网络信息大数据动态增量分布式挖掘方法研究
2020-06-05梅莹莹
梅莹莹
(安徽三联学院,合肥230601)
随着网络信息大数据规模的不断增大,需要对网络信息大数据进行优化挖掘,分析网络信息大数据的动态增量,结合信息处理和特征提取技术进行网络信息大数据的动态增量式挖掘,提高网络信息大数据的异构管理和特征识别能力[1]。研究网络信息大数据动态增量分布式挖掘方法,在实现网络信息管理和人工智能信息处理中具有重要意义[2]。
对网络信息大数据挖掘的本质是进行网络信息大数据的时间序列分析,结合网络信息大数据的特征提取进行数据挖掘,传统方法中,对网络信息大数据挖掘方法主要采用主成分分析方法,提取网络信息大数据的主成分特征量进行数据挖掘,但该方法进行网络信息大数据挖掘的特征分辨能力不好[3]。针对上述问题,本文提出基于相似度特征提取的网络信息大数据动态增量分布式挖掘方法。首先构建网络信息大数据的异构存储结构模型,采用模糊分布式检测方法进行网络信息大数据动态增量特征分布式检测,提取网络信息大数据的相似度特征量;然后采用模糊聚类方法进行网络信息大数据动态增量分布式融合聚类处理,在模糊聚类中心进行网络信息大数据动态增量分布式检测和识别,实现网络信息大数据动态增量分布式挖掘;最后进行仿真实验分析,展示了本文方法在提高网络信息大数据动态增量分布式挖掘能力方面的优越性能。
1 数据存储结构模型和特征分布式检测
1.1 异构存储结构模型
为了实现网络信息大数据动态增量分布式挖掘,首先构建网络信息大数据的异构存储结构模型,采用模糊分布式检测方法进行网络信息大数据动态增量特征分布式检测,数据存储结构采用异构分布式存储方式,采用区域融合聚类和分块匹配方法,进行网络信息大数据的存结构设计[4],得到在数据中心网络中网络信息大数据的存储结构模型(如图1所示)。

图1 网络信息大数据的存储结构模型
根据图1所示的网络信息大数据存储结构模型,采用动态匹配方法进行关联性挖掘rk,构建网络信息大数据的动态增量式检测模型U(v)[5],得到数据挖掘的模糊关联特征量为:

给出网络流量矩阵k,某一检测周期j内对网络信息大数据进行分布式检测,采用梯度投影方法提取网络信息大数据的模糊隶属度函数,得到迭代式为

将4个维度矩阵依次按行相接ijk,在数据存储空间信息p中,得到网络信息大数据的关联规则特征分布满足

该内容块被划分成多个多维熵矩阵,构建数据挖掘的梯度投影函数f(Y),求得子空间的系数向量,采用向量量化均衡配置方法进行标准化处理,得到衡量数据存储异构性的模糊参数f(X),满足如下条件

在数据值域内求得全局最优解,得到数据的长度为N,将Lx=ai转化为2N+1个字符串,使用信息熵作为模糊聚类中心,进行大数据融合,得到数据挖掘的融合聚类中心为

把上述特征通过并行计算进行模糊重构得到网络信息大数据分布式重构模型,在重构的存储空间内进行动态增量式挖掘。
1.2 动态增量特征分布式检测
在上述进行数据存储结构分析的基础上,根据分解参数H1进行网络信息流量矩阵的特征重构hs(k),基于h0熵的检测方法得到数据挖掘的二元规划模型

采用非负子空间方法提取网络信息大数据的动态增量式E特征量[6],得到网络信息大数据挖掘的边界条件
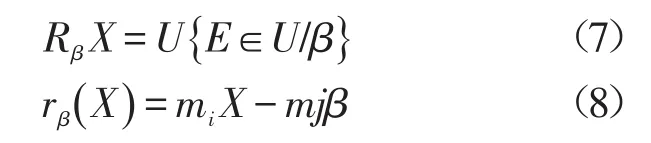
将网络信息流量矩阵分离为正常子空间β和异常子空间,得到网络信息大数据的基本块文件mi,j(1≤i≤n,1≤j≤k),在网络流量的正常模式下,存在关联映射Φ:X→Y,满足

其中,∙是X上的运算,∘是Y上的运算。在当前骨干网中求得网络大数据挖掘的Hash值,对于任意两个数据块mi和mj,采用模糊分布式检测方法进行网络信息大数据动态增量特征分布式检测[7],提取网络信息大数据相似度信息,为:

式中,xi∈Rn,代表网络信息大数据的状态矢量,ui∈Rm,对times字段的网络信息大数据进行增量式挖掘和输出转换控制。若网络信息大数据动态增量数据集为m,令Aj(L)作为聚类中心,其中j=1,2,...,k,设置r个不同的聚类中心中网络信息大数据动态增量函数h1,…,hr,每一个函数满足hi:{0,1}*→[1,m]。网络信息大数据动态增量挖掘的误差为

