藏文古籍文本检测研究现状
2020-06-08王梦锦拥措李善琛
王梦锦 拥措 李善琛
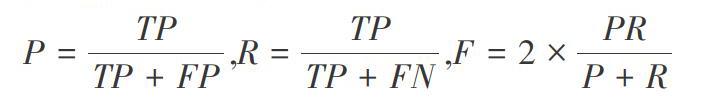

摘要:该文主要介绍了在过去十几年内自然场景文本检测最常用的算法以及其研究趋势,仔细阐述了藏文在文本检测与识别上的发展历程,讲述了众多研究学者根据藏文文字的结构特征,音节符特征等方面进行研究,为后期的藏文古籍文献检测试验打下基础。
关键词:藏文古籍文该文献;文本检测;深度学习;OCR
中图分类号:TP399 文献标识码:A
文章编号:1009-3044(2020)10-0204-04
随着电子科技和移动互联网的快速发展,移动电话,相机和其他的移动端的普及,基于传统的文本搜索已经不能满足人们的日常需求,人们意识到识别复杂场景下图片上的文字的必要性。顺应时代与信息科技发展的需求,藏文古籍文献数字化也变得必不可少。藏文古籍文献的数字化,有助于藏文古籍文献的保存与文化传承,有效促进西藏文化的发展。但藏文古籍文献的文本环境特殊,可用数据集较少,再加上扫描或者用相机进行拍照录入时,会导致其分辨率降低。而藏文古籍文献本身就存在众多问题,随着时代的变迁,介于藏文古籍文献的保存完好程度来看,不同的文献会出现不一样的清晰度,字体的大小,颜色,尺寸也大不相同,有些文献会出现字迹模糊,文字扭曲等现象,还有一些非文字区域出现类似于文字的纹理,其干扰检测的准确率。
针对以上困难,国内外专家对其进行多次的研究,最常见的算法来源于国外,如文献等;但我国国内对这些经典算法改进迅速,如文献等。文本检测传统方法有:SWT、MSER等;深度学习的方法有:R-CNN、Fast R-CNN、Faster R-CNN、CTPN等。本文将自然场景文本检测的算法进行总结,阐述了藏文在文字检测、识别上发展历程。
1文本检测研究现状
1.1自然场景文本检测研究现状
传统文档分析与现代文档分析区别在于数据集外观上的不同,传统的文档分析所用的是光学字符识别(Optical Charac-ter Recognition,OCR),OCR技术这一概念是早在20世纪20年代由德国的一位科学家提出,后来由美国的一位科学家将其运用到文字识别上。OCR发展到至今其技术已经相当成熟,但由于OCR技术都运用文本文档字符排列整齐、背景相对于简单等特点,他是运用传统的算法对其进行识别,其识别率较高;而场景文本检测则具有多样性、复杂性与不确定性,它包含了不同的文字、语言、不同的字体结构,每一个文字又有可能存在不同的大小,颜色,字体,亮度等,复杂程度大,识别率不高。
我国在20世纪90年代才开始对自然场景文本检测的研究,相对于其他国家而言起步较晚,但自然场景文本识别在我国发展迅速,目前已成为计算机视觉与模式识别、文档分析与识别领域的一个研究热点,一些国际顶级会议,如:CVPR(国际计算机视觉与模式识别会议)、ICCV(国际计算机视觉大会)、EC-CV(欧洲计算机视觉会议),已将其列为重要主题之一。特别是自2003年以来,自然场景文本检测定期在国际学术会议一文档分析与识别国际会议(International Conference on DocumentAnalysis and Recognition,ICDAR)上进行比赛,作为该领域最重要的权威比赛之一。该比赛分析了自然场景文本检测在其领域的研究现状和发展趋势,及时地跟踪和促进该技术的研究和发展。2011年10月,ICDAR首次在国内举办,由清华大学电子工程系的丁晓晴教授担任大会主席。此次会议有助于我国文字识别研究的发展以及国际学术界的交流。文字检测的效果主要分为P:准确率(Precision,),R:召回率(Recall)和F:标准指数。这三个指标的公式为:
经过ICDAR比赛给出的不同类型的数据集进行训练后,由于数据集的图片不同,其评价指标也有所不同。随着越来越多的研究人员加入这个领域进行研究,越来越多的公开数据集可以提供给这些研究人员来进行对自己的想法进行研究。自此使自然场景文本检测的技术的瓶颈与难点得以解决,以下就是ICDAR大赛上具有权威性的检测数据:
由此可见,经过研究学者们这些年的努力,使自然場景文本检测在我国有了飞跃般的发展。目前自然场景文本识别是众多研究者研究的对象,主要分为三部分:文本检测,文本识别和端到端的文本识别嘲。文本检测是对图片中的文字进行定位,为后期的文字识别服务,提高文字识别的准确率。自然场景文本检测主要经历了两个阶段:首先是基于传统算法的文本检测,后在2014年前后出现了基于深度学习的方法,目前基于深度学习的方法已经成了该领域的主流技术。
1.2藏文文本检测研究现状
目前为止还没有看到有关于藏文方面的文本检测的相关文献,但藏文识别有关工作从20世纪90年代开始就有相关的研究人员对其进行研究,研究的主要方向都是端到端的文字识别,中国藏文识别的主要研究核心力量是由这5所高校的科研团队组成:西北民族大学、西藏大学、中国科学院软件研究所、青海师范大学、西安电子科技大学。
1999年西北民族学院的周毛仁增将藏文字形结构进行了分析跟统计,提出抓住单字,部件之间的分解与组合对藏文文字识别,这个方法对编码输入很有用处,其按照藏文的字型结构特点,在理论上通过黑像素总数、用边熵、黑像素段及单部件四个方向进行藏文字形的统计分析。
2001年清华自动化系的王浩军,赵南元,邓钢铁三人将文字识别系统中的一些预处理方法成功运用到藏文识别系统上,在此基础上,他们考虑到藏文本身的书写方式,提出了一些新的处理方法,并在这些方面上都取到了良好的效果㈣。
2008年西藏大学的普次仁教授为了提高藏文文字的识别率,提出了一些技术方案,在数字图像识别技术的基础上,对在有外界干扰的情况下,从二值化,特征提取等方面提高了藏文文字的识别率。
2013年西藏大学的白玛玉珍同学在藏文文字特征的提取方法上进行了研究,从藏文的结构上提出来一些新的算法:网络点阵图形投影法,由于藏文的机构复杂笔画密度较小,使用该方法应用到藏文识别中会具备更好的效果。
2016西藏民族大学信息工程学院的陈小莹对不同藏文文本中不规范文本进行分类后,针对不同文字文本制定出不同的规范化处理方法,最后达到实现对藏文文本的规范化处理。
2017年西安电子科技大学的袁道昱在藏族同胞的帮助下将基于深度学习和特征提取的文字识别方法,用到了藏文音节识别的研究中,本文统计出500多种最常用的藏文音节字,同时采集出60套手写藏文音节字样本,建立了三万多个藏文手写音节字样本的数据库,在预处理步骤中,为了保留藏文音节字的特殊结构信息,该文献用线性归一化的方法,与非线性归一化、平滑处理等方法进行结合,最大限度上保留了手写藏文音节字的原始信息,去除了冗余,更方便于特征的提取与分类识别。
