生物特征识别模板保护综述
2020-06-08王会勇唐士杰王玉珏李佳慧
王会勇 唐士杰 丁 勇 王玉珏 李佳慧
1(桂林电子科技大学数学与计算科学学院 广西桂林 541004)2(桂林电子科技大学电子工程与自动化学院 广西桂林 541004)3(桂林电子科技大学计算机与信息安全学院 广西桂林 541004)4(广西密码学与信息安全重点实验室(桂林电子科技大学) 广西桂林 541004)
随着互联网与电子商务的发展,日常生活中有越来越多的场景需要对用户进行身份鉴别,如机场安检、登录银行系统、解锁手机等.
传统的身份鉴别手段主要有2种:1)根据持有物,如各种证件;2)根据用户了解的信息,如语音口令或数字密码.但这2种方式都存在明显缺陷,如证件容易丢失、密码容易忘记等.生物特征识别(bio-metric authentication, BA)技术能够有效解决上述问题,因而在近年来得到快速发展与应用.
生物特征识别是指“为进行身份识别而采用自动技术对个体生理特征(如指纹、掌纹、虹膜、人脸、脑电波等)或个人行为(如步态、字迹、声音、键盘敲击习惯等)特点进行提取,并将这些特征或特点与数据库中已有的模板数据进行比对,从而完成身份认证或识别的过程”[1].
自20世纪70年代指纹识别技术被成功应用[2]以来,BA技术获得了快速发展,目前已在世界范围内得到广泛应用.但与此同时,BA系统的数据安全与隐私保护问题却一直没有得到良好解决,成为阻碍该技术获得快速推广应用的一个主要障碍[3].
世界范围内已经发生了多起由生物特征数据泄露或隐私泄露引起的安全事件,引起了众多关注.例如在2019年2月美国旧金山市公布了一项立法法案,使得该市成为美国首个禁止人脸识别技术的城市,其主要理由是该技术可能威胁到个人的隐私信息安全,同时存在种族歧视嫌疑[4].
生物特征信息泄露的后果是非常严重的.这是因为生物特征具有唯一性和不可更改性,一旦泄露,被窃取的生物特征几乎永远无法再用,其危害性比丢失身份证等传统身份鉴别媒介大得多.
近年来,众多研究者对BA系统的数据安全与隐私保护问题进行了研究,重点聚焦于生物特征模板保护工作.也出现了多篇综述性文献,但很多综述文献的内容不系统,或者比较陈旧,甚至存在冲突内容.因此,本文拟对近年来出现的针对BA系统的模板攻击及其应对性技术文献进行综述,希望为相关研究者提供有价值的参考.
本文首先概述BA系统面临的安全性与隐私保护问题,主要包括BA系统的一般框架、安全性与隐私保护的内涵,以及当前BA系统面临的主要风险;然后介绍国内外学者在应对BA系统面临的主要威胁——生物特征模板攻击方面的研究进展与代表性技术方案;最后对此类研究面临的困难和解决思路提出展望.
1 BA系统的数据安全性隐私保护
1.1 BA系统的一般架构
一个典型的BA系统是带有生物特征采集设备的访问控制系统[1],基本工作模式包含注册与比对2个过程.在注册阶段,用户通过采集设备读取生物特征,并生成模板特征存入数据库;在比对阶段,系统调用采集设备对用户的相应生物特征进行再次采集并生成新鲜特征,然后与数据库中存储的模板特征进行比对,根据2个特征的相似度确定用户身份.
根据识别的任务和目的,BA系统可以分为2类[5](如图1所示):验证系统(verification)和搜索(或检索)系统(identification),而“生物特征识别”一般是对这2类任务的统称.

Fig. 1 Authentication and search task flow of BA system图1 BA系统的认证与搜索任务流程
验证系统的任务是对用户提供的身份进行核实,以确定该用户的身份是否与其声称的身份一致.此类系统常被用作某些系统的准入机制(如利用指纹认证解锁手机和门禁系统等),一般需将用户的特征数据与数据库中的特定记录进行1对1比对.而搜索系统的任务是在不了解用户身份的情况下利用其生物特征在数据库中查找其身份,通常需要将用户数据与数据库中的多个记录进行1对N比对,因而工作量和难度一般比验证系统大.此类系统大多用于被动方式,如在公共环境下对特定人员的身份进行甄别等.

Fig. 2 The main connotation of individual privacy图2 个体隐私的主要内涵
BA系统的决策结果一般有2种[6]:合法用户与非法用户(或匹配与不匹配).这2种决策过程都可能出错或不出错,因而共有4种可能的结果.通常用错误接受率(即假冒者被判定为合法用户的概率)和错误拒绝率(即合法用户被判定为假冒者的概率)来表征BA系统的正确性.
1.2 数据安全与个体隐私的内涵
在信息科学领域,数据安全是一项基本要求,其基本内涵是保证只有授权用户才能使用数据.而个体隐私安全则是近年来随着云计算的发展逐渐产生的一种新需求,基本内涵是保证数据只能被设定的个体用于设定的目的.Campisi[7]认为:个体隐私的内涵主要包括决策隐私、空间隐私、故意隐私及信息隐私4个方面,如图2所示,其中信息隐私是主要考虑.
1.3 BA系统面临的安全与隐私风险
在BA系统中,生物特征本质上是一种便携式“密钥”.但这种密钥却面临着比传统密钥更大的风险,因为“生物特征不是秘密”[8],很难杜绝数据泄露.
Ratha等人[9]、Tuyls等人[10]和Campisi[7]认为BA系统面临的主要风险(如图3所示)来自3个方面[11]:
1) 原始数据泄漏.有些生物特征无法完全保密,如人脸、声音、体态等,很容易被攻击者秘密采集.其他一些生物特征(如虹膜、静脉等)的窃取难度虽然稍大,但也很难杜绝恶意采集.而泄露的原始数据可能成为伪造攻击(spoofing)的工具.
2) 模板攻击.当前的很多BA系统无法提供对用户生物特征模板的有效保护,在数据传输或保存过程存在模板泄露风险,而从泄露的模板恢复出原始数据是可能的.
