基于一致性度量的概率模糊语言多属性群决策方法
2020-06-05任嵘嵘孟一鸣李晓奇
任嵘嵘,孟一鸣,李晓奇,赵 萌,3
(1.东北大学工商管理学院,辽宁 沈阳 110819;2.东北大学理学院,辽宁 沈阳 110819;3.东北大学秦皇岛分校,河北 秦皇岛 066004;4.河北省科普信息化工程技术研究中心,河北 秦皇岛 066004)
1 引言
随着客观事物的不断发展,由于决策环境的复杂性、不确定性以及决策者对评价对象的主观认识,仅用精确数难以全面和真实表达决策者对客观事物的认知[1-2]。在实际的决策过程中,人们更喜欢通过语言术语来表达他们的偏好,因此建立语言信息模型是十分必要的[3]。为此,Xu Zeshui[4]提出了一个下标对称可加的语言术语集(Linguistic Term Set, LTS),但有时计算和分析起来不方便;为了保留所有的语言信息,又将离散的LTS扩展成连续的LTS(或叫做虚拟LTS),在此基础上,Liao Huchang等[5]建立了虚拟语言项与和它们相关的语义之间的映射。随着模糊理论的不断发展,利用犹豫模糊信息来刻画现实不确定性的情景十分常见。Torra和Narukawa[6]、Torra[7]提出了犹豫模糊集(Hesitant Fuzzy Set,HFS),Rodríguez等[8]在结合LTS与HFS提出了一个新的概念,犹豫模糊语言术语集(Hesitant Fuzzy Linguistic Term Set,HFLTS),针对某些属性或方案,决策者可能犹豫不决,因此可以通过几个可能的语言项对其进行评价;Rodríguez等[8-9]定义了HFLTS的基本运算;Wang Hai[10]简化了HFLTS的运算,王坚强和吴佳亭[11]定义了HFLTS的距离和优序关系,并在此基础上提出了HFLTS的多准则决策方法;Wei Cuiping等[12]根据概率理论构建了HFLTS的可能度公式,并提出HLWA以及HLOWA算子,据此提出了HFLTS的多属性群决策方法;Beg和Rashid[13]扩展了具有替代准则意见决策者的HFLTS模糊TOPSIS方法;Liao Huchang等[5]定义了不同类型的HFLTS的距离以及相似性度量方法,并将其应用于多准则决策问题,Wu Zhibin和Xu Jiuping[14]定义了HFLTS的可能性分布概念以及一致性度量方法,在此基础上提出HFLTS的多属性群决策方法;陈秀明和刘业政[15]定义了多粒度HFLTS的概念以及距离公式,并将距离公式结合满意度公式提出了群体推荐方法;葛淑娜和魏翠萍[16]提出了二元语义的犹豫模糊语言决策方法。
然而,目前大多数关于犹豫模糊语言术语集的研究,决策者给出的可能值都有相同的重要性或权重,很明显这种情况不符合现实,在实际决策过程中,决策者可能对于某些语言术语具有一定的偏好,因此,在HFLTS中决策者对于不同的语言项所赋予的权重可能会有不同,如果权重的值类似于概率分布,评价信息不仅包含了几个可能的语言术语,而且包含了概率信息。Pang Qi等[17]在HFLTS的基础上,考虑到各决策者对于不同语言术语的偏好问题提出了概率型语言术语集(Probabilistic Linguistic Term Set, PLTS)的概念,并表明PLTS不仅可以由决策者根据自己对于个语言项的偏好给出评价;同时在大群体决策过程中,可以根据不同群体决策者的评价语言项出现的概率得到PLTS,同时,在处理信息不完全问题时,也可以通过标准化将决策者评价信息用PLTS表示,并基于PLTS提出了PLTS的多属性群决策问题。GouXunjie和Xu Zeshui[18]定义了PLTS新的运算规律,避免运算超出语言集,并且使运算后保持概率信息完整;Liu Peide和Teng Fei[19]给出了PLTS的PLAMM算子等四种不同算子以及PLTS的多属性决策过程;Bai Chengzu等[20]给出了PLTS的比较方法,利用图表方法分析PLTS的结构提出PLTS的可能度公式;Zhang Yixin等[21]从偏好关系图角度讨论概率语言偏好关系(Probabilistic Linguistic Preference Relation, PLPR),并通过PLPR的一致性指数度量其一致性,同时提出了PLPR不可接受一致性的优化方法。Liao Huchang等[22]利用PLTS表示给定标准的替代方案的偏好,并提出一种线性规划方法来解决概率语言信息的多属性决策问题。Wu Xingli和Liao Huchang[23]根据新的PLTS距离度量方法提出概率语言全局偏好得分函数以及三种概率语言偏好强度公式。Xie Wanying等[24]将AHP方法应用到概率语言环境,重新定义概率语言比较矩阵及新的一致性指数,并提出检验和改进PLCM一致性的方法。Zhang Xiaofang等[25]提出了PLTS的相关性度量方法,并基于改进的聚类算法将其应用于保险公司的客户关系管理。
