社交网络中网络空间安全用户挖掘模型研究
2020-06-08赵翠镕黄建军孙鹏方勇祝鹏程
赵翠镕,黄建军,孙鹏,方勇,祝鹏程
(四川大学网络空间安全学院,成都610065)
0 引言
社交网络平台已经愈发成为网络空间安全用户的聚集地。到2019 年,推特的月活跃用户达到3.3 亿。在如此海量的推特用户中,存在一些安全技术专家、研究者以及黑客,这些用户会经常发布分享安全相关的专业知识或者资讯,这些用户数据对于威胁情报分析、用户社区分析等研究具有重大价值[1,2]。但如此庞大的用户规模不可避免地导致了数据过载的问题。在如此海量的推特用户中,如何准确地发现网络空间安全领域的用户是一个值得研究的问题。针对上述问题,本文综合相似用户发现和用户分类检测技术,设计出一种针对社交网络中的网络空间安全领域用户挖掘模型。
1 相关研究
目前许多对社交网络进行用户群体的挖掘的工作主要是通过对用户的社交关系、行为、内容等各种属性信息来进行研究。
使用分类技术对用户进行挖掘特别是对社交网络中的恶意用户进行挖掘是当下比较热门的研究点。张晓宽等人[3]以社交网络用户地理位置、评论数、时间间隔等信息为特征,使用支持向量机算法训练分类模型,对用户进行分类。Aswani 等人[4]结合了社交媒体分析和生物启发计算,从用户行为和内容中提取了21 个特征对恶意用户进行检测,从而提出了一种新的识别恶意用户的方法。Adewole 等人[5]在进行恶意用户检测的研究时也使用了类似的特征,并给出一种进化搜索算法来筛选特征,并使用了多种分类算法进行实验,其中随机森林算法表现最好。刘勘等人[6]通过分析机器用户的特点,从用户关系、用户行为、微博文本、和发布平台4 个方向提取用户的特征,并使用随机森林算法对机器用户进行识别,取得了不错的效果。
通过用户间的相似度进行用户群体挖掘也是一种常见的研究思路。郁启麟等人[7]通过微博用户背景信息、关系和用户动态话题构建用户相似度,从而在微博的社交网络中进行相似用户群体的发现。Perozzi等人[8]提出一种方法,以一组用户作为样本,通过最小化样本个体之间的距离度挖掘与样本相似的用户群体。Wang 等人[9]使用Jaccard 相似度建立了基于用户行为相似性的检测模型,实现恶意用户群体的挖掘。
但目前来说,这两种针对社交网络平台进行用户群体挖掘的方法还都存在弊端。基于分类检测的方法需要对用户集合中的每一个用户进行分类判别,而对海量的社交网络用户直接进行分类,是不可行的。通过相似度进行用户群体挖掘则无法保证能够准确得到特定领域的用户。因此本文结合用户相似度和用户分类技术,提出一种方法对推特平台的网络空间安全领域的用户进行挖掘。
2 网络空间安全领域用户挖掘模型设计
为了针对推特平台构建网络空间安全领域的用户挖掘模型,本文首先人工选取少量推特中的网络空间安全领域用户作为种子用户。在构建相似用户发现模型时,在作者原有的基于社交关系的用户相似度算法研究成果上,结合基于动态交互信息的用户相似度算法,通过综合加权平均,提出一种加权综合的用户相似度算法,并利用该算法从用户的关系网络中初步提取网络空间安全相似用户群体。然后通过用户分类检测模型对相似用户群体进一步进行网络空间安全分类判别,最终准确得到网络空间安全领域的用户。本文提出网络空间安全领域用户挖掘模型如图1 所示。