3) 联系攻击.如果用户使用同一个生物特征登录多个BA系统,其存储在不同系统中的特征模板可能是相同的或可以匹配成功的.这可能允许攻击者利用某个系统的新鲜模板登录另一个系统,或从不同模板之间的联系推测出有效模板或用户身份.

Fig. 3 Attacking points and patterns in general BA systems图3 一般BA系统的攻击点与攻击模式
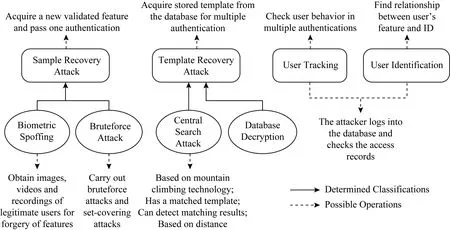
Fig. 4 Classification of attacks on BA systems图4 针对BA系统的攻击分类
Pagnin等人[5]对上述攻击进行了具体阐述(如图4所示).其中,样本恢复攻击的目的是获得能够通过认证的用户特征,以实施欺诈攻击或暴力破解;模板恢复攻击旨在获得数据库中存储的用户模板;而对用户进行追踪和识别的主要方法是记录并分析用户在不同时间登陆BA系统或登录不同BA系统时的身份与模板的对应关系,以找到模板与用户的联系.
与生物特征使用相关的隐私担忧主要有3种[5,7]:
1) 未经允许收集和分享生物特征;将生物特征用于未授权目的(即功能蠕变).
2) 利用生物特征推测个体状况,如种族、性别、健康状况.
3) 利用生物特征精准追踪个体等.
1.4 针对BA系统的保护工作概述
近年来有众多学者参与到BA系统的保护工作中,积累了丰富的研究成果:有旨在研究现有BA系统脆弱性的工作[12-17];有构建新的保护方案和技术的论文[18-21]和书籍[7,22-25];也有旨在讨论商业系统客观评估通用框架[26-27]的文献.
同时,出现了一些面向生物特征和一般信号处理的教程、会议[28-29]和讲习班以及以研究脆弱性评估为目标的竞赛组织[30-31]和评估团体与实验室[32-33]等.
BA系统面临的安全与隐私威胁[34-35]主要来自于间接攻击和直接攻击.间接攻击是在系统内部执行的,如黑客或内部人员操纵特征提取器或模板生成器、修改模板数据库等,可以通过多种措施来预防,如防火墙、防病毒软件、入侵检测和加密等,工作重点在于保护生物特征模板的安全性.直接攻击主要是指生物特征欺诈(spoofing),其主要攻击目标是传感器,因此很难用数字保护机制来对抗.
2 生物特征模板攻防技术
通常认为,对生物特征模板的未授权访问是对用户数据的最大威胁[10],因为安全的生物特征模板存储方案可以抵抗针对信道和数据库的多种攻击.因此,构建安全高效的生物特征模板存储方案(包括保密比对过程)是保护BA系统安全性与隐私性的关键.
由ISO/IEC 24745标准[36]和文献[37]可知,一个良好的生物特征模板存储方案应具有4个特性:
1) 可更新性.即能够撤销被泄露的生物特征模板,并基于相同的生物特征生成新的模板.
2) 多样性.重新生成的生物特征模板不能与被撤销的(来自同一生物特征的)模板成功匹配.
3) 安全性.应保证从生物特征模板获得原始生物特征数据是不可能的,至少在计算上是复杂的.
4) 模板存储方案不应该使生物特征识别性能(如错误拒绝率、错误接受率)有较大下降.
2.1 针对生物特征模板的攻击
Pagnin等人[5]认为:在不破坏BA系统的前提下,针对BA系统的模板恢复攻击主要有2种方式.
1) 利用爬山技术[38]实施的中心搜索攻击.这种攻击需要3个条件:攻击者拥有一个已经匹配成功的生物特征模板;攻击者能够得到每次测试的结果,即匹配是否成功;比对过程是基于距离的.
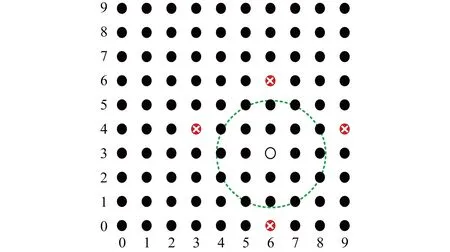
Fig. 5 Central search attack towards biometric template图5 针对生物特征模板的中心搜索攻击原理
设数据库中存储的模板b对应点(6,3),而已经通过认证的一个模板b′对应点(6,4),显然虚线圆圈内的点是能够匹配成功的点.敌手从点b′(6,4)开始匹配实验,若成功则将第1个组件值加1(向右移动1),并继续实验.当被拒绝时,即实验到点(9,4)(最右侧带乘号的点)时,敌手会知道上一个实验点是接受圈内该方向的最后一个点.然后敌手重新从点b′开始,向左侧重复实验,直到被拒绝.随后,敌手对第2个组件值做相同的测试(上下方向).最后,敌手能够找到接受圈的4个边界点的坐标,从而能够计算出其中心的坐标,即找到数据库中存储的生物特征模板的数字表示.
这种模板恢复攻击非常有效,因为它需要的匹配尝试次数与生物特征向量的长度呈线性关系[39].
2) 获得数据库的控制权并使用暴力攻击解密模板.由于抵抗暴力攻击是所有安全模板存储方案的基本目标,因而简单暴力攻击成功的可能性很小.
