大数据技术在道路建设规划中的应用实践
2020-06-03龙绍海艾冠韬黄晓虹陈先龙
龙绍海, 宋 程, 艾冠韬, 黄晓虹, 陈先龙,3
(1.广州市道路工程研究中心, 广州 510030; 2.广州市交通规划研究院, 广州 510030;3.同济大学道路与交通工程教育部重点实验室, 上海 200092)
0 引言
道路建设规划是明确城市道路交通近期建设项目安排的重要依据,国内主要城市均会依照城市发展基本诉求开展道路建设规划编制工作. 然而,道路建设规划编制的理论研究支撑不足,既有研究侧重于规划布局[1]、工程设计理念的探讨[2-4],缺乏建设规划编制的定量支撑理论体系,使得建设规划编制针对性不强,适用性欠缺. 随着我国城市化进程不断加速,道路建设规划的精准性要求越来越高,粗放式的道路建设规划难以适应新时代发展要求. 大数据技术发展为精准建设规划的开展提供了基础支撑,但现有交通大数据研究多局限于对某一特定领域的应用探索,如GPS数据判别道路运行车速[5-6]、网络和移动信息数据分析居民出行行为[7-9]、基于大数据分析的交通智能管控系统框架构建[10-11]等,缺乏多源数据的整合及其在道路建设规划中的应用. 为此,基于大数据精确、宏微观分析能力,研究探索利用大数据技术构建道路建设规划的定量支撑技术体系,并以广州市道路建设规划为例进行应用研究,证实了定量支撑体系在道路建设规划中的适用性.
1 大数据开展道路建设规划的优势
以城市交通运行管理(如线圈、闸机、GPS等)、城市交通相关行业和公众互动平台(如移动运营商、腾讯、高德等)为代表的交通大数据,蕴含了丰富的交通出行信息,通过深度挖掘可识别城市交通运行状态、预判交通发展趋势,从而为道路建设规划提供丰富的基础支撑.
相对于传统交通模型的定量分析技术,基于大数据开展道路建设定量分析具有得天独厚的优势,具体如下:
1) 数据样本量大,有效避免随机误差影响. 传统交通模型以小样本调查为基础,数据量小、周期短,无法避免数据的随机性对分析精度的影响. 大数据具有典型的大样本特征,可避免偏样本局限性、小样本扩样造成的误差放大影响;同时,大数据具有数据周期长的特征,能客服传统调查数据的随机性影响,有助于更精确发现数据背后的规律.
2) 数据的宏微观双重分析能力强. 一方面,大数据具有宏观分析适应性,相较于传统数据的行政壁垒限制,大数据往往能突破区域限制,形成更宏观分析能力;另一方面,大数据中蕴含丰富的信息,各类信息的关联能形成微观问题的细化分析能力.
3) 数据可获取性强. 传统交通调查数据难以突破行政壁垒,基本以市为单位开展,且成本高昂;以互联网和手机信令为代表的大数据已形成良好示范效益,技术移植性强,数据获取性好,具有更广的推广应用前景.
综上,大数据具有海量样本、宏观和微观双重精准分析能力、数据行政壁垒小等优势. 以大数据为途径的数据源,能够保持数据的生成与道路的运作同步化,解决传统的规划编制过程中对于规划基础数据的补充存在的滞后性、被动性等问题,提升了传统规划模型中因小样本分析数据所制约的模型分析精度,对建设规划的高精准性要求具有更强的适应性.
2 大数据在道路建设规划中的应用方法
道路建设规划主要目的是立足于现状交通治理、支撑近期开发等方面诉求来明确近期道路建设的优先顺序. 为实现这一目标,必须依托科学、精准的定量分析技术. 结合大数据特点,建设规划定量支撑体现在现状路网运行诊断、近期需求态势分析、关键路段甄别等方面.
2.1 基于互联网位置数据的路网运行状态识别
传统交通分析技术以静态指标为主,注重于道路饱和度分析,亦即线层的运行诊断. 大数据技术可拓展路网运行诊断技术体系,在面层和点层具有更好的动态指标评价.
2.1.1 基于实际耗时矩阵可达性测度的面层诊断
道路网络面层诊断主要体现路网结构、交通运作水平与城市客流空间结构的适应性,可从2个方面评估路网整体效益:一是居民加权通勤时间,体现了道路交通系统对城市职住空间分布的适应性;二是服务便利性,可采用指定时耗客流覆盖比例进行评价. 如式(1)(2)所示.
