融合语义标签和噪声先验的图像生成
2020-06-07张素素倪建成周子力
张素素,倪建成,周子力,侯 杰
(曲阜师范大学软件学院,山东曲阜273165)
(∗通信作者电子邮箱nijch@163.com)
0 引言
图像生成任务近年来已成为计算机视觉领域的研究重点,传统的拍摄技术易受到时空的限制,无法凭空产生不存在的事物。深度学习中的图像生成技术不仅能自动为艺术家和用户生成图像,有助于视觉理解,而且还推动了跨视觉-语言推理的研究[1],因此,准确有效地生成高分辨率图像成为目前研究的关键问题之一。
传统的图像生成主要采用非参数化生成模型和参数化生成模型:非参数化生成模型的基本思想是从数据库中匹配图像块,主要应用于图片纹理合成和半自动图像修复;参数化的图像生成技术中的自回归方法[2]调节所有先前像素上的每个像素为概率似然建模。由于传统模型直接用数据样本进行参数更新,公式推导较繁杂且模型计算量较大。
近年来,深度学习在图像生成领域取得了较好的成果,变分自编码器(Variational Auto-Encoder,VAE)[3]使用变分推理联合学习编码器和解码器到隐码和图像的映射。随后,级联优化网络(Cascaded Refinement Network,CRN)[4]使用多个分辨率倍增的模块,从真实语义分割图生成街景的高分辨率图像。图像-图像翻译模型[5]进一步使用输入-输出图像对作为训练数据,将输入图像转换为另一个图像域。目前,生成对抗网络(Generative Adversarial Network,GAN)是最常用的生成模型,其联合学习生成器和判别器。基于GAN的图像生成通常以文本为输入,已在简单数据集上(如鸟、花和人脸)生成了逼真的个体图像,但在包含多个对象和场景信息的数据集上难以生成高质量的复杂图像。将文本作为输入,仅以全局句子向量为条件,在单个实例级别上错过了相关信息,难以生成高质量的复杂图像[6],如Hong等[7]提出文本到图像的生成方法(text2Img),由于简短文本描述中的模糊性,对象的位置和大小未知,使生成过程难以约束。相较于文本结构,Johnson等[8]提出从场景图到图像生成方法(sg2im),由于场景图是较清晰的结构化表示,可用于编码对象、属性和关系,克服了文本输入的模糊性;但是场景图缺乏属性与空间信息,生成的图像分辨率较低且纹理较为模糊。
此外,噪声作为GAN输入的重要部分,包含了许多图像特征信息,但现有方法仅输入随机噪声,无法学习到图像属性信息[9];同时,用引入动量的 Adam(Adam with Momentum,AMM)算法[10]优化对抗训练,可解决Adam算法出现的模式崩溃和收敛速度慢等问题。
针对以上挑战和限制,本文使用基于语义标签和噪声先验的生成对抗网络SLNP-GAN进行图像生成。1)为克服文本描述的模糊性和场景结构的复杂性,直接使用语义标签作为输入,其包含了对象位置、空间关系、大小、形状等信息;2)为使得图像生成器学习到实例的全局属性并使得生成图像匹配输入的语义标签,采用有先验知识的噪声快速搜索到图像的特征,初步生成图像,再结合注意力机制合成高分辨率图像;3)为优化训练过程,使其更稳定且收敛更快,用AMM优化算法代替常用的Adam算法,提高图像生成的效率。
1 SLNP-GAN模型
GAN是常用的图像生成模型[11],包括:生成器(G)和判别器(D)。生成器主要用于学习真实图像的像素分布,使自身生成的图像更加真实;判别器需要区分接收的图像真假。生成器和判别器进行最小最大值的训练,两个模型相对抗最后达到全局最优。AttnGAN[12]将注意力机制[13]引入到图像生成中,但该模型的输入仍是简单文本形式,传递的信息有限且缺乏核心的空间属性规范,难以生成有复杂位置关系的高质量图像。图像-图像转换pix2pixHD[14],由语义标签对应的语义布局生成了具有多个实例-关系复杂图像;然而,由语义布局生成图像是一对多问题,许多图像可能布局一致,不同外观的对象布局也可能相同,使用全局对象特征,图像缺少纹理细节,丢失了实例级别的细粒度信息。
因此,为了生成高分辨率且匹配输入语义标签类别和布局的图像,提出了融合语义标签和噪声先验的图像生成模型SLNP-GAN,模型概述如图1所示。该模型首先直接用语义标签作为输入,同时结合噪声先验初步生成低分辨率的全局图像;再使用注意力机制引导局部细化生成器进行像素级的合成,进一步生成高分辨率的图像。即:1)输入语义标签L0,其提供了对象类别、位置大小和形状等信息,全局图像生成器Gimg0利用L0全局嵌入向量和噪声先验初步生成全局图像I0;2)由局部细化生成器Gimg1结合注意力机制,为生成的低分辨率图像的每个实例查询对应于语义标签L1的类标签,细化不同的区域,生成更高分辨率的图像I1。同时使用相同结构的多级判别器判别生成图像的真假,改变输入的语义标签可实现不同图像的生成。
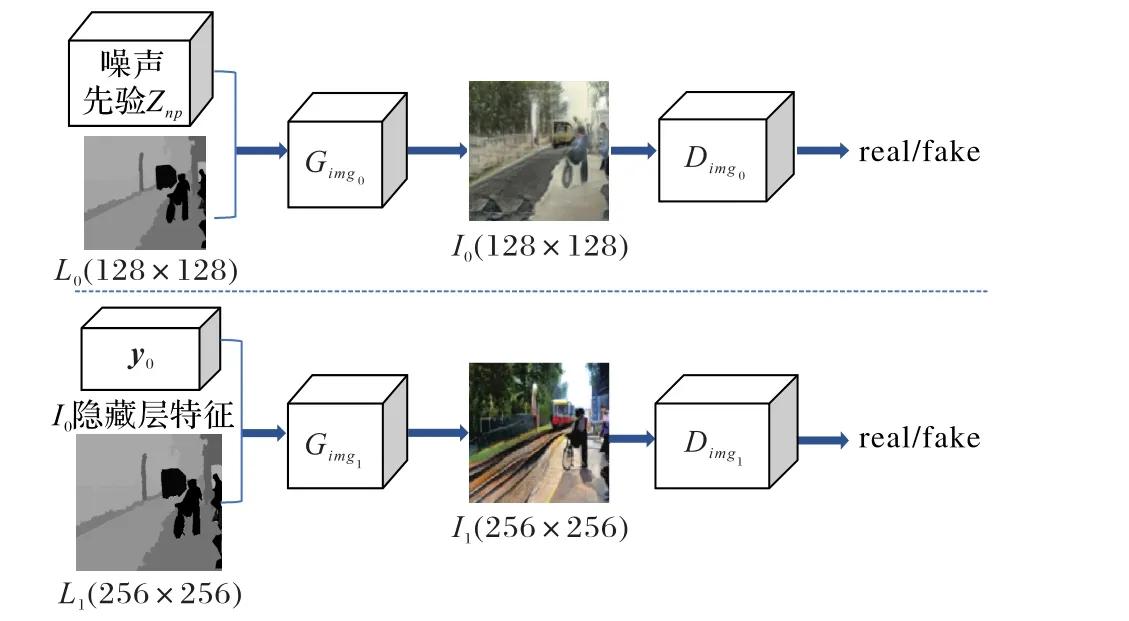
图1 SLNP-GAN模型概述Fig.1 Overview of SLNP-GANmodel
1.1 噪声先验生成机制
早期研究发现噪声分布实际代表图像属性和类别等特征信息。作为生成对抗网络的输入,若先让噪声学习到图像特征再输入网络,则生成图像的准确度能得到提升[15]。
噪声先验知识的学习方法是基于变分自编码器,其由编码器和解码器构成。变分自编码器的训练过程,如图2所示。编码器对输入高维数据进行编码得到低维隐藏层的表达,解码器对低维隐藏层解码来重构和输入大小相同的高维输出,输入和输出之间的重构误差则是模型优化的目标函数。用x表示输入图像,h表示潜在变量,x̂是重构图像。理想情况下,训练输出的重构图像应该和原图相似。编码器(Enc)和解码器(Dec)分别如式(1)、(2)表示:

