单声道语音降噪与去混响研究综述
2020-06-08叶文政惠国强吕忆蓝钱宇欣
蓝 天 彭 川 李 森 叶文政 李 萌 惠国强 吕忆蓝 钱宇欣 刘 峤
(电子科技大学信息与软件工程学院 成都 610054)
语音增强是指利用音频信号处理技术及各种算法提高失真语音信号的可懂度或整体感知质量,从而进一步在语音识别、语音通话、电话会议、场景录音、军事窃听和听力辅助等场景中改善应用效果.语音增强属于语音分离的一项内容,而后者还包括说话人分离等.狭义的语音增强单指语音降噪,而广义的语音增强还包括语音去混响[1],因为语音去混响也是提高语音质量的重要手段.根据接收端麦克风数目的不同,可以将语音增强分为单声道(单个麦克风)与多声道(多个麦克风)2类.单声道语音增强算法只需单个麦克风,实现的成本较低,在实际生活中得到了广泛的应用[1].由于单声道增强算法获取的音频信息量较少,且无法利用声音传播的空间信息,它的实现更具挑战[2-3].本文着重关注广义的单声道语音增强(为简化叙述,后文如无特别说明则省略“单声道”限定语),对语音降噪与语音去混响两方面的研究工作都进行了调研分析.
早期的语音降噪或去混响主要通过数字信号分析方法,如谱减法、滤波法等,从时域、频域或时频结合的方式对语音信号进行分解,找到纯净语音或噪声的特征,从而将二者分离,属于无监督的方法.随着机器学习技术的演进,有监督的方法不断地被提出,学者们开始尝试通过各种机器学习模型去自动发现带噪(带混响)语音与纯净语音信号之间的关系,近年来最有代表性的莫过于深度学习在本领域的应用,它极大提升了语音降噪、去混响的效果.
本文对单声道语音增强的现有研究工作进行了梳理分类,简要介绍了典型方法的研究思路,并对具备可比性的实验结果进行了综合比较,有助于本领域研究人员进一步分析这些方法之间的联系与区别;对在实验与评估过程中所涉及到的相关基本概念进行了整理与简介,并提供出处来源,有利于初学者查阅所需预备知识;在全面分析相关研究工作现状的基础上,探讨了目前单声道语音增强仍然面临的主要问题与挑战,可供本领域研究人员参考归纳未来的研究方向.
1 传统的语音降噪方法
语音降噪是语音处理领域的一个基本问题,旨在从受噪声干扰的信号中有效地分离出目标信号.噪声干扰对语音活动检测和语音识别等任务的准确率具有很大的影响,因而研究解决噪声对后续语音处理任务的影响一直受到学术界的广泛关注[4].传统的语音降噪方法主要是基于数字信号处理等算法,主要包括谱减法、维纳滤波、基于统计模型以及子空间的方法等.
1.1 谱减法
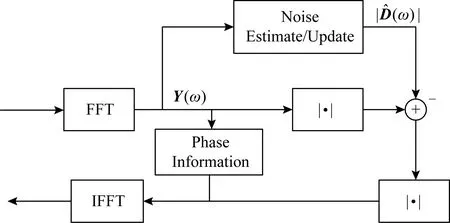
Fig. 1 Spectral subtraction based speech enhancement method图1 基于谱减法的语音增强方法
谱减法是最早期提出的降噪算法之一,它基于一个简单假设:噪声是加性噪声.通过从带噪语音谱中减去对噪声谱的估计来得到降噪后的语音谱,其基本做法如图1所示,做出这一假设是基于噪声的平稳性或者是一种慢变的过程[5].由于实际噪声的非平稳特性,在使用过程中,这种方法很容易由于谱减过程中减去谱成分的过大或过小造成语音失真,即产生令人困扰的音乐噪声.为减轻由谱减过程引入的语音失真,最常用的一种方式就是采用过减因子来控制失真程度,众多学者提出了不同的准则来计算过减因子[6-8],例如对差分谱做半波整流(half-wave rectification, HWR)和基于心理声学掩蔽阈值的方法.随着小波技术的发展,Zhong等人[9]根据硬阈值和软阈值改进了基于小波降噪的阈值函数算法,该方法有效地减少了降噪后信号中的毛刺现象.但是受到假设条件的限制,谱减法始终不能有效地解决音乐噪声的问题.
1.2 滤波法
不同于基于简单假设的谱减法,维纳滤波器的提出是基于最小均方误差意义的最优解,通过求解最优化均方误差计算得到增强信号[10],基本流程如图2所示,但是它的推导仍然是基于所分析信号具有平稳性这一假设,不能有效地处理非平稳信号的情况.在后续改进中,通过使用卡尔曼(Kalman)滤波器,滤波法成功地被推广到处理非平稳信号和噪声的场景下[11-12].Wang等人[13]提出了一种使用卡尔曼滤波器进行调制域语音增强的算法,利用高斯环统计模型将语音和噪声频谱幅度进行结合,通过高斯混合来模拟复数傅里叶域中语音和噪声的先验分布;Andersen等人[14]将多声道技术,即基于语音失真加权的帧间维纳滤波器(speech-distortion weighted inter-frame Wiener filter)应用于单声道,进一步利用二次高分辨率滤波器组(secondary higher resolution filter bank)改进了对帧间相关性(inter-frame corr-elation, IFC)的估计,更好地在语音降噪和失真之间找到一个平衡参数,减轻了增强语音失真;Peng等人[15]在线性预测残差域中结合人类听觉系统的掩蔽特性,进一步抑制了残留噪声.
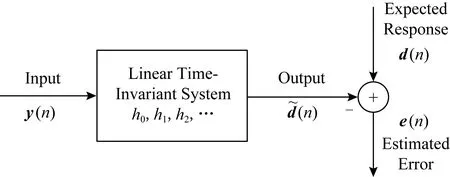
Fig. 2 Wiener filtering based speech enhancement method图2 基于维纳滤波法的语音增强方法
1.3 基于统计模型的方法
最小均方误差(minimum mean-square error, MMSE)估计是一种常用的基于统计模型的语音降噪方法,与维纳滤波的区别在于,基于MMSE的语音降噪方法可以得到对降噪语音谱的非线性估计[16-18].该方法对短时频谱幅度(short time spectral amplitude, STSA)进行最优估计,即得到关于估计幅度与实际幅度均方误差的最小优化估计器:

(1)

1.4 子空间方法
子空间方法是一种基于线性代数理论的语音降噪方法,这类算法假设纯净信号可以被视为带噪信号在Euclidean空间中的一个子空间,通过将带噪信号向量空间分解为纯净信号主导和噪声信号主导的2个子空间,从而可以简单地通过去除落在“噪声空间”中的带噪向量分量来估计纯净信号[22].带噪信号分解为2个子空间常用的正交矩阵方法有奇异值分解(singular value decomposition, SVD)[23-24]和特征值分解(eigenvalue decomposition, EVD).Ephraim等人[25]提出了利用协方差矩阵的特征值分解,通过利用Karhunen-Loéve变换(Karhunen-Loéve transform, KLT)进行信号分解,在满足残余噪声低于预设阈值约束的同时实现了语音失真最小化.
我们统计并比较了传统的语音降噪方法在不同噪声环境以及不同信噪比下的主观语音质量评估(perceptual evaluation of speech quality, PESQ)和短时客观可懂度(short-time objective intelligibility, STOI)指标,如表1和表2所示.其中PESQ取值范围为-0.5~4.5,STOI取值范围为0~1,两者的数值越高表示降噪效果越好,详见4.3节所述.
2 基于机器学习的语音降噪方法
语音降噪问题可以视为一个监督性学习问题,很多学者考虑使用机器学习的方法来解决语音降噪的问题.由于计算机硬件的限制,早期的有监督模型一般都是在浅层模型以及小数据集上实现的;在2006年Hinton等人[30]提出了一种基于受限玻尔兹曼机的逐层学习方案,并将其应用于深层神经网络(deep neural network, DNN)的网络训练中,解决了DNN训练中的局部最优问题,显示出监督性学习的建模优势.此后,得益于DNN的层次化非线性处理能力,深度学习的概念被广泛应用于语音[31-32]、图像[33]及自然语言处理[34]任务中,迅速发展成为机器学习领域的一个重要分支,越来越多的学者开始探索深度学习在语音降噪方面的应用.

Table 1 Comparison of PESQ Scores in Traditional Speech Denoising Methods表1 传统语音降噪方法的PESQ指标对比

Table 2 Comparison of STOI Scores in Traditional Speech Denoising Methods表2 传统语音降噪方法的STOI指标对比
Note: The symbol * comes from our estimation of the graph in the reference paper.
早期的经典DNN模型通常由一个输入层,若干非线性隐含层以及一个输出层组成,层与层之间相互堆叠,前一层的输出传递到后一层,形成一个深层网络.相比于浅层网络,深层模型更擅长从原始数据中学习对目标有用的特征表示,比较典型的神经网络有卷积神经网络(convolutional neural network, CNN)[35-36]、循环神经网络(recurrent neural network, RNN)[35]以及2014年提出的生成对抗网络(generative adversarial network, GAN)[37]等.在基于深度学习的语音降噪任务中,根据神经网络是否对语音时域波形直接处理可以分为非端到端和端到端的语音降噪;在非端到端的语音降噪任务中,根据网络的学习目标的不同,可以把降噪方法分为:基于时频掩蔽(time-frequency mask)的语音降噪算法、基于频谱映射的语音降噪算法和基于信号近似的语音降噪算法;一些学者也提出了基于端到端的算法以及深度学习与传统方法结合的算法.本节将介绍传统机器学习、非端到端方法以及端到端的方法在语音降噪领域的应用.
图3给出了非端到端的语音降噪算法结构图,在训练阶段首先通过时频分解、特征提取将原始的时域波形处理为时频表示,随后将时频表示的特征送入到神经网络中进行训练,将估计出的目标作用于带噪语音得到降噪后的语音;经过多轮迭代调整网络参数,使其更好地学习带噪语音与纯净语音之间的复杂映射关系.在测试阶段,提取特征后的带噪语音被输入到训练好的降噪模型中,降噪后的语音时频表示与带噪语音的相位结合便可得到时域的波形信号.与图3类似,图4给出了端到端的语音降噪模型,通过直接学习时域波形层级的映射关系,在保留更多原始波形信息的同时,简化了处理流程.

