基于机器学习的故意伤害案件风险分析
2020-06-08曾祺
曾祺
(中国人民公安大学警务信息与网络安全学院,北京100032)
0 引言
自中共中央、国务院发出《关于开展扫黑除恶专项斗争的通知》[1]以来,公安部号召各地方单位开展大量扫黑除恶行动,坚持依法严惩、打早打小、除恶务尽,始终保持对各类黑恶势力违法犯罪的严打高压态势。一个区域内故意伤害案件的发生数量和严重程度能够反映该区域内的治安状况与社会稳定度。故意伤害案件背后往往涉及到相关黑恶势力,进而反映出该区域扫黑除恶行动的打击力度和效果。对故意伤害案件进行风险分析不仅可以预测一起案件发生的危害后果还能够探测其风险因素,从而给公安机关打击黑恶势力,加强社会治安提供决策帮助。
随着公安信息化建设的不断推进,公安部门内部积累了海量的犯罪历史与实时数据[2]。许多专家学者利用机器学习方法挖掘犯罪数据中的线性或非线性关系,通过对比算法,优化参数,得到最优模型,进而利用最优模型能够对犯罪发生的风险以及影响因素进行分析。Mehent 等人[3]利用贝叶斯方法,研究发案的日期和地点,犯罪类型,罪犯ID 和熟人等特征预测嫌疑人犯罪风险。陈鹏等人[4]利用犯罪嫌疑人的生物信息、社会信息和行为信息作为基本特征,基于二项逻辑回归算法构建了惯犯身份分类预测模型,通过某市街面盗窃、扒窃、入室盗窃三类案件数据进行分类预测验证,模型能够有效进行身份预测。邱凌峰等人[5]以实际盗窃犯罪数据为基础,采用数据预处理、特征分类等特征工程,利用随机深林算法训练得到了效果较优的前科人员身份预测模型。综上可以看出,该方法的研究对象多为盗窃、扒窃等侵财类案件,针对暴力类犯罪的研究相对较少,缺少对某一类案件精细地特征挖掘和分析;同时机器学习过程中数据量越大,模型越准确[6]。
本文针对上述情况,利用A 市2014-2016 年故意伤害案件近2 万条真实数据。通过分词抽取、机器与人工比对方法将受害人的受害程度确定为模型目标值,进行数据预处理与特征分类,对比决策树、随机深林、SVM 等5 种机器学习算法,构建故意伤害案件的后果预测模型进行风险分析。