其中:分布q和分布p分别被θ和Φ参数化,使网络从x映射为潜在特征向量h,并由h重构图像x,最后还原为输出图像x̂。

图2 变分自编码器训练过程Fig.2 Training process of variational autoencoder
因此,在VAE模型的基础上改进,使用先验知识的学习方法,尝试在投入模型之前先让噪声习得图像的实例属性,如图3所示。

图3 噪声先验生成机制Fig.3 Noiseprior generation mechanism
与VAE模型不同,本文先将随机噪声z输入到在数据训练集上训练好的VAE解码器中生成图像x̂,再将其作为VAE编码器输入,得到包含图像属性的噪声先验Znp,作为模型的输入以生成图像。噪声先验的具体生成过程,如图4所示。
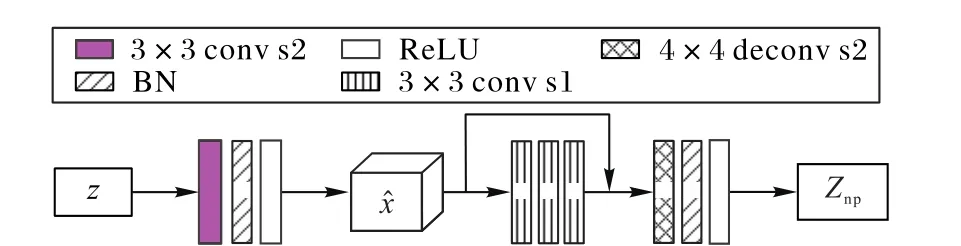
图4 噪声先验生成过程Fig.4 Processof noiseprior generation
噪声先验生成机制采用解码-编码的架构。首先对随机噪声下采样,该下采样模块由步长为2的3×3卷积层、批量归一化层和ReLU激活层构成,通过对随机噪声解码获得图像x̂;然后将初步获得的图像特征喂入由3个步长为1的3×3卷积层和一个残差连接构成的残差单元,该残差模块使得网络有更深的编码结构;最后,对获取的图像特征上采样进行编码以获得噪声先验,上采样模块由步长为2的4×4反卷积层、批量归一化和ReLU激活层构成。解码器、编码器分别如式(3)、(4)所示:

训练随机噪声获得噪声先验,目标损失函数被定义为对数似然和先验正则项之和:
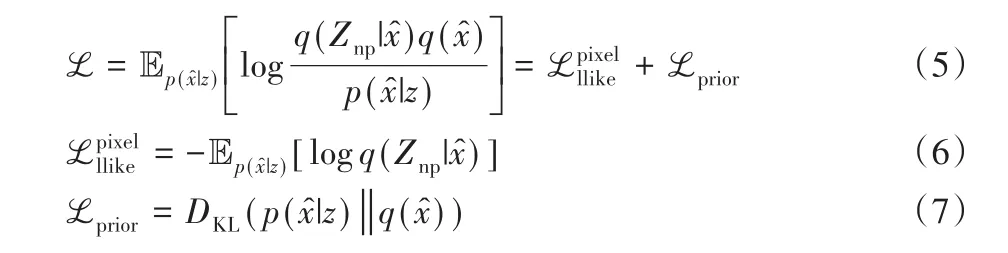
其中:z∼N(0,1)是服从正态分布的随机噪声,DKL是KL散度使用对数似然表示重构误差表示先验正则项。加入该正则项以防止出现过拟合,同时确保模型重构的噪声先验尽可能准确。训练过程中p(x̂|z)和q(x̂)应尽可能接近,以最小化KL散度。
由此,通过对随机噪声进行预训练,对潜在分布q(x̂)增加先验约束,舍弃了与现实相违背的噪声数据,生成了包含图像特征有先验知识的噪声。生成器可以从分布特性明确的噪声中快速搜索到图像的属性特征,解码出噪声先验,同时将不低于维度下界的噪声映射到合理的图像特征空间,生成基本符合属性和类别特征的图像。
1.2 多阶段图像生成器
1.2.1 全局生成器
如图5(a)所示,随机噪声学习到图像中实例的属性,得到有先验知识的噪声;同时,全局生成器Gimg0计算128×128语义标签L0的全局嵌入向量G'∈ℝDout,结合G'和获得的噪声先验Znp进行语义编码,并将二进制实例语义编码聚合为标签映射M i∈ {0,1}H∗W∗L,其中i∈ (1,2,…,T)表示实例数,W、H和L分别为实例的宽、高和类别标签,当且仅当存在类别为k且覆盖像素(i,j)的实例掩码时,即:Mi,j,k=1 时,在该位置进行图像像素表示。计算L0的全局嵌入向量G'的同时,对语义标签L0进行下采样得到μ0,连接M i和μ0,输入到残差块和上采样层,由隐藏层获得图像隐层特征y0,输送到一个3×3卷积层,初步合成低分辨率的全局图像I0,如式(8)、(9)所示:
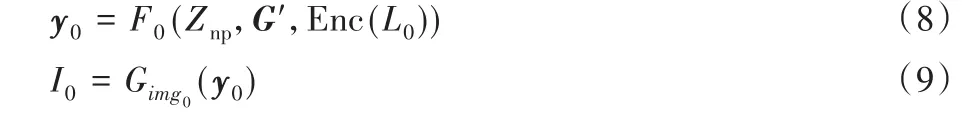
其中:Enc(L0)是低分辨率实例的编码,F0被建模为神经网络,y0是获得的图像隐层特征。式(9)表示全局生成器Gimg0根据该隐层特征y0生成低辨率图像I0。
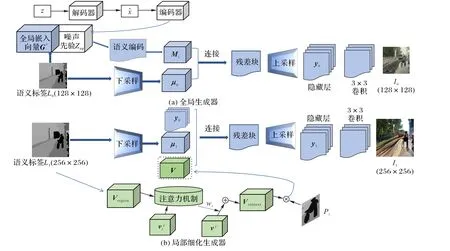
图5 SLNP-GAN图像生成器架构Fig.5 Architectureof imagegeneratorsin SLNP-GAN
1.2.2 局部细化生成器
全局图像I0的生成仅利用全局信息,缺少细粒度实例级别的信息,出现过度平滑的纹理,没有足够的细节和高层次的抽象特征。由于传统的网格注意力机制已成功用于图像-图像翻译[16]和图像问答[17],AttnGAN将注意力机制引入文本-图像生成任务中,允许简单图像的生成。受此启发,本文在语义标签-图像生成过程中首次引入注意力机制,如图5(b)所示。局部细化生成器用初步生成的图像子区域向量查询高分辨率语义标签中的相关实例,获得基于背景信息的实例向量,优化调整以合成匹配实例标签的更准确、细粒度图像。
注意力机制主要有两个方面:首先,根据所有输入信息获得注意力分布;然后,根据注意力分布来计算输入信息的加权平均。将输入信息向量X作为信息存储器,q为作为查询向量来选择X中的相关信息,该过程需要被选择信息的索引。定义变量n为被选择信息的索引,注意力分布αi表示X中被选择的第i个信息与查询q的相关程度。则注意力分布αi构成的概率向量为:
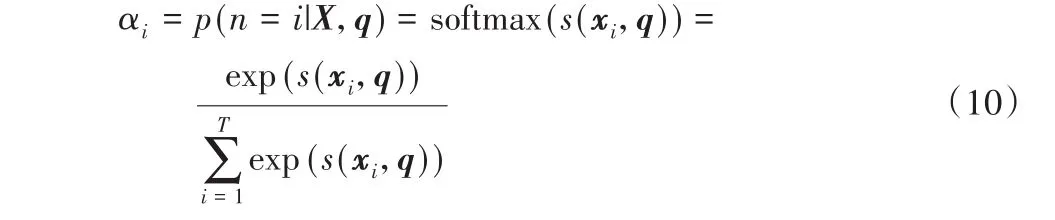
其中s(x i,q)是注意力打分函数,可用点积模型计算:

其中:x i是输入的第i个信息,softmax将权重归一化,得到符合概率分布区间的注意力分配值,用该权重分布表示不同输入受关注的程度。
最后,利用加权平均对输入信息汇总得到注意力值:

局部细化生成器Gimg1引入的注意力机制,如图6所示。通过关注L1中与I0子区域实例向量Vregion对应的最相关子标签,来获取实例像素级别的信息,细化不同区域的像素特征。Gimg1使用I0的子区域向量Vregion来查询语义标签L1中有更详细信息的相关实例向量v i'(如:实例具体为woman,而非I0中Vregion的person),为每个的实例向量v'分配注意力权重wi,然后由wi计算输入信息的加权和,生成基于背景信息的实例向量Vcontext,计算生成图像的第j个子区域时的背景向量,如式(13):

其中:v i'是包含详细信息的第i个实例向量,生成第j个子区域时,对第i个实例分配的注意力权重wj,i使用注意力机制中权重分布的计算公式求解,得到符合概率分布区间的注意力分配值,如式(14)所示:
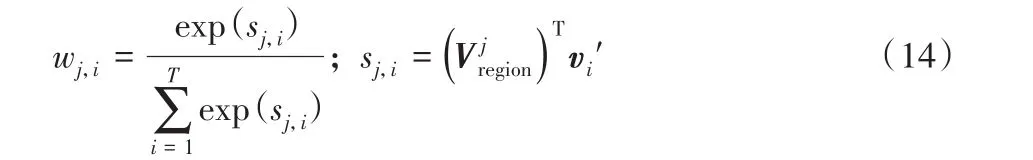
其中:注意力打分函数sj,i采用点积模型计算,使用softmax进行权重归一化。