Fig. 3 A block diagram of non-end-to-end speech denoising system based on deep learning图3 基于深度学习的非端到端语音降噪系统结构框图
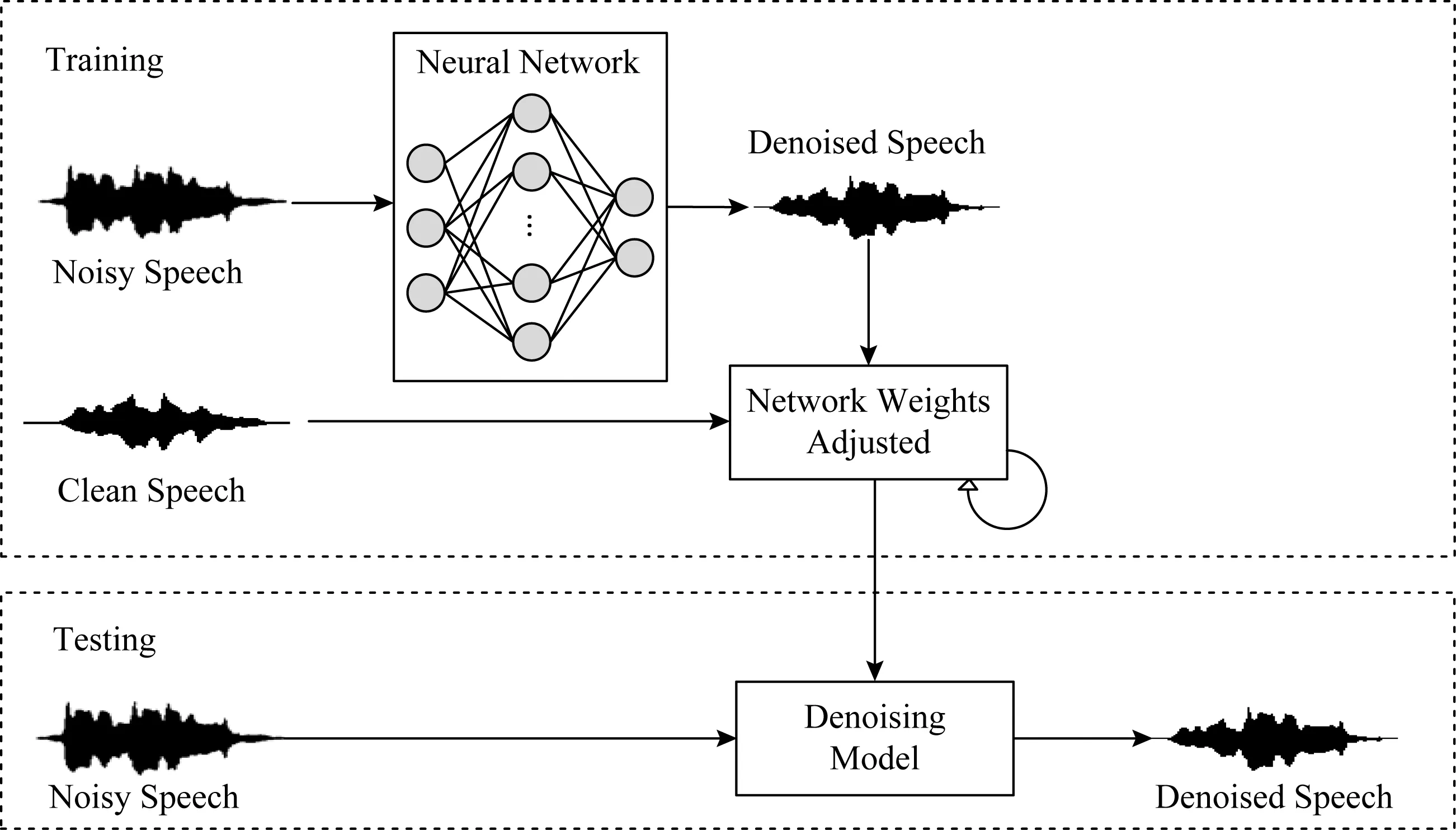
Fig. 4 A block diagram of end-to-end speech denoising system based on deep learning图4 基于深度学习的端到端语音降噪系统结构框图
2.1 基于传统机器学习模型的方法
早期语音降噪系统模型主要是一些浅层模型,经典的方法包含高斯混合模型(Gaussian mixture model, GMM)、支持向量机(support vector machine, SVM)和非负矩阵分解(nonnegative matrix factori-zation, NMF).
高斯混合模型通过多个高斯分布函数的线性组合,来模拟复杂的分布.Kim等人[38]利用GMM对时频单元进行建模,通过输入给定的频带特征,输出语音主导和噪声主导的概率.利用估计的二值掩蔽和混合语音的Gammatone滤波输出合成语音的时域波形.但由于该模型是单独对每一个频带进行建模,忽略了频带间的相关性,不具有较强的实用性.
支持向量机通过在高维特征空间中寻找最优分类面对数据进行分割.Han等人[39]利用SVM对每个频带的时频单元进行建模,学习被目标语音主导的时频单元和被噪音主导的时频单元最优区分面,通过计算到分类面的距离实现时频单元的分类.相比于GMM,SVM具有更好的分类准确性和泛化性能.
非负矩阵分解是最常用的有监督语音降噪方法[40-41].NMF算法对纯净语音和噪声单独训练,分别得到对语音和噪声的信号基表示,从而在带噪语音中分离出纯净语音.为了减少具有与语音信号类似的特征的残余噪声分量,Chung等人[42]提出了基于NMF的类条件基矢量的训练和补偿算法.但是当遇到在训练阶段没有出现过的语音或者噪音时,算法性能会出现下降.
2.2 基于深度学习模型的方法
2.2.1 基于时频掩蔽的方法
基于时频掩蔽的语音降噪方法将描述纯净语音与噪声之间相互关系的时频掩蔽作为学习目标.研究表明,基于时频掩蔽的方法可以有效地提高复杂环境下的语音可懂度[38,43],但该方法需要假设纯净语音与噪声之间有一定的独立性.理想二值掩蔽(ideal binary mask, IBM)[44]是最早用于语音降噪的时频掩蔽之一,它实际上是一个定义在二维空间(时间和频率)上的一个二值(0或1)矩阵,其中每个元素:
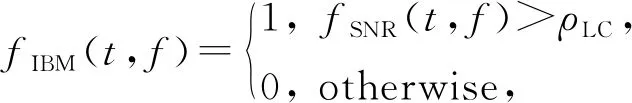
(2)
其中,t和f分别表示时刻和频率,fSNR(t,f)表示在时刻t、频率f处时频单元的局部信噪比.当局部信噪比大于局部阈值(local criterion, LC)ρLC时,IBM在此处赋值为1,否则赋值为0,这代表IBM将每个时频单元判定为以语音为主或以噪声为主.除此之外,也有一些基于比值的掩蔽或复数域掩蔽相继被提出,例如理想比值掩蔽(ideal ratio mask, IRM)[45]、最优比值掩蔽(optimal ratio time-frequency mask, ORM)[46]、频谱幅度掩蔽(spectral magnitude mask, SMM)[47]、相位敏感掩蔽(phase-sensitive mask, PSM)[48]以及复数域理想比值掩蔽(complex ideal ratio mask, cIRM)[49]等.这些掩蔽根据语音及噪声的幅度谱或功率谱计算得到,随后通过将逆变换技术作用于估计的时频掩蔽上,从而合成目标语音的时域波形.
Wang等人[50-51]将DNN引入语音分离与降噪领域,并对该工作进行扩展.他们将受限玻尔兹曼机(restricted Boltzmann machine, RBM)预训练的前馈DNN作为二元分类器来估计IBM,并考虑了语音的时间动态特性,引入结构化感知机和条件随机场来改进模型.实验证明:相比于传统方法,基于DNN的方法在匹配和不匹配的噪声情况下均取得了很好的降噪效果.在扩展工作中,Wang等人[52]对通过Gammatone滤波器组的子带信号使用DNN来学习输入信号的特征,他们将训练网络中最后一个隐藏层的输出与输入特征串联起来送入SVM中估计IBM,经过实验评估作者取得了高的语音可懂度,但是语音质量损失较为严重;Healy等人[43]将该算法扩展为2阶段训练方式,利用数据的上下文信息,显著提高了分类精度.作者在专业测验中测试了该算法,结果表明,对于听力正常和听力受损的听众,语音可懂度均显著提高.
Narayanan和汪德亮[53-54]将理想比率掩蔽IRM作为目标,在梅尔谱域估计IRM,并在一定程度上提高了语音识别的鲁棒性;Madhu等人[55]也发现连续性学习目标相比于二值目标可以取得更好的性能;Nie和Zhang等人[56-57]提出了一种用于IBM估计的深度叠加网络,并使用掩码进行基音估计,提高了掩码估计和基音估计的精度;Williamson等人[49]提出复数理想比例掩蔽cIRM并使用DNN同时估计cIRM的实部和虚部,极大提高了语音可懂度;Hui等人[58]使用卷积网络,通过Maxout和Dropout方法分别解决了训练的饱和问题以及泛化问题,并在客观可懂度和语音质量方面均超过了基于DNN的方法;Wang等人[47]在语音分离任务中分析对比了一系列时频掩蔽的训练目标,从论文结果中可以看出,以IRM为训练目标的方法可以得到更好的语音质量与可懂度.