2.2 模板保护技术
近年来,学者们提出了多种生物特征模板保护技术(biometric protection, BP),也出现了多个综述性文献,但有些文献对某些技术、方案的命名和分类存在分歧,也有部分文献的系统性较差.经过整理,我们认为现有的BP技术可分为2类:基于特征变换的方法和基于特征加密的方法,如图6所示:
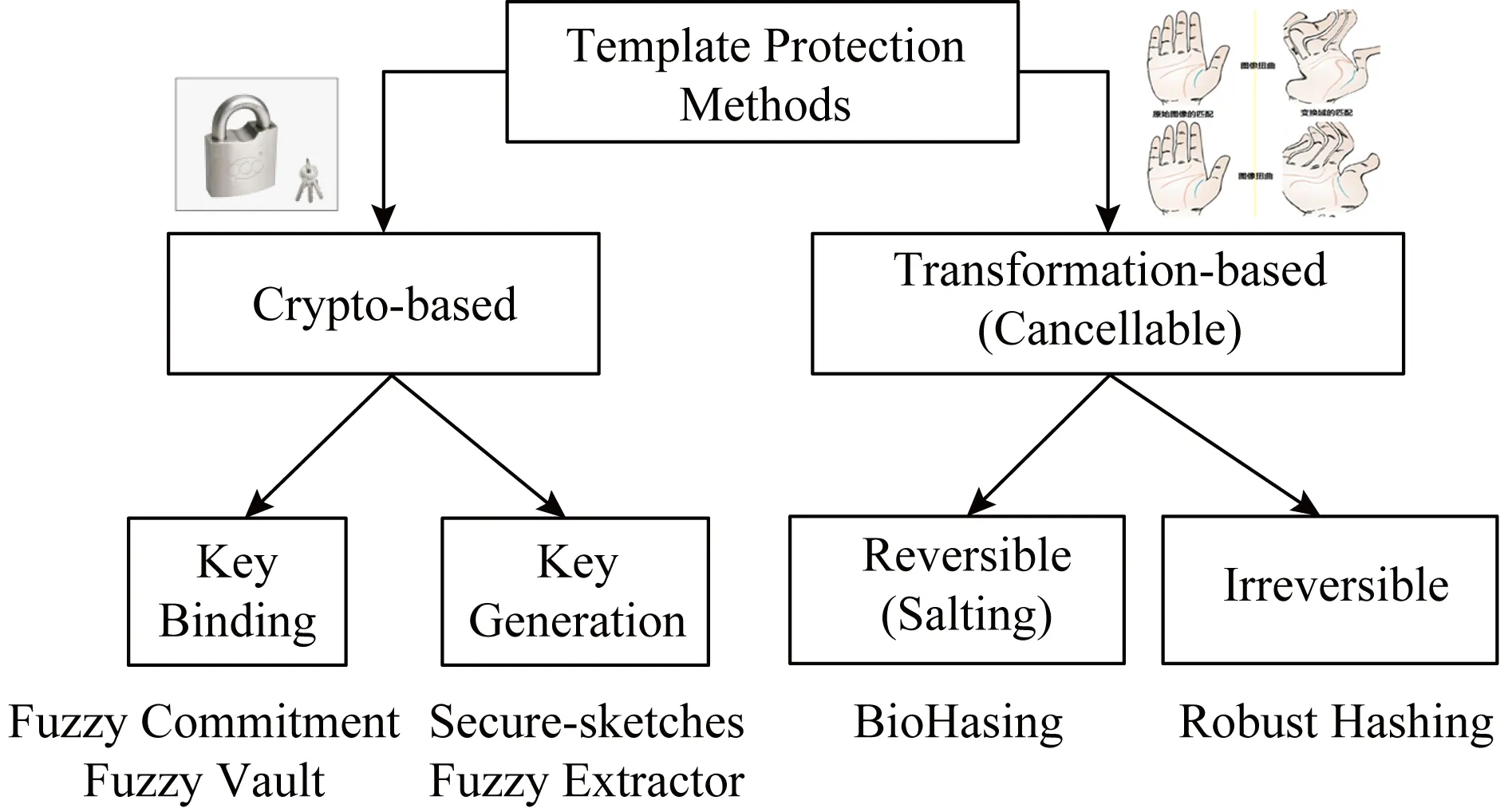
Fig. 6 Classification and representations of BP technologies 图6 BP方法的分类与代表性技术
2.2.1 基于特征变换的模板保护方法
此类方法也被称为可撤销(cancellable)的模板保护方法[39],需要用某种变换函数对生物特征或其模板进行变换,并在变换域进行匹配,如图7所示.根据所用的变换是否可逆,此类方法又可以分为2类:
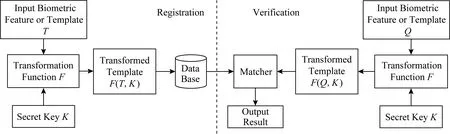
Fig. 7 Flow of transformation-based BP methods图7 基于特征变换的模板保护方案流程
1) 基于可逆变换的方法.此类方法被有些文献称为加盐法(salting)[40]或生物特征散列法(bio-hashing)[39,41],是Jin与Teoh等人[42]于2004年首次提出的,并被用于指纹识别.随后,该类算法被应用于人脸、掌纹、虹膜、指纹、签名等认证过程.
生物特征散列法的主要优点是错误接受率较低、可移植性高、模板可更换,主要缺陷在于安全性能不足,因为在此类方案中模板的安全性取决于对变换函数参数的保护.Lumini等人[43]指出:如果用户密钥丢失,生物散列法的整体效率和安全性将有很大下降.
Jin等人提出的用于指纹认证的生物散列法[44]的基本流程为:首先求取指纹方向场,获得指纹中心;其次,对指纹图像做小波变换、Fourier变换和梅林变换,得到指纹图像的Wavelet-Fourier-Mellin变换特征;然后将得到的特征向量投影到一个正交随机矩阵中,并经过阈值量化生成一组BioCode码作为指纹特征模板.认证时,通过计算存储的BioCode模板和新鲜BioCode模板的海明距离来决定是否通过认证.