1 数据与方法
1.1 实验数据
本节利用A 市重点人员数据库中的2015-2016 年故意伤害案件中前科人员的11467 条和受害人的16793 条真实数据。两组数据通过案件编号进行关联,数据中枚举型特征居多,除了案件编号、发案时间、年龄为连续型特征,简要案情、详细发案地址为文本型特征外,其他特征均为枚举型。对数据初步分析并结合实际公安经验,去除空缺值超过90%、特征值唯一以及与案件分析无关的特征数据。最后筛选得到数据如表1 和2 所示。
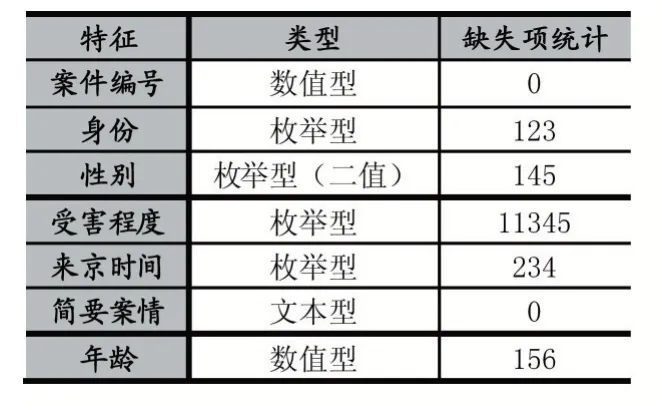
表1 受害人数据
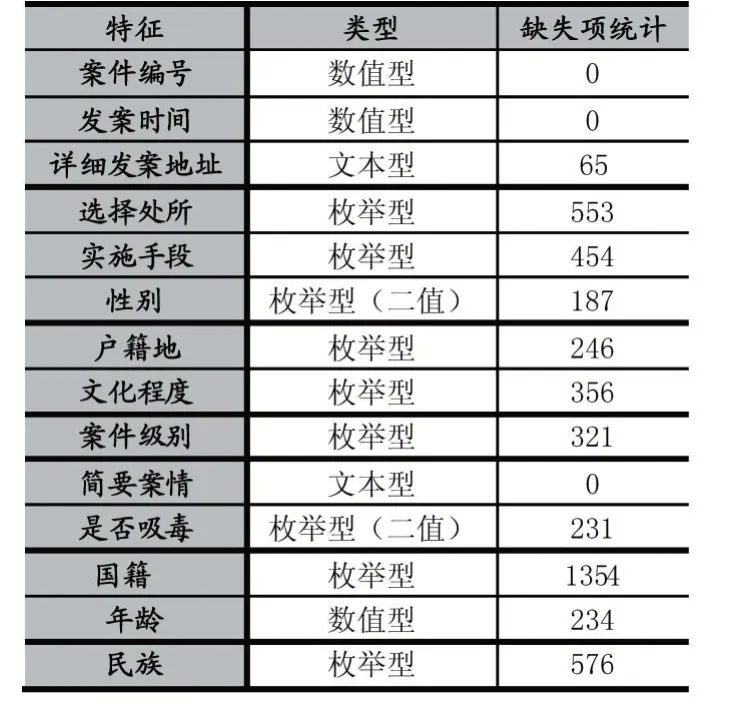
表2 前科人员数据
1.2 实验方法
依据原始数据资源的状况、机器学习分类预测的基本原理[7]以及风险分析的目标对象,本文提出了如下图1 所示的基于机器学习的风险分析方法流程。其中原始数据中特征信息丰富、多为枚举型特征,但与目标值关联度不确定,需通过卡方检验来进行筛选;特征工程主要包括目标值选取、特征分类、特征编码等方法;选取逻辑回归、支持向量机、k-邻近、决策树、随机森林等算法[8]进行比对,对随机森林算法进行调参优化;最后得到最优模型进行风险后果预测和风险要素排序。
2 实验与结果分析
2.1 目标值选取
本研究采用受害人数据中的‘受害程度’特征作为目标值来表示故意伤害案件的后果程度。受害人数据中的受害程度分为:‘轻微伤’、‘轻伤二级’、‘轻伤一级’、‘重伤二级’、‘重伤一级’、‘伤害致人死亡’、‘不低于轻伤’、‘不低于重伤’、‘轻伤’、‘重伤’、‘不构成轻微伤’共11 种类别。将上述类别按照严重程度进行归类,把‘轻微伤’、‘不构成轻微伤’归为轻微;把‘不低于轻伤’、‘轻伤二级’、‘轻伤一级’,‘轻伤’归为一般;把‘不低于重伤’、‘重伤一级’、‘重伤二级’、死亡归为严重,最后得到分为‘轻微’、‘一般’、‘严重’的三分类目标值。数据中三种类别占比如图2 所示。