由于PLTS的自身优势,将其应用于决策问题具有重要意义。然而现有的关于PLTS的研究主要集中在集结方法和排序方法上,而忽视了PLTS的多属性群决策方法的研究。在文献[17]中提出了PLTS的多属性群决策,但其中没有涉及到决策者权重的集结,通过该方法得到的排序结果通常适合具有绝对优先级的PLTS,不符合实际情况。因此进一步研究PLTS的多属性群决策方法有很重要的意义,在群决策方法研究中主要关注两个方面:集结方法以及决策者之间的一致性的度量[26]。一方面在集结方法上:Beg和Rashid[13]汇总不同专家或决策者关于不同标准的意见提出了犹豫模糊语言术语集的集结方法;Zhang Zhen和Guo Chonghui[27]基于二元语言集结算子和分布语言集结算子提出了犹豫语言聚合算子并应用于多属性群决策中;Wu Zhibin[28]提出了HFLTS的加权平均算子和有序加权平均算子,利用HLFTS解决多属性决策过程;但由于PLTS涉及到概率信息,现有的HFLTS的集结方法不适用于PLTS,随后Pang Qi等[17]提出了PLTS的集结方法,该方法计算简便,但集结结果缺少概率信息;为此Gou Xunjie和Xu Zeshui[18]提出了PLTS的新的集结方法,该方法包含了概率信息,但多次集结会导致集结结果的不合理,导致评价信息出现误差;Zhang Yixin等[21]提出了PLTS新的集结方法,该方法的集结结果概率信息差异不明显并且与决策者初始评价信息不相符,导致评价信息失真;另一方面在一致性度量问题上:Liao Huchang等[5]基于所提出HFLTS的距离和相似性度量,建立不同备选方案的满意度,然后用于在多标准决策中对备选方案进行排序。Sun Bingzhen和Ma Weimin[29]提出了两个语言值和两个语言偏好关系之间的相似度概念以及一种衡量具有语言偏好信息的群决策中个体偏好关系与集体(群体)偏好关系之间一致性的方法。Wu Zhibin和Xu Jiuping[30]等引入基于概率分布的HFLTS,利用个体与群体决策矩阵之间的距离来定义一致性程度;Wu Zhibin[31]从成对替代方案、替代方案和偏好关系三个水平上定义提出了犹豫模糊语言偏好关系的一致性过程。Rodríguez和Martínez[32]提出了犹豫模糊语言信息群决策中获取高度一致性的解决方法;关于PLTS的一致性研究较少,Zhang Yixin等[21]通过PLTS引入PLPR的概念,定义PLPR的一致性指数利用集结运算获取备选方案的排序,但没有涉及到具体的PLTS的多属性群决策方法的研究。
从已有的研究可以看出,PLTS的研究刚刚起步,已有的集结方法适用于PLTS多属性群决策的研究较少,现有的PLTS集结方法不仅在计算上比较复杂且集结结果存在不合理性;关于PLTS的多属性群决策方法的研究中,缺少对于决策者一致性的研究。因此有必要对PLTS群决策的集结方法和一致性度量方法进行研究,本文借鉴LTS的相似度量方法,定义PLTS的相似度度量公式,根据现有PLTS的集结公式存在的问题给出新的集结方法,基于相似度量以及集结公式提出具体的PLTS多属性群决策方法,使PLTS的集结方法以及群决策结果更加合理,为解决现实生活中的多属性群决策问题提供重要的方法基础。
2 预备知识
定义2.1[33]:令S={st|t=0,1,…g}或S={st|t=-τ,…-1,0,1,…τ}是一个奇数项的语言集,其中,中间项表示评价值大约为0.5,或者“无差异”,其余的语言标签对称排列。
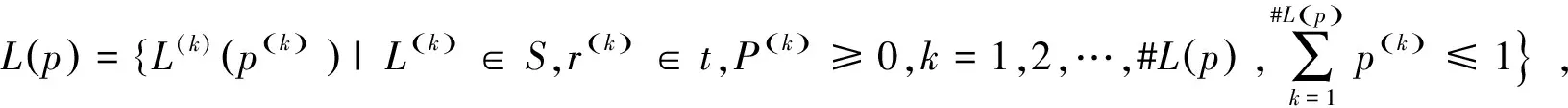
定义2.3[20]:令L(p)={L(k)(p(k))|k=1, 2, …#L(p)}是一个概率型语言术语集,r(k)是语言项的下标,令L-=min(r(k)),L+=max(r(k))分别是L(p)的最小和最大边界。
定义2.4[20]: 令S={st|t=-τ,…-1,0,1,…τ}或S={st|t=0,1,…g}是一个语言集,L1(p)和L2(p)是两个概率型语言术语集,L1(p)不小于L2(p)的可能度公式为:

其中,a(L1)-表示横轴为L-,纵轴坐标为p=p(L-)所围成的面积,a(L1)+表示横轴为L+,纵轴坐标为p=p(L+)所围成的面积,a(L1∩L2)表示L1与L2中相同语言项下标r(k)及其概率p相交部分的面积之和。
注:(1)如果L1(p)和L2(p)没有相同的语言项,则有p(L1(p)≥L2(p))=1或0;如果L1(p)=L2(p),则p(L1(p)≥L2(p))=0.5。
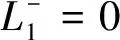

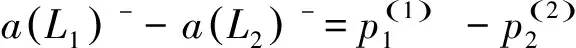
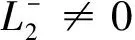

定义2.5[20]:如果p(L1(p)≥L2(p))>p(L2(p)≥L1(p)),L1(p)优于L2(p)的程度表示为:L1(p)≻P(L1(p)≥L2(p))L2(p);如果p(L1(p)≥L2(p))=1,则L1(p)绝对优于L2(p);如果p(L1(p)≥L2(p))=0.5,则L1(p)与L2(p)无差异,表示为L1(p)~L2(p)。
性质2.1[20]:p(L1(p)≥L2(p))+p(L2(p)≥L1(p))=1,尤其是当L1(p)=L2(p)时,p(L1(p)≥L2(p))=p(L2(p)≥L1(p))=0.5。
性质2.2[20]:令S={st|t=-τ,…-1,0,1,…τ}或S={st|t=0,1,…g}是一个语言集,L1(p),L2(p)和L3(p)是S上的三个概率型语言术语集。
(1)若p(L1(p)≥L2(p))>0.5,p(L2(p)≥L3(p))≥0.5或p(L1(p)≥L2(p))≥0.5,p(L2(p)≥L3(p))>0.5,则有p(L1(p)≥L3(p))>0.5;
(2)若p(L1(p)≥L2(p))=0.5,p(L2(p)≥L3(p))=0.5,则有p(L1(p)≥L3(p))=0.5。
3 理论基础
3.1 概率型语言术语集的集结方法
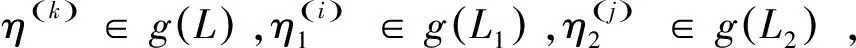
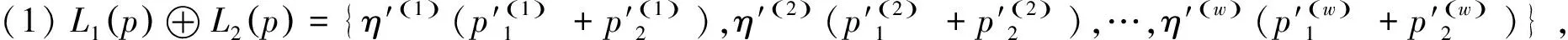
(2)λL(p)={η(k)(λp(k))},k=1,2,…,#L(p),λ∈[0,1];
注:若L1(p)和L2(p)的语言项不同,将L1(p)和L2(p)扩展为相同语言项,并令新增的si概率为0,即添加si(0)。