2) 基于不可逆变换的方法.此类方法由Ratha等人[9]于2001年提出并被用于指纹模板保护(可撤销的模板保护方法起初只表示基于不可逆变换的方法,但后来被赋予更广泛的含义,即基于变换的模板保护方法).其基本思想是用一个参数可调的不可逆变换对生物特征进行变换,并将变换后的特征作为模板.如果模板泄露,可以通过修改变换函数的参数生成一个新的模板.在此类方法中,模板的安全性取决于根据逆变换获得原始生物特征的难度.此类方法所需的变换函数必须满足3个条件:必须是不可逆的;应具有局部光滑但全局不光滑的特性;对每个细节点的变化幅度不能太小.基于不可逆变换的代表方案主要有2个:
① Ratha等人[44]提出了3种用于生成生物特征模板的不可逆变换:笛卡儿变换、极坐标变换和表面褶皱变换.在笛卡儿变换中,指纹图像的每个细节点被映射到一个矩形表中的特定位置;在极坐标变换中,指纹图像被映射到一个扇形区域中;表面褶皱变换则是利用电势场函数(式(1))或二维高斯函数对指纹细节点进行变换.实验证明褶皱变换的整体表现最好.
方案中给出的电势场(向量值)函数的定义为
(1)
其中,z=x+iy为电荷位置.显然电荷的位置与强度取决于随机密钥z1,z2,…,zK,q1,q2,…,qK.
平移的大小由该函数的模|F(z)|决定,而平移方向由以下平移方向(相位)函数(式(2))决定:
(2)
所用二维高斯函数的定义为
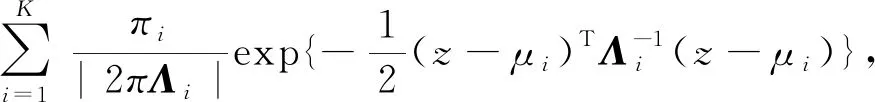
其中,z=x+iy表示位置.权值πi、协方差矩阵Λi和核的中心ui显然由随机密钥决定.
平移的大小由该函数的模|F(z)|决定,平移方向由相位函数

决定,其中Φrand为一个随机相位偏移.
由此可得到指纹细节点的位置与方向变换公式:
X′=x+K|G(x,y)|+Kcos(ΦF(x,y)),
Y′=y+K|G(x,y)|+Ksin(ΦF(x,y)),
Θ′=mod(Θ+ΦG(x,y)+Φrand,2π),
其中x,y,Θ分别表示变换之前细节点的横坐标、纵坐标和方向角,而X′,Y′,Θ′分别表示变换之后细节点的横坐标、纵坐标和方向角,ΦG为G的相位函数.
众多学者对上述方案进行了研究与改进.Feng等人[45]认为该方案所构建的映射关系很难抵御多重记录攻击或暴力攻击,因为在大部分映射区域内,其函数关系为一一映射,即不可逆的信息非常有限.要获得更高的安全性能,必须增加映射中多对一区域的比例,但这样做会导致认证性能出现下降.Chikkerur等人[46]利用正交变换构造了一种不依赖于注册的可撤销指纹模板生成方案,获得了良好的鲁棒性,能够抵抗重放攻击,但识别性能不高.Maiorana等人[47-48]提出了基于卷积算子的不可逆变换集合,原则上可以作用于所有能够被表征为序列集合的生物特征.
② 近年来,布隆过滤器(Bloom filters)[49]成为构造可撤销的生物特征模板方案所需的不可逆变换的一个有力工具.
布隆过滤器实质上是一种用于表征集合的空间效率很高的随机数据结构,允许向集合添加元素并检测一个元素是否在集合中.其主要缺点是误识率较高,且无法删除元素.
标准布隆过滤器的工作原理如图8所示:
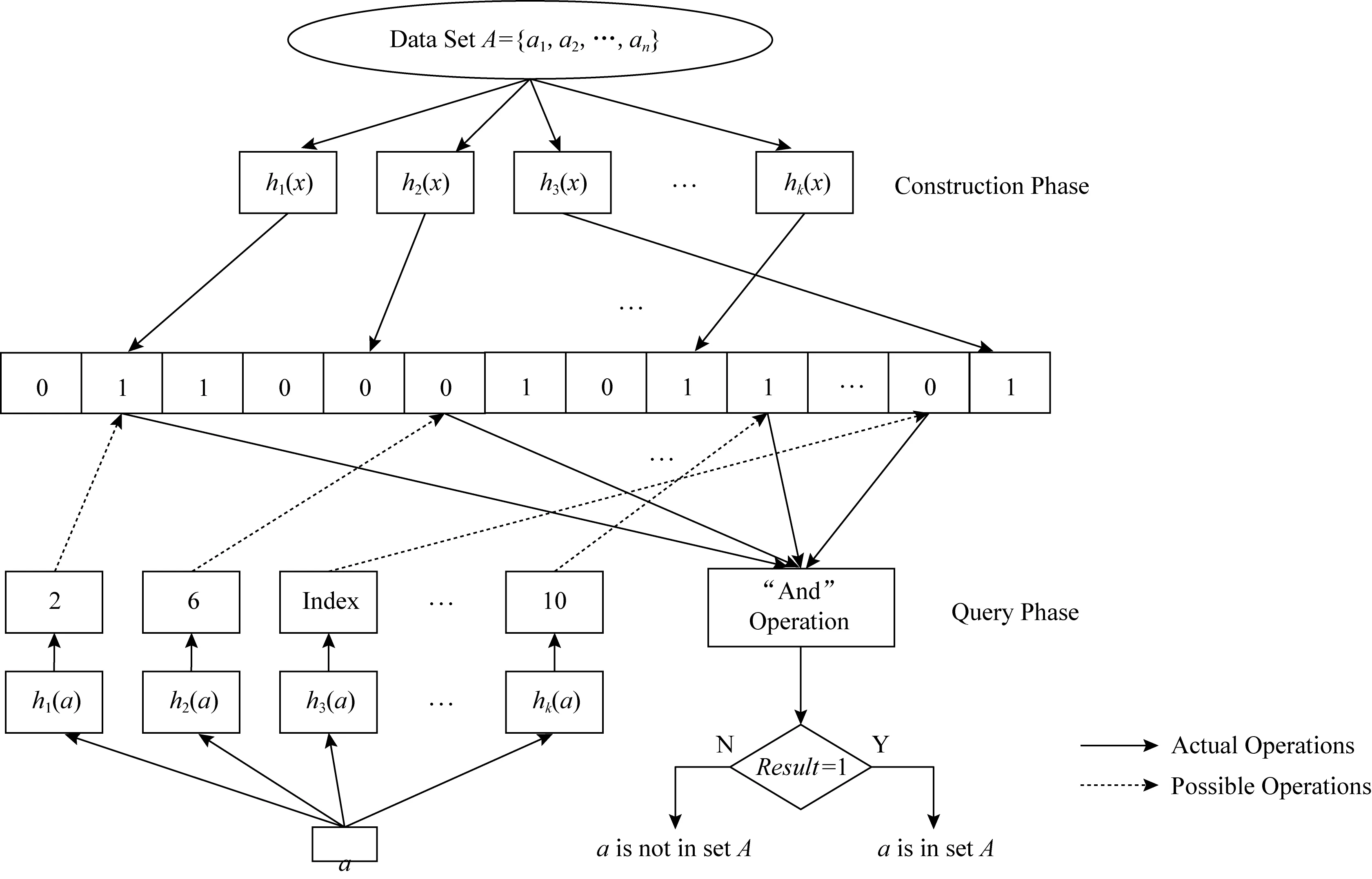
Fig. 8 Principle of standard Bloom filters[49]图8 标准布隆过滤器[49]的工作原理
布隆过滤器的组件包含一个长度为m的二进制向量V(所有位初始值为0)和k个(k≤n)相互独立的散列函数h1,h2,…,hk,每个散列函数能够按均匀分布将集合A={a1,a2,…,an}的某个元素映射到V的某个位.
