基于多分支神经网络模型的弱监督细粒度图像分类方法
2020-06-07边小勇江沛龄张晓龙
边小勇 ,江沛龄 ,赵 敏 ,丁 胜 ,张晓龙
(1.武汉科技大学 计算机科学与技术学院,武汉430065; 2.武汉科技大学大数据科学与工程研究院,武汉430065;3.智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学),武汉430065;4.武汉科技大学信息科学与工程学院,武汉430081; 5.冶金自动化与检测技术教育部工程研究中心(武汉科技大学),武汉430081)(∗通信作者电子邮箱xyongwh04@163.com)
0 引言
细粒度图像分类是近年来计算机视觉、模式识别等领域一个非常热门的研究课题[1],是对属于同一基础类别的图像(如birds类、aircrafts类、dogs类等)进行更加细致的子类划分,但由于类内差异更大,存在姿态、视角、遮挡和背景干扰等诸多变化,而类间差异更加细微,因此细粒度图像分类是一项极具挑战的研究任务。
近十年来,细粒度图像分类研究方法大多数是从局部可区分性部位检测出发,寻找对图像鲁棒的特征表示,具体可分为4个研究内容:1)基于常规图像分类网络的微调方法,2)基于部位检测和对齐的方法,3)基于细粒度特征学习的方法,4)基于视觉注意机制的方法。以上前两类方法通常需要额外的对象标注信息,例如包围边框(Bounding Box,Bbox)或部位(Part),而获取人工标注信息的成本极高,且有较强的主观性,因而模型往往不是最优的。国内外学者越来越多地集中在后两类方法的研究上。Xiao等[2]提出了两级注意力算法,首次尝试只依靠类别标签实现细粒度图像分类。此后,弱监督细粒度图像分类研究得到快速发展。以上述方法3)为代表的工作有:Lin等[3]提出的双线性卷积神经网络模型(Bilinear-CNN),该方法使用 VGG-D(Visual Geometry Group-D)和 VGG-M(Visual Geometry Group-M)两个网络作为基础网络,并组合它们的输出特征进行分类,对细粒度图像产生更好的表示;Zhang等[4]从卷积神经网络(Convolutional Neural Network,CNN)中提取神经激活,分别用于定位局部区域和描述特征,提出了一种空间加权Fisher向量的编码方法(Spatially Weighted Fisher Vector CNN,SWFV-CNN),通过Fisher向量的空间加权组合来描述判别性特征;Wang等[5]提出了非对称多分支网络,同时关注局部区域与全局信息,并利用显著性检测,提取显著性区域的特征;王永雄等[6]构建聚焦—识别的联合学习框架,通过去除背景、突出待识别目标,消除无关信息对分类的影响;从数据扩增方面,Yang等[7]提出了一种新的自监督机制,学习具有判别性的细微特征。