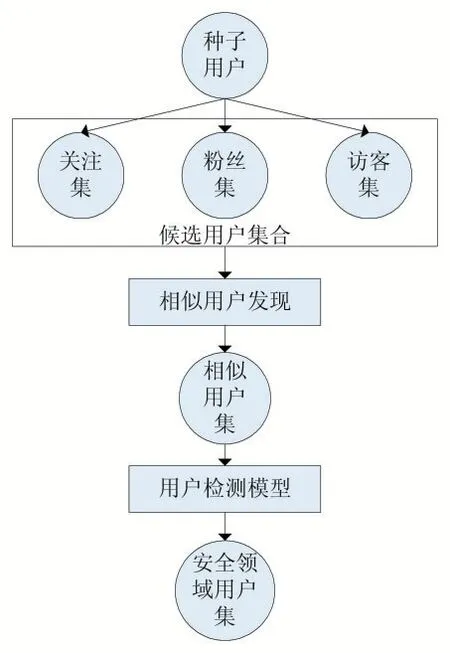
图1 网络安全领域用户挖掘模型
2.1 基于动态交互信息的相似度计算
在推特中用户的交互行为能够反映用户间共同的兴趣倾向,这对用户相似度的计算具有重要意义。推特中用户使用的交互行为主要包括:转发(retweet)、评论(comment)、提及(mention)等。一般来说,用户间的交互相似性通过用户间的交互次数来表示[11]。对于两个用户u,v,用retweet(u,v)表示用户u 与用户v 之间转发行为的次数;同理,将用户u 与用户v 之间评论行为的次数记为comment(u,v);用户u 与用户v 之间的提及次数记为mention(u,v)。结合以上三种交互信息,用户间交互强度表示为公式(1):
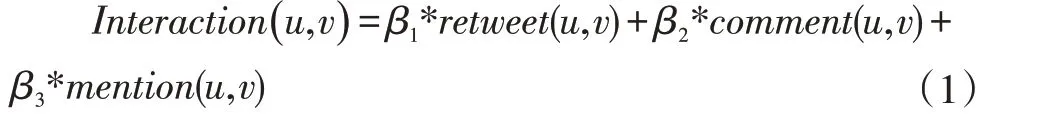
其中β1,β2,β3表示转发、评论、提及三种交互行为的权重,且β1+β2+β3=1,在已有的相关研究[11,12]中通常认为评论>转发>提及。
本文以一个月时间为周期划分时间片,对用户交互行划分时间片,时间片集记为T={T1,T2,…,Tm},对于时间片Ti内的两个用户u,v 的交互强度,我们按照公式(3-8)的方法通过时间片Ti内的交互行为次数来计算,记为IntertationTi(u,v)。将所有时间片中用户之间强度的最大值Interactionmax,以Interactionmax为基准对用户交互强度做归一化,其计算公式为:

计算出每个时间片的交互相似度,再采用一定的衰减策略进行累加,当两个用户的时间片数量不一致时,选取时间片数量少的用户为参照。本文使用了指数衰减的策略,基于动态交互信息的用户相似度计算方法如公式(3)所示:
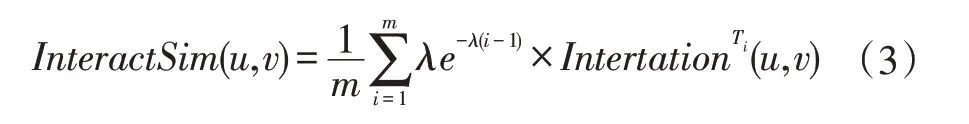
2.2 加权综合的用户相似度计算
如果只通过动态交互信息进行相似度计算,则忽略了用户之间存在的重要社交关系。因此完整的用户相似度计算是将动态交互信息、用户社交关系相似度两个因素进行加权综合。笔者在已发表的基于社交关系的相似度计算的研究成果的基础上[10],加权得到最终的用户相似度公式,公式如(4)所示:
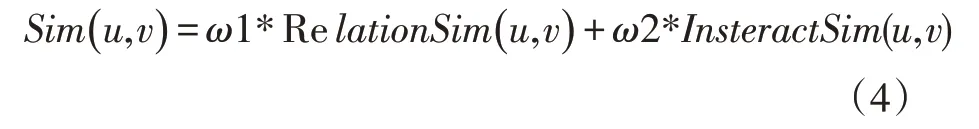
其中RelationSim( u,v )表示基于社交关系的用户相似度,InsteractSim(u,v)表示基于动态交互信息相似度,ω1,ω2,表示两者的权重。本文参考已有的研究工作,对用户各种属性进行分析并结合实验给出各类属性的权重,并在表1 中给出具体各属性的权重设置。
在加权得到综合的相似度计算算法,本文通过以下步骤对推特中的用户进行相似用户发现:
(1)从给定的推特用户出发,获取推特用户的关注用户集Follows(u)和粉丝用户集Fans(u),并通过用户评论、转发、@等交互行为,获得访客用户集Visitor(u)。将这三类用户合并记为用户u 的候选用户集合EN(u)。
(2)通过综合的用户相似度算法计算用户u 与EN中每个用户ui的相似度。
(3)按照相似度大小排序并选取前N 个用户,得到相似用户集SimUser(u)。