2.2.2 基于特征映射的方法
基于特征映射的语音降噪方法利用带噪语音特征与纯净语音特征之间的复杂关系,学习两者间的映射.网络的输入与输出通常是同种类型的声学特征,并且在实现过程中,几乎没有对语音和噪声信号做任何假设.常见的特征映射包括目标幅度谱(target magnitude spectrum, TMS)、Gammatone域目标功率谱(Gammatone frequency target power spectrum, GF-TPS)以及短时傅里叶变换幅度谱(short-time Fourier transform spectrum, SFTS)等.其中,TMS[59-62]从带噪语音中估计纯净语音幅度谱、功率谱或梅尔谱等,然后将得到的幅度与带噪语音相位结合,得到估计语音波形;GF-TPS[47]是基于Gammatone滤波器的听觉谱(cochleagram),通过听觉谱转换,可以很容易地将GT-TPS的估计结果转换为降噪的语音波形;SFTS是语音的时域信号经过分帧、加窗以及短时傅里叶变换得到的时频表示.若不考虑相位不匹配的影响,则可直接估计目标语音的短时傅里叶变换(short-time Fourier trans-form, STFT)幅度谱,结合带噪语音相位信息后,通过短时傅里叶逆变换(inverse short-time Fourier transform, ISTFT)可估计得到目标语音的时域波形.
自动编码器是基于特征映射的语音降噪算法中的一类典型结构,Vincent等人[63]在2008年首次提出降噪自动编码器(denoising autoencoder, DA),并将其用于提取鲁棒性的特征;在此基础上,Maas等人[64]提出了循环降噪自动编码器(recurrent denoising autoencoder, RDA),并将该方法应用到语音识别的前端降噪任务上,降低了语音识别的错误率;Xia等人[65]利用降噪自动编码器估计纯净语音的频谱,然后用最小控制迭代平均的方法估计噪声,进而计算出先验信噪比,最后用维纳滤波的方法得到纯净语音的频谱估计;Lu等人[59]提出用堆叠式自动编码进行语音降噪,将多个训练好的自动编码器(autoencoder, AE)叠加成一个深层自动编码器(deep autoencoder, DAE),然后使用反向传播算法对其进行监督微调.通过DAE学习一个梅尔域带噪语音到纯净语音的功率谱映射,并在匹配噪声的情况下取得了一定的降噪效果.
Xu等人[61,66]提出把深层神经网络视为一个回归模型,作者使用带RBM预训练的DNN将带噪语音的对数功率谱映射到纯净语音的对数功率谱上,然后使用混合语音的相位,通过ISTFT得到目标语音的时域波形信号;作者使用了多种噪声来构建训练数据集,降噪后的PESQ比带噪语音高0.4~0.5,明显高于传统语音降噪方法,并且具有较好的泛化性能.Han等人[62]使用DNN来学习带混响和噪声的语音到纯净语音的映射关系,提高了语音可懂度与信噪比;Tu等人[67]在DNN非连续层之间添加了跳连接,间接地迫使神经网络学习IRM,另外,作者将网络结构堆叠起来,取得了更好的评估结果;Wang等人[68]发现直接使用标准的前馈神经网络把带噪信号映射到纯净信号的效果不理想,所以他们将傅里叶逆变换融合到神经网络中.Karjol等人[69]考虑到单个DNN可能无法更好地挖掘语音信号的时空结构信息,所以他们使用了添加门控网络的多DNN策略来训练数据,并取得了优于单个DNN的降噪效果.也有一些基于CNN的方法被用于频谱映射,通常CNN模型由输入层、卷积层、池化层、全连接层和输出层组成,通过卷积层与池化层的级联挖掘特征信息,另外CNN中的权重共享可以减少训练参数的数量.Park等人[70]提出冗余卷积编码解码网络(redundant convolutional encoder-decoder, R-CED),通过删去池化层、加入跳跃连接的方式优化训练过程.Fu等人[71]提出了一种SNR-Aware(signal to noise ratio aware)的CNN语音降噪模型,并在实际应用中验证了该方法的泛化性.Gao等人[72]采用长短期记忆网络[73](long short-term memory, LSTM)显式学习特定信噪比的中间目标,引入密集连接的渐进学习,将输入以及中间目标的估计拼接起来,再一起学习下一个目标.这种方式缓解了信息丢失的问题,语音可懂度在各种实验噪声下均有提高.
一些学者将GAN应用到了语音降噪领域,GAN中的对抗机制来源于二人博弈的思想,它同时训练2部分模型:生成模型和判别模型,分别用MG和MD表示.MG的目标是生成更加“真实”的样本以欺骗MD,MD的目标是更准确地分辨真实样本与MG生成的样本之间的差异;通过迭代训练,在持续的竞争中共同推动2种模型提高性能,直到MD无法区分MG生成的样本与真实样本为止.Michelsanti等人[74]借鉴图像领域的Pix2Pix[75]框架,通过MG对带噪语音频谱图降噪,MD用来将MG生成的降噪频谱与纯净语音频谱区分开,作者取得了与DNN相当的降噪效果.Donahue等人[76]探索了GAN在语音鲁棒性识别中的应用,在频域上应用GAN,提出了FSEGAN(frequency-domain speech enhancement GAN)并在语音鲁棒性识别中相比于传统多风格训练(multi-style training, MTR)有7%的性能提升.
2.2.3 基于信号近似的方法
基于信号近似(signal approximation, SA)的方法是利用神经网络估计掩蔽,并将其作用于带噪语音幅度谱上,得到估计语音的幅度谱。该掩蔽能最小化纯净语音幅度谱与估计语音幅度谱之间的差异:

(3)
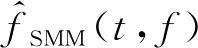
Huang等人使用DNN与DRNN(deep RNN)对说话语音进行降噪与分离[77-78],DRNN是多层RNN的堆叠,与RNN类似,是一类具有短期记忆能力的神经网络,其神经元既可以接受其他神经元的信息,也可以接受自身的信息,形成具有环路的网络结构,比较适合对语音信号这种序列化数据建模;通过DRNN估计出目标语音和干扰语音的掩蔽值,由区分性训练的方式将掩蔽值引入到损失函数中,最小化混合语音重构误差,实验结果相比于NMF方法有很大提升.然而,在RNN中很容易出现梯度消失和梯度爆炸的问题[79],为缓解这一问题引入了LSTM,通过门控机制将上下文信息保持在记忆单元中,Weninger等人[80]使用LSTM模型实现信号近似来预测掩蔽值,在时频域内估计误差,在随后的工作中加入了相位信息并应用到了鲁棒性语音识别的任务中[81].
2.2.4 基于端到端的方法
大部分监督性语音降噪是在时频域进行的,近年来,一些学者开始将注意力转移到端到端的解决方式上,即对原始时域波形信号直接进行处理.由于不依赖于频域表示,端到端的方法避免了相位信息丢失以及重构降噪语音时使用带噪语音相位而可能引发的降噪效果不佳的问题;端到端的处理方式可以减少语音信号的处理工序,避免了信号在时频域的来回切换,使得流程更加简化.
Qian等人[82]提出贝叶斯WaveNet[83]框架BaWN(Bayesian WaveNet)用于语音降噪,利用WaveNet对原始波形的强大建模能力,将输出正则化到语音空间,显示出贝叶斯框架中语音先验分布的有效性,并取得了较好的泛化性能;随后,Rethage等人[84]也在WaveNet的基础上进行语音降噪,利用非因果扩张卷积来预测一系列目标,而不是单一目标.实验结果表明,该方法优于基于幅度谱的Wiener滤波方法;Fu等人[85-86]提出了全卷积神经网络(fully convolutional neural network, FCN)来对语音进行降噪,他们发现全连接层不易同时映射语音信号的高频分量与低频分量,所以删除了卷积网络的全连接层.作者将神经网络应用于整句语音波形信号,并改进了损失函数,使得语音降噪效果得到改善.Venkataramani等人[87]提出了一种基于卷积自动编码器的前端变换,用来替代STFT.该编码器可以自动从数据的原始波形发现数据特定的频域表示,该方法相比于基于STFT的方法,取得了更好的性能,可以用于端到端的语音降噪任务中.Pascual等人[88]提出了基于GAN的端到端语音降噪模型,其MG是一个全卷积网络,用于对语音进行降噪处理,鉴别器MD与MG有着同样的结构,它对MG生成的波形以及纯净原始信号波形进行判别,并将判别结果反馈给MG.通过作者的实验,GAN可以在一定程度上对语音进行降噪,但是在评估指标PESQ上略低于Wiener滤波.