图6 局部细化生成器的注意力机制Fig.6 Attention mechanism of local refined generator
此外,生成过程中语义标签可能有多个像素覆盖同一个像素点,可用实例级别的背景向量解决。为生成外观清晰且真实的图像,必须决定用哪个背景向量对重叠部分像素表示。因此,求解第i个实例的每个像素Pi与实例级别的背景向量的向量外积,如式(15)所示:

其中:⊗是向量外积,若多个像素覆盖同一个像素点,则对多个像素点最大池化,使像素Pi与最相关的实例级别的背景向量Vciontext关联,在该位置进行像素表示,获取包含底层细节信息向量V。
与全局生成器不同,如图5(b)所示,局部细化生成器为将全局信息从Gimg0整合到Gimg1,Gimg1残差块的输入是含底层细节信息的向量V和语义标签L1下采样信息μ1,以及Gimg0隐藏层的特征y0。然后经上采样获取I1的隐藏层特征y1,并输送到3×3卷积层,由Gimg1生成256×256高分辨率图像I1。如式(16)、(17)所示:
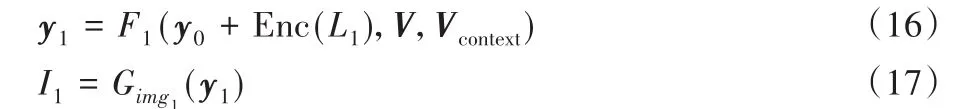
其中:Enc(L1)是高分辨率实例编码,V表示含底层细节信息的向量、Vcontext为实例级别的背景向量,F1被建模为神经网络。式(17)表示Gimg1由隐层特征y1生成高分辨率图像I1。
因此,SLNP-GAN采用多阶段的图像生成策略。全局生成器结合噪声先验,直接输入语义标签,生成了布局和语义标签基本一致的全局图像;然后局部细化生成器使用注意力机制完善局部细节,生成了256×256图像。
1.3 多级图像判别器与损失函数
为区分真实图像和合成图像,判别器要有较大的感受野,需要更深的网络或更大的卷积内核,会导致容量增加、过拟合和重复图案。为解决该问题,对不同分辨率图像使用相同架构的多级判别器Dimg0和Dimg1分别进行训练。判别器架构如图7所示。
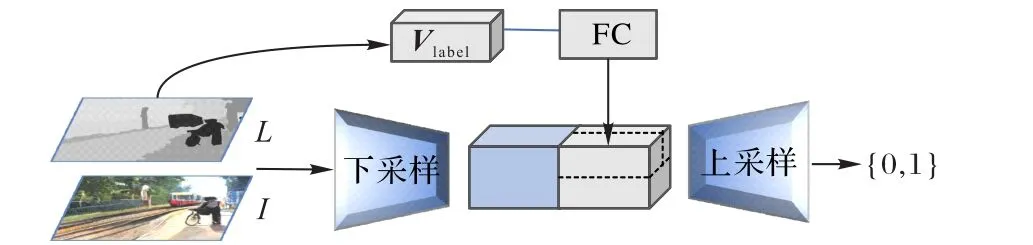
图7 图像判别器架构Fig.7 Architecture of imagediscriminator
首先,连接生成的图像I和语义标签L,输送到下采样块以产生大小为h'×w'的特征映射。同时将L的标签嵌入向量Vlabel全连接并进行空间平铺,经上采样计算判别器的决策分数。虽然二者有相同的结构,但是Dimg0在粗粒度级别指导Gimg0生成和语义标签的布局大体一致的图像I0,具有最大的感受野和图像的全局视图;在细粒度级别的Dimg1用于引导Gimg1生成纹理逼真的I1。将低分辨率模型扩展到高分辨率仅需在细粒度级别添加判别器,无需从头重新训练,由此也使得生成器由粗粒度到细粒度的训练更容易。
图像生成器G={Gimg0,Gimg1}和多级判别器的对抗训练是多任务学习过程。GAN交叉熵损失函数为:
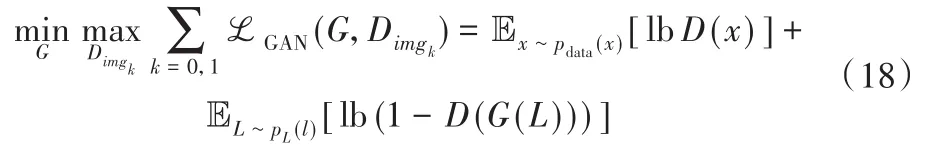
其中:x表示真实图像,D(x)表示对真实样本进行判别,判别结果越接近1,说明模型性能越好;同样,对生成样本G(L)的判别值越接近0,也说明模型性能越好。
生成对抗网络训练过程具有不稳定性,易导致模式崩溃,Johnson等[18]提出了感知损失,该损失能对超分辨率图像重构并进行风格转换[19],因此,SLNP-GAN模型采用与之相关的特征匹配损失[20],从判别器网络的多个层中进行特征提取,比较真实和生成图像的特征,学习匹配真实和合成图像的中间表示,使得生成结果和真实图像接近。将Dimgk的第i层特征提取器表示为,则特征匹配损失为:
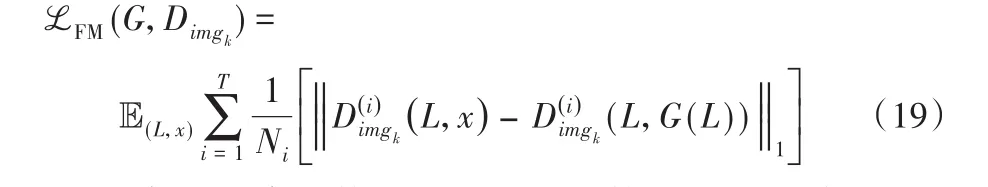
其中:Ni为每层元素的数量,T表示总层数,L和X分别表示语义标签图和相对应的真实图。
因此,SLNP-GAN的完整目标损失函数为GAN损失函数和特征匹配损失函数的加和,如式(20)所示:
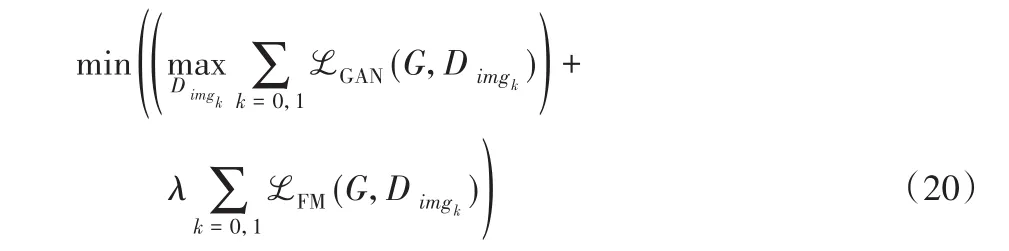
其中:ℒGAN为GAN损失函数项,ℒFM为特征匹配损失项,λ表示特征匹配损失的权重分配值。
1.4 AMM算法优化训练
对抗网络训练通常使用Adam优化算法,仅计算损失函数的一阶梯度,不同的参数需要设置不同的学习率。由于生成对抗网络的目标函数是复杂高维且非凸的随机函数,该算法在训练时不稳定,可能会跳过全局最优解,导致模型难以收敛[21]。
如表1所示,本文使用基于Adam算法和动量思想提出的AMM算法,对Adam的参数更新进行了改进。初始时AMM算法和Adam算法的方向均为PAdamt。其中:δ是常数,初始化为10-8,和分别表示一阶矩偏差修正和二阶矩偏差修正,由式(21)、(22)所示:
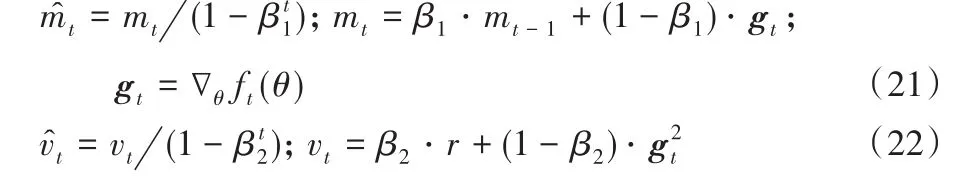
其中:mt和vt表示梯度和梯度平方的指数移动平均,即梯度的一阶和二阶原始矩估计;βt1和βt2分别表示β1和β2的t次方,两者控制指数移动平均mt和vt的衰减速率;g t=∇θft(θ)表示第t个损失函数中关于变量θ的梯度向量,即ft关于θ的偏微分。将mt和vt的初始化为0会产生误差,但是这些误差可以通过修正消除,从而产生无偏估计m̂t和v̂t。