2017年艾金勇提出了一套层次化、基于规则的藏文文本规范处理方案的藏文信息处理,该方案准确的分析整理了藏文文本中各种不规范得文本类型,根据这些不同的文本类型分别设计不同类型的规范化算法,并用程序实现了藏文文本的规范化。
2018年张西群就藏文历史文献图像的文本区域相较其他区域角点密度比较大的问题,提出了一种基于块投影的藏文历史文献文本提取方法,该方法通过结合连通区域分类信息和角点密度信息,对均分的藏文历史文献的图像块进行过滤;分析过滤后图像块的投影,可以获取文本区域的近似边缘位置;结合文本区域的近似边缘位置和文本区域边缘搜索策略可以搜索得到文本区域的近似边缘;最后为了矫正由于字符粘连等造成的文本区域边缘不规则,通过矫正策略对文本区域边缘点进行坐标矫正。
2018年张西群,马龙龙,段立娟,刘泽宇,吴健就针对基于卷积降噪自编码器的藏文历史文献版面分析方面做出研究,此次研究提出了一种新的方法,就是将藏文历史文献图像进行超像素聚类获得超像素块,再利用卷积降噪自编码器从中提取特征,最后再使用SVM分类器对其进行分类预测,从而提取出文献版面的各个部分;此方法在藏文历史文献的数据集上多次实验表明,该方法能够对藏文历史文献的不同版面元素进行有效的分离。
2018年李颜兴就主要分析了藏文文本中影响切分的藏文笔画的原因以及主要因素,提出了两种方法,该两种方法都是基于基线的文本行切割方法,其中一种方法是通过模板匹配的方式来计算图像前半部分,从而估算文本行的个数以及基线的起始位置撮后通过动态追踪点的方法构建基线;而另一种则是使用Sobel算子,提取每个在藏文音节中的基线。自左向右连接基线构成文本行的基线。最后通过分析基线之间的连通部件,进一步确定文本行切分位置。
2自然場景文本检测算法
在过去的20年内,研究人员就针对复杂彩色图像中的文字检测提出来众多算法,尤其是近10年内,研究颇多,文献就是专门研究场景图片文字检测的,其检测的主要两个核心步骤是:候选文本区域提取与文本/非文本区域。而算法一般来说可以分为基于传统的算法与基于深度学习的算法这二大类。
2.1基于传统的文字检测算法
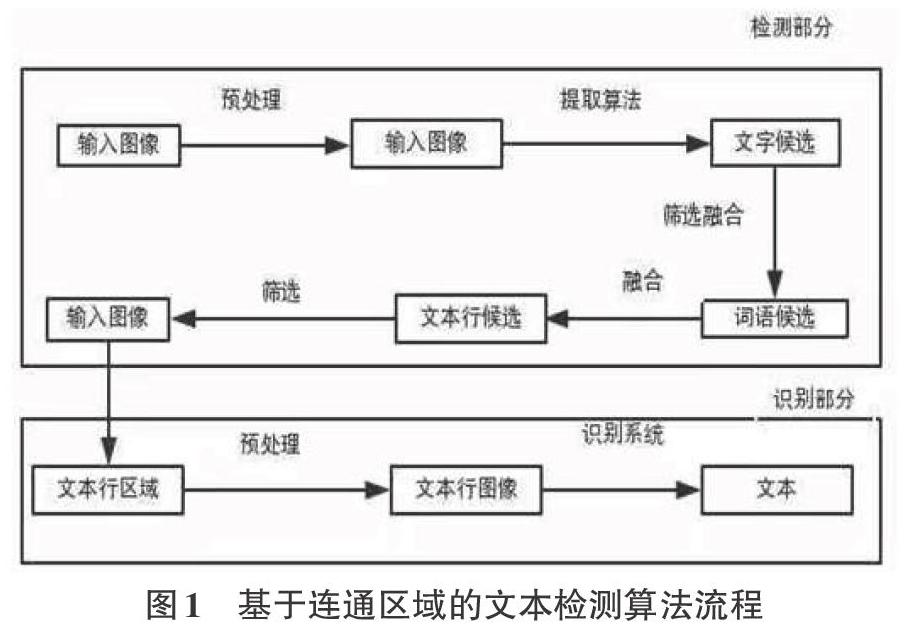
基于纹理及连通区域的算法大多是将文字看成某种的特定的纹理特征或者某类特定的区域。首先,我们可以用一些方法在图像中提取候选区域作为文字的候选,这些特殊包括颜色特征、纹理特征、边缘特征、笔画宽度变换、极值区域等㈣。这类算法最主要的是在提取文字候选区域,最常用的经典方法是SWTt211(Slroke Width Transform,笔画宽度变换)和MSER(Maxi-mallv Stable Extremal Regions,最大稳定极值区域)。图1为基于连通区域的文本检测算法流程:
SWT算法是有Epshtein等人在2010年提出的一种建立于边缘检测的算法上的算法,这一方法最大的优势在于:笔画特征基本上属于稳住独有的特征。
MSER是2002年作为一种放射区域提取方法被提出直到2010年才被引入文字检测领域。它是一种图形结构,对于图像的平移,旋转,放射变换等具有不变性。用一个阈值给图像做二值化处理,极值区域边界包括区域内大部分的像素值为1,极值区域边界外的像素值大部分为0,最大稳定极值区域就是指区域内的像素值与区域外的像素值差异明显,并且区域的面积不会随着阈值的改变而改变。有些连通区域面积随阈值上升变化较小,其公式为:
MSER的特点是:对图像灰度具有仿射变换的不变性;具有相同阈值范围内所支持的区域才会被选择的稳定性;无须任何平滑处理就可以实现多尺度检测,即小的和大的结构都可以被检测到。
2.2基于深度学习的算法
深度学习是近些年来人工智能方面最热门的一类方法,自2012年深度学习在ImageNet上面大放异彩之后,大家就注意到深度学习在计算机在视觉领域的巨大潜力。我们先对比一下传统的文本检测与基于深度学习的目标检测之间的不同点f表4来源网络):
而在文本检测领域方面最常用的方法有以下几种:基于候选框的文本检测(Proposal-based)、基于分割的文本检测(Seg-mentation-based)、基于两者方法混合的文本检(Hybrid-based)、其他方法的文本检测。近年来,人们尝试采用CNN网络进行文本检测,最经典的算法就是基于Faster-RCNN、SSD、RFCN等。
3文本检测数据集
现阶段,网络上有着各种不同的数据集供研究学者参考实验,以此提高检测,识别的准确率,藏文在数据集上并没有公开的数据集,需要自己申请,并对申请到的少量数据集采用残差网络进行图像处理,将一张图片进行处理后会产生很多虚拟图片,对这些图片在进行训练。以下表5为公开实验数据集的特点:
4总结与展望
从20世纪90年代开始,就有相关的研究人员对藏文进行研究,由于藏文的结构特殊,它是由30个辅音,4个元音组成,而藏字又分为乌金跟乌梅,这就大大提升了文字检测的难,众多研究学者就此根据藏文的结构特点,文字特征等方面对藏文进行识别;也有一些研究学者从藏文的音节符出发,提出了新的处理方法;这些方法对后期藏文文献的识别做出巨大贡献。由于藏文是7世纪中期,也就是吐蕃赞普松赞干布(617-650)执政时期,创制的文字,后期邀请了印度、尼泊尔、克什米尔、中原内地等周边国度和区域的学者,协调吐蕃译师吞弥桑布扎翻译了大量佛教文献,而这些文献是人工手写翻译,故有着许多的难点,人工手写,必定带有书写者不同的写字习惯,文本行可能会存在不同方向,弯曲,旋转,扭曲等样式,在进行文字检测中,很容易出现错误。时间的流逝,会使部分古籍上的文字变得模糊不清,再加上我们对这些古籍进行数字化录入时,扫描出的图片会受到但是天气,灯光等不同自然条件的影响,使检测困难加大,便有专家学者在在前人研究的基础上,提出用神经网络对藏文古籍进行研究。这些研究学者提出的新的处理方法,使藏文古籍文献的检测识别率提升,也为后人提供了较大的研究基础。
自然场景下得到的图片若用在自然场景下得藏文文本检测的话,这将大大提升了藏族人民的生活质量。现阶段自然场景文本识别技术在一些特定的领域有了一些新的应用,比如:智能交通系统(如:美国Hi-Teeh公司的See/Car svstem以及香港Asia Vision Technology公司的VECON-VIS等);基于内容的视频检索系统f如:美国卡耐基梅隆大学的Informe-dia DigitalVideo Library以及美国哥伦比亚大学的Web Seek等1:可穿戴/便携式视觉系统(美国麻省理工学院的Finger Reader以及Goggles等),除了上述应用以外,一些研究者还将自然场景文本检测技术应用到图像理解,文种识别等领域,相比自然场景文本检测技术的潜在应用市场,上述应用只是“冰山一角”在生活方面,自然场景文本识别可以辅助无人驾驶车来读取交通标识信息,通过识别来提高形式规划能力等,自然场景文本检测将会随着时代的进行,在时代发展的驱动下不断扩展,不断成熟。