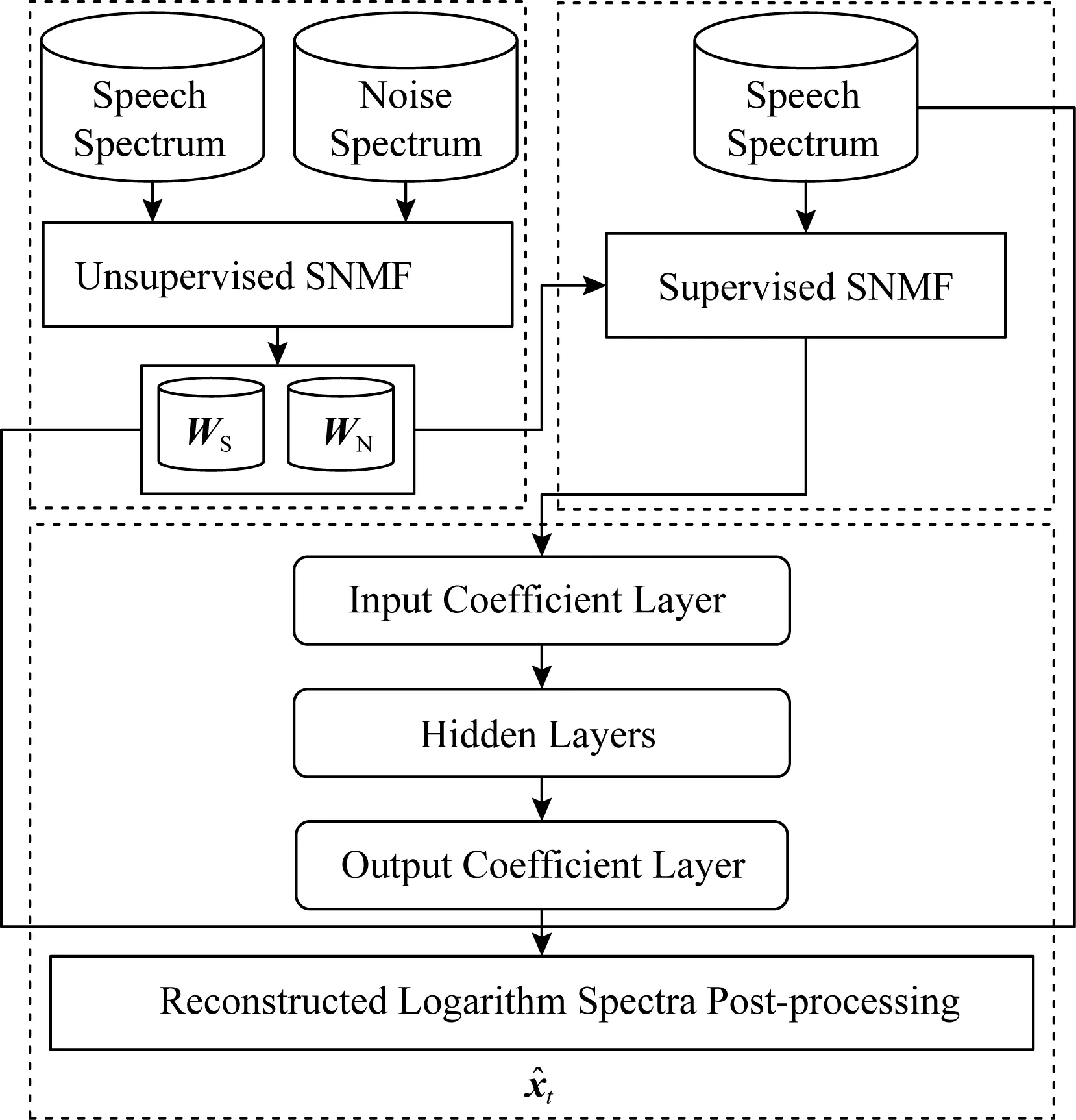
Fig. 5 Combination of DNN and NMF method图5 DNN与NMF结合的方法[89]
2.3 结合传统方法与深度学习的方法
并非所有的语音增强方法都是单纯基于神经网络的,一些学者将深度学习的方法与传统方法相结合.Vu等人[89]将DNN与稀疏非负矩阵分解(sparse non-negative matrix factorization, SNMF)结合应用到噪声环境下的自动语音识别(automatic speech recognition, ASR)任务中.如图5所示,作者在已标记数据上对语音和噪声基向量进行无监督SNMF学习,并进行有监督的SNMF特征提取,通过构建神经网络来学习SNMF激活系数之间的非线性映射,使降噪信号的对数谱与目标语音的对数谱之间的均方误差最小.Roux等人[90]将NMF扩展为深层结构,并在各种噪声和混响条件下进行测试,取得了较大的性能提升.
Yang等人[91]提出了一种利用DNN估计自回归模型(autoregressive model, AR)参数的新方法,训练神经网络学习纯净语音与噪声AR模型的参数,利用学习到的AR模型参数构造AR-Wiener滤波器;采用语音存在概率对AR-Wiener滤波器进行了改进,消除了谐波间的残余噪声.Bando等人[92]最近提出了一种半监督语音降噪方法VAE-NMF(variational autoencoder NMF),该方法采用了基于变分自编码器(variational autoencoder, VAE)的语音概率生成模型和基于NMF的噪声概率生成模型,并在未知噪声下取得了比传统DNN监督学习更好的性能.我们对不同信噪比和不同噪声条件下的深度学习算法进行了对比,并比较了他们的PESQ和STOI性能,如表3和表4所示:
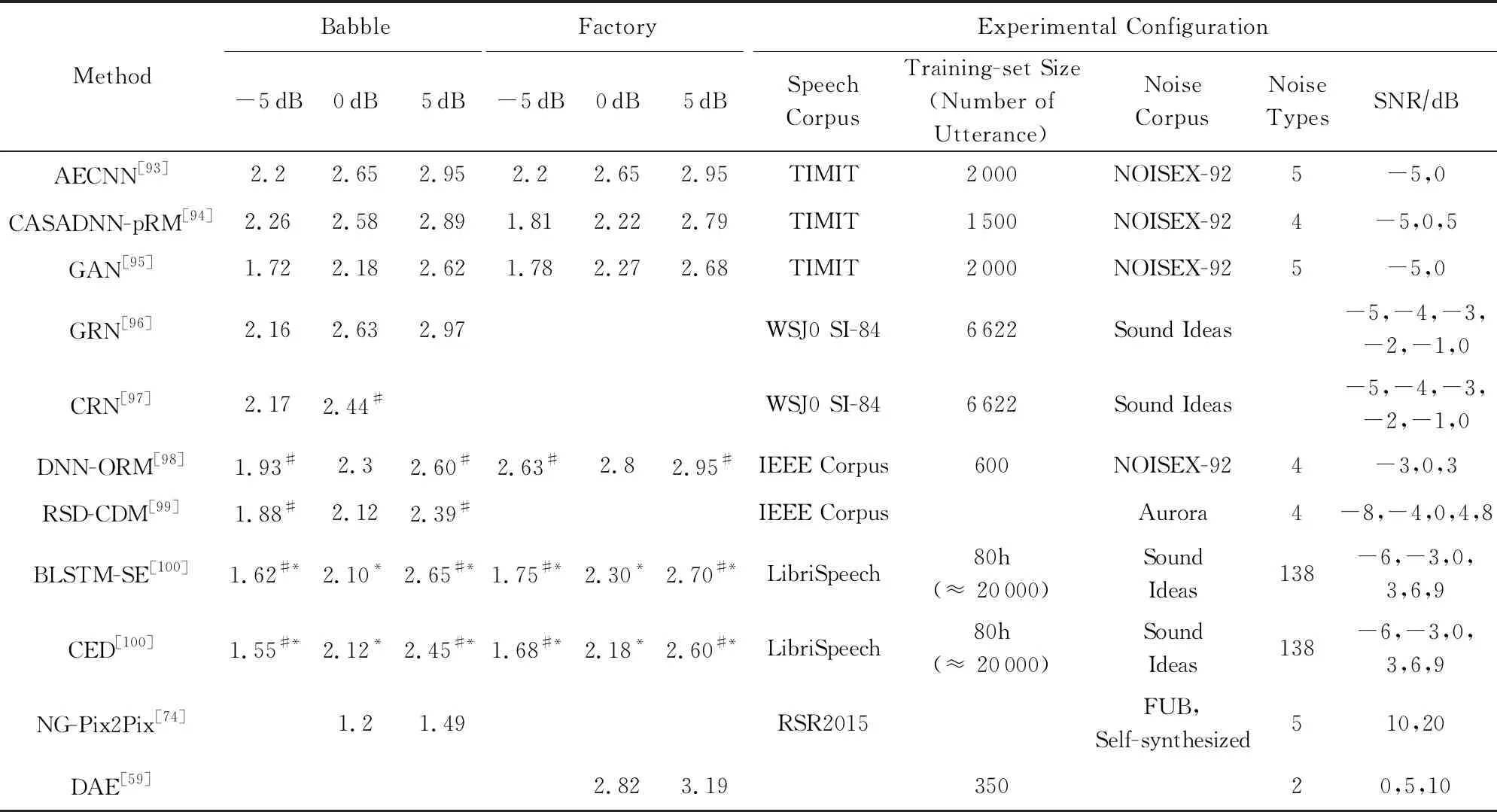
Table 3 Comparison of PESQ Scores in Deep Learning Based Speech Denoising Methods表3 深度学习语音降噪方法的PESQ指标对比
Note: The symbol * comes from our estimation of the graph in the reference paper, and the symbol # comes from the rounding of the data in the reference paper.
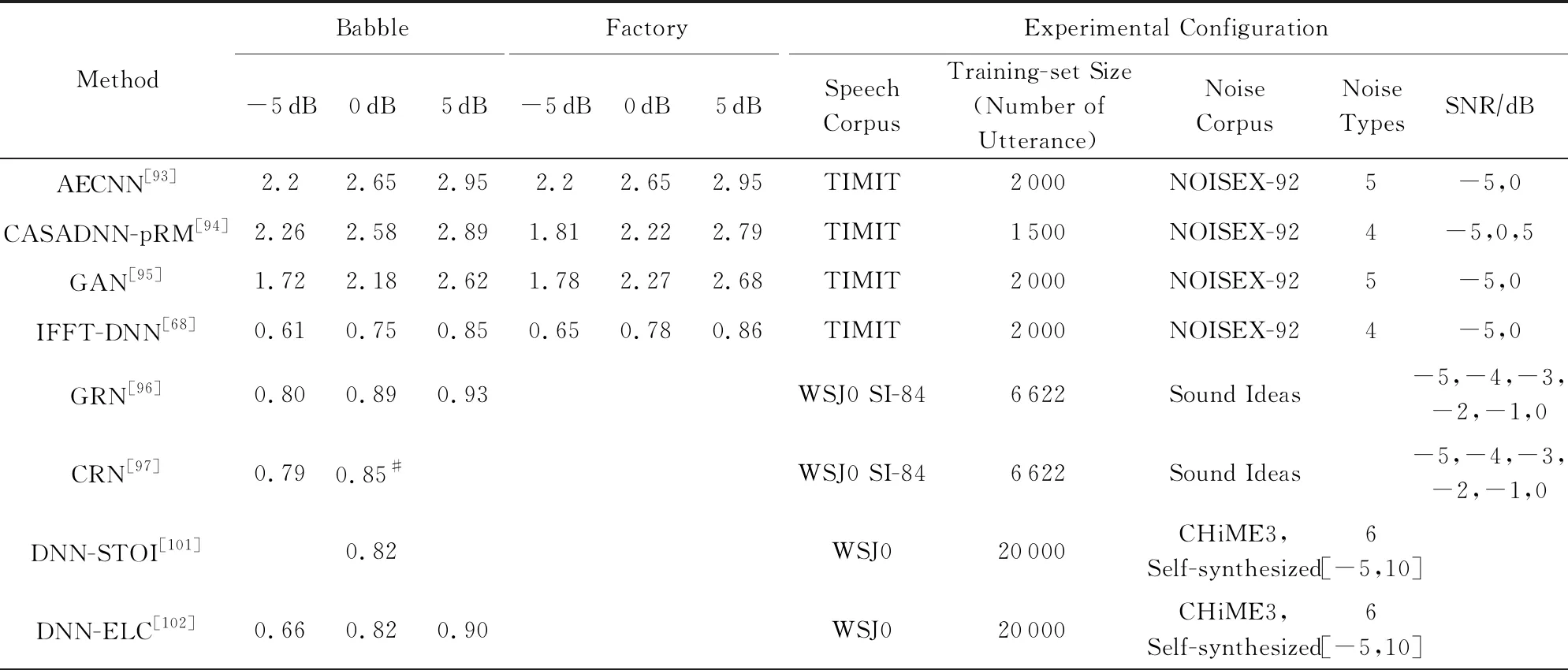
Table 4 Comparison of STOI Scores in Deep Learning Based Speech Denoising Methods表4 深度学习语音降噪方法的STOI指标对比

Continued (Table 4)
Note: The symbol * comes from our estimation of the graph in the reference paper, and the symbol # comes from the rounding of the data in the reference paper.