最近,基于注意力的细粒度图像分类研究取得了不少进展。针对传统注意力模型只关注单个位置,Zhao等[8]提出多样注意力网络,采用长短期记忆(Long Short-Term Memory,LSTM)网络作为注意力机制,在不同时间生成不同的注意区域,每个时间步都会预测物体类别,采用各个预测结果的均值后得到最终预测结果;随着对注意力研究的深入,Sun等[9]提出多注意力多约束网络,结合了度量学习,加强了注意力特征之间的联系;针对局部信息关注不足的问题,王培森等[10]提出了一种端到端训练的多通道视觉注意力网络,通过多视觉注意力图提取对应高阶统计特性的视觉表示用于细粒度图像分类。尽管上述方法都取得了一定的效果,但是基本都是考虑部位检测及其变种,很少关注到对象大小、姿态和视角等诸多变化表达的差异性。现有的细粒度图像分类仍然存在一些困难,主要体现在:如何对潜在语义区域进行有效的关注,以及减少因姿态、视角等诸多变化造成的干扰;针对非刚性、弱结构对象如何提取丰富的特征信息。
本文在我们以前工作[11]的基础上,受Zhou等[12]在图像区域定位和Zhou等[13-14]在滤波器旋转学习上所做工作的启发,提出了一种多分支神经网络模型的弱监督细粒度图像分类方法。不同于以上方法,本文首先通过轻量级定位网络定位图像中有潜在语义信息的局部区域用作新的输入,然后设计可变形卷积的ResNet-50网络和旋转不变编码的方向响应网络(Oriented Response Network,ORN)[13]进行特征提取,最后通过网络微调提取混淆少、对象形变适应和旋转不变的特征并组合学习。主要工作如下:1)基于类激活图(Class Activation Map,CAM)[12]网络定位有潜在语义信息的局部区域;2)设计了可变形卷积的ResNet-50的网络结构和旋转不变编码的ORN网络结构,提取对象形变适应的局部特征和旋转不变特征;3)将以上特征嵌入到一个多分支损失计算的优化目标中,使整合后的特征具有更好的判别性。
1 相关工作
细粒度图像分类研究的核心任务是抽取局部具有判别性的细微特征,产生类内差异小、类间差异大的特征表示。近年来,随着深度学习的快速发展,细粒度图像分类方法从细粒度特征学习到弱监督部位检测方法不断涌现。
1.1 细粒度特征学习方法
物体的细粒度特征有助于物体的分类识别,从寻找局部判别性特征出发,Liu等[15]提出了全卷积注意力网络(Fully Convolutional Attention Network,FCAN),该方法利用基于强化学习的视觉注意力模型来学习定位物体的多个局部区域,提取局部区域的细粒度特征用于分类,但由于使用固定尺寸的注意力区域,无法有效避免背景干扰。基于局部区域定位的细粒度图像分类方法可能会丢失具有判别性的微小区域,如鸟爪、尾翼等。