基于多核模糊粗糙集与蝗虫优化算法的高光谱波段选择
2020-06-07陈红梅
张 伍,陈红梅
(西南交通大学信息科学与技术学院,成都611756)
(∗通信作者电子邮箱hmchen@swjtu.edu.cn)
0 引言
高光谱遥感技术是现代卫星遥感技术领域的重大突破。高光谱成像仪能对同一物体在几百个光谱波段上同时成像,并构成像素点的连续曲线。因为高光谱波段图像间相似性极高,产生了很多不必要的冗余,不便于存储以及计算,甚至会产生“HUGHES”问题[1],所以需要对其进行降维处理。
目前,高光谱图像降维主要分为特征提取以及波段选择两种方式:特征提取是采用一些数学方法对属性值进行变换,将其重新映射为新值进行降维,这样做会破坏图像原有的物理含义,不利于图像的解译;高光谱波段选择是通过算法将波段进行组合,使用一些重要的波段代表整个高光谱数据集。
高光谱波段选择算法根据是否利用地物真值信息,可以分为无监督波段选择算法以及有监督波段选择算法。刘雪松等[2]提出了使用相对熵间接衡量波段信息差异的最大信息量波段选择方法;刘春红等[3]提出了通过计算高光谱波段标准差以及与前后皮尔逊系数之和的比值,进行优先度排序的自适应波段选择算法;此外还有基于层次聚类[4]、密度峰值聚类[5]、k-means[6]聚类的高光谱波段选择算法,它们从聚类簇中找出代表波段,形成波段子集;Zhang等[7]根据波段间的相关性递增挑选高光谱波段。上述算法不需要地物真值信息,是无监督的波段选择算法。Liu等[8]提出基于邻域粗糙集理论的高光谱波段选择算法,并且设置扰动,分析算法稳定性;Patra等[9]用粗糙集理论计算高光谱波段的相关性和重要度,定义了一个新的准则,选择相关性及重要度高的波段;Su等[10]提出了基于双层粒子群的高光谱波段选择算法,采用JM(Jeffreys-Matusita)距离及最小丰度方差估计(Minimum Estimated Abundance Covariance,MEAC)作为适应值;Guo等[11]根据真实地物真值表与高光谱波段间的互信息进行波段选择。这些算法是有监督波段选择算法。
目前绝大多数波段选择算法均采用前向贪婪式的搜索方式,每次挑选当前最优解,通过不断迭代直至选出最终解。贪婪算法具有较高的计算效率但很容易陷入局部最优的情况。近些年来,部分学者尝试将演化算法引入特征选择领域来更好地选择最优特征子集。演化算法具有群体搜索策略和群体中个体之间信息交互的特性,不容易陷入局部最优解。
蝗虫优化算法[12]是Saremi等于2017年提出的一种元启发式算法,它模仿蝗虫群体中蝗虫的行为探索目标解,具有较强的探索和开发能力。随后Mafarja等[13]提出了二进制版本的蝗虫特征选择算法,将蝗虫算法应用于特征选择问题。高光谱数据中不同地物类别对象间的分割区域蕴含有大量不确定信息,核模糊粗糙集是不确定信息分析的新兴范式。多核学习能考虑不同核函数间的互相影响,提高对不同数据分布情况的适应性。本文通过多核模糊粗糙集对高光谱波段中的不确定信息进行分析和度量,同时基于蝗虫优化算法探索波段组合。高光谱波段选择旨在选择出信息量大、相关度低、便于后续分类的波段子集。对应考虑波段信息熵、波段相关性、模糊粗糙集波段依赖度构建蝗虫个体解的评价函数。本文算法与常用高光谱波段选择算法相比,在获取较少波段个数的同时具有较高的地物分类能力。
1 相关基础知识
本章介绍蝗虫优化算法以及多核模糊粗糙集计算模型。
1.1 蝗虫优化算法
不同于粒子群算法中粒子根据当前位置、个体历史最佳位置、群体历史最佳位置进行更新,蝗虫优化算法的个体位置要根据群体内的每一个个体位置进行更新。蝗虫优化算法流程如下。