3 语音去混响
语音去混响的目标是将混响语音转化为无混响语音,是一项具有挑战的任务.混响是声信号从声源通过多条路径传播到人耳或麦克风(接收器)的过程.接收器接收到的信号中,包括未经过任何障碍物反射而直接到达的语音成分,以及随后到达的混响成分.一般从直达语音到达后算起,50 ms内到达的混响,称为早期混响,超过50 ms到达的称为晚期混响[104-105].相比于晚期混响,早期混响反射次数较少,信号强度较高,与说话人和接收器的位置高度相关;晚期混响在经过多次反射后,强度大致呈指数衰减,与位置无关,并且会改变语音的时间包络,对语音质量的影响较大[106-107].
语音去混响技术可概括为3类:1)假设带混响语音由线性系统产生,首先估计声学系统的参数,再得到无混响信号的估计,称作混响消除方法;2)假设带混响语音由加性过程产生,且混响与语音无关,称作混响抑制方法;3)对混响声学系统未知,直接从带混响语音映射到无混响语音,这一类的典型代表是基于深度学习的语音去混响方法[104,106].
3.1 混响消除方法
混响消除方法利用卷积失真模型对信号建模,将纯净语音信号s(n)与线性系统冲激响应a(n)卷积,再加上噪声u(n)形成带混响和噪声的语音x(n),在时域可表示为

(4)
在不考虑噪声干扰情况下,式(4)在经过傅里叶变换并取幅度值后,可表示成矩阵形式:
X=AS,
(5)
其中,S,X分别表示纯净语音与带混响语音的时频域幅值矩阵,矩阵A由冲激响应a转换.
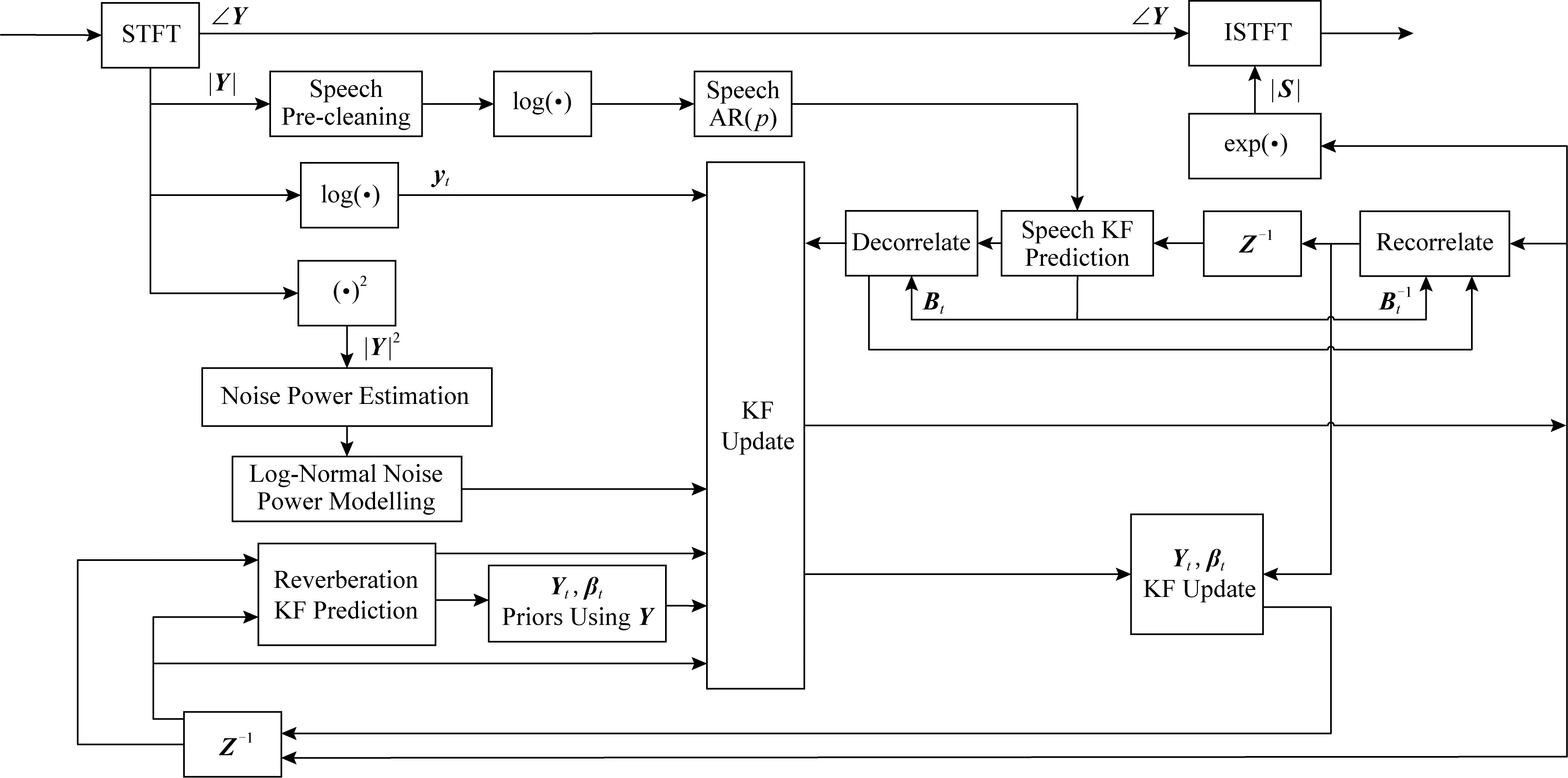
Fig. 7 A method for reverberation suppression图7 一种混响抑制方法[118]
早期混响消除法的一个基本思路是对冲激响应求逆,通过混响的逆过程将语音还原.Neely等人[108]最先开展这方面研究,针对冲激响应恰好是最小相位的情况,设计了一个逆滤波器,在一定程度上消除了冲激响应对语音信号的影响,但在多数情况下冲激响应是非最小相位的,因此该方法有一定的局限性;Wu等人[109]利用逆滤波器解决早期混响的非平坦频率响应使语音频谱失真的问题,但发现不能去除晚期混响,于是采用谱减法进一步处理,实验表明逆滤波器和谱减法都改善了语音质量;Dong等人[110]研究如何提升室内公共广播系统的语音清晰度,提出将Taal等人[111]的感知失真测量语音增强方法(perceptual distortion measure based speech enhancement)方法与Kirkeby等人[112]的快速逆滤波法(fast inverse filtering, FIF)结合,新设计了一种基于Gammatone滤波器的FIF方法,比原FIF方法能进一步减少传输信道的失真,如图6所示.有的工作根据式(3)构建NMF模型以消除混响.Liang等人[113]使用NMF对纯净无混响语音建模,并推导出一种有效的闭式变分期望最大化算法来估计混响和噪声参数.Mohammadiha等人[114]提出的方法使用卷积传递函数的非负近似(non-negative appro-ximation of the convolutive transfer function, N-CTF)来同时估计语音信号和RIR(room impulse responses)的幅度谱.在N-CTF模型中,假设幅度谱中每个频点的STFT系数大小是由纯净语音信号的幅度与RIR的卷积决定,其优势在于无需对RIR相位建模.同时为了利用语音的频谱结构,应用NMF对语音的频谱建模;Zhang等人[115]考虑到在真实环境中,RIR可能较长而导致对其幅度谱的估计难以收敛,于是在结合N-CTF和NMF的基础上,分2阶段分别处理混响和噪声,缩短了处理时间并提升了性能;Mohanan等人[116]提出构建非卷积的NMF模型,这样将更容易在时域或频域中引入新的约束,以及扩展到有加性噪声的场景.
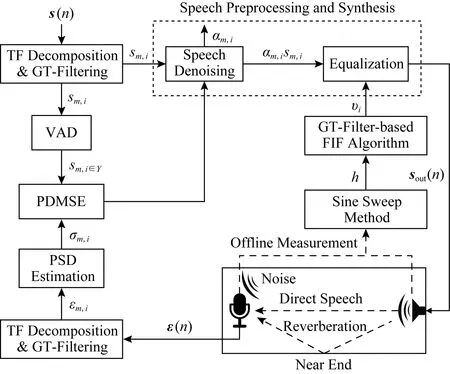
Fig. 6 A method for reverberation elimination图6 一种混响消除方法[110]
3.2 混响抑制方法
混响抑制方法利用加性失真模型对信号建模,纯净语音信号s(n)、混响r(n)与噪声u(n)相加形成带混响和噪声的语音x(n),在时域可表示为
s(n)=x(n)+r(n)+u(n).
(6)
在混响抑制方法中,早期混响因为混响时间极短且对语音质量有益,一般将它假设为纯净语音的一部分.而晚期混响因为失真且混响时间较长,假设其与纯净语音、早期混响无关,是需要被抑制的部分[104,117].
基于以上晚期混响与语音的加性假设和无关假设,语音降噪方法可以应用于去混响.例如Dionelis等人[118]提出将调制域的自适应卡尔曼滤波用于单声道语音降噪和去混响,如图7所示,该算法需要估计语音对数幅度谱的后验分布,滤波器的更新步骤对语音、噪声和混响之间的非线性关系进行建模,实验证明了算法的有效性.Peng等人[15]对噪声与混响同时加以抑制,使用广义奇异值分解(generalized singular value decomposition, GSVD)的方法,提出了一种基于约束最小均方误差(constrained minimum mean square error, CMMSE)的线性预测残差估计(linear prediction residual estimator, LPRE)算法,称作CMMSE-GSVD -LPRE.在含有混响和噪声的实验中,该算法优于谱减法,但仍有混响成分残留,于是他们在线性预测残差域利用了人的听觉掩蔽特性,进一步提升性能.