而基于特征表示的图像分类方法可能会提取到判别性不够好的特征,基于此,Fu等[16]提出循环注意力卷积神经网络(Recurrent Attention Convolutional Neural Network,RA-CNN),学习多尺度局部区域特征,组合多个尺度的特征进行分类,不足的是关注的是一个多尺度局部区域,特征之间可能有较大冗余。基于一幅图像关注一个局部区域或许不足以作出判断,同时关注多个局部区域才能获得更多的图像信息,Zheng等[17]提出了多注意力卷积神经网络(Multi-Attention Convolutional Neural Network,MA-CNN),利用特征图不同通道关注的视觉部位不同,聚类峰值响应相近的通道从而得到注意力区域,但针对多个区域的特征对齐问题值得探索。
1.2 弱监督部位检测子方法
基于部件检测的方法中,代表性的工作有Sermanet等[18]提出一种基于GoogLeNet的深度递归神经网络,网络在每个时间步处理一个图像部位来学习图像特征。由于图像块之间存在冗余,并且包含了无用的背景信息,因此最终分类结果不够理想。Han等[19]提出了基于部件的卷积神经网络基于压缩-刺激(Squeeze-and-Excitation,SE)模块加强信息信道和抑制无用信道,来学习信道特征响应,利用卷积滤波器定位判别性部件,学习部位特征和全局特征联合进行分类。
不同于以上所有方法,本文利用轻量级CAM网络定位有潜在语义信息的局部区域,输入到可变形卷积的ResNet-50网络和旋转不变编码的ORN,有效提取形变适应的局部特征和旋转不变特征。通过组合分支内和分支间损失计算优化整个网络,可以提取更好的区分特征,提高对非刚性、弱结构对象和姿态、视角等诸多变化的分类性能。
2 多分支神经网络模型
针对传统的基于注意力机制的神经网络模型不能联合关注局部特征和旋转不变特征的问题,本文提出一种多分支神经网络模型的弱监督细粒度图像分类方法。首先,研究了基于轻量级CAM网络定位有潜在语义信息的局部区域;然后,设计了可变形卷积的ResNet-50网络和旋转不变编码的ORN,将原图像和局部区域输入到特征网络进行特征提取;最后,组合3个分支内损失和分支间损失优化整个网络,进行分类。
本文方法的整体框架如图1所示,包括两个子网络:局部区域定位网络与特征提取网络,其中,利用CAM定位网络的最后一个卷积层、全局平均池化层(Global Average Pooling,GAP)和Softmax分类层联合生成类激活图,定位有潜在语义信息的局部区域(如图1所示)。随后将原图和定位出的局部区域分别输入到两个可变形卷积的ResNet-50网络和旋转不变编码的ORN,构成3个分支的特征网络,并组合3个分支内损失和分支间损失优化整个网络,直至收敛。

图1 多分支神经网络模型Fig.1 Model of multi-branch neural network