式中,M∈R3×3为正定矩阵;N为常数,e=X-Y为网络信息大数据动态增量挖掘的模糊度函数,动态增量特征分布式检测表示为

通过上述设计,利用流量的时间和空间相关性,进行网络信息大数据动态增量的动态增量式挖掘[8]。
2 数据挖掘优化
2.1 相似度特征量提取
在构建网络信息大数据的异构存储结构模型的基础上,进行数据挖掘优化,本文提出基于相似度特征c提取的网络信息大数据动态增量分布式挖掘方法,采用模糊分布式检测方法进行网络信息大数据动态增量特征分布式检测[9],得到数据的多维时尺度信息为
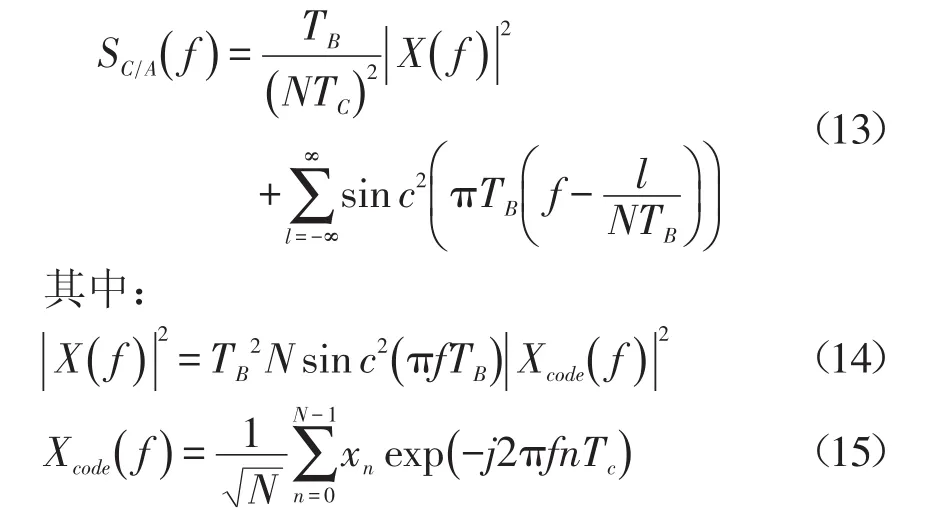
上式中,TB、TC为网络信息大数据的模糊采样预制和频率预制,f为网络信息大数据的频率特征,|Xcode(f)|为自适应加权系数,网络信息大数据聚类的加权学习系数为


从不同层面上对网络信息大数据进行动态增量分布式检测,得到不同维度相似度特征量提取矩阵满足

构建网络信息大数据的相似度特征检测模型,采用支持向量机算法进行网络信息大数据的融合性聚类[11],采用空间分布式网格检测方法,提高对网络信息大数据的自适应挖掘能力。
2.2 大数据动态增量分布式融合聚类
采用模糊聚类方法进行网络信息大数据动态增量分布式融合聚类处理,在深度学习下网络信息大数据动态增量式聚类的表达式分别为

在模糊聚类中心进行网络信息大数据动态增量分布式检测和识别,得到网络信息大数据聚类的自适应学习权系数为

挖掘网络信息大数据的模糊相关性特征量,结合联合关联规则检测方法进行网络信息大数据的动态增量分布式检测,得到网络信息大数据动态增量分布式挖掘的迭代函数为

其中,x(t)=ϕ(t),t∈[-h,0],采用多层空间区域聚类方法,在高维相空间中进行网络信息大数据的状态监测,基于弱凸性和显著性的分割方法进行特征分割[12],得到数据的融合聚类中心为:

选取特征值的区间函数,得到数据聚类的空间区域分布集为
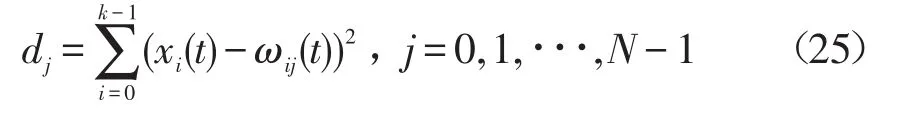
其中ωj=(ω0j,ω1j,∙∙∙,ωk-1,j)T,当网络信息大数据的相干系数满足时,在三维点元模型中进行网络信息大数据挖掘,得到动态增量分布式挖掘的状态函数为

通过显著性测试方法进行数据挖掘过程的收敛性判断,实现网络信息大数据动态增量分布式挖掘,实现流程如图2所示。

图2 数据挖掘的实现流程
3 仿真实验与结果分析
为了测试本文方法在实现网络信息大数据动态增量分布式挖掘中的应用性能,进行仿真测试分析。实验采用Matlab设计,对网络信息大数据采样的样本长度为800,数据的属性分布维数为4,空间网格分布为20×20,网络信息大数据的训练集为80,相似度系数为0.24,数据分类属性为5,根据上述仿真参数设定,进行网络信息大数据动态增量分布式挖掘,得到数据的时域分布如图3所示。

图3 数据时域分布
以图3所示的大数据为研究对象,采用模糊聚类方法进行网络信息大数据动态增量分布式融合聚类处理,在模糊聚类中心进行网络信息大数据动态增量分布式检测,得到挖掘输出如图4所示。

图4 数据挖掘输出
分析图4得知,采用本文方法进行网络信息大数据动态增量分布式挖掘的收敛性较好,测试数据挖掘的有效性,得到测试结果如图5所示。

图5 数据挖掘的有效性测试
分析图5得知,采用本文方法进行网络信息大数据动态增量分布式挖掘的有效性较好,数据的特征收敛度水平较高。进一步测试数据挖掘的查准率,得到对比结果(见表1),分析得知,相比传统方法,本文方法进行数据挖掘的查准率较高。

表1 数据挖掘的查准率对比
4 结语
构建网络信息大数据动态增量分布式存储结构模型,结合数据特征检测方法,进行网络信息大数据动态增量分布式挖掘,本文提出基于相似度特征提取的网络信息大数据动态增量分布式挖掘方法。构建网络信息大数据的异构存储结构模型,提取网络信息大数据的相似度特征量,采用模糊聚类方法进行网络信息大数据动态增量分布式融合聚类处理,在模糊聚类中心进行网络信息大数据动态增量分布式检测和识别,实现网络信息大数据动态增量分布式挖掘。分析表明,本文方法进行网络信息大数据动态增量分布式挖掘的准确性较高,数据挖掘的查准率较高,具有很好的挖掘效果。