带有权重的预测线性误差(weighted linear prediction error, WPE)方法早在2008年被提出[119],是目前应用广泛的混响抑制方法,有不少研究是基于此方法[120-121].虽然其数学模型是基于多声道的,但也能有效地应用到单声道.WPE的基本思路是构造滤波器,使用从倒数第K+Δ帧开始的共K帧语音,估计出当前语音帧的混响,再用当前语音减去混响估计,得到对纯净语音的估计,WPE去混响可表示成:
(7)
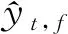
3.3 基于深度学习的语音去混响方法
混响消除和抑制方法都对产生混响的信号模型做出假设,估计模型的参数,恢复出纯净语音.还有一类方法不估计信号模型的参数,直接将带混响的语音转换成纯净语音.近年来,这类方法的主要研究方向是用深度学习模型,通过大量数据训练,建立混响语音到纯净语音的非线性映射.目前为止,涌现出的相关研究已经应用了多种神经网络,并根据语音混响特点,结合其他机器学习方法做出创新.
基于深度学习的语音去混响方法在探索初期主要采用DNN.Han等人[122]提出了基于DNN的去混响算法,首先从混响语音中提取出频谱,采用MLP估计纯净语音的耳蜗谱,最后重构语音信号,取得了比非深度网络的方法更好的结果;随后,Wu等人[123]提出混响时间感知模型,将混响时间作为一个控制参数,引入到特征抽取和模型训练阶段,以适当地选择输入的语音帧长和帧移;Zhao等人[124]针对噪声和混响同时存在的场景,分2个阶段建模,第1阶段用DNN估计掩码的方式去除噪声,第2阶段用另一个DNN直接估计频谱的方式去除混响,第1阶段的输出经过特征提取输入到第2阶段的DNN,在训练过程中,2个DNN是分别单独训练,然后再联合训练的;在重构语音阶段,这项工作没有直接使用带噪带混响语音的相位,而是使用Griffin等人[125]提出的时域信号重构技术;实验结果表明,该方法明显优于单阶段方法.
除了DNN以外,也有研究工作使用CNN[126-127],RNN或LSTM[128-132]等深度学习模型.Guzewich等人[127]提出了一个基于CNN的去混响模型,参考了VGG模型[133]基本思路,用大量小卷积核提升神经网络的能力,包含9个卷积层、4个池化层和最后2个全连接层;实验表明该模型比参考的基线模型更好,并且优于Wu等人[123]提出的DNN模型,该模型在说话人识别任务中有效降低了错误率;考虑到早期混响对语音的可懂度有益,而晚期混响则会降低可懂度[134],Zhao等人[132]提出用LSTM神经网络对混响语音中的长期依赖信息建模,估计出晚期混响成分并从混响语音中减去,而非直接估计出无混响语音;Yu等人[135]提出一个隐含层有CNN和LSTM结构的神经网络模型,用于语音关键词检测的前端去噪和去混响;在Zhao等人[136]提出的神经网络模型中,使用卷积层学习时频域中的局部模式,再用双向循环连接层对相邻语音帧间的动态相关性建模,最后用全连接层估计纯净语音的频谱;Santos等人[129]采用了相似的建模思路,使用了卷积层和循环连接层构建神经网络,还在输入层、隐含层及输出层间加入了残差连接.
值得注意的是,近年有工作开始使用GAN的对抗策略训练去混响模型.Ernst[126]借鉴了全卷积网络在图像处理领域的成功经验,用频谱图表示混响语音信号,使用U-Net[137]学习混响语音频谱到无混响语音频谱的映射.他们利用了CGAN(conditional GAN)[74]训练U-Net,这是CGAN首次应用于去混响.Li等人[138]使用了对抗训练策略,其中语音增强模型是一个包含卷积层、双向LSTM层和全连接层的神经网络,与之对抗的判别器模型同样包含卷积层、双向LSTM层和全连接层.
有的工作将深度学习与其他机器学习方法结合.Lee等人[139]提出的去混响模型包含多个DAE,根据集成学习的思想,每个DAE处理特定声学环境中的语音,用融合函数将各DAE处理结果整合得到去混响语音;刘斌等人[128]提出用LSTM神经网络去混响,发现LSTM估计的纯净语音过于平滑而降低了语音信号的感知质量,于是采用NMF对LSTM的输出做后处理,有效抑制了过平滑问题;Chien等人[140]设计了一种由矩阵分解方法构建的神经网络层,称作STNF(spectro-temporal neural factorization)层,用于提取语音中的时频域特征,STNF的前向计算和反向传播都可视作矩阵分解过程,实验表明STNF层相比于全连接层的去混响效果更好;Raikar等人[141]提出用最大后验估计建模方法,将独立的去混响和降噪过程结合到一起,其中降噪部分使用的是SEGAN模型[88],其输入是去混响的结果,其去噪的结果又会提升混响卷积矩阵的估计准确率.表5中是不同去混响方法在不同的混响时间(T60)下的PESQ,STOI以及语音混响调制能量比(speech-to-reverberation modulation energy ratio, SRMR)指标统计.SRMR是一种非侵入式无需纯净语音进行计算的指标,用于评估语音质量与可懂度,它的值越高表示去混响的效果越好.

Table 5 Comparison of Scores in Speech Dereverberation Methods表5 语音去混响方法的指标对比
Note: The symbol * comes from our estimation of the graph in the reference paper and the symbol # comes from the rounding of the data in the reference paper.
4 实验与评估
本节介绍了在语音增强实验及评估中的一些必要内容,主要包括数据集、特征和评估指标.语音增强实验都需要根据实验目的准备特定的数据集,并使用数据集对算法的有效性及性能进行检验.对大多数学习算法而言,进行学习前需要先从数据中提取更易于学习的特征,因为直接学习原始数据往往是比较困难的.此外,对实验结果进行评估也是必要的,一方面可以从评估分数判断实验结果的好坏,另一方面不同算法的实验结果很难直接进行比较,在进行评估后就可以方便地对比每个算法的性能.
4.1 数据集
数据集是语音增强实验的关键部分,作用于模型训练、验证、测试的整个过程.通常,数据集的大小和数据的多样性对模型的性能及泛化能力有很大影响.在语音增强中,数据的多样性包括语料的多样性、噪声的多样性、信噪比的多样性、说话人的多样性.经实验证明[61,142],在一定范围内,随着数据集数据量的增加和数据多样性的提高,语音增强模型的噪声、信噪比、说话人甚至是语言的泛化能力都有所提高.
在语音增强中音频数据集一般可以分为纯净语音数据集、噪声数据集以及带噪语音数据集,实验大多会使用公开数据集,但此外一些有特殊需求的研究者会自行构建数据集.当实验需要用到带噪语音时,可以使用已有的带噪语音数据集,也可以使用语音噪声混合工具,如滤波与噪声添加工具(filtering and noise adding tool, FaNT)[143]将纯净语音和噪声混合,通过调整参数得到特定信噪比的带噪语音.在进行去混响实验时,主要通过将语音信号与不同混响时间的房间脉冲响应RIR进行卷积得到混响语音信号.语音增强中常见的音频数据集如表6所示:

Table 6 Common Voice and Noise Datasets表6 常见语音和噪声数据集
4.2 特 征
语音信号是一种非平稳、时变的随机过程,很难直接对其学习,因此往往需要进行特征提取,而提取不同的特征会对增强性能有很大的影响.数十年来,为提高语音质量及可懂度,学者们提出了多种语音特征,这些特征都有各自的优势和不足.在单声道语音增强的早期研究中,主要使用基于基音的特征[157]和幅度调制谱(amplitude modulation spectrum, AMS)[158],这些特征提取过程相对简单,但表示能力不足.接着逐步提出了更多单声道特征,包括梅尔倒谱系数(mel-frequency cepstral coefficient, MFCC)[159]、感知线性预测(perceptual linear prediction, PLP)[160]、相对频谱表示(representations relative spectra, RASTA-PLP)[161],这些特征虽然在一定程度上提高了语音增强性能,但单个特征还是难以取得很好的效果.针对这一问题,Wang等人[159]使用Group Lasso特征选择器,得到了1组互补的特征组合,包括AMS,RASTA-PLP,MFCC,这个特征组合在多种条件下相对单个特征显著地提高了增强性能,在很多研究中得到了应用.同时,短时傅里叶变换幅度谱和短时傅里叶变换对数幅度谱也常用于语音增强,且由于高频部分幅度较小,故对数幅度相对幅度更能凸显高频成分.然而有研究[162]发现,短时傅里叶变换幅度谱的性能比短时傅里叶变换对数幅度谱略好.此外,学者们还在Gammatone滤波的基础上提出了Gammatone特征(Gammatone feature, GF)、Gammatone倒谱系数(Gammatone frequency cepstral coefficient, GFCC)[163]、Gammatone调制频谱(Gammatone frequency modulation spectral based cepstral, GFMC)[164].随后,又有学者对已有的特征进行研究与改进,在MFCC的基础上提出了Delta倒谱系数(delta spectral cepstral coefficients, DSCC)[165]、相对自相关序列MFCC(relative auto-correlation sequence MFCC, RAS-MFCC)[166]、自相关序列MFCC(auto-correlation sequence MFCC, AC-MFCC)[167]、相位自相关MFCC(phase auto-correlation MFCC, PAC-MFCC)[168].陈纪同等人[169]提出了多分辨率听觉谱(multi-resolution cochleagram, MRCG)特征,它同时计算出4种不同分辨率的倒谱,从而可以同时提取到局部性信息和整体性信息,现已成为最常用的特征之一.