2.1 基于CAM的局部区域定位网络
如图1所示,在CAM定位网络[12]中,最后一个卷积层之后紧跟着的是GAP层,以及Softmax分类层。将Softmax层输出的预测概率映射回最后一个卷积层来产生类激活图。具体是,对于给定的图像,在GAP层对每一个特征图求全局平均值,输出每个特征图的平均值。用c表示某个类别标签,fk(x,y)表示第k个特征图上位置(x,y)的值,wck表示在第k个特征图上第c类的权重,两者相乘后得到第c类的激活特征图。最后,将多个激活特征图加权得到该图像的类激活图。定义属于某个类别c的类激活图为:

Mc(x,y)表示不同的特征图对识别类别c的加权结果,即定位到当前图像最强响应特征的高亮区域。然后基于灰度阈值框选出有潜在语义信息的局部区域,如图1中感兴趣区域选择(Region Of Interest Selection,ROI Selection)框为增加的处理模块,最后结合原图像和ROI位置信息就可以得到裁剪后的局部区域。局部区域仍然保留一定数量的上下文像素有助于产生辅助信息。
基于CAM的定位网络由于使用GAP层取代全连接层,减少了网络参数,避免了过拟合,能定位到有潜在语义信息的局部区域。同时CAM网络是轻量级的,因而没有增加额外的计算开销,具有好的适应性。
2.2 特征提取网络
1)可变形卷积的ResNet-50网络。
传统的卷积核受固定形状的影响,只能采集固定邻域内的局部信息,因而缺少自适应特征表达能力。而可变形卷积(Deformable Convolution)[20-21]通过扩展卷积,在更大的邻域范围采样到更为丰富的特征信息,但输出特征图仍然具有相同的空间分辨率。
本分支以ResNet-50网络为基础,其中每一个残差模块都是由卷积核大小分别为1×1、3×3、1×1的三个卷积层串联在一起,Conv1包含一个卷积层,Conv2_x、Conv3_x和Conv4_x分别由3、4、6个残差块组成。参照文献[20],如图1所示,设计将Conv5_x层中3个3×3传统卷积替换为可变形卷积,构成可变形卷积的ResNet-50网络。因此,原先规则网格R会附加一个偏移量{Δps|s=1,2,…,A|},A=|R|,对于输出特征图U中的每个位置p0,U(p0)计算为:
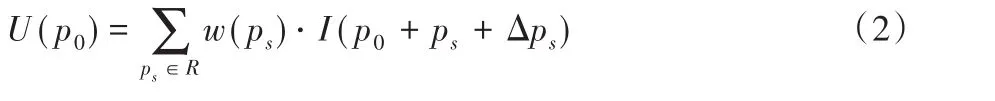
其中I(⋅)表示输入特征图。根据可变形卷积原理,首先在输入特征图的每个位置生成一个偏移量,并将其向前传播;在后向传播阶段,新增的偏移位置ps+Δps会同时被学习,然后经过双线性插值得到整数的空间位置,进而执行可变形卷积。由以上可知,可变形卷积的ResNet-50网络增加了对物体形变的检测能力,能提取到更为丰富的判别特征。
2)旋转不变编码的方向响应网络。