若要向集合A添加一个元素a,需先计算索引:h1(a),h2(a),…,hk(a),并将向量V的第hi(a)位(i=1,2,…,k)的值置为1.
若要搜索一个元素b是否在集合A中,同样需要先计算h1(b),h2(b),…,hk(b),然后检查向量V中第hi(b)位(i=1,2,…,k)的值是否全为1(只要对这些位的值做“与”运算即可,若结果为1,则证明这些位的值全为1).如果这些位置的值全为1,则说明b∈A;否则说明b∉A,或出现了假真(false positive)错误.
Rathgeb等人[50]提出了基于布隆过滤器的可撤销模板生成方法,并将其应用于虹膜特征模板的保护.其基本思想是注册时根据用户的特征向量生成布隆过滤器向量,如文献[50]中图1所示,基本步骤为:
步骤1. 将原始生物特征表示为一个N×M的二进制矩阵J;
步骤2. 将矩阵J分块,其中水平方向分为l块(即每块宽为Ml列),垂直方向分为Nω块(即每块高为ω行),则矩阵J被划分为l×Nω块;
步骤3. 初始化l×Nω个长度为2ω的二进制布隆过滤器向量,将这些向量的所有位置0,并取定散列函数h1,h2,…,hk;
步骤4. 将J的每个子块Jij(i=1,2,…,l;j=1,2,…,Nω)的每列(一个ω位的二进制数)转换为十进制数aijp(p=1,2,…,Ml);
步骤5. 计算h1(aijp),h2(aijp),…,hk(aijp),其中,(p=1,2,…,Ml),并将与此子块Jij对应的(第j个)布隆过滤器的第h1(aijp),h2(aijp),…,hk(aijp)位的值全置1,最终得到l×Nω个布隆过滤器向量;
步骤6. 将上述结果存为模板,或将其按列链接为长度为2ω·(l×Nω)的特征向量后存为模板b.
认证时,用同样方式生成新鲜特征模板b′,然后计算这2个向量的海明距离HD(b,b′),并按如下方式计算其“不近似”程度:
最后将该值与设定的阈值比较,即可判定认证是否成功.
由于采用了散列运算,并可能将多个数字映射到布隆过滤器的同一个位置,因此上述算法实质上构成了一种不可逆映射.包括Rathgeb等人在内的多位研究者对该方案进行了分析和改进.
Rathgeb[51]在2014年将上述方法进行了扩展,使其具备了数据压缩功能,并声称能够完成高效的生物特征“识别”任务.2015年Rathgeb又将该算法推广到多生物特征(人脸和虹膜)模板的保护中.但文献[52]的分析表明上述2个方案不具备不可链接性,而文献[53]指出文献[50]的方案存在泄漏数据的可能性.为克服上述问题,Gomez等人[54]对原始的布隆过滤器进行了重新设计,提出了一个额外步骤“保结构的特征重置(structure preserving feature rearrangement)”,获得了比原始方案更好的识别性能,并能够抵抗交叉匹配攻击.
3) “蜜糖模板(honey template)”是2015年出现的另一种生物特征模板保护技术,由Yang等人[55]提出并被用于人脸识别[56],旨在抵抗伪造攻击并检测生物特征模板数据库可能发生的数据泄露.其基本架构如图9所示,基本工作流程包括注册流程和认证流程:

Fig. 9 Architecture of the “honey template” scheme[55]图9 “蜜糖模板”方案[55]基本架构
注册流程:
① 根据用户的真实生物特征生成一个“糖模板ST(sugar template)”,然后根据k-1个假特征生成k-1个“蜜模板HTj(honey template)”,其中j=1,2,…,k-1;
② 将上述k个模板的存储单元地址打乱,以掩藏真实模板的地址,并将这k个模板用k个伪标识符PIj表示,其中j=1,2,…,k-1;
③ 将集合PT={AD,PI1,PI2,…,PI2}定义为该用户的模板,其中AD为可能存在的辅助信息;
④ 将PT存储到模板数据库,并将ST的索引号L记录到“蜜检测数据库(honey checker database)”,要求这2个数据库可以根据用户的身份索引号相互关联.
认证流程:
① 应用服务器根据用户身份从模板数据库取出与待认证用户对应的辅助信息AD,并用与注册过程相同的方式生成一个伪标识符PI*,将其发送给模板数据库服务器;
② 模板数据库服务器将PI*与该用户的所有k个模板进行比对,找出相似度最高的一个,并将其索引号idx返回应用服务器;
③ 应用服务器从“蜜检测服务器”搜索出与用户身份对应的索引号L,并将idx与L进行比对.若idx=L,则应用服务器给出验证通过的结论.否则就意味着有人利用从“蜜模板”计算出的原始图像来挑战系统,也就意味着该用户的生物特征数据发生了泄露.