1.2 基于二进制版本的蝗虫特征选择算法
蝗虫优化算法在开发、探索、避免局部最优及收敛速度方面有着优秀的性能,该算法能较好地应用基于包裹式的特征选择算法中。根据特征选择问题的性质,其中搜索空间可以用二进制值0-1表示。Mafarja等[13]提出了二进制版本的蝗虫特征选择算法。

1.3 核模糊粗糙集
Pawlak基于等价关系提出了经典粗糙集理论,它能在不损失信息的情况下,获取核心知识。但是在现实生活中,对象属性值可能是数值型,并不能直接通过等价关系进行比较。因而Dubois等[15]提出了基于模糊等价关系的模糊粗糙集理论,扩展了经典粗糙集理论。
定义1[14]设U是论域,A:U→ [0,1],则称A是U上的一个模糊集合,A(x)称为模糊集合A的隶属函数。对于任意的x∈U,A(x)表示x对A的隶属度。U上全体模糊集的集合用F(U)表示,A∈F(U)意指A是U上的一个模糊集合。
定义2[15]设U,V为两个论域,当满足R∈F(U×V)时,则称R为U到V的一个模糊关系,隶属度R(u,v)称为(u,v)∈ (U×V)关于R的相关程度。
定义3[14]设U是有限论域,U≠∅,且R是U上的二元模糊关系,若x,y,z∈U,R满足:
自反性R(x,x)=1;
对称性R(x,y)=R(y,x);
min-max传递性 min(R(x,y),R(y,z)) ≤R(x,z);则称R是一个模糊等价关系。
定义4[15]设R为论域U上的一个模糊等价关系,A是U的一个模糊子集,模糊集A∈F(U)的上、下近似定义为:
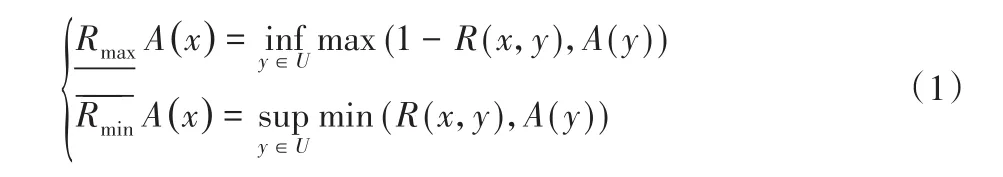
在机器学习领域中,常常使用高斯核计算两个对象间的相似性。下面介绍核模糊粗糙集和与之相关联的一些概念。Hu等[16]给出了核模糊粗糙集的定义。高斯核函数为

1.4 多核模糊粗糙集
由于样本数据分布情况不同,单一核函数并不能很好地适应每一个数据集,故基于单核学习的方法受到了一定限制。传统的核模糊粗糙集并没有考虑不同核函数之间的影响,基于此,Hu等[19]提出可以采用组合核的方式构建出一个新的核函数来进行学习。常用的方法有线性组合以及非线性组合方法。
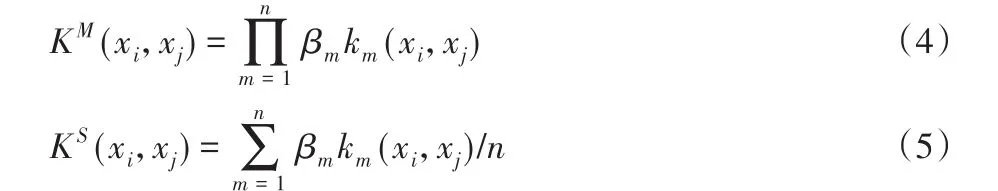
其中:n是核函数的个数,βm∈[0,1]是第m个核函数的权重。
定义7 给定决策表U,C,D,RK是论域U上的多核模糊相似关系,则基于S-T算子的模糊空间多核粒化下、上近似算子分别定义如下:

定义8 给定决策表U,C,D,RK是论域U上的多核模糊相似关系。U在决策属性上形成的划分为{d1,d2,…,d i}。那么决策属性D对B⊆C的模糊正域定义如下:

定义9 给定决策表U,C,D,RK是论域U上的多核模糊相似关系。U在决策属性上形成的划分为{d1,d2,…,d i}。那么决策属性D对B⊆C的属性依赖度定义如下:

2 基于多核模糊粗糙集与蝗虫优化算法的高光谱波段选择
本文根据Mafarja等提出的二进制版本的蝗虫特征选择算法进行波段搜索,同时综合考虑波段信息熵、波段相关性、核模糊粗糙集属性依赖度构造适应度函数,评价每一个高光谱波段子集。
2.1 基于模糊粗糙集的蝗虫优化算法适应度函数
本文构建出一种新的适应度函数,先计算波段子集内各波段的信息熵之和与依据该波段子集计算出的属性依赖度的乘积,然后使用该乘积与波段子集内各波段间相关系数的和的比值作为该波段子集的适应度值。
信息熵能用来表示信息的不确定性,本文把信息熵含量作为高光谱波段选择的适应度函数的一部分。信息熵公式定义如下:a
其中PA(a)表示像素a出现的概率。图1是去除水汽及噪声污染的3.1节数据集中每个波段的信息熵变化。

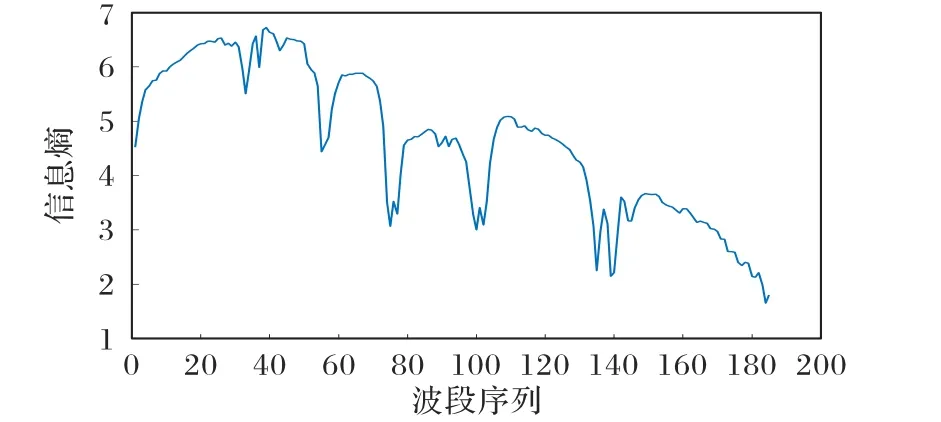
图1 Indian Pines波段信息熵Fig.1 Information entropy in Indian Pines band
给定决策系统U,B,D中,U={x1,x2,…,xn}是n个像元的集合,B={b1,b2,…,bm}是m个波段的集合,D是像元所对应的地物真值类标。将波段bi以及波段bj每个像素点的下近似之差取绝对值并且求和的方式计算两个波段间的差异。
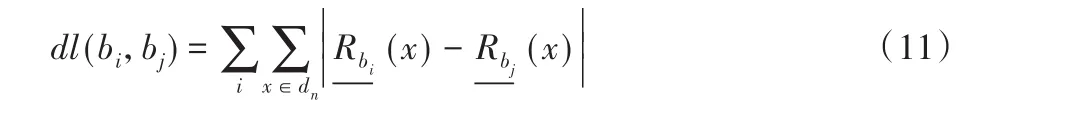
设蝗虫个体解所代表的波段子集为B={b1,b2,…,bn},高
光谱图像对象类别数为I,信息熵之和,波段间的相似度之和,以及波段子集所计算出的波段属性依赖度
由于蝗虫优化算法将最小的适应度函数值设为最佳,故将相关性放置在分子,信息熵及粗糙集下近似的乘积放置在分母。这样可以保证当波段相关性总和较小,及波段子集信息熵之和与波段属性依赖度乘积较大时,整个适应度函数的值较小。适应度函数如下所示:

技术路线如图2所示。图左侧为适应度函数的构建思想,右侧为迭代寻优的步骤。
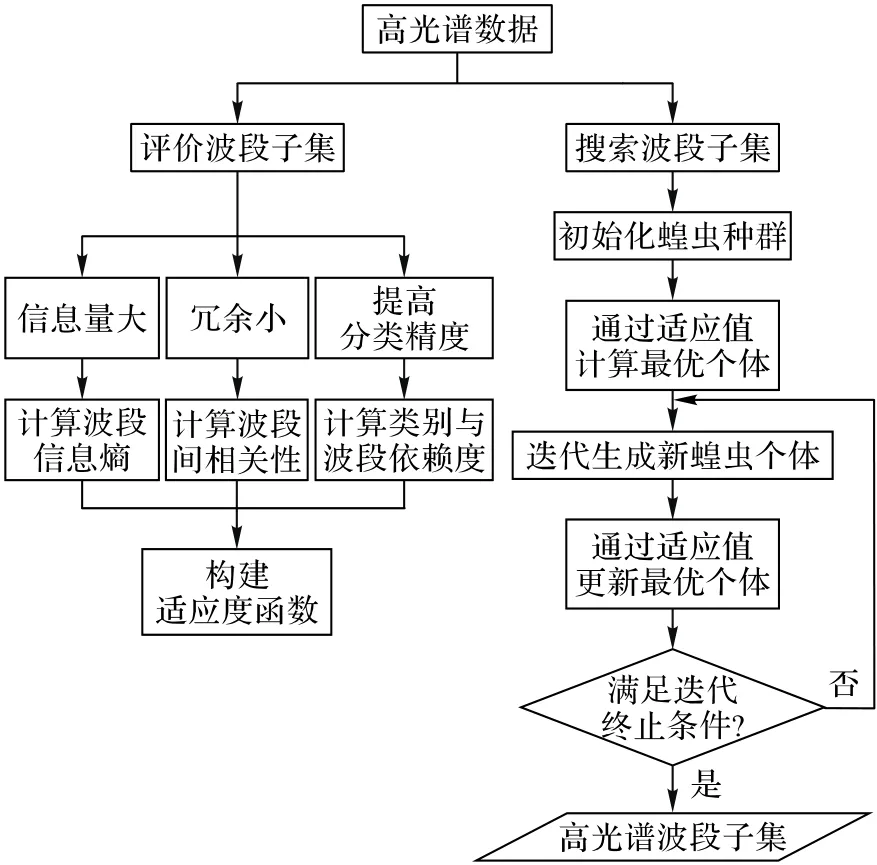
图2 技术路线Fig.2 Technical route
2.2 蝗虫优化算法与模糊粗糙集结合的高光谱波段选择算法
蝗虫优化算法对优化问题求解具有较强的探索和开发能力,多核模糊粗糙集模型能较好地分析类别与特征属性间的依赖关系,因而本文将多核模糊粗糙集模型引入对高光谱波段子集的评价中,采用Majdi等提出了二进制版本的蝗虫特征选择算法,提出了一种基于多核模糊粗糙集与蝗虫优化算法的高光谱波段选择算法。算法伪代码如下所示。
算法2 基于蝗虫优化算法与模糊粗糙集的波段选择算法。

每一个蝗虫个体对应一张决策信息表,决策信息表的每一列中的值代表对应波段下每一个像元的亮度值,最后一列代表每一个像元对应的地物真值类别。当蝗虫个体的某一维度为1时,代表该波段被进行选择;为0时代表该波段未被进行选择。通过该决策信息表,可以求得被选择的每一列代表的波段信息熵,求得选择后的波段间的波段相关性,以及地物信息与选取后的波段子集间的依赖度。通过式(12)即可求得该蝗虫个体对应的适应度。信息图如图3所示。

图3 蝗虫对应信息Fig.3 Correspondinginformation of grasshoppers
3 实验及结果分析
3.1 实验数据集
为了验证本文提出的模糊粗糙集蝗虫优化算法(Fuzzy Rough Set Grasshopper Optimization Algorithm,FRSGOA)的有效性,下载了Indian Pines数据集进行测试。目前,国内外高光谱数据的降维及分类实验常在此数据集上进行测试。Indian Pines数据集采用机载成像仪AVIRIS于美国印第安纳州采集。数据集包含16个地物类别,大小为145像素×145像素,图像空间分辨率为25 m,波长范围为0.4~1.5μm,共有220个波段。该区域主要由植被及蔬菜覆盖:蔬菜主要有玉米、麦子、大豆;植被有干草、树木、草地等。
数据集移除了水汽污染波段及噪声波段。用剩余的[4~102],[113~147],[166~216]共 185 个波段进行选择。取数据的36,41,45号波段分别代表R、G、B三色合成的伪彩色图见图4。地物类型个数如表1所示。