表1 AMM和Adam参数更新对比Tab.1 Parameter update comparison between AMMand Adamalgorithm
计算每一步迭代更新量时,Adam算法仅和初始学习率以及原来方向有关,而AMM算法每步迭代更新量为其上一个迭代步与Adam当前迭代步的加权之和,其中上个迭代步所占权重为α,该更新过程体现了经典动量的思想。最后对时间步为t的参数θt进行参数更新时,Adam算法中,θt是t-1时的参数θt-1与更新量Δθt之和,AMM算法将参数θt-1和第t步的迭代更新量之差进行参数更新。
相比Adam算法,AMM算法结合了动量和基于L2范数优化算法的优点,更加稳定而且收敛速度更快,因此采用AMM算法对图像生成任务优化训练,稳定训练过程并加快收敛速度。
2 实验结果与分析
2.1 实验环境与数据集
本文模型采用深度学习框架PyTorch 1.2.0,实验环境为Linux 4.4.0-135-generic操作系统。使用单个显存为16 GB的Tesla P100在COCO_Stuff和ADE20K数据集上分别训练约171 h和163 h。对于所有数据集,生成器和判别器的学习率设置为0.000 1和0.000 4,使用AMM算法优化训练,一阶矩和二阶矩估计的指数衰减速率β1,β2设置为0.9和0.999,其中β1,β2∈ [0,1),常数δ=10-8,初始化历史迭代步所占的权重ω和学习率η分别为0.9和0.001。
COCO_Stuff数据集[22]包含182个语义类,具有像素级的标注。按照COCO_Stuff数据集既定的划分,本文使用118000张训练集、5000张验证集图像,每张都有5句文本描述和对应的语义标签。
ADE20K数据集[23]中的每个文件夹包含对场景分类的图像,对于每一张图像,目标和对象分割被存储为两个不同的文件,所有的图像和对象实例都有注释。该数据集包含150个语义类的场景,可用于场景的感知、解析、分割、多物体识别和语义理解。按照ADE20K数据集给定的训练集和验证集的划分,实验将20 210张图像作为训练集,2 000张图像作为验证集。对于两个数据集,均使用来自训练集的标签和图像配对数据来训练全局布局和实例像素合成,使用验证集中的语义标签进行图像生成。
2.2 实验评价指标
将SLNP-GAN模型生成的图像输入语义分割模型,比较预测的语义分割掩码和真实掩码的匹配程度。生成图像与真实图像越相似,则语义分割模型预测到的标签越接近真实标签。采用DeepLabV3网络获取平均交并比(mean Intersection over Union,mIoU)和像素精准度(Pixel Accuracy,PA)指标评估生成图像的准确度:
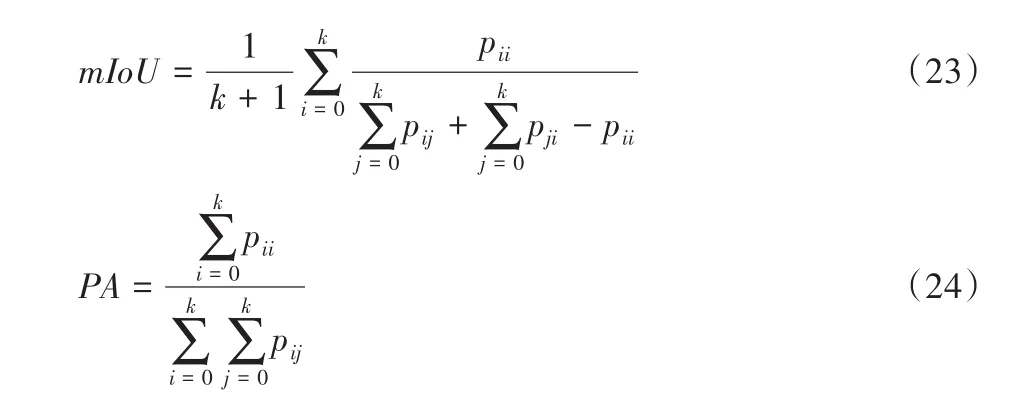
其中:mIoU是在每个类的真实值和预测值两个集合的交集和并集之比(Intersection over Union,IoU)的均值,k为类的个数,此处定义为k+1类(包含一个空类或背景);pii为真正例数,pij和pji分别为假负例数和假正例数;PA表示正确分类的像素占总像素的比例。
同时利用训练好的Inception v3网络来提取中间层特征,用高斯模型的均值μ和协方差来计算Frechet初始距离(Frechet Inception Distance,FID)。真实图像和生成样本在特征空间的Frechet距离表示如式(25)所示:
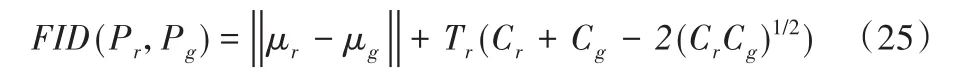
其中:Tr表示矩阵对角线上元素的总和,C是协方差。FID得分越低,表示生成的图像与真实图像越接近,图像质量和多样性更高,对噪声的鲁棒性更好。
2.3 结果分析与对比
SLNP-GAN进行多阶段图像生成,如图8所示。全局生成器由训练得到的噪声先验学习到粗粒度的属性特征,并且生成了和语义标签布局一致的全局图像,但是出现了过度平滑的特征,缺乏细粒度纹理,第一阶段的生成结果示例如图8(a)所示;因此,局部增强生成器结合注意力机制,查询高分辨率语义标签中的相关实例,获得了基于背景信息的实例向量,优化调整合成了匹配实例标签的更准确、细粒度图像,第二阶段的生成结果示例如图8(b)所示。