2017年Martiri等人[57]又基于“蜜糖模板”和布隆过滤器提出了一个一般性的模板保护方案,能够提供不可链接性和不可逆性,并能够抵御欺诈攻击.该方案已经被用于构建一个公开的多生物特征数据库BioSecure Multimodal[58].
2.2.2 基于生物特征加密(BC)的模板存储方法
基于生物特征加密的模板存储方法将加密后的生物特征数据存储为模板,由加拿大学者Tomko等人[59]于1996年提出.大多数BC系统需存储一些与生物特征相关的公开信息(通常被称为辅助数据,helper data[60]),用于重构或生成密钥.辅助数据虽与生物特征相关,但不能泄露关于生物特征的任何显著信息.根据辅助数据的生成方式,BC系统主要包括密钥生成(key-generation)系统和密钥绑定(key-binding)系统2类.
1) 密钥生成方法,即在注册时从生物特征数据直接生成密钥,并将密钥保存于数据库中,在认证时按同样的方法由生物特征生成密钥,然后通过比对密钥实现身份认证.这种方法的主要优点是可移植性强,主要困难在于密钥的获取,因为处理生物特征数据类内变化性是一个困难,可能导致密钥生成方法的识别性能出现较大幅度下降[61].此类方案较难构造,也很难满足多样性要求.
现有的相关文献主要致力于从有噪声的生物特征数据获得鲁棒的密钥.最早的密钥生成方案在2002年由Monrose等人[62]提出,旨在将用户敲击键盘的特征用于密钥生成,以增强密钥的可靠性.随后,文献[63-64]进一步研究了如何根据声音特征生成密钥;Goh等人[65-66]等则利用卷积神经网络和循环神经网络等方法从人脸特征生成密钥;Vielhauer等人[67-68]、Feng等人[69]和Tanwar等人[42]研究了从签名生成密钥的方法;Kuan等人[70]提出并总结了将随机令牌与签名结合以生成密钥的方法;Rathgeb等人[71]和Akdogan等人[72]则研究了基于虹膜的密钥生成方法.
密钥生成方法的代表性方案是模糊提取器(fuzzy extractor)方案和安全概略(secure sketch,也译作安全骨架)方案[73].安全概略方法从生物特征提取一些可以公开的信息,当输入与原始模板相似的信号时,可以根据这些公开信息完美恢复原始生物特征模板.而模糊提取器能够从输入的生物特征信号提取近似均匀分布的随机信号密钥.
为了给不同的生物特征提供有效的度量标准,Dodis等人给出了3种不同的距离:海明距离、集合差(set difference)和编辑距离(edit distance).在海明距离下,由Juels和Wattenberg[74]构造的模糊承诺方案可以被看作一个近似最优的安全概略,且可以通过一般性的构造方法将其改造成近似最优的模糊提取器.在集合差度量下,由Juels等人[75]构造的模糊保险箱方案可以被看作一个近似最优的安全概略,且也可以利用一般性构造方法将其转化成一个近似最优的模糊提取器.另外,他们还定义了从编辑距离到集合差的变换,从而可以将集合空间的最优模糊提取器转化到编辑空间.
2) 密钥绑定方法.此类方法最早由Soutar等人[76]于1999年提出.其基本思想是在加密阶段将随机生成的密钥与生物特征数据绑定在一起.在注册阶段,选择一个与生物特征相互独立的密钥,并将该密钥与生物特征模板以某种方式“绑定”在一起,从而产生一些可以公开的“辅助”数据.在识别阶段,将待认证的生物特征与辅助数据相结合,就可以释放出密钥,从而解密存储的生物特征模板并完成比对.
此类系统需要保证从辅助数据很难获得原始的生物特征或密钥,因此能够满足不可逆的要求.另外,利用不同的密钥与同一生物特征绑定可以生成不同的模板,因此满足了可撤销和不可链接的要求.又因为利用了纠错码技术,此类方法能够较好地处理生物特征数据类的内在变化,因此容错性较好.但此类方法很难应用于成熟的或专用的匹配器,因而很难获得较高的匹配准确率.
在已有的密钥绑定系统中,Bioscrypt方法[77-78]、模糊承诺(fuzzy commitment, FC)[79]和模糊保险箱(fuzzy vault, FV)[75]是最有代表性的方案.
① Bioscrypt方法是生物特征加密领域最早的实用化算法之一.其基本思想是将生物特征样本与一个预定义的随机密钥进行绑定,得到一个phase-phase值.如果认证成功,上述phase-phase值将被解密,以释放出密钥.但该算法要求对指纹图像预先配准,且没有给出拒识率和误识率等关键信息.
② 模糊承诺(FC)方案是由Juels和Wattenberg[79]在1999年提出的.这种方案的基本思想是将纠错码技术用于生物特征表示,以体现生物特征的“模糊性”.该方案借用了比特承诺方案[80]中的承诺和证据概念,包含2个基本步骤:承诺和解承诺.
承诺步骤为:
步骤1. 从某种纠错码体系选择一个与生物特征向量ω等长度的码字c,并定义两者的偏差δ=c-ω;
步骤2. 给出承诺{Hash(c),δ}.
解承诺步骤为:
步骤1. 用户输入新鲜生物特征ω′;
步骤2. 按c′=ω′-δ=ω′-ω+c求新码字c′;
步骤3. 判断:如果生物特征模板ω与ω′差别不大,经过纠错码的处理,能够得到c=c′,因此可以通过检验Hash(c)与Hash(c′)是否相等来判断新鲜特征模板与存储的模板是否属于同一用户.