细粒度图像类内差异更大,存在姿态、视角、遮挡和背景干扰等诸多变化。为减少类内变化带来的影响,本分支引入ORN[13]进行旋转不变特征学习。如图1所示,将所有普通卷积层均替换为方向响应卷积(Oriented Response Convolution,ORConv),且最后一个ORConv层之后接入一个旋转不变对齐层,构成旋转不变的方向响应网络。该网络首先设计多个不同方向的主动旋转滤波器(Active Rotating Filter,ARF)来产生不同方向的特征信息。一个含有O个方向的ARF在卷积过程中主动旋转O-1次产生O个通道的特征图,该特征图显式包括了位置和方向信息。基于主动旋转滤波器F和O个通道的特 征 图M,定 义 方 向 响 应 卷 积(ORConv)为=ORConv(F,M)。输出特征图͂具有O个通道,其中第k个通道计算为:
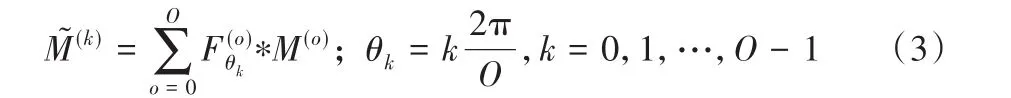
其中:F(o)θk为第o个方向旋转角为θk的主动旋转滤波器F。第0个方向的主动旋转滤波器F可看成是物理的,通过后向传播进行学习,即使用其余O-1个方向(虚拟)的主动旋转滤波器进行更新,定义为:
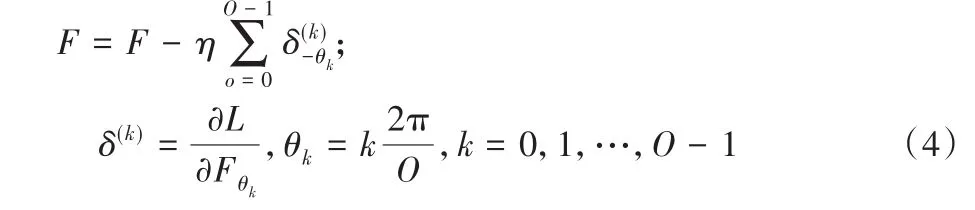
其中:δ(k)-θk表示第k个方向对齐到-θk的训练误差,L表示训练损失,η表示学习率。依照式(4),后向传播阶段对第0个方向的主滤波器进行更新,因而对于外观相似但方向不同的样本(块)的训练误差得以聚合。
在ORN中,通过以上步骤获得的输出特征编码了方向信息,但还不是旋转不变的。为了获得类内旋转不变表示,本分支引入方向响应对齐(Oriented Response Align,ORAlign)层编码上述特征。具体是,采用类似尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)的对齐方式,找到特征响应最强的方向,将其作为主方向,然后旋转输入特征,从而获得类内旋转不变特征,进而保持类间判别性。
与卷积神经网络(CNN)相比,ORN使用ARF取代常规滤波器,网络参数更少,能捕获更多方向的模式特征,并基于ORAlign层处理使得输出特征具有旋转不变性。
2.3 分类识别
本文方法定义了分支内损失和分支间损失两种损失函数,将分支内损失和相邻分支之间的损失组合起来优化网络,总损失函数定义为:

其中:B表示分支数,α是调整总损失和相邻分支损失之间关系的因子,如图1融合层所示。分支内损失L(b)intra使用交叉熵损失,计算为:
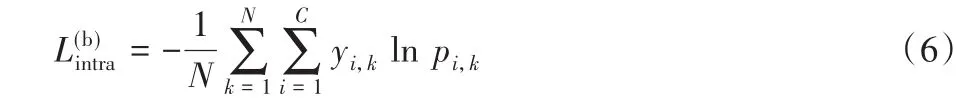
其中:N表示训练样本数,C是类别数,yi,k是真实类别,第k个样本被预测为第i个类别的概率为pi,k。为了确保分支之间以相互强化的方式学习,定义分支间损失为:
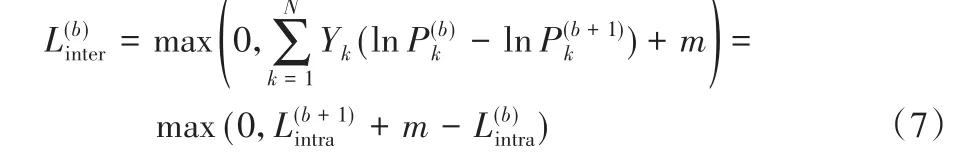