图8 不同阶段生成结果示例Fig.8 Result examplesof different generation stages
输入相同的语义标签,将SLNP-GAN和不同方法的生成结果进行了对比,如图9所示。sg2im方法是由场景图推测语义标签,并使用级联优化网络(Cascaded Refinement Network,CRN)模型将该标签转化为64×64的图像。由于场景图缺乏核心对象属性和空间交互信息,并且该方法没有引入注意力机制,缺少整体布局的细粒度编码信息,难以在正确的位置生成与与布局一致的相关实体(如图9(c)踢足球者缺失人体特征)。此外,由于场景结构仅定义了实体和简单的方位信息,未能解决空间位置接近的对象像素重叠问题,无法协调和其他对象的像素表示,导致出现了难以分离的不同对象外观(如图9(c)中的公交车未能和背景像素信息区分,不同大象的躯干和轮廓不清晰且出现像素遮挡)。

图9 在COCO_Stuff数据集上不同方法生成图像对比Fig.9 Comparison of imagesgenerated by different methodson COCO_Stuff dataset
text2img模型输入的是文本,由边界框生成器和形状生成器构建语义标签,最后经图像生成器生成128×128的图像。该方法是跨文本-图像的多模态生成,由于输入文本中的每个单词都具有描述图像内容的不同级别的信息,但是text2img仅以单个句子向量为条件未引入注意力机制,所有实例的权重都相同,没有考虑每个单词对生成结果的影响,缺少每个实例和生成图像整体之间的交互。对于单一对象的生成效果较好(如图9(d)滑雪者和公交车),但是难以生成包含较多实例的高分辨率场景,也出现了不同实例难以分离,像素重叠与特征融合的现象(如图9(d)大象和踢足球者)。
而SLNP-GAN直接输入语义标签而非将其作为中间表示生成图像,提供了实例位置形状等约束,包含不同实例之间的空间交互关系,因此,在相应的位置都合成了对应的实例布局。同时,加入的噪声先验习得了实例的全局属性,根据布局合成了基本符合现实属性信息的实例。此外,对于不同实例像素重叠的问题,采用对多个像素最大池化,同时结合注意力机制来获得最相关的实例向量,在该位置进行像素表示,解决了不同实例像素遮挡的问题,生成了包含细粒度的纹理特征。另外,相较于其他直接合成图像的方法,由于SLNP-GAN采用多阶段生成策略,合成了256×256的较高分辨率复杂图像(如图9(e))。
同时,为避免单一数据集可能出现的偏差,使用ADE20K数据集也进行实验,如图10所示。输入语义标签和噪声先验,SLNP-GAN经多阶段同样生成了高质量的256×256图像。由于输入的语义标签提供了全局布局约束,即使对于复杂场景,SLNP-GAN也能较好地生成符合语义标签的布局。同时,先验知识的噪声作为输入,摒弃了与现实违背的噪声,因此生成的图像几乎没有不合理的属性特征。另外,结合了注意力机制,对于包含较多实例的复杂场景,该模型也能根据权重分配,获取最相关实例向量并进行像素表示,几乎未出现其他模型常见的多个实例难以区分、像素重叠等现象。

图10 SLNP-GAN基于ADE20K数据集的生成结果Fig.10 Images generated by SLNP-GAN on ADE20K dataset
此外,对噪声先验的效果进行了实验对比,如图11所示。SLNP-GAN在图像生成中加入有先验知识的噪声而非随机噪声。没有加入噪声先验,由于随机噪声包含许多与现实相违背的噪声数据,输入的噪声包含违背现实的特征信息,生成器作为映射函数,只能合成粗粒度的图像,如图11(c)所示。由于缺少基本的噪声先验约束,随机噪声各个维度随机取值,各向同性,没有侧重性,难以提取到有效特征信息。导致相邻像素之间出现一致的特征,生成的图像整体趋近于单模态且纹理不清晰。加入噪声先验,如图11(d),模型舍弃了与现实违背的噪声,为噪声增加了先验知识,引导生成器从先验噪声各个维度获取相应的特征信息,从而学习到全局属性和多模态的细节特征,生成了符合真实标签的特征图像。