(1)
(2)
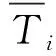

2.1.2 基于互联网数据的常发拥堵点识别
治堵是当前城市交通治理的热点议题,拥堵点的识别是治堵的重要基础工作,也是道路近期建设着重解决的问题. 互联网位置数据提供了掌握长周期、全覆盖的车速数据的方法,进而为常发性拥堵点识别提供了基础支撑,利用互联网数据获取的车速数据识别常发性拥堵点方法如下:
(3)
(4)
Sk=∑sk(t)
(5)
式中,Rkt为路段k在时刻t的拥堵指数;lk为路段k的长度;vkt为路段k在时刻t的实际行驶速度;vkd为路段k的自由流速度;sk(t)为路段k在时刻t是否拥堵标识;r为拥堵判断标准;如Rkt≥r为拥堵;sk(t)记为1,否则记为0;Sk为某一统计时段内sk(t)累加,反应统计时段内路口k发生交通拥堵的次数.
拥堵点识别常用的数据为高德车速数据,可获取某一时间间隔的各路段车速vkt,如5 min间隔的vkt,则某一路段全天可获取288个vkt,将288个vkt从小到达排序,取95%分位vkt作为vkd,进而可计算各时刻的拥堵指数. 在拥堵指数计算时,时间间隔可增大到30 min或1 h以满足拥堵统计要求,根据高德拥堵指数相关定义,r取为3. 结合作者从事交通规划10多年的工作经验,月平均Sk值大于15次时可判断为常发性拥堵点.
2.2 基于长周期历史数据的近期发展趋势预测
道路交通流量近期发展趋势受到2个方面影响,一是体现区域发展成熟度的人口就业增长,二是地区机动车拥有水平,可反应在地区道路交通流量增长率上(某一地区的机动车拥有量难以核实,采用交通流量增长率间接体现机动车拥有水平变化的影响). 通过上述指标可计算出不同区域的道路交通流量增长率,具体如式(6)所示.
fi=fpi*kpi+fei*kei+fti*kti
(6)
式中,fi为区域i的近期道路交通流量增长率,fpi、fei、fti分别代表区域i的人口、就业、机动车流量增长率,该数据需利用长周期的调查数据计算统计,kpi、kei、kti为权重系数,采用专家打分法确定.
2.3 基于高密度数据的关键道路识别
通过对现状交通问题诊断、近期交通需求预测及分析,提出相对应的道路建设初选方案后,需进一步明确初选方案的优先顺序加以重点推进实施,为此可利用高密度数据的渗流理论进行关键路段识别,从而挑选出对关键路段改善效果明显的通道加以实施.
渗流理论是随机图理论的重要发现,关键路段识别核心是利用车速数据判断路网不同功能组团的连通情况,进而测定连通路网中最先拥堵的路段. 计算核心指标为路段相对速度λk(t),该指标为某一时刻路段的实际运行速度vkt与自由流车速vkd的比值. 基于渗流理论关键路识别的具体流程如下所示:
步骤1:利用互联网位置数据获取任意路段全天任意时刻的车速数据. 为便于研究,按5 min间隔统计,全天可获取288个vkt,将vkt从小到大排序,取95%分位速度即为自由流车速vkd.
步骤2:计算各路段的相对速度λk(t). 按路段计算vkt与vkd的比值,全天共288个λk(t).
λk(t)=vkt/vkd
(7)
步骤3:路段畅通与拥堵状态判别. 对于给定的阈值q,当路段k的相对速度λk(t)大于阈值时该路段畅通,否则该路段拥堵,即:
(8)
步骤4:关键路段识别. 通过不断调试q值,可以确定网络中不同规模尺寸的功能连通子团. 根据渗流理论,整个网络处于渗流临界处时会存在一个结构相对稀疏的主干网络,这个主干网络能以最少的节点维持整体网络的功能完整性. 在这个主干网络中会存在一条或多条关键的“红边”,它们在连接不同的局域功能子团上起着不可替代的作用[12-13]. 这些关键“红边”即为网络中的关键路段,关键路段的拥堵会影响网络中不同功能组团的连通,对主要交流量的交互产生明显影响,进而影响到整个道路网络的运作状况和连通性.
3 基于大数据的道路建设规划应用实践——以广州为例
根据上述方法,以广州市道路交通建设规划为例,阐述利用大数据开展面、点层面的路网现状运行诊断,基于长周期数据历史数据的近期交通需求预测和承载力分析,初选方案的关键路段识别应用研究.