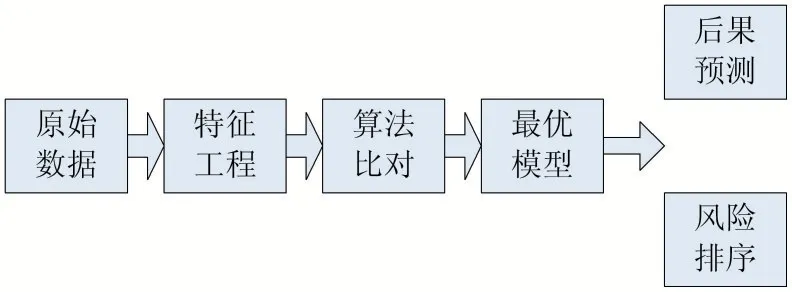
图1 基于机器学习的风险分析流程

图2 受害程度划分
2.2 特征衍生、筛选与分类
特征衍生[9]是指从原始数据中构建新的特征,本实验中对一名前科人员对应的多名受害人数据进行统计,从而得到一起故意伤害案件中的涉案人数,以此作为衍生得到的新特征。
特征选择[10]是从给定的特征集合中选择出相关特征子集的过程,其去除掉无关特征后将会降低学习任务的难度,提高机器学习效率。卡方检验是检测离散型自变量与因变量之间相关性的经典方法,将数据中11 种离散型特征分别与目标值做卡方检验,得到的Z与p 值(特征与目标值无关的概率)如表3 所示。
数据中选择处所、实施手段、被害人身份、来京时间等四个特征的类型较多,且少数类型样本数量多,多数类型样本数量少,这样会导致训练集和测试集中大量特征信息不一致,严重降低模型的准确性[11]。按照如下四则原则对上述特征进行分类:一、尽可能保证各分类的样本量平衡,且高于测试集的样本量;二、尽可能保证每类特征之间没有重复;三、类别应具备较好的扩展性;四:尽可能依据数据分布规律,结合业务经验进行合理分类。身份特征分为“低收入人群类”、“普通收入人群类”、“学生和退休人员类”、“其他类”;选择处所特征分为:“餐饮娱乐区”、“露天地段区”、“住所区”、“一般公共场所”;实施手段特征分为:“持器伤人类”、“徒手伤人类”、“其他类”。
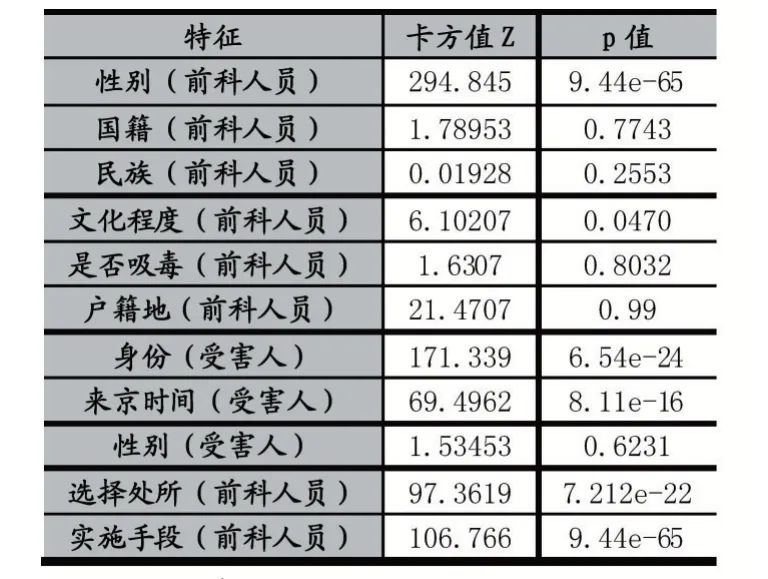
表3 离散型特征的卡方检验
2.3 实验结果分析
综合数据集中受害程度的三类样本比例约为2:7:1,为了解决数据集不平衡问题,采用SMOTE 过采样处理后得到9253 条数据,其中“严重”程度2732 条,“一般”程度4211 条,“轻微”程度2310 条。利用Python3.6 中Scikit-learn 机器学习模型库建立SVM、逻辑回归、K-临近、决策树、随机深林等5 种机器学习模型,并将过采样处理后的数据带入训练,通过10 折交叉验证评估各模型的结果。