该算法要求将生物特征表示为二进制序列,且要求对应分量的排列顺序保持一致,因此较适合于具有规范编码的生物特征,如具有较为规范的IrisCode(固定长度2 048 b)编码结构的虹膜特征.Hao等人[81]在2006年设计并实现了一套虹膜加密方案,采用了双因子认证思想,即必须提供正确的令牌和虹膜特征才能通过认证.该方案取得了良好的识别效果:在错误接受率为0的前提下,错误拒绝率为0.47%.其基本流程如图10所示:

Fig. 10 The basic process of Hao’s scheme[81]图10 Hao方案[81]的基本流程
之后,FC技术被用于多种生物特征识别方案中:Van等人[82]提出了基于真值(real-valued)脸特征的FC方案;Teoh等人[83]、Shi等人[84]提出了基于指纹的FC方案;Maiorana和Campisi等[85-86]提出了基于签名的FC方案等.近期,FC技术也被用于物联网设备的保护[87-88]中.
3) 模糊保险箱(FV)方案是生物特征加密领域最经典的实用化方案之一,由Juels和Sudan[75]在2006年提出.该方案基于无序集构造,因而特别适用于无序生物特征的识别.方案包含2个步骤(如图11所示).
① 用户1选择一个多项式p(x)并用其加密密钥K,然后计算无序集合A在多项式p(x)上的投影p(A),生成有限点集(A,p(A)).随后,用户1随机生成远多于真实点的杂凑点(chaff points)并将其加入(A,p(A)),从而构造出保险箱(vault).
② 如果用户2拥有另一个无序集合B,且B与A有大多数元素重合,则B中的很多元素可以落在多项式p上.借助于纠错码技术,用户2可以重构出多项式p,从而取出密钥K.若集合B与A的重合元素不多,则很难重构出p.

Fig. 11 Principle of the fuzzy vault scheme[75]图11 模糊保险箱方案[75]原理
在上述工作的基础上,Clancy等人[89]、Yang Shenglin等人[90-91]、Uludag等人[92-93]、Nandakumar等人[94]分别构建了指纹保险箱.其中,Uludag等人的方案未使用纠错码技术,而是使用了循环冗余校验技术,在误识率为0的前提下,可以达到15%的拒识率.
上述方案的一个共同不足是仍然需要对指纹图像进行预先配准,因而有些后续文献致力于提高FV方案配准算法的性能[95],或构造无需配准的指纹FV方案[96].另外,也有一些文献致力于改进杂凑点的生成方式[97-99]或多项式的生成方式[100]来提升FV方案的安全性和效率.其中,Wu等人[99]的方案使用有序的杂凑点来生成保险箱,从而可以有效利用生物特征的顺序信息,获得了良好的安全性和效率.到目前为止,FV方案已经被应用到指纹、人脸[101]、虹膜[102-103]、掌纹[104-105]、签名[106]等多种BA方案中.
4) 近年来,随着安全多方计算(SMC)[107]技术的发展,安全两方计算成为构造具有隐私保护特性的BA系统的一种新手段[108-109].由于此类系统所需的密钥通常不由生物特征直接生成,因此常将其归类于密钥绑定系统[110].
构造适用于BA系统的SMC方案的密码学工具主要有[11]:同态加密(homomorphic encryption, HE)[111-112]、不经意传输(oblivious transfer, OT)[113]、乱码电路(garbled circuits, GC)[114]和可验证计算(verifiable computation, VC)[115].其中,基于HE技术的BA系统呈现良好的研究与应用前景.
HE系统允许对加密数据进行计算,且能由计算后的结果解密得到对相应明文的计算结果,即满足Dec(Enc(m1)⊗(Enc(m2))=m1⊕m2.其中⊕和⊗分别表示明文空间和密文空间中的2种运算,Enc和Dec分别表示加密与解密算法.若系统允许⊕为任意运算,且可以进行任意次⊕运算,则称该方案为一个全同态加密(FHE)方案[112,116-119].
基于HE技术的生物特征认证的基本思路是利用HE技术的“保密计算”功能实现对生物特征的“保密比对”.“认证”过程的一般流程如图12所示:

Fig. 12 General flow of HE based biometric verification图12 基于同态加密的生物特征“认证”的一般流程
这种架构的3个优点非常明显:
① 可以保证在信道中传输的数据和数据库中存储的数据都是密文,即使泄露也不会导致用户的原始生物特征丢失.
② 该架构所用密钥可以与生物特征无关,无法根据生物特征推断出所用密钥.
③ 如果模板泄露,可以用不同密钥对生物特征进行再次加密得到新的模板.新模板与已丢失的模板匹配成功的概率非常小,这是因为它们是用不同的密钥加密得到的.这就满足了文献[9]提到的模板“可更新”和“多样性”的要求.
但由于HE技术的发展比较缓慢,基于该技术的BA研究直到2009年才开始大量涌现,且因为当前FHE技术的整体效率仍未达到实用标准,基于FHE技术构造的BA方案仍然较少[120],单同态技术[121-123]仍然是主要选择.其中较有代表性的工作有:
2010年Mauro等人[124]提出了基于Pailler方案的指纹认证系统.该方案利用Fingercode表征指纹特征,用平方欧氏距离作为度量.相似的方法己经被应用在人脸识别[125]、虹膜识别[126]等工作中.2012年,Wong等人[127]采用ElGamal方案实现了虹膜的保密认证,这是首次使用乘法同态算法完成认证.2013年,Bringer等人[128]分析了用加法同态技术完成人脸、指纹和虹膜认证的方法,并对基于加法同态的生物特征认证做了总结.此外,另外一些HE技术也被用于BA方案的构造,如基于Blum-Goldwasser系统的方案[129]、基于Goldwasser-Micali的方案[130]和基于RSA系统的方案[131]等.Ali等人[132]对基于RSA加密算法的生物认证进行了综述,并将其应用到人脸、虹膜、掌形和指纹中.
也有学者将HE技术应用到多模态(multi-modal)生物特征识别中,如Barrero等人[133]、Yildiz等人[134]将多种HE算法结合,实现了多生物特征的融合认证,获得了较好的识别效率和安全性.最近,Salem等人[21]利用HE技术和转移学习(transfer learning)构造了一个基于云的、具有隐私保护特性的安全多方BA系统“DeepZeroID”,在虹膜和指纹的组合实验中,获得了95.47%的综合识别准确率.