其中:Yk是所有类别上的yi,k,P(⋅)k为所有类别上指定分支的pi,k。每个分支参考相邻分支逐步学习各自的特征表示,使总体损失误差趋于最小,提高分类性能。
在第b个分支上的卷积权重通过随机梯度下降计算为:
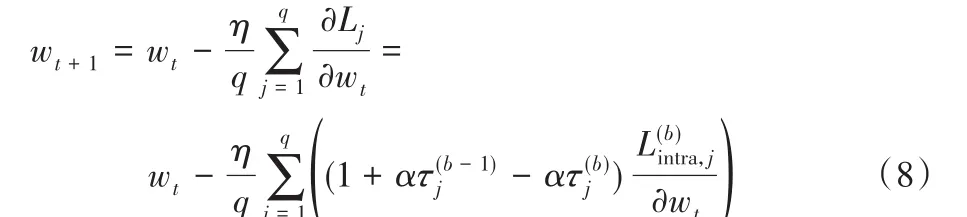
其中:η表示学习率,Lj表示第j个训练样本的损失值函数,q表示批大小。Τ表示相邻分支之间的关联度,定义为:
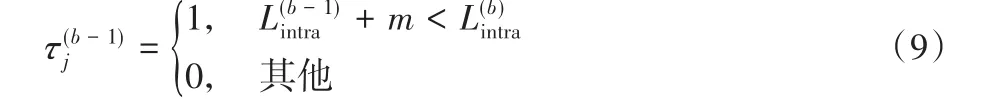
如果分支损失明显高于分支损失,学习率α将增加以减小分支b和分支b-1之间的距离。通过训练总损失函数来优化整个网络,将不同分支计算的结果进行融合,得到最终的预测类别。
3 实验
本文方法在Ubuntu 16.0 LTS系统中进行实验仿真,使用基于Pytorch的深度学习框架,采用Tesla V100图形加速卡进行训练。
3.1 数据集与实验设置
本文使用细粒度图像分类领域中两个广泛使用的、富于挑战性的图像数据集CUB-200-2011[22]、飞行器细粒度视觉分类 (Fine-Grained Visual Classification of Aircraft,FGVC_Aircraft)[23]和 一 个 实 验 室 收 集 的 战 斗 机 数 据 集Aircraft_2进行实验,概述如下:
CUB-200-2011 该数据集是细粒度图像分类领域最富挑战性的数据库,有200种不同鸟类的图像,共有11 788幅图像。该数据集由于鸟类姿态、位置各异,因此类间差异小、类内差异大。
FGVC_Aircraft 有102类不同的飞行器图像,包含民航客机、直升机和无人机等。每一类包括100张不同的图像,共有10 200张图像。该数据集飞机型号划分非常细致,类间相似性高。
Aircraft_2 在FGVC_Aircraft数据集的基础上,我们收集了20类战斗机图像,每类包含100张图像,一共2 000张图像。相对于FGVC_Aircraft数据集,由于战斗机的涂装和所处环境不同,导致类内差异较大。
CUB-200-2011数据集中的图像,每幅图像的大小从200像素×200像素到500像素×500像素不等,实验中被调整为448像素×448像素。FGVC_Aircraft数据集中的每幅图像大约为800像素×600像素,实验中被固定为800像素×600像素。实验室收集的数据集Aircraft_2图像大小约为600像素×400像素,统一调整为600像素×400像素。三个细粒度图像数据库的示例图像如图2所示,每个数据集的训练集与测试集的划分如表1所示。

图2 细粒度图像数据集示例图像Fig.2 Example images of fine-grained image datasets
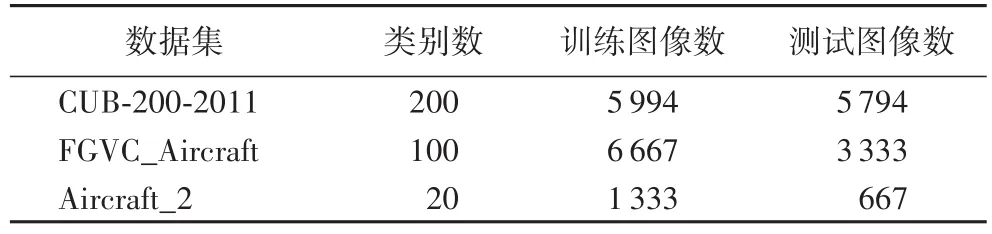