(1)L1(p)⊕L2(p)=L2(p)⊕L1(p);
(2)λ(L1(p)⊕L2(p))=λL1(p)⊕λL2(p);
(3)λ1L(p)⊕λ2L(p)=(λ1⊕λ2)L(p)。
证明:
(1)显然成立。
其中,w=#L1(p)+#L2(p)-#(L1(p)∩L2(p))
(3)(λ1L(p)⊕λ2L(p))={η(1)((λ1p(1)+λ2p(1))),η(2)((λ1p(2)+λ2p(2))),…,η(w)((λ1p(w)+λ2p(w)))(λ(p(w)+p(w)))}={η(1)((λ1+λ2)p(1)),η(2)((λ1+λ2)p(2)),…,η(w)((λ1+λ2)p(w))}=(λ1+λ2)L(p)
3.2 概率型语言术语集的相似度量
由定义2.4以及文献[29]的方法,重新定义了新的概率型语言术语集的相似度。

ρ(L1(p),L2(p))
性质3.2:0≤ρ(L1(p),L2(p))≤1。
(1)ρ(L1(p),L2(p))=⟺P(L1(p)≥L2(p))=1或P(L2(p)≥L1(p))=1;
定义3.3:令L1(p),L2(p)是两个概率型语言术语集,L1(p)与L2(p)之间的偏离度定义如下:
d(L1(p),L2(p))=1-ρ(L1(p),L2(p))=|P(L1(p)≥L2(p))-P(L2(p)≥L1(p))|。
性质3.3:0≥d(L1(p),L2(p))≤1。

(2)d(L1(p),L2(p))=1⟺P(L1(p)≥L2(p))=1或P(L2(p)≥L1(p))=1。
定义3.4:令Lk(p),Lm(p)是两个概率型语言术语集,其中Lk(p)={Lk1(p),Lk2(p),…,Lki(p),…,Lkn(p)},Lm(p)={Lm1(p),Lm2(p), …,Lmi(p),…,Lmn(p)},定义Lk(p),Lm(p)之间的相似度为:
定理3.1令Lk(p),Lm(p)是任意两个概率语言集,有:
(1)0≤ρ(Lk(p),Lm(p))≤1;
(2)ρ(Lk(p),Lm(p))=ρ(Lm(p),Lk(p))。
定义3.5:令Lk(p),Lm(p)是两个概率语言集,其中Lk(p)={Lk1(p),Lk2(p),…,Lki(p),…,Lkn(p)},Lm(p)={Lm1(p),Lm2(p),…,Lmi(p),…,Lmn(p)},定义Lk(p),Lm(p)之间的偏离度为:
性质3.4:令Lk(p),Lm(p)是任意两个概率语言集,有:
(1)0≤d(Lk(p),Lm(p))≤1;
(2)d(Lk(p),Lm(p))=d(Lm(p),Lk(p))。