2016年Jong等人[135]利用具有乘法同态性的ElGamal加密方案构造了一个掌纹认证方案.虽然该方案的整体性能并不突出,但提出了1个有潜力的过程.该方案的基本过程为:
① 注册时,采用Garbor滤波等技术,从掌纹照片获取掌纹特征,表示为二进制特征向量X;
② 根据特征向量X构造一个与其等长的整数向量X′.具体方法为:取2个不同的素数a和b,若向量X中的某位为0,则将X′中的对应位置为a,否则将其置为b;


其保密比对过程的正确性是显而易见的.由于ElGamal方案具有乘法同态性,向量T的每个分量应为向量X′与Y′的对应分量的乘积.若T的某个分量对a·b取模的结果为0,说明向量X′与Y′的对应分量的值不同(不可能同时为a或为b,否则其对a·b取模的结果必不为0).
该方案的主要优点在于:①使用了二进制形式的特征向量,并使用海明距离度量掌纹特征的相似度,相较于使用实数或整数特征向量方案的计算复杂度更低.②为进一步降低计算复杂度,采用了随机投影法[136]对数据进行降维,在不显著降低识别性能的前提下获得了较好的效率.但该方案也存在明显不足:①在用ElGamal方案对特征向量加密之前,采用了固定映射将二进制特征向量X映射为整数特征向量X′,这种构造为比对攻击留下了可乘之机.②提取出的掌纹特征向量质量不佳,导致方案的整体性能较差.
为克服上述方案的不足,王会勇等人[137]、高志强等人[138]分别提出了基于掌纹脊线和图像简单二值化的特征向量生成法,均获得了良好的性能:前者在明文比对过程中几乎取得了100%的识别准确率;后者的识别准确率约为99.5%,但效率较高,并将文献[135]方案中的固定映射方式变为多映射方式,消除了比对攻击的隐患.最后,针对不同的特征提取方法、数据降维方法、特征向量大小和阈值进行了多组对比实验.结果表明:经过加解密操作后,在特征向量为1 000维、阈值取为0.23时,能够取得最佳性能:约97.5%的正确识别率和3%的等错误率.
2.3 针对生物特征检索的模板保护技术
在考虑模板保护的前提下,现有的BA方案几乎都不适用于“检索方案”.主要有2个原因:
1)“检索”任务的难度远大于“认证”任务,导致现有方案的效率远未达到实用要求.例如,在张璐等人[139]对模糊保险箱算法[75]的改进工作中,即使不考虑图像校准时间(占用了算法的大部分时间),实现一次指纹模糊保险箱算法所需的时间约为0.25 s.这种表现对于“认证”任务来说是可以接受的,但对自动检索任务显然是不实用的.
2) 对基于“密钥绑定”的模板存储方案来说,“检索”任务还存在密钥协调困难,即要求必须使用同一个密钥加密存储的模板和新特征,才能进行有效比对.这是因为当前用于BA系统的加密技术均是单密钥的,因而对基于不同密钥的2个密文做计算是没有意义的.但在搜索任务中很难实现密钥协调,因为搜索任务的典型场景是待搜索人的身份未知,如果要将加密未知用户生物特征所用的密钥与加密模板所用的密钥统一起来,密钥管理的负担将会很大.
正是由于这些原因,当前以“检索”为目标的方案非常少,这一结论可以从过去2009-01-01—2019-04-20的10年中,中国知网与Web of Science网站收录的相关论文数量看出,如图13所示:

Fig. 13 Number of related papers indexed by Web of Science and CNKI from 2009-01-01 to 2019-04-20图13 2009-01-01—2019-40-20 Web of Science与中国知网收录的相关论文数量
3 构建安全BA系统的3个困难与解决思路
3.1 构建安全BA系统的3个困难
虽然已经存在很多技术方案来保护BA系统的安全性与隐私性,但实际部署的大多数系统仍然是用传统手段(硬件隔离、身份控制机制等)加以保护的.其主要原因是现有的具有隐私保护特性的BA系统的整体性能仍不能满足实际需要,尤其是大规模应用的需要.主要有3个典型困难:
1) 生物特征识别一般具有很强的时效性,而对生物特征的混淆或加解密操作会对系统性能造成较大拖累.
2) 基于生物特征加密的认证方案存在密钥管理难题:如果设立密钥管理中心,会带来效率和安全性方面的负担,且现有方案要求密钥中心参与解密,更增加了数据泄露的风险.但如果不设立密钥中心,就需要将密钥交由服务器或客户端保管,都存在密钥泄露或遗失风险.
3) 如2.3节所述,生物特征“搜索”任务的难度远大于“认证任务”,因而上述绝大多数方案都是针对“认证”任务构造的,不适应于“搜索”任务.
3.2 解决思路与展望
针对上述困难,现有文献的主要解决思路有3种[11]:
1) 将加解密模块硬件化是解决BA系统效率不足问题的一种可行思路.另外,基于硬件的两方安全比对也是解决密钥管理难题的一种可能方法.
2) 采用新技术手段来构造BA系统,如多模态BA技术[25,140]、差分隐私技术[141]等.
3) 在构造具有隐私保护特性的“搜索”方案时,可以首先构造某些“弱化”的实用方案,如:可考虑加密存储用户的特征模板,但以明文形式记录新录入的用户特征,并设计实现“密文”与“明文”的比对方案.相对于“密文”与“密文”的比对方案,“密文”与“明文”的比对方案更容易构造,且更容易获得较高效率,也能满足特定场景下的搜索需要.
4 总 结
本文对生物特征识别系统面临的模板攻击和相应的保护方法相关文献进行了综述.
首先对BA系统的一般理论、体系架构及安全与隐私的基本概念做了介绍;然后对保护BA系统用户数据安全性和隐私性的关键技术-模板保护技术进行了阐述,重点介绍了模板保护技术的分类与代表性技术方案.最后,指出了构建安全的BA系统的3个困难和可能的解决思路.