图4 Indian Pines数据伪彩色图Fig.4 Pseudo color chart of Indian Pines data
3.2 实验结果与分析
实验使用Java语言编写实现了FS-GKA(Feature Selection based on Gaussian Kernel Approximations)[20]波段选择算法、最大信息量(Max Information,MI)[2]波段选择算法、标准化互信息(Normalized Mutual Information,NMI)[11]波段选择算法、波段相关性分析(Band Correlation Analysis,BCA)[7]高光谱波段选择算法以及本文的FRSGOA波段选择算法。各方法的特点如表2所示。
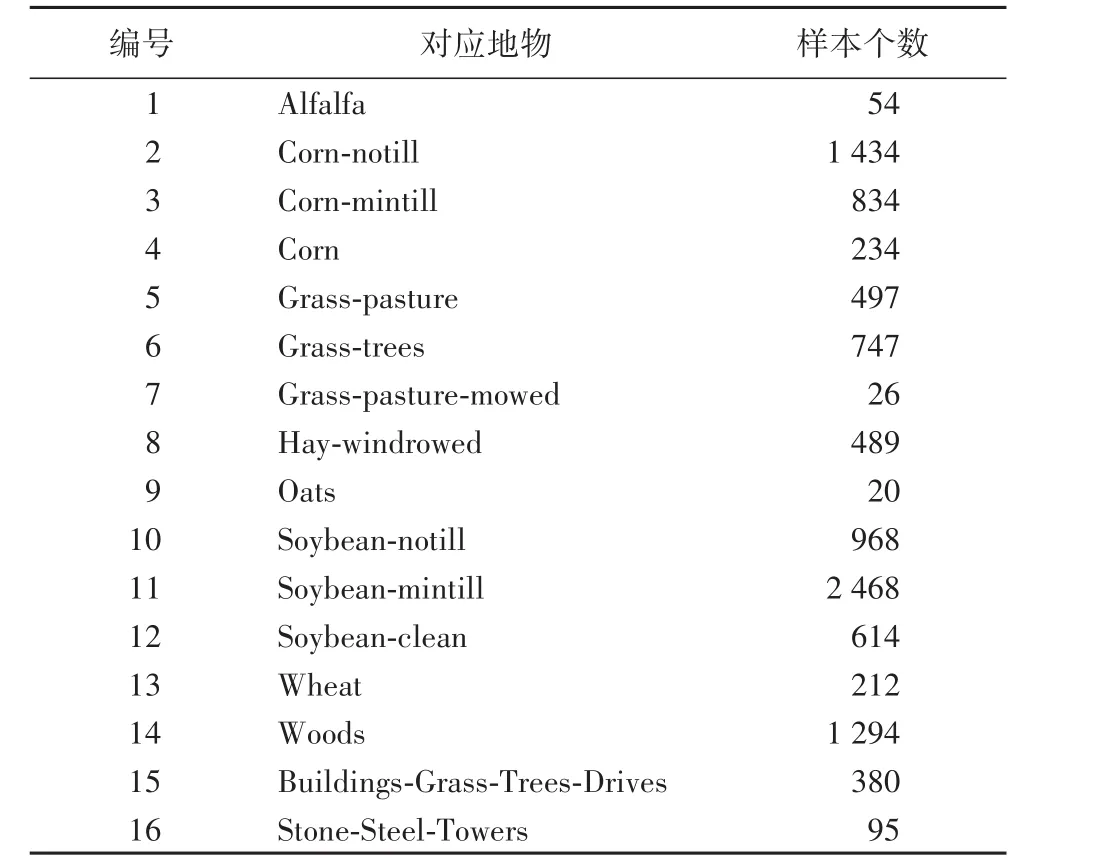
表1 Indian Pines数据中的地物类别Tab.1 Ground object categoriesof Indian Pines data