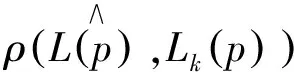
证明:
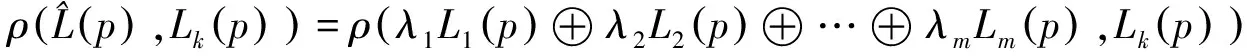
例3.1:某企业拟选取某种材料作为生产原材料,对于候选材料x进行评价,语言评价集为:S={很差,差,一般,好,很好}或S={-2,-1,0,1,2},为了能够得到更加合理的评价结果,现有4名决策者d1,d2d3,d4对于候选材料x给出的评价信息如下:
d1={s-1(0.1),s0(0.6),s1(0.3)}
d2={s-1(0.3),s0(0.5),s1(0.2)}
d3={s0(0.5),s1(0.5)}
d4={s0(0.4),s1(0.6)}
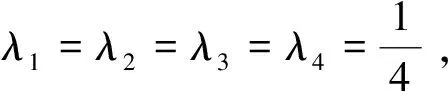
决策者d1,d2,d3,d4之间的一致性如下:
ρ(d1,d4)=0.636;
ρ(d1,d3)=0.727;
ρ(d1,d2)=0.727;
ρ(d1,d1)=1.
由定义3.2、定义3.4,得出:
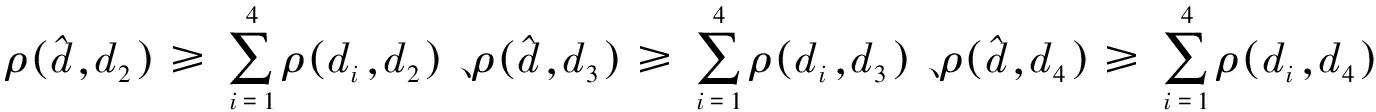
计算结果进一步验证了定理3.2的合理性。
4 决策方法
4.1 问题描述
PLTS是HFLTS的一种特殊情况,在实际应用中,PLTS具有两种形式:一种是由决策者根据自身偏好直接进行评价,另一种形式是根据不同组决策者根据各个语言项进行评价时,汇总各个语言项出现的概率来获取PLTS[17]。本章的重点提出一种基于一致性度量的PLTS下的多属性群决策方法。下面以第二种形式获取PLTS,给出具体的PLTS的多属性群决策方法:决策中,将全体决策者根据某一特征进行分组,通过不同组决策者的评价信息获取PLTS,如图4.1所示,对于不同组别的决策者在决策过程中,其评价信息对于决策结果可能存在不同的重要性,因此在决策过程中需要考虑到各组评价信息对于决策结果的权重问题。因此需要利用各组决策者之间的一致性来确定各组的权重。通过考虑各组与整个群体之间的相似性来确定权重,使得与群体相似性较高的组别在决策过程中具有更高的权重,而与群体评价偏离程度较高的组别具有更小的权重,以使决策结果更加合理。在决策过程中需要对各个指标进行评价,然而其中每个指标会具有不同的属性,为了使结果更加合理,需要确定各个属性的权重。本文采取层次分析法(AHP)确定各个属性的权重,并将各个属性进行集结,使每个指标对应一个PLTS。最后,根据PLTS的排序方法对不同指标进行比较得到最终的决策结果。对于第一种PLTS的获取方式的多属性群决策问题,该决策方法同样适用。以下是几个贯穿全文的表示:
X={x1,x2,…,xn}表示n个待评价指标的集合;
D={d1,d2,…,dm}表示m组决策者;
C={c1,c2,…cp}表示每个指标的p个属性;
S={-2,-1,0,1,2}表示给定的语言术语;


图4.1 各组决策者共同决策
4.2 算法流程
第一步:获得属性C={c1,c2,…cp}每组决策者对待评指标xi∈X(i=1,2,…,n)的PLTS:

(k=1,2,…,m,i=1,2,…n,j=1,2,…,p)。

(j=1,2,…,p)
(k=1,2,…,m,j=1,2,…,p)
第五步:通过AHP得到属性权重w=(w1,w2,…,wp)T,并在指标xi下,将属性cj(j=1,2,…,p)的评价信息进行集结,得到Li(p)(i=1,2,…,n)。
第六步:建立可能度公式
通过比较Li(p)(i=1,2,…,n),建立可能度矩阵P
其中pij=p(Li(p)≥Lj(p))(i,j=1,2,…,n)。
第七步:根据[33]中方法从互补判断矩阵P获取优先级:
v=(v1,v2,…vn)T
第八步:令v′=(vk1,vk2,…vkp)T是v的排序向量,则指标Li(p)(i=1,2,…n)的排序为:
Lk1(p)≻P(Lk1(p)≥Lk2(p))Lk2(p)≻…
≻P(Lkp-1(p)≥Lkp(p))Lkp(p);
因此指标xi的排序为:
xk1(p)≻P(Lk1(p)≥Lk2(p))xk2(p)≻…
≻P(Lkp-1(p)≥Lkp(p))xkp(p)。
专家直接给出的PLTS的多属性群决策情况,与上面所述方法相同,只是PLTS的获取方式不同,因此上述算法同样适用于由专家直接给出PLTS的多属性群决策问题。
4.3 实例分析
某地为推广实现科普工作,需要了解各科普信息传播方式的有效性,以更好的推广科普知识,根据相关资料查询,将科普传播方式分为三类:科普图文资料(x1),传统传媒方式(x2),新兴网络方式(x3),将全部决策者按照年龄进行分组,即D={d1,d2,d3},回收有效问卷531份,分别对以上三类传播方式的不同属性进行评价:信息真实程度(c1)、内容丰富性(c2)、获取难易程度(c3)、趣味性(c4)、信息丰富程度(c5),根据语言集S={很差,差,一般,好,很好}(S={-2,-1,0,1,2})分别对以上属性进行评价,并根据本文的决策方法进行决策,具体过程如下:
第一步:根据问卷调查的结果进行分组,得出三组决策者的概率语言信息评价值,由于论文篇幅有限,以c1为例:

表1 属性c1下决策者d1的概率语言信息的评价值

表2 属性c1下决策者d2的概率语言信息的评价值

表3 属性c1下决策者d3的概率语言信息的评价值
表4 属性cj下dk相对群体的相似度

表5 属性cj下决策者dk的权重
第四步:在属性c1下集结方案xi(i=1,2,3)的PLTS,得到xi(i=1,2,3)的PLTS分别为:
s0(0.340),s1(0.317),s2(0.095)}
s0(0.311),s1(0.452),s2(0.134)}
s0(0.237),s1(0.458),s2(0.214)}
第五步:通过层次分析法得出属性权重为w=(0.298,0.158,0.298,0.158,0.088)T,求出xi(i=1,2,3)的综合评价值为:
L1(p)=(s-2(0.074),s-1(0.250),
s0(0.357),s1(0.238),s2(0.081))
L2(p)=(s-2(0.069),s-1(0.174),
s0(0.335),s1(0.331),s2(0.091))
L3(p)=(s-2(0.041),s-1(0.144),
s0(0.263),s1(0.396),s2(0.156))

第七步:求出v=(v1,v2,v3)T=(0.304,0.317,0.379)T。
第八步:排序向量v′=(0.379,0.317,0.304)T,则指标Li(p)(i=1,2,3)的排序为L3(p)≻0.616L2(p)≻0.657L1(p)。xi的排序为x3≻0.616x2≻0.657x1。最好的指标是x3。
5 对比分析
5.1 集结方法的对比
为了证明本文提出的集结方法的有效性,将上述案例中属性c1下,指标x1,x2,x3的各组评价信息进行集结,并分别与文献[18]、文献[21]方法得到的集结结果进行对比,结果如下:
对比本文与文献[18]、文献[21]的集结方法,不同之处在于:(1)对于具有n维下标的语言集,进行m次集结时,本文方法需要进行n次运算,而对比文