3.1 基于大数据的广州市现状路网运行诊断分析
3.1.1 广州市现状道路网络(面层)运行诊断
基于腾讯数据获取的广州市3 989个交通分区的职住分布矩阵和各交通小区的实际耗时矩阵,按照式(1)计算得到广州主城区各交通小区的加权通勤时间,如图1所示. 结果显示,广州中心城区部分区域存在通勤时耗较长的问题,如天河中心、芳村、洛溪南浦等,表明该部分区域路网与职住空间分布适应性不强,需优化区域路网以提升职住通勤效益.

图1 基于大数据的广州主城区通勤时耗评估示意图

图2 广州南站高峰期间可达性示意图
此外,依据式(2)对广州市关键地区,如广州南站、白云国际机场等重要枢纽,科学城、南沙副中心等外围地区,计算客流与出行时耗的匹配性,具体结果见表2所示. 计算结果显示,广州重要对外枢纽、外围关键地区对外客流主要分布位于中心城区,但现状其出行时耗偏大,50 min出行时空圈无法覆盖其85%客流,需进一步强化该地区的道路网络.
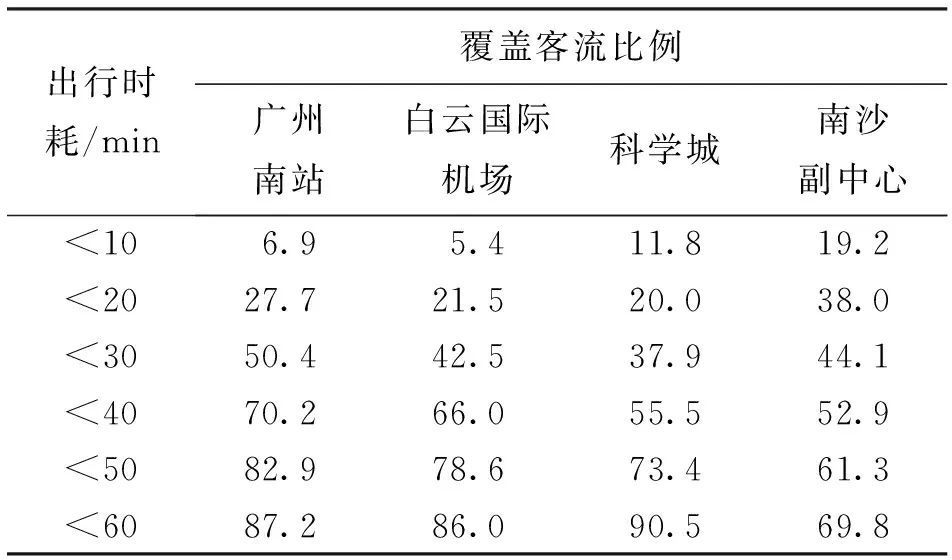
表2 重点地区不同出行时耗覆盖的客流比例一览表 %
3.1.2 广州市常发性拥堵黑点识别
根据9个月高德历史车数数据进行分析,按式(3)~(5)进行计算统计,广州主城区内顺畅道路占比75.8%,接近25%的道路处于缓行、拥挤或严重拥挤状态,其中常发性拥堵黑点共计53处,具体见图3所示.

图3 利用互联网数据的常发性拥堵黑点识别
3.2 利用长周期历史数据分析路网近期需求及承载力
研究结合大数据和广州市历年积累的长周期交通流量数据,分析获取广州市近10年人口就业演变态势、道路流量增长态势,如图4~6所示,然后依据式(6)按照加权系数0.4、0.3、0.3进行加权,得到广州市近期各区域道路交通需求增长态势,如图7所示,进而进行近期道路网络承载力分析发现,多条高快速路和进出城区通道在近期将进一步达到饱和度状态,如图8所示.