图11 噪声先验的效果对比Fig.11 Effect comparison of noise prior
基于COCO-Stuff和ADE20K数据集的注意力可视化分别如图12(a)、(b)所示。图中高亮部分表示生成过程中每一步关注的图像实例区域,在局部细化生成器生成图像的过程中,引入的注意力机制关注生成图像的不同区域并分配注意力,获取语义标签每个位置对应的最相关实例信息,在该位置进行像素级别的图像生成,完善不同实例的细节特征。

图12 注意力机制可视化图Fig.12 Visualization of attention mechanism
为比较Adam和AMM算法的性能,同时避免单个数据集的误差,在COCO_Stuff和ADE20K数据集上均进行了实验。对比结果如图13、14所示。
图13是Adam和AMM优化算法在COCO_Stuff数据集上训练时损失值和收敛的变化,图14是两算法在ADE20K数据集的性能对比。实验均选取了相同的样本量,参数β1,β2都被初始化为0.9和0.999,学习率均为0.001,图13、14中的D_real和D_fake指标分别代表判别器把生成的图像判别为真和假。刚开始迭代时,二者的损失值在所有数据集上都相近。随着次数的增加,接近100 000次时,图13(a)和图14(a)中Adam的D_fake和D_real对应的损失函数值接近于0.8,并持续在0.8附近波动且幅度较大;而图13(b)和图14(b)中AMM算法在接近50 000次时,D_fake和D_real对应的损失值均已趋近于0.5,并持续在附近波动。对比可知:在不同的数据集上,AMM算法均能将训练的收敛速度提升大约一倍,并缩短收敛时间;而且在相同的迭代次数条件下,AMM算法的损失函数值均小于Adam算法的损失值,波动幅度更小而且训练更稳定。
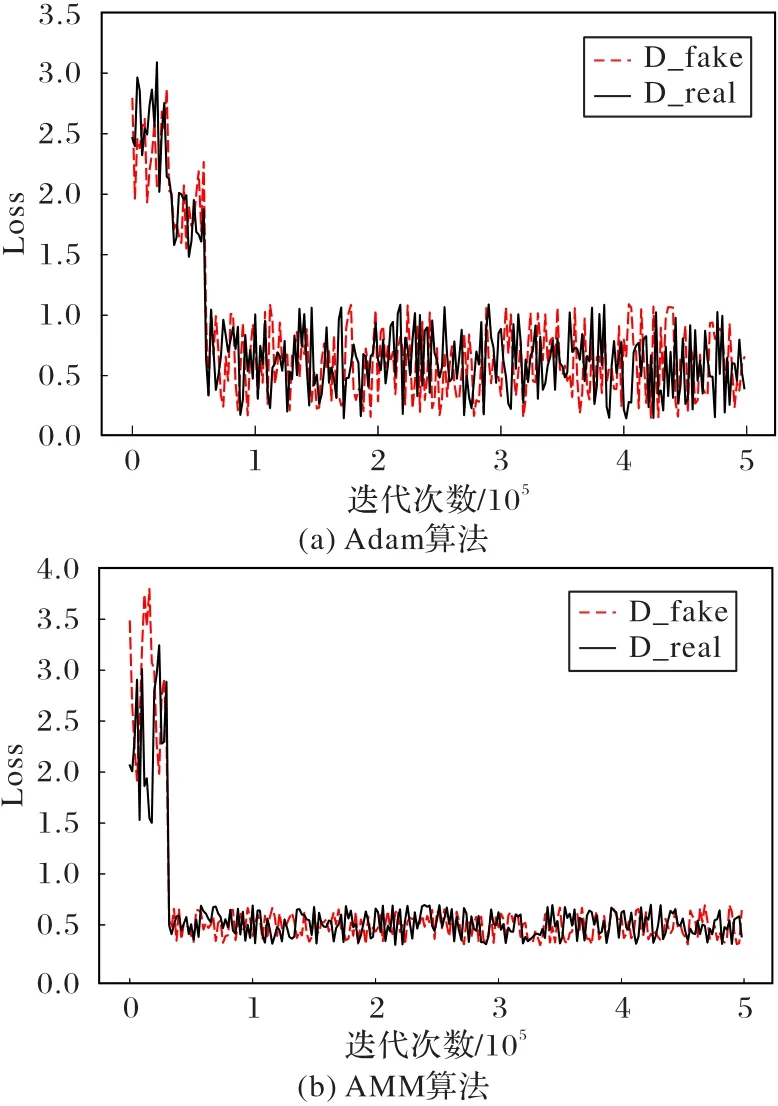
图13 基于COCO_Stuff数据集的训练性能对比Fig.13 Comparison of trainingperformanceon COCO_Stuff dataset
最后,将生成的图像输入到语义分割网络DeepLabV3中得到mIoU和PA评估值,并用Inception v3网络提取中间层特征获得FID指标,在COCO_Stuff和ADE20K数据集上不同方法的评价指标对比,分别如表2和表3所示。
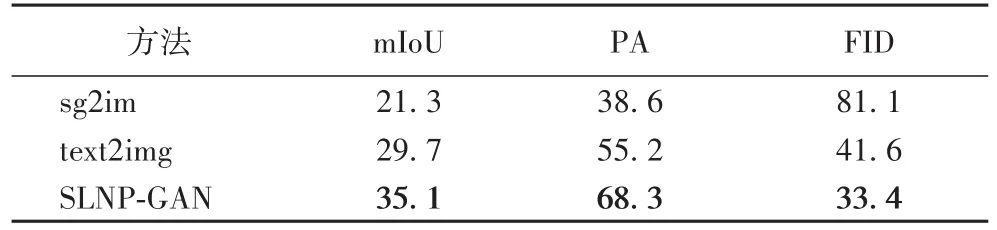
表2 COCO_Stuff数据集上不同方法的评价指标对比Tab.2 Comparison of evaluation metrics between different methods on COCO_Stuff dataset