表1 细粒度图像数据集统计信息Tab.1 Statistics of fine-grained image datasets
实验中,可变形卷积分支用于偏移学习的卷积层参数初始化为0,学习率的倍数β设为1。α和m分别设置为0.1、0.05。批处理大小统一设置为16,初始学习率为0.002,迭代200次,每迭代50次学习率减半,当损失值保持平稳后得到最优模型。可变形卷积的ResNet-50网络和旋转不变编码的ORN的层数分别为50、18,分别使用预训练模型ResNet-50和OR-ResNet-18进行初始化。
3.2 不同方法的实验结果对比
为验证本文方法的分类性能,首先设计了不同方法的对比实验,实验结果如表2所示,对照方法中一部分使用了图像类别之外的额外监督信息,包括数据集提供的包围边框(Bbox)和部位标注(Part);另一部分使用了弱监督注意力机制。从表2中实验结果可知,本文方法相较于此前使用包围边框等数据集标注的强监督分类方法,分类精度达到了同一水平,比多粒度卷积神经网络(Multiple Granularity CNN,MGCNN)提高了2.3个百分点;同时相较于不使用额外标注的弱监督分类方法,本方法有明显提升,比最近的MA-CNN提高了1.2个百分点。这一结果证明了多分支神经网络模型具有有效提取互补特征,对细粒度图像(鸟类图像具有不同大小且对象像素少)进行有效区分的能力。
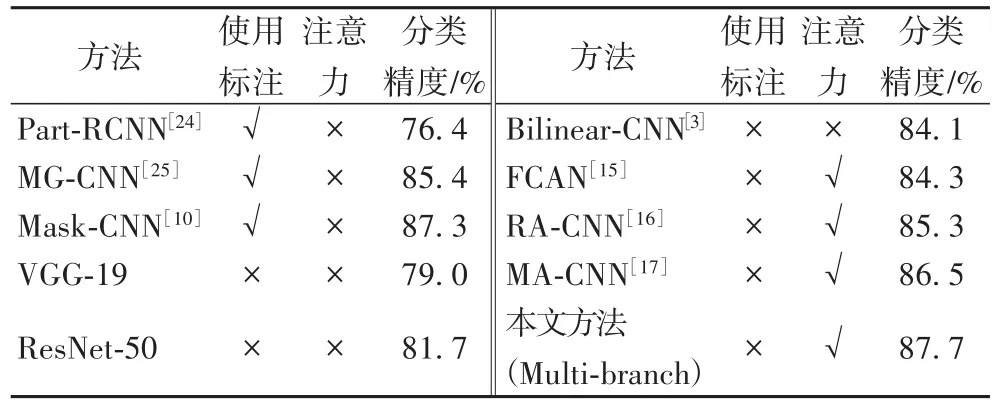
表2 CUB-200-2011数据集上的分类结果Tab.2 Classification results on CUB-200-2011 dataset
按照上文所述配置,本文基于多分支神经网络模型的弱监督细粒度分类方法在FGVC_Aircraft数据集上得到了90.8%的分类精度,表3展示了不同方法在这个数据集中的比较结果。本文方法比最近的MA-CNN高出0.9个百分点,比挖掘判别性三元组(Mining Discriminative Triplet of Patch,MDTP)卷积神经网络提高了5.4个百分点,比Fisher向量卷积神经网络(Fisher Vector Convolutional Neural Network,FVCNN)提高了9.3个百分比,证明了本文所提方法的有效性。同样地,部分方法使用了包围边框等额外标注信息。
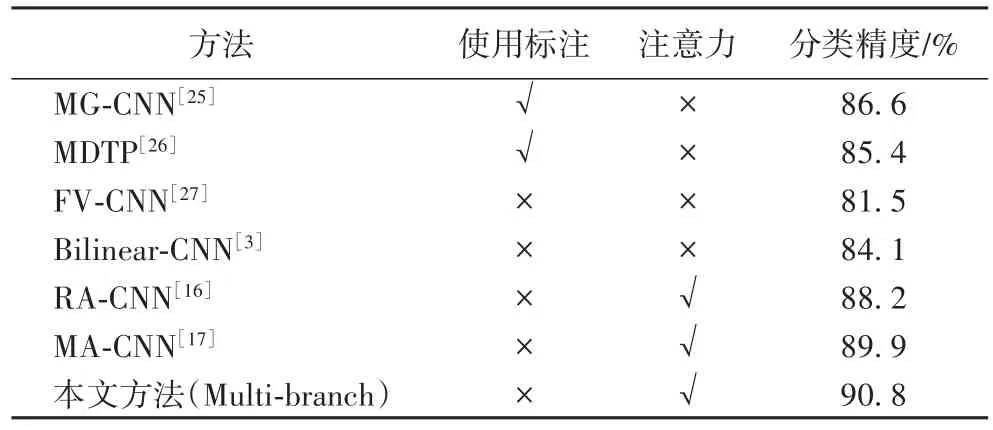
表3 FGVC_Aircraft数据集上的分类结果Tab.3 Classification results on FGVC_Aircraft dataset