下面对一些常见的特征进行介绍:
1) MRCG
MRCG由4种不同分辨率的倒谱组成,高分辨率倒谱捕捉局部信息,3个低分辨率倒谱捕捉不同尺度的上下文信息.为得到MRCG,首先将信号进行64通道的Gammatone滤波得到一个听觉谱,称作CG1,并在每个时频单元进行取对数操作;类似地,可用200 ms的帧长和10 ms的帧移计算得到第2个听觉谱,称作CG2;其次使用一个长为11帧和宽为11频带的方形窗对CG1进行平滑,得到第3个听觉谱,称作CG3;和CG3的计算相似,使用23×23的方形窗对CG1进行平滑,得到第4个听觉谱,称作CG4;串联CG1,CG2,CG3,CG4得到一个64×4的向量,即为MRCG.
2) MFCC
MFCC即梅尔倒谱系数,首先对输入信号作分帧操作,经验上取10~30 ms帧长,5~15 ms帧移;其次对每一帧进行加窗处理,一般使用汉明(Hamming)窗;然后进行FFT计算得到对应的频谱,再将频谱通过Mel滤波器组转换为梅尔域,最后在Mel频谱上进行倒谱分析,得到MFCC.
3) GF
该特征由Gammatone听觉滤波得到,首先用Gammatone滤波器组对信号进行处理,然后对每个滤波输出以100Hz的频率进行采样,最后采样结果通过立方根操作进行幅度压缩得到GF.
4) GFCC
GF特征一般由64个频率成分组成,但在实际系统中由于GF特征矢量的维度比较大,计算量也较大.此外,由于相邻的滤波器通道有重叠的部分,导致GF特征矢量相互之间存在相关性.因此为减小GF特征矢量的维度及相关性,对每一个GF特征矢量进行离散余弦变换(discrete cosine transform, DCT)得到GFCC.实验表明,前若干维及最后若干维的GFCCs系数对语音的区分性能较大,因此一般取前26维的GFCC系数作为特征.
5) PLP
PLP即感知线性预测系数,它能够最大限度地消除说话人不同带来的影响,同时可以留下关键的共振峰结构,由于该特征与语音内容比较相关,因此常用于语音识别.
4.3 评估指标
评估实验结果需要设定评估指标,不同的指标从不同角度对实验结果进行评分.语音增强任务有多种评估指标,这些指标按评估方法可以分为主观方法和客观方法.主观方法的评估主体为人,以人耳感受为判别标准,带有一定的主观因素;客观方法是指计算机直接以一定的计算方法来为语音评分,在实验中多采用客观方法.从评估目标级别的角度可分为信号级别和感知级别,信号级别的指标目的是量化信号增强或干扰降低的程度,如信噪比(signal to noise ratio, SNR);而感知级别的指标更关注语音增强对于语音的可懂度和感知质量的提高,如PESQ,STOI.表7~9中分别列举了语音增强中的客观指标、主观指标以及语音去混响的指标:
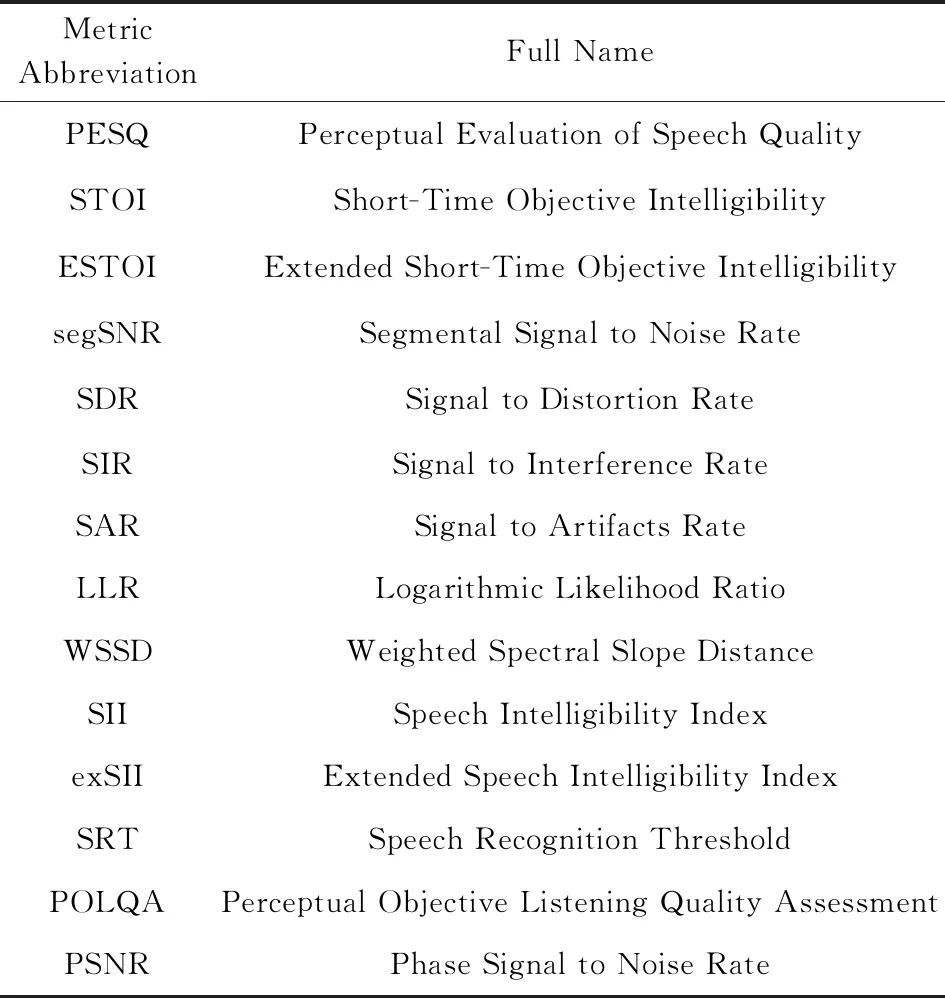
Table 7 Speech Enhancement Objective Evaluation Index表7 语音增强客观评估指标

Table 8 Speech Enhancement Subjective Evaluation Index表8 语音增强主观评估指标

Table 9 Speech Dereverberation Evaluation Index表9 语音去混响评估指标
对4个常用的评估指标进行详细介绍:
1) 平均主观意见分(mean opinion score, MOS)
MOS[170]常用于衡量通信系统语音质量,由人对语音质量的真实反映得出,但其受测试条件的限制和测试人员主观因素的影响,且不满足实时性要求.由不同人分别对原始语料和经过系统处理后失真的语料进行主观感觉对比,最后求平均得到MOS值,MOS值取值范围为1~5分.
2) PESQ
PESQ指标[171]的设计目的是评估电话网络和编解码的语音质量,与MOS高度相关,侧重于评估语音的清晰度.它是感知分析测量系统(perceptual analysis measurement system, PAMS)和感知语音质量增强版PSQM99(perceptual speech quality measure 99)集成的结果,应用范围广泛,包括模拟连接、编解码器、报文丢失、可变延迟.同时它是国际电信联盟电信标准化部门(ITU-T) P.862建议书提供的客观MOS评估方法.PESQ值介于-0.5~4.5之间,但是对于正常的主观测试材料,该值介于1.0(差)和4.5(无失真)之间.在极高的失真度下PESQ值可能会低于1.0,但这种情况非常少见.
3) STOI
STOI指标由Taal等人[172]于2011年提出,它是基于纯净语音与带噪语音的时间包络相关系数计算得到,在实验中表现出与语音可懂度的高度相关性.计算STOI包括3个步骤:首先去除静音帧(silent frames),即删除能量少于50 dB的帧,因为静音对语音可懂度没有影响;其次,对信号进行基于DFT的1/3倍频带分解,汉明窗的长度为25 ms,256个频率覆盖,频率范围为0~5 kHz;最后通过相关过程计算输出STOI.STOI取值范围为[0,1],且与主观语音可懂度正相关,即值越大表示语音可懂度越好.
4) 分段信噪比(segmental SNR,segSNR)
segSNR指标主要用于语音增强、语音编码后的测试.由于语音信号是非平稳信号,有很多低能量和高能量区域,并且这些区域与语音的理解密切相关.segSNR不计算整段语音的信噪比,而是计算短期(15~20 ms)SNR的平均值,因此能够反映语音的局部失真水平.与SNR相比,segSNR与MOS的相关度更高.
5 问题与挑战
在研究者们的努力下,传统方法或深度学习方法的语音增强算法性能都得到了一定提高.但语音增强领域仍存在着一些问题和挑战,包括低信噪比环境下的语音增强问题、增强算法的泛化问题、相位失真问题、测度不匹配问题等.
5.1 低信噪比环境下的语音增强问题
在低信噪比环境中实现有效且稳定的语音增强仍然面临着挑战.在-5 dB环境下,语音功率不及噪声功率的1/3,语音幅度常常只有噪声幅度的一半.短时傅里叶变换后,幅度谱以噪声为主导,使得一些基于掩蔽的模型失去了优势,常用的IBM会把噪声与语音混合的部分划分为噪声而全部过滤,这种情况下基于掩蔽的模型的效果往往不如基于映射的模型.