表1 推特用户相似度计算权重分配
2.3 用户分类检测技术
对于发现的相似用户,还不能准确地就确认其一定属于网络空间安全领域,为了进一步判别其是否属于网络空间安全领域,本文在发现相似用户的基础上,构建一个网络空间安全用户分类检测模型来对指定的相似用户进行分类判别。
首先,选择一定数量网络空间安全领域用户以及普通用户,采集其基本信息、推文等数据。对采集到的用户数据进行处理,得到用户模型训练的数据集。
其次,从用户基本信息、用户行为、用户文本三个方面选择合适的特征,对于用户分类来说,所使用的特征是否较好地反映样本数据中隐含的特性,对于整个分类任务来说至关重要。为了选取合适的特征,本文在全面分析社交网络平台用户信息的基础上,初步从用户基本信息、用户行为和用户文本内容三个方面筛选了共23 个用户特征指标用于用户检测。初步构建的特征组合如表2,为了进一步优化特征组合,本文使用剔除特征法对用户特征进行优化,优化后的特征如表3 所示。
最后,在得到优化的特征组合后,本文选择决策树、随机森林、支持向量机三种分类算法进行实验,选择效果最好的算法用于构建用户分类模型。
在确定最优的特征组合和最佳分类算法后,本文构建网络空间安全领域用户分类检测模型,该模型的总体结构如图2 所示。对于一个推特用户,在提取各类用户数据后,构造其特征向量,最后通过分类算法检测其是否为网络安全领域的用户。
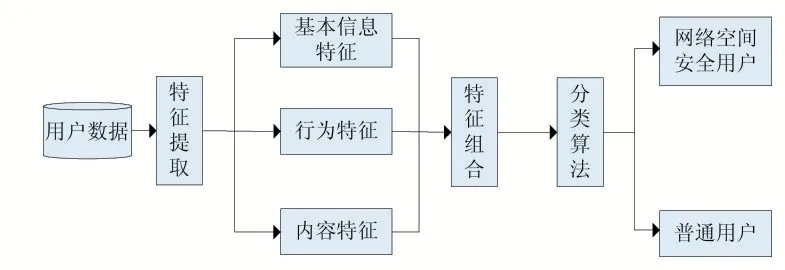
图2 网络空间安全领域用户检测模型

表2 初步特征组合

表3 优化的特征组合
3 实验与分析
3.1 相似用户发现实验
(1)实验数据
目前,关于推特用户相似度计还没有统一的公开数据集,根据需求,本文使用Python 编写的爬虫程序自行从推特上采集相关数据。本文在推特中选择了网络空间安全领域的10 个用户作为网络空间安全种子用户,并利用其社交关系链向外扩展一层,抓取用户的推文、关注、粉丝数据用于相似用户发现实验。
(2)评估指标
对于社交媒体中海量的用户群体,通常使用评价指标P@N 对相似用户发现的结果进行评价,即通过计算相似度得分排名前N 的用户,判断其中是真正属于相似用户的比例。本文将使用用户文本相似度得到相似用户序列F(U)作为实验中的标准答案,待评价的相似用户序列记为S(U),通过计算F(U)和S(U)的之间的P@N 来衡量相似用户发现的准确性。序列F(U)和S(U)之间的P@N 计算方法如公式(5)所示:
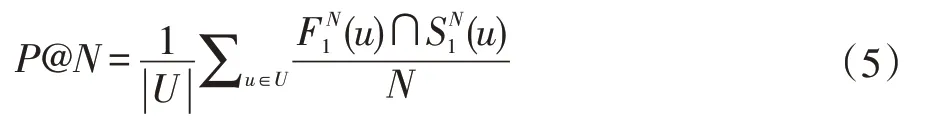
(3)实验结果及分析
本文将用基于社交关系的用户相似度计算算法、基于动态交互信息的用户相似度计算算法、以及加权构建的综合用户相似度计算算法来进行对比试验。在实验中,分别取TOP-N 中的N={10,20,30,40,50,60,70,80,90,100}的10 种情况进行计算,以验证本文提出的加权构建的综合用户相似度算法的效果。实验结果如图3 所示。
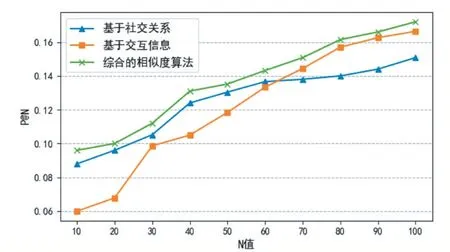
图3 实验结果
从实验结果可以看出,随着推荐用户N 的增加,基于加权构建的综合相似度算法性能相较于两种单独属性构建的相似度算法来说,P@N 分值始终更高,具有更好的相似的用户发现效果。