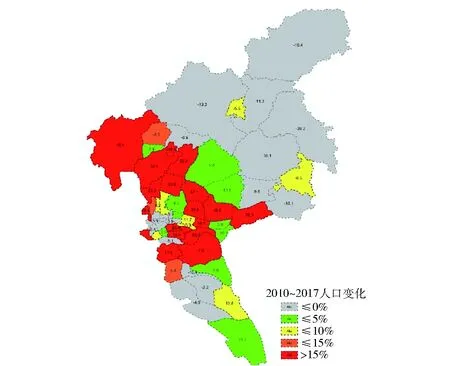
图4 2010—2017年广州市各区域人口年均增长率
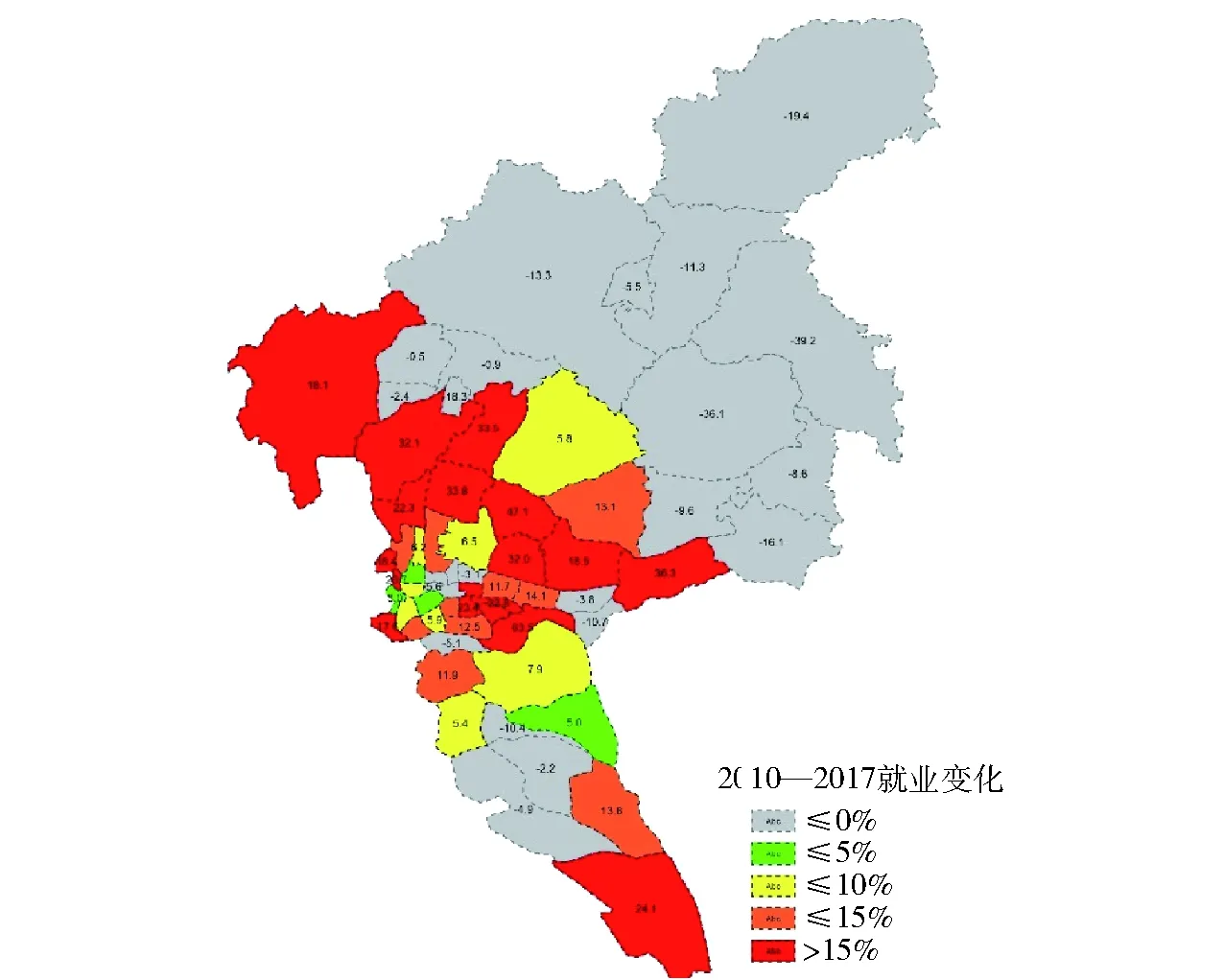
图5 2010—2017年广州市各区域就业年均增长率
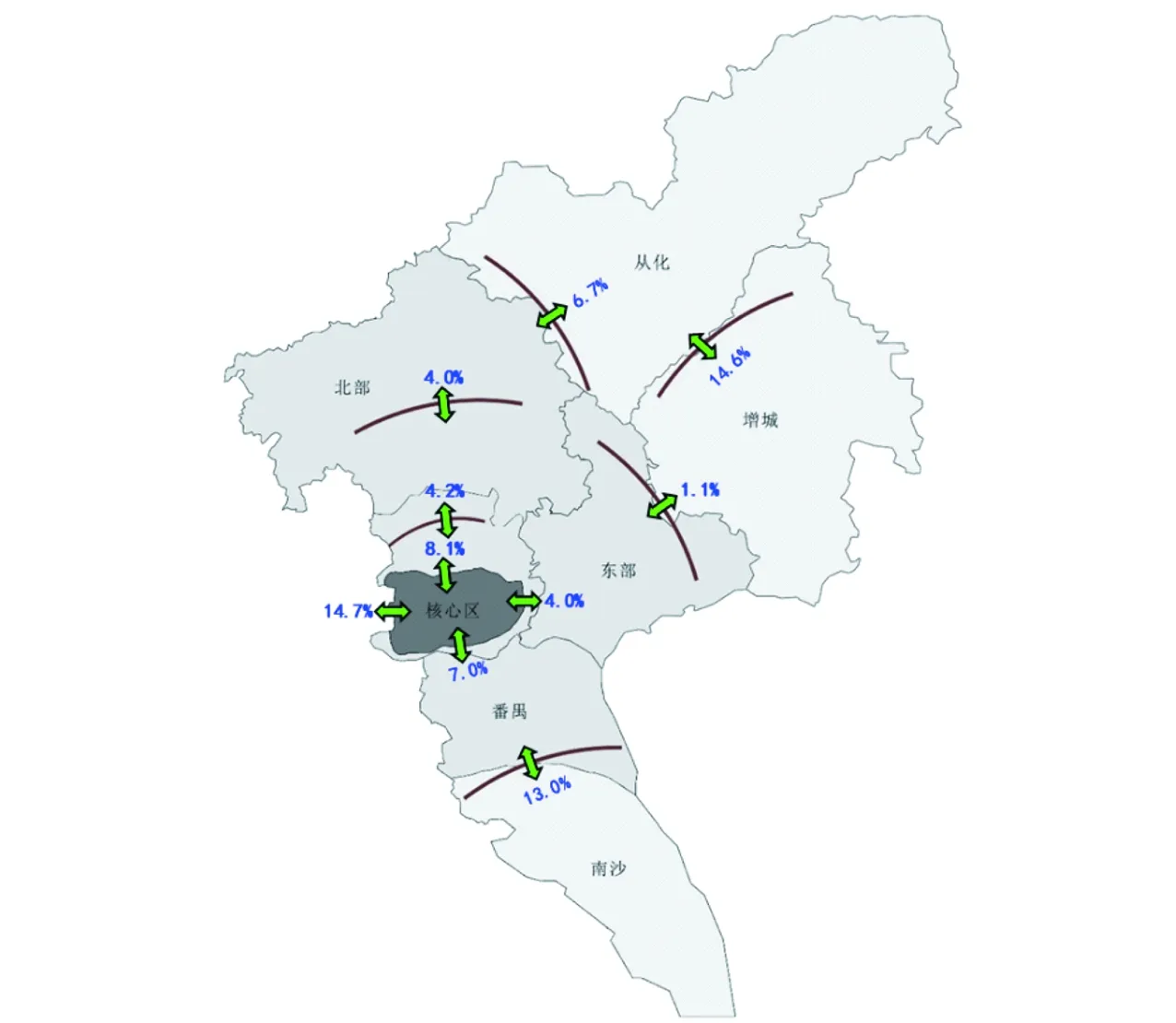
图6 2010—2017年广州主要核查线交通流量年均增长率
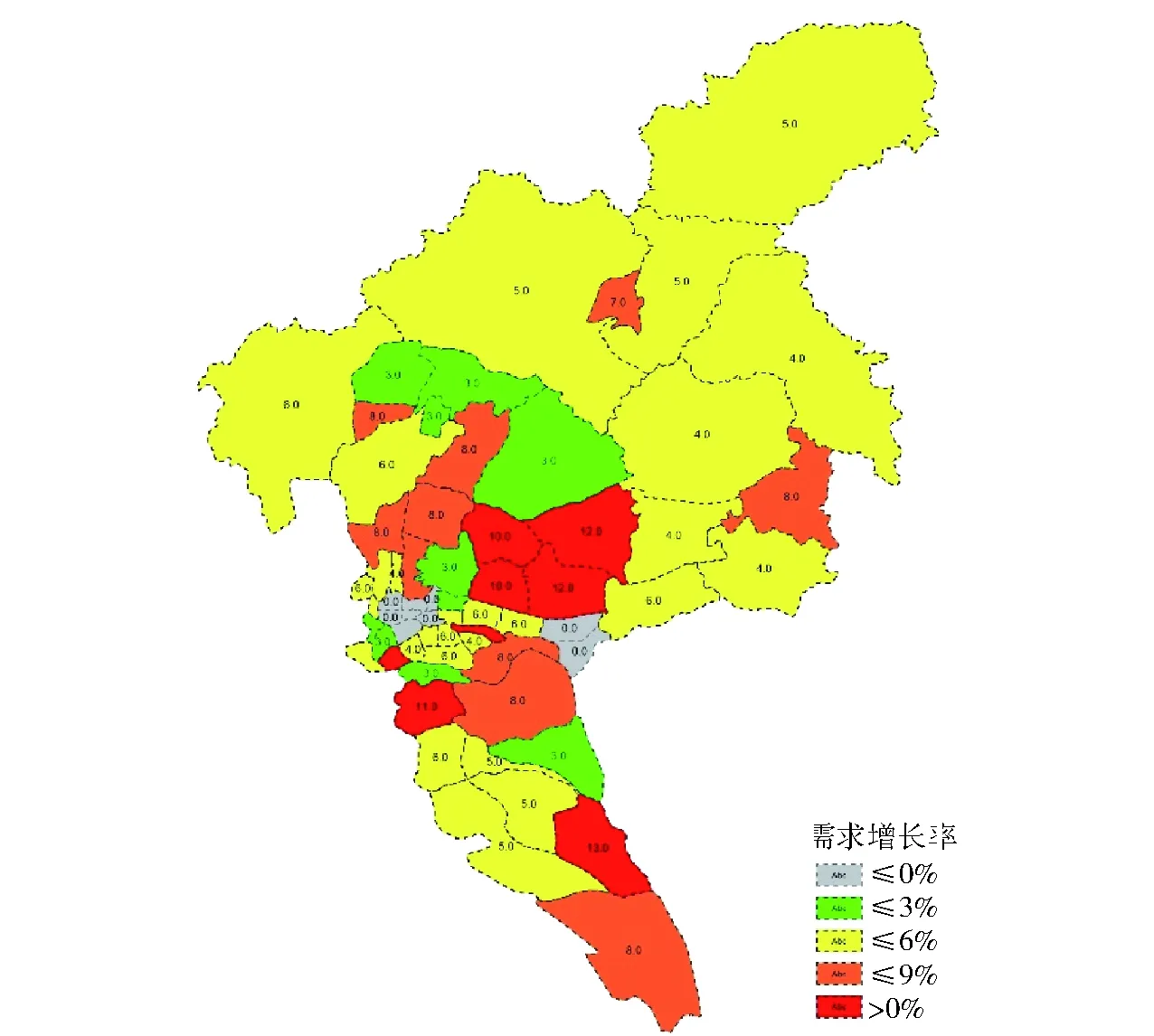
图7 道路交通近期需求增长态势分析

图8 近期道路交通承载力分析示意图
3.3 基于渗流理论对初选方案筛选
基于高德5 min颗粒度的车速数据,按照式(7)、(8)计算,并根据渗流理论得到广州市现状关键路段,如图9所示. 图中结果显示,关键路段基本位于城市重要功能组团间的连通道路,道路近期规划中方案筛选应重点针对图示关键路段进行改善,对相关关键通道改善效果明显的通道应优先选择.

图9 基于渗流理论的广州市关键道路识别结果示意图
4 结束语
基于大数据的大样本、长周期、高密度特征,以及宏观和微观双重精准分析能力,提出了基于多源大数据的面、点路网运行诊断技术,构建了利用长周期历史数据的近期道路交通发展趋势的预测方法,依托高密度车速数据采取渗流理论探讨了关键路段的甄别方法. 以广州市道路交通近期建设规划为示例,对构建的基于大数据道路建设规划定量支撑技术体系进行了应用验证,证明了其适用性. 研究提出了可操作的技术流程和数据指标以指导城市道路建设规划,将大数据技术在交通建设方面落于规划实质,探索了信息化时代下城市道路建设规划的新模式,从而指导各类城市更精准道路建设规划工作的开展.