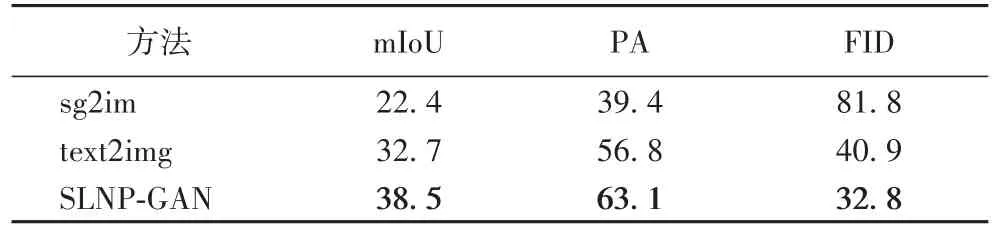
表3 ADE20K数据集上不同方法的评价指标对比Tab.3 Comparison of evaluation metrics between different methodson ADE20K dataset
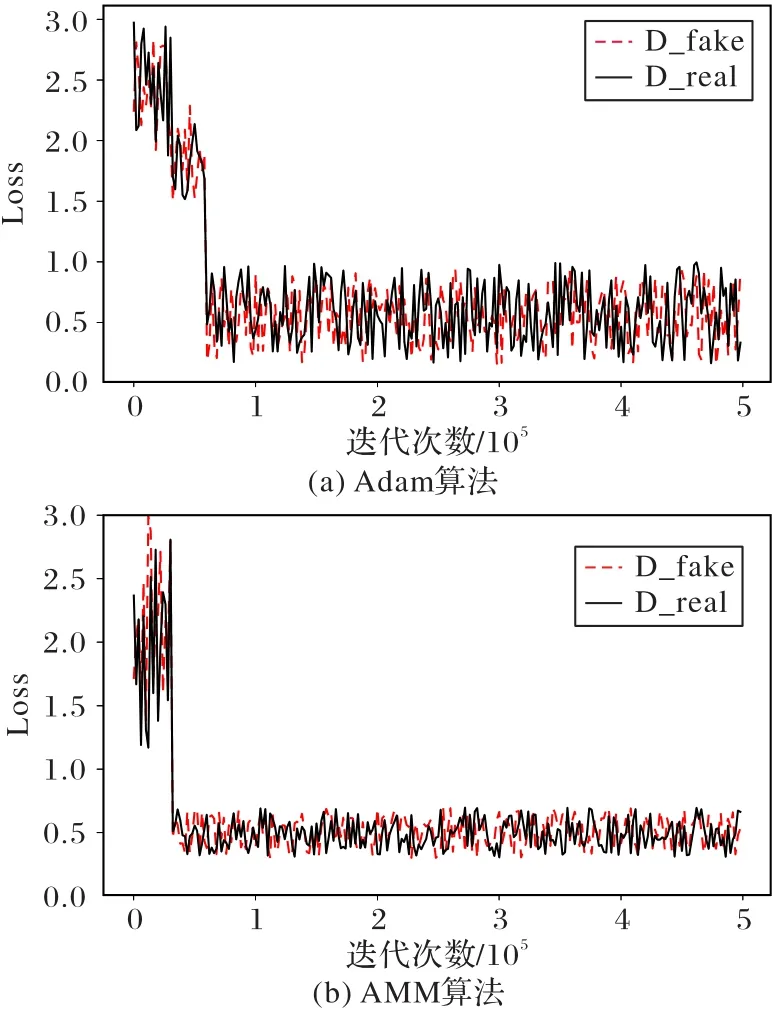
图14 基于ADE20K数据集的训练性能对比Fig.14 Comparison of trainingperformanceon ADE20K dataset
表2、表3的结果表明,相较于text2img,SLNP-GAN模型在COCO_Stuff和ADE20K数据集分别将mIoU值提高了18.18%和17.74%,像素准确度(PA)增长了23.73%和11.09%,FID值降低了19.71%和19.80%。由于sg2im和text2img的输入分别为场景结构和文本,而SLNP-GAN直接输入语义标签,能够合成更符合语义布局的图像。因此,将生成结果喂入Inception v3网络,得到的语义分割图与真实标签的匹配度较高,得到了较高的平均交并比(mIoU)值。此外,其他方法直接输入随机噪声,没有摒弃与现实不符的噪声数据,而本文使用噪声先验,学习全局图像属性特征,生成的图像包含合理的像素特征,像素精准度(PA)最高。同时,引入的注意力机制给不同的实例分配了不同的权重,在有像素重叠的区域选择最相关的实例进行像素特征表示,生成结果与真实图像距离较近,FID最低。而sg2im和text2img没有区分生成图像的不同实例权重,出现大量的实例遮挡、像素重叠等问题,像素精准度较低,而且生成样本和真实图像在特征空间的距离相差较大(FID值较高)。对比可知,SLNP-GAN使用语义标签直接作为输入,加入噪声先验并结合注意力机制能生成高质量的准确图像。
3 结语
针对复杂语义标签生成以实例为中心的图像分辨率不高而且训练效率低的问题,使用基于语义标签和噪声先验的SLNP-GAN模型在COCO_Stuff和ADE20K数据集上进行真实且高分辨率图像的生成。首先,使用训练获得的噪声先验学习到全局图像属性提升生成结果的准确度,同时用语义标签替代文本或场景图直接作为输入;然后,结合注意力机制生成包含细粒度纹理信息的图像;最后,使用AMM算法对图像生成模型进行优化,使得训练更稳定且收敛更快。实验结果表明,SLNP-GAN模型在不同的数据集上都可以生成分辨率更高的图像、训练过程较稳定而且损失函数值更小。然而图像
生成效率和分辨率仍需进一步提升和完善,后续工作重点将集中于由知识图谱推理得到相应的语义标签,以端到端的方式由一张语义标签生成多张图像以及视频合成的研究。
