集中出现,随机分散的异常点表现为CPU负荷大幅度突变的特征,连续集中的异常点则表现出CPU负荷持续处于低位的特征。采取连续和同点这两种时间序列模型同时进行预测的方法,计算相关的基线和阈值,置信度均设置为95%,仿真实验结果的分别如图3和图4所示。
首先对图3 中的仿真曲线进行分析,可以明显的观察到,预测线较好地逼近了观察线,而且针对观察线上的异常点,预测线也在较短时间内给出了较为准确的预测结果,尤其对于4 个分散异常点,系统均在第一时间做出了检出响应,体现了较高的实时性。但与此同时,检测系统也出现了检出错误并发出误报警的情况,将两个处于阈值范围内的正常点也误判为了异常点;对于13 个连续集中异常点,该方案检出率较差,只能够检出第一个异常点,此外还出现了6 例错判和误报警的情况。由此可以看出,连续时间序列模型下的SVM 检测算法敏感性过高,而鲁棒性相对较差,容易出现误报警的情况,导致检测方案的实用性受到了限制。
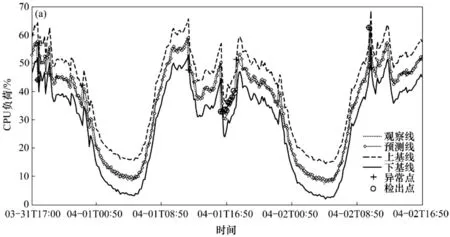
图3 连续时间序列仿真结果
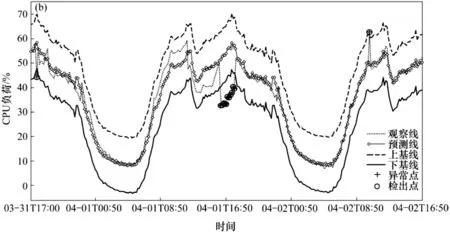
图4 同点时间序列仿真结果
图4 则采用同点时间序列模型,可以看出预测线相较于图3 中的曲线要更为平滑,即检测方法的敏感性得到了合理的控制,虽然各个预测点对于正常点的逼近程度稍弱于前一模型,但这种弱化程度是有限且平均的,因此不会对正常点的预测造成影响。在对异常点的检出率方面,同点时间序列模型的预测方法则表现出明显的优势,17 个异常点均被及时地检测出,同时也没有因误判而发生任何一次误报警,体现了良好的鲁棒性与可靠性,同时大幅度降低了检测失误的概率,已实际具备了持续监控能力。
5 结语
本文提出了将SVM 算法机制引入到信息系统异常检测过程中,并采用粗略寻优和精细寻优的两步交叉验证法,提高了SVM 核函数参数的寻优效率,并从而更加合理地确定了电力企业网络性能异常检测工作所需的基线和阈值参数。随后根据网络性能异常特征,构建了基于同点时间序列的检测模型,并同传统检测方法所采用的连续时间序列模型相对比,分别通过仿真实验对异常检测结果进行了分析,论证了本方法的有效性和可靠性。