3.2 用户分类检测实验
(1)实验数据
由于目前还没有发现推特中网络空间安全领域用户的公开数据集,因此本文从推特平台上选择了一些网络空间安全领域的专家,并对列表中的用户进行人工筛选,通过筛选获得1000 用户作为网络空间安全领域用户样本。为了数据集平衡,本文在其他领域随机选择了1000 普通用户作为普通用户样本。然后使用开发的数据采集程序抓取所选择的2000 用户的基本信息和用户发布的推文信息用于实验。
(2)评估指标
本文将决策树、随机森林、支持向量机三种分类算法用于实验进行对比。使用三种常见的分类模型评价指标准确率(Precision)和召回率(Recall)、F1 度量值(F1-measure,简称F1)作为衡量用户检测结果的评估指标,并采用10 折交叉验证。
(3)实验结果与分析
本文使用了前面所介绍的三种分类算法和三类用户特征用于网络空间安全领域用户检测的实验。其实验结果如表4 所示。
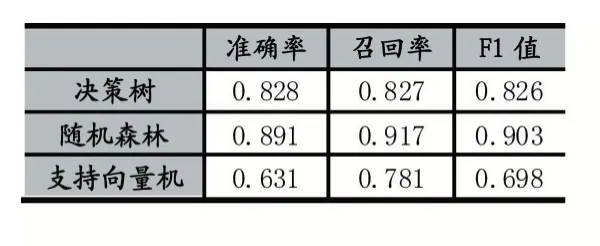
表4 全部特征实验结果
通过实验结果可以明显地发现,在三类特征中,用户文本特征的准确率、召回率、F1 值等指标最高,其用户检测效果最好,用户行为特征的其次,用户基本信息特征的分类效果最差。在三种分类算法中,随机森林的分类效果最好,在三种特征上用户检测效果均高于其他两种算法。而支持向量机算法的效果最差,特别是在用户基本信息特征和行为特征中几乎无法完成用户分类任务。因此我们选择随机森林作为网络空间安全领域用户识别模型的分类算法。
3.3 网络空间安全用户挖掘模型实验
本文从推特上选择10 个用户作为种子用户,作为模型的输入进行网络空间安全领域用户挖掘,并对本文提出的模型进行验证和测试。本文人工选择了网络空间安全领域的10 个用户作为种子用户进行领域用户挖掘。
以这10 个用户为种子用户进行网络空间安全领域用户挖掘得到的结果如表5 所示。

表5 以10 个种子用户为起始的挖掘结果
10 个种子用户的关注、粉丝和访客用户数据构建待处理的候选用户集中共包括20923 个用户。在数据采集模块采集这些用户数据后,通过加权综合的用户相似度算法从每个用户中获取相似度最高的200 个用户,最终共得到2000 个相似用户;最后通过用户分类检测模型对相似用户集进行进一步分类检测,最终挖掘到网络空间安全领域用户524 个。我们从10 个推特用户出发,最终获取网络空间安全领域的推特用户524 个,用户规模扩大50 倍,通过说明本模型可以有效地从社交网络中发现网络空间安全领域用户。
4 结语
本文针对社交网络中网络空间安全领域用户的挖掘方面做了一定的研究,设计并实现了网络空间安全领域用户挖掘模型。但仍然存在一些问题和不足,值得在日后工作中进行更深入的研究。在该领域的工作可以从以下几点进行深入和改进:
(1)在网络空间安全领域用户的识别的研究中,还存在更多的潜在的用户信息值得作为用户分类模型的特征,在后续的工作中应深入研究用户分类的特征工程,并对特征组合进行进一步优化。
(2)本文主要对网络空间安全领域用户进行挖掘,在今后的工作中,可以在已有研究的基础上扩展到其他领域进行用户挖掘技术的研究。