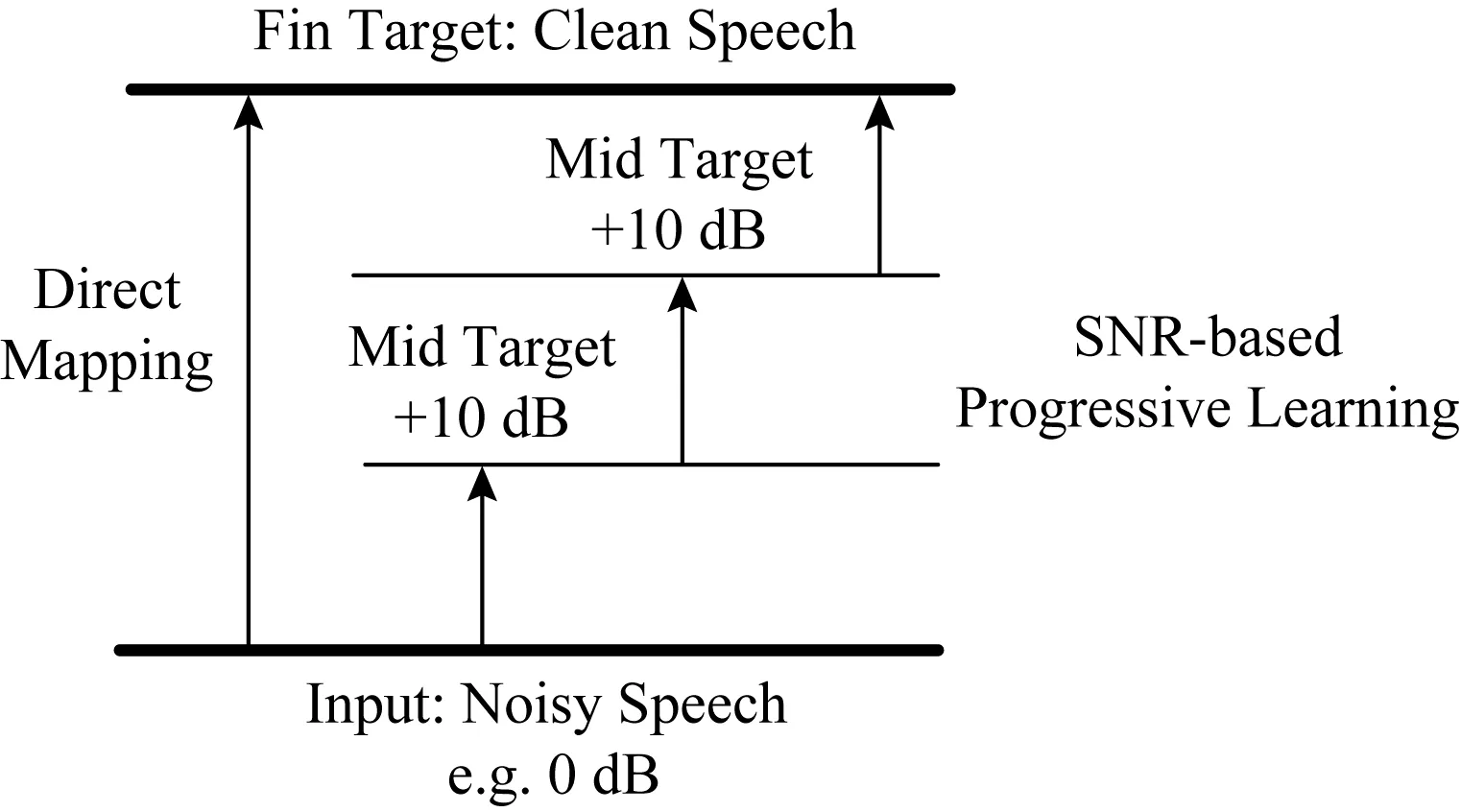
Fig. 8 The PL model for speech enhancement[174]图8 语音增强的PL模型[174]
面对低信噪比条件下的复杂环境,PL(prog-ressive learning)模型及其与多任务学习和集成学习结合的方法进入了研究者的视野[72,173].PL模型与普通模型的差别是它把一个学习目标拆分为多个子目标,每个子目标相较前一个目标更加接近最终目标.如图8所示,处理SNR为0 dB的信号的过程可以拆分为先达到10 dB、再到20 dB、最后获得目标纯净信号3个阶段.实验证明,PL模型比一般模型更加适合训练海量数据或复杂特征.一种解释是一般模型训练海量数据时,随着训练数据的增加,模型发生了灾难性的遗忘,丢失了之前学到的部分信息.复杂的低信噪比环境下,一般模型也更容易受到影响.而PL模型的结构可以使之按阶段保留过去学习到的信息,最后把每个阶段的信息集成到对最终目标的训练中去.因此,在低信噪比或多信噪比环境下,PL模型可以学习并保留更多特征,泛化性更强.然而,如何选择中间阶段的训练目标是PL模型要解决的问题,简单地把训练目标指定为一个固定SNR的语音,可能无法发挥模型真正的效能.而在结合多任务学习的PL模型中,如何选择训练目标也是一个问题.研究者可以探索一种产生对信噪比环境自适应的阶段目标算法,也可以选择其他的评估指标.
在结合多任务的模型中,模型使用了不同滤波方法提取的声音特征,MFCC和GFCC是2种提取声音特征的方式[175],提取后的特征会存在相似或者不同的地方,研究者可能需要选择具有互补特征的训练目标.Fu等人[71]将SNR感知结构和语音增强模型相结合,提出了2个基于CNN的模型,它们在低信噪比条件下取得了更好的效果.前一个模型学习环境中的SNR级别,在目标函数中加入环境真实的SNR值,形成一个多任务学习模型.模型在降噪的同时还会判断环境的SNR,以此适应不同的环境;后一个模型先评测环境的SNR.然后根据不同的SNR,选择不同的降噪模型.实验表明,这2个模型性能都优于简单CNN模型,这说明对于不同的SNR环境,可以通过加入SNR评测的方法来提高模型能力.而且实验中还发现后一个模型在12 dB和-12 dB的SNR环境下测得的一些指标优于前一个模型,这意味着对应不同SNR环境使用不同的语音增强模型可能得到更好的结果.
5.2 模型算法泛化问题
基于深度学习的语音增强模型在面对未知环境时,性能会明显恶化.模型的泛化能力不良一直是个难题.语音增强算法的泛化能力可以分为3个方面:对未知种类噪声的泛化能力、对未知信噪比环境的泛化能力和对未知说话人的泛化能力.一种简单有效提高模型泛化能力的方法是在大量不同的噪声数据集上训练模型,而且使用RNN模型比DNN模型更加有优势[96].近几年,Park等人[176]提出了基于CNN编码的语音增强模型,在未知噪声和未知信噪比环境下表现较好.同时,利用编码CNN或扩张CNN模型也能提高对未知说话人语音增强的能力[96-97].
ASAM[177]提供了另外一种提升增强模型对噪声的泛化能力的思路.ASAM是一个利用注意力机制和长期记忆的语音分离模型,它利用双向LSTM对混合语音和纯净语音的幅度谱作高维映射.再将纯净语音幅度谱的映射融合为一个向量,表示为纯净语音的特征,存入长期记忆中.然后利用该段记忆来关注混合语音中属于同一说话人的映射的向量.长期记忆结构中存在一个存储空间来临时保存未知说话人语音的记忆.这是一个语音分离模型,但可以把要移除的语音替换作噪声.在测试阶段,把捕获的不含语音的未知噪声看作未知语音输入模型,将其特征存入模型的长期记忆中.这类似一种实时获取噪声特征的方法.此后可以利用不同噪声的特征结合语音特征来增强语音.
5.3 相位失真问题
目前常用的基于深度学习的语音增强过程是先对带噪语音计算短时傅里叶变换得到幅度谱和相位谱,再对幅度谱进行处理,最后将产生的幅度谱与原始带噪信号的相位信息合成纯净语音.但是近些年,研究者开始注意到相位信息在语音增强中的重要性.
除了利用相位信息的掩蔽层的模型[48],研究者探索更好的方法去使用带噪信号的相位重构纯净语音信号的相位.在频域的无监督语音增强的相位重构方法中,有2类方法:基于振幅的方法和基于模型的方法.基频法是一种基于模型的方法,最近研究者提出利用基频的方法[178-185].短时傅里叶变换相位改良法[182]是一种先进的相位重构方法,但该方法会引入额外的蜂鸣声.而Wakabayashi等人[185]利用了相位失真特征,抑制了额外的声音,在PESQ上表现超过短时傅里叶变换相位改良法[181],但在STOI指标上没有有效地提高.
一些研究者直接在时域上利用CNN处理带噪语音[84,93],这样避免了原始带噪信号的相位的使用,提升了一定的模型性能.但是这种做法只将时域上的信息输入神经网络,未利用神经网络处理频域信息,或忽略了信号在频域上的信息,这样可能丢失了一部分必要的纯净语音信息.将模型结合多任务学习的方法可能会有进一步提高.
5.4 语音增强算法测度不匹配问题
语音增强的一个目标是增加语音的可懂度,把错字率(word error rate, WER)看作评估语音增强算法能力的指标可能更为直接.但这种做法要结合语音识别系统的测试或人工识别测试,评估难度较大.简单地计算增强语音的SDR,SIR,SAR指标可以避免语音识别中繁杂的流程,但同时这些指标存在与语音可懂度的相关度不够的问题.于是后来出现了一些匹配人类听觉感知方法的指标,如STOI.
同时,不匹配的问题也存在于深度学习增强算法所常用的损失函数MSE(mean-square error).一个好的损失函数可以提高模型的性能.MSE简单地计算预测语音和正确语音波形或幅度谱的欧氏距离,有时不能完全反映增强语音的质量.因此,出现了新的基于不同的语音评估指标的损失函数.STOI是目前评估增强语音可懂度的重要指标,它接近人类评估语音方式.但一般使用的损失函数MSE与这种方式不匹配,在优化模型时不一定能改善STOI[186].如何改良损失函数以匹配STOI的运算方式是最近的一个研究点.有研究者以提高语音有限的SNR为目标来训练模型,却取得了更好的效果,由此发现人类对语音质量的评估与损失函数MSE存在不匹配问题[103].Zhao等人[186]提出了以STOI指标为训练目标的损失函数:
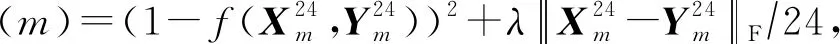
(8)


Table 10 Performance Comparison of Models Using STOI and MSE Loss Functions
Note: The bold indicates better performance under the same metric and SNR.
6 结束语
语音识别被认为是人工智能未来发展的重要方向之一,而语音增强是其中一项核心关键技术,此外它也能应用于语音通话、电话会议、场景录音、军事窃听和听力辅助等场景,因此具有重要的理论研究与实际应用价值.本文从方法、数据集、特征、评估指标等方面,对单声道语音增强(包括降噪与去混响)研究工作的发展现状进行了全面调研和深入分析,并对该工作面临的重要挑战和关键问题进行了总结.尽管国内外研究人员已经提出了多种单声道语音增强方法,深度学习的引入也为该领域研究带来了新的突破,但已有工作还存在泛化性差、相位失真、测度差异等问题,特别是在低信噪比环境下的应用效果还很不理想,所以这仍是一个充满挑战、值得研究的领域.