表2 波段选择算法技术特点Tab.2 Technical characteristicsof band selection algorithms
由于本文算法具有随机性,分类精度取5次计算后的平均分类精度。对于过滤式特征选择算法,单一的分类器不能较好地衡量波段选择后的波段子集,本文采用J48及K近邻(K-Nearest Neighbor,KNN)两种分类算法衡量波段子集评价特征选择算法性能。分类算法采用WEKA的默认接口,基于10折交叉验证确定这些特征子集的分类性能。本文在KNN分类器中,设置近邻数为5。本文算法设置迭代数为50,蝗虫个体数为90。核函数部分采用高斯核、指数核、二次有理核等权重进行线性组合。设高斯核为k1、指数核为k2、二次有理核为k3、对象x和y,则基于线性方式的组合核由kl(x,y)=(k1(x,y)+k2(x,y)+k3(x,y))/3表示。
由于不同核函数参数δ,会导致下近似值计算的差异,这样会对本文算法生成的波段子集产生影响,本文测试不同核参数δ下选择的波段子集。这里δ设置为0.10,0.22,0.32,0.50。实验结果如表3所示。
从表3中可以发现,在核参数δ为0.22时,波段平均数为14.4,同时相较于其他3个核参数,在J48及KNN分类器下具有最高的平均分类精度。其他3个核参数,虽然获得的平均波段个数较小,但是仍能具有较高的平均分类精度。
本文使用FS-GKA、MI、NMI、BCA算法作为本文算法的对比实验算法。FS-GKA算法采用高斯核函数,参数δ设置为0.22。NMI算法设置参数为按照原文设置。比较结果见表4。
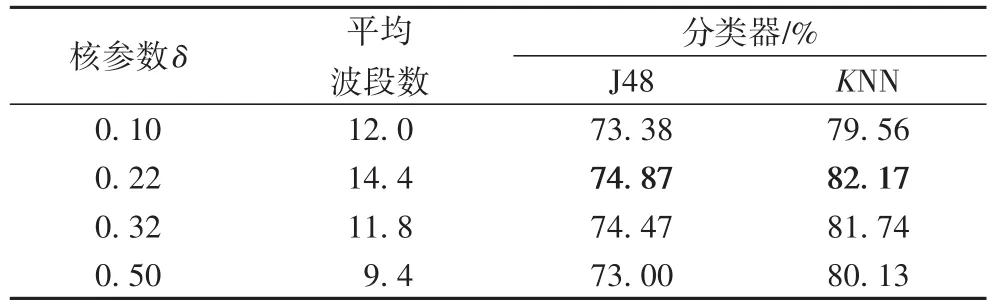
表3 不同核参数分类结果Tab.3 Classification resultsof different kernel parameters
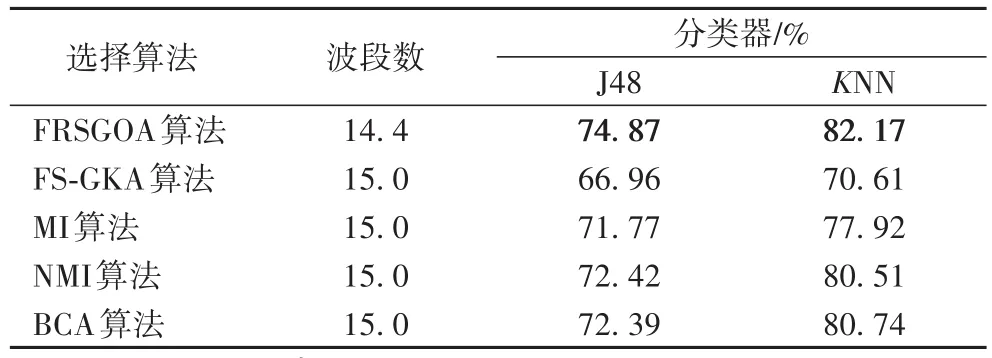
表4 各算法对Indian Pine数据平均分类精度Tab.4 Averageclassification accuraciesof different algorithmson Indian Pinedata
从表4中可以发现,本文算法与其他比较算法相比,能在波段子集更小的情况下取得更高的分类精度。这里BCA比MI、NMI及FS-GKA算法分类精度高,但是仍然不及本文算法的分类精度。
4 结语
本文提出一种基于核模糊粗糙集及蝗虫优化算法的高光谱波段选择算法,它根据蝗虫优化算法较强的开发及探索能力搜索波段子集。针对数据分布情况难以预计对于单核学习的限制,采用多核模糊粗糙集的方式计算属性依赖度,同时考虑波段子集信息含量及波段间相关性构造出了适应度函数。本文算法与大多数波段选择算法相比,不需要提前确定波段个数,直接选择出波段子集,但所提算法有许多参数需要设置,而且这些参数会对于波段选择有一定的影响,如何确定较好的参数仍有待进一步研究。