根据表4 可知,在查准率上随机森林0.74、决策树0.70、支持向量机0.56 效果较好,在查全率上随机森林0.69、决策树0.64、逻辑回归0.53 效果较优。决策树与随机森林算法在查全率和查准率上都要优于其他三种算,从F1值也能看出来,随机森林0.72 最优,决策树0.67 次之,逻辑回归0.51 效果一般,支持向量机和k-近邻均在0.5 以下效果较差。
依据表5 可知,在特征工程中对“受害人身份”、“来京时间”、“实施手段”、“选择处所”进行归类后,随机森林模型对一般级别案件分类效果提升0.42(一倍),对严重级别案件分类效果提升0.3、对轻微级别案件分类效果提升0.36,总体上都得到了大幅度提高,因此可以说明特征工程中的归类思想是合理的。
从表6 可知,“涉案人数”特征重要性最高(0.7864),“实施手段”次之(0.5762),“热点时段”排名第三(0.4867),“选择处所”排名第四(0.3987),其他特征重要度评分均在0.1 之下,对模型影响程度较低。因此可以得出涉案人数、实施手段、是否为热点时段以及案件发生处所是能够影响一起故意伤害案件后果的重大风险因素。
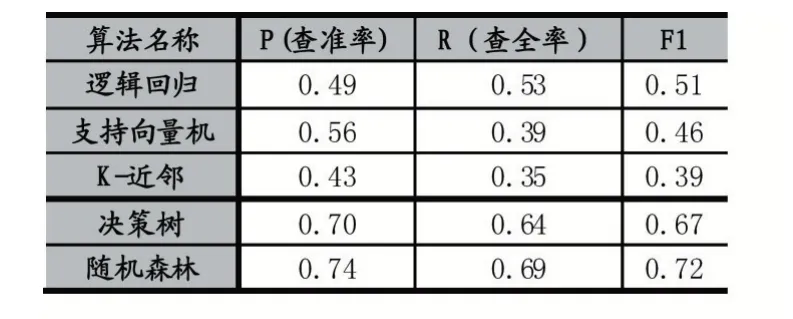
表4 不同模型精度比对

表5 随机森林在特征归类前后结果比对
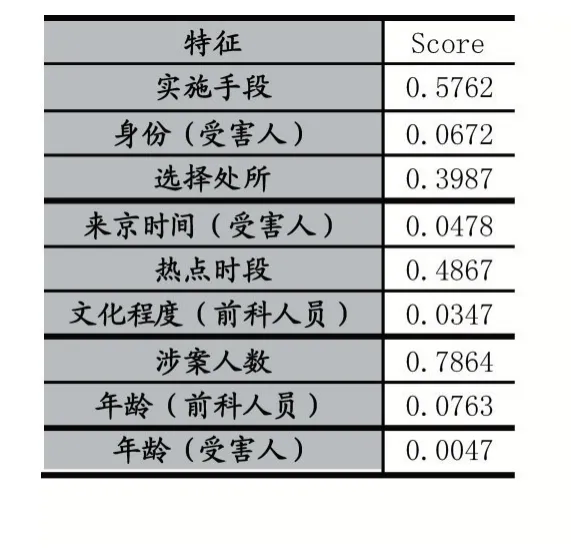
表6 特征重要性度量
3 结语
本文基于机器学习方法对故意伤害案件进行风险分析,利用故意伤害案件的前科人员数据与受害人数据构建一个能够准确评估案件后果严重程度的机器学习模型,并通过对模型中的特征进行重要度排序来分析故意伤害案件的风险要素。
通过上述实验可以看出,一起故意伤害案件的涉案人数、作案手段以及案发位置的周边环境对于案件后果有显著影响。涉案人数越多,作案人若使用武器、发案地点为餐饮区域,则案件后果越严重,因此当公安机关接到符合上述特征的警情时应增加派出警力和警用装备,及时到达现场控制局面,防止危害增大。