按照上文所述配置,本文所述多分支神经网络模型在实验室收集的Aircraft_2数据集中得到了91.8%的分类精度。其他三个对比方法FCAN、RA-CNN和MA-CNN均在本实验中实现。从表中结果可知,本文方法相较于其他方法,在分类精度上有所提高。同时,结合网络模型的复杂度进行比较,可知在使用预训练模型的基础上,本文方法所采用的多分支神经网络模型能够更为有效地提取与细粒度图像分类相关的特征。由于飞机是刚性对象,且有较清晰的背景,因此分类精度更高。
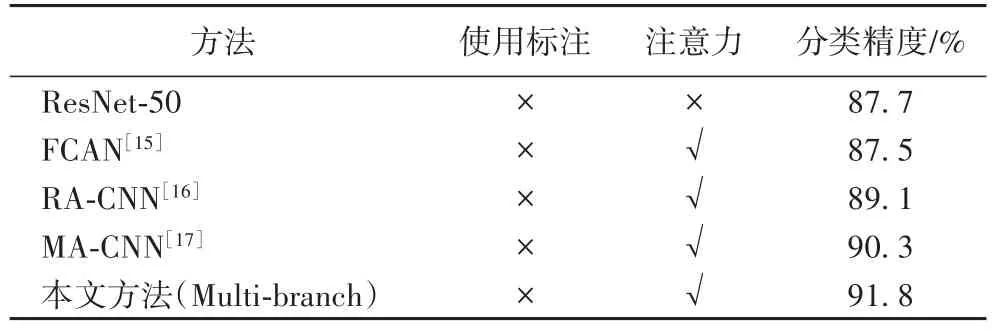
表4 Aircraft_2数据集上的分类结果Tab.4 Classification resultson Aircraft_2 dataset
3.3 本文方法不同设置的实验对比
为进一步验证本文方法各个分支的贡献度,分别对局部区域定位网络(CAM)、可变形卷积网络(Deformable Convolutional Network,DCN)和方向响应网络(ORN)三个不同分支进行实验。实验以ResNet-50网络作为基础网络(Baseline)。不同分支(或分支组合)在上述三个数据集上的实验结果如表5所示。
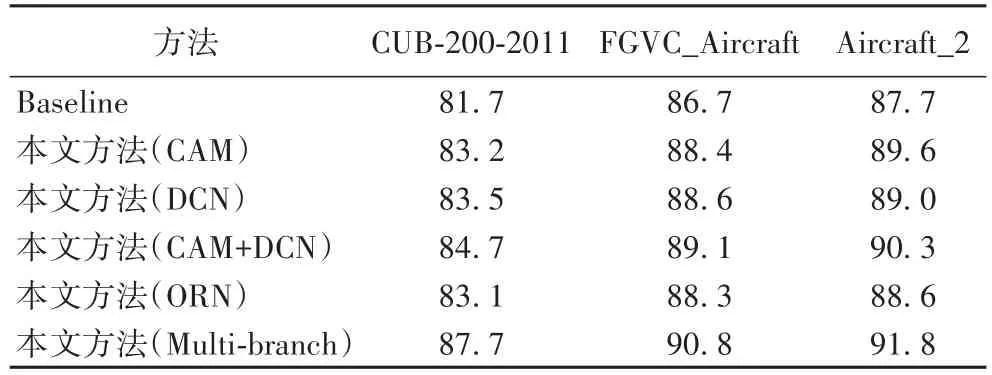
表5 本文方法不同分支在三个数据集上的实验结果 单位:%Tab.5 Experimental resultsof different branchesof the proposed method on three datasets unit:%
从表5可知,本文所述多分支神经网络模型在所有数据集上均要好于单个分支(或两个分支)和基础网络的分类结果,在三个细粒度数据集上分别高出基础网络6.0个百分点、4.1个百分点和4.1个百分点,证明了多分支神经网络整体优化可以有效地提取到有助于分类的重要信息。从实验结果还可以看出,可变形卷积网络(DCN)的分类结果略好于局部定位网络(CAM)和方向响应网络(ORN),这与该网络层数更深有关。
4 结语
考虑到弱监督细粒度图像分类受语义对象像素大小和对象姿态、视角等诸多变化的影响,本文提出了一个新颖的多分支神经网络模型的弱监督细粒度图像分类方法。该方法首先利用CAM网络快速定位图像中有潜在语义信息的局部区域,输入到可变形卷积的ResNet-50网络和旋转不变编码的ORN学习物体形变适应的局部特征和旋转不变特征表示,并将这些特征嵌入到一个多分支损失计算的优化目标中,从而获得更具有判别性的图像表示。在两个公开的细粒度图像数据集CUB-200-2011和FGVC_Aircraft,以及实验室收集的战斗机数据集Aircraft_2上评估验证了本文方法的有效性,且实验结果表明本文方法在不同数据集上的准确率均优于对比方法。然而在本文研究中仅考虑利用图像中包含潜在语义对象的单个局部区域,没有考虑定位图像中多对象的其他区域。在接下来的工作中将探索如何改进模型,使得本文方法更加完善。