表6 本文方法的集结结果

表7 文献[18]方法的集结结果

表8 文献[21]方法的集结结果
献[18]、文献[21]则需要进行nm次运算,因此当集结次数较大时,文献[18]、文献[21]涉及的计算量较大,需要进行多次计算,而本文方法在保持原有语言集下标维度不变情况下计算,在计算上更加简便;(2)由表6、7、8可以看出,文献[21]方法在多次集结时,集结结果导致语言集下标分散成多个维度,并且集结结果PLTS中各元素概率较小,在取值上会导致概率信息损失;(3)文献[18]、与文献[21]的集结方法导致PLTS的右边界语言项概率较大,而本文的集结结果元素个数少,并且避免了概率信息的损失,可以明确集结后的语言偏好。
根据相同的排序方法,将三组集结结果进行排序并对排序结果进行对比,结果如下:本文集结方法的排序结果:x3≻x2≻x1;文献[18]集结方法的排序结果:x2≻x3≻x1;文献[21]集结方法的排序结果:x3≻x2≻x1。由三组集结方法的排序结果可以得出,本文方法与文献[21]得出的结果一致,本文集结方法的有效性得以证明。然而文献[18]的结果与其不一致,因此,当进行多个维度的多次集结时,文献[18]中集结方法可能会造成信息损失,从而对排序结果造成影响。
5.2 决策方法对比
利用文献[17]、文献[35]中决策方法,对本文中案例进行排序,结果如下表所示:

表9 现有方法的最终结果
从表9中可以看出,文献[17]的排序结果与本文方法相同,不同之处在于:(1)文献[17]没有考虑到群体中可能存在的不同组别决策者可能存在不同的重要性问题,本文方法在决策过程中通过度量相似度从而考虑到不同群体评价信息的权重问题;(2)文献[17]的方法只有排序结果,而本文方法最终结果包含排序的可能度信息。
文献[35]与本文方法排序结果相同,都采用了大量评价数据分组处理,但本文的方法不同之处在于:(1)采用不同的评价信息处理方法,文献[35]采用离散分布描述数据,本文通过PLTS处理评价信息;(2)文献[35]在决策过程中只考虑组内的一致性问题,忽略了各组的组间一致性;(3)在计算过程中本文方法更加简便;(4)文献[35]与文献[17]相同,只有排序结果,而本文方法最终结果包含排序的可能度信息。
6 结语
本文提出了一种基于PLTS的多属性群决策的新方法,使用该方法,不仅可以处理大群体决策,而且可以处理由专家直接给出PLTS的群决策问题。根据给出的PLTS,利用已有的LTS的相似度公式确定PLTS的相似度公式,并由该方法获得决策者权重,利用新的PLTS集结方式集结各决策者的评价信息。通过层次分析法,可以获得各属性权重,并对属性进行集结。根据各指标的综合评价值,计算各个指标成对比较的可能度,并且可以使用可能度矩阵确定指标的排名情况。本文的主要工作体现在三个方面:
(1)提出了新的PLTS的集结方法,与已有的集结方式相比,该方法的集结结果保留了原有PLTS的语言信息,与专家初始意见保持一致、避免了概率信息的损失,使集结后专家偏好更加明确,在计算上更加简便;
(2)定义了PLTS相似度量公式,并根据相似度量公式确定了PLTS的各决策者权重,结果表明该方法考虑到决策者之间的一致性问题,可以得到更加合理的集结结果;
(3)基于新的集结方法、以及相似度度量公式进而提出基于一致性度量的多属性群决策方法,这种方法同时适用于PLTS的两种获取方式。该方法考虑了各决策者之间的一致性,通过相似度公式获取各决策者权重。结果表明该本文方法更加简便,在进行多维度集结时,避免了集结次数较多造成信息损失,最终的决策结果包括了排序的可能度信息。
