“多人言语声”语音训练对人工耳蜗植入儿童声调感知能力干预效果研究
2020-06-03李永勤陶仁霞赵伟时卫仁涛张昊丁红卫
李永勤 陶仁霞 赵伟时 卫仁涛 张昊 丁红卫
随着现代医疗科技的发展,人工耳蜗植入已经成为重度或极重度感音神经性听力损失儿童有效的听觉补偿手段。当前主流人工耳蜗所采用的言语编码策略是基于西方非声调语言的特点而设计的,经其编码和传输的语音频域信息极大弱化;受限于当前人工耳蜗编码技术无法提供足够的时域和精细结构信息,声调的基频(F0)信息不能完整再现,人工耳蜗植入者更多地依赖时长和包络等时域信息来感知声调[1,2]。然而,汉语普通话作为一种典型的声调语言,声调具有重要的表意功能,对声调信息的正确解读是普通话言语感知的关键环节,F0是声调感知最重要的声学线索,F0信息的缺损使得人工耳蜗植入者的声调感知较差[2,3]。因而,运用科学有效的训练方法,改善人工耳蜗植入儿童的声调感知能力尤为重要;“多人言语声”语音训练(multi-talker phonetic training)多应用于提升二语学习者的目标语语音感知能力[4,5],已成为一种成熟的训练范式,并已推广应用于特殊人群的言语康复训练中[6]。本研究拟通过采用“多人言语声”语音训练方法对人工耳蜗植入儿童进行声调感知能力康复训练,探讨这种直接且简便的语音康复训练能否有效提升人工耳蜗植入儿童的声调感知能力。
1 资料与方法
1.1研究对象及分组 选择16例3~7岁的双耳重度或极重度感言神经性听力损失并单侧植入人工耳蜗的学龄前儿童为研究对象,其中干预组8例 (男4例,女4例),对照组8例(男5例,女3例),两组的年龄及希内学习能力评估得分见表1。所有儿童补偿或重建听力均为最适,影像学检查显示所有儿童耳蜗结构无明显异常,除听力损失外无其他功能障碍。干预组和对照组使用听觉年龄和人工耳蜗植入年龄进行匹配,经过配对样本T检验,两组儿童在生理年龄(t=0.21,P=0.84)、听觉年龄(t=0.92,P=0.39)、植入年龄(t=-0.92,P=0.39)及希内学习能力评估得分(t=-1.29,P=0.24)差异均无统计学意义。干预组有5例儿童对侧佩戴助听器,平均佩戴时间为3.12±1.33岁;对照组有6例对侧佩戴助听器,平均佩戴时间为3±0.91年。

表1 干预组和对照组平均年龄、听觉年龄、植入年龄及希内得分(岁,
1.2“多人言语声”语音训练 “多人言语声”语音训练的关键特征为训练语料的高变化性(high variability),这种高变化性集中体现在两个方面:其一,多位发音人的多次发音;其二,多个声调负载音节。本研究另外邀请10名普通话母语者(5男5女)录制普通话元音/a/、/i/、/u/的4个声调,要求每位发音人尽可能自然的对每个元音的每个声调朗读5遍,这样一共获得600个语音样本作为训练材料。语音训练采用个训的形式,训练时间为一个月,在一个月内分5次进行,完成对所有语音样本的声调识别训练。干预组8例全程参与5次语音训练,每次训练时间为30分钟到50分钟不等,参训儿童可以随时休息,每次完成1男1女两名发音人的120个语音样本的声调识别训练;声调识别通过指认图片实现,其中,汽车在平直道路上行驶的图片代表一声,汽车在上坡道路上行驶的图片代表二声,汽车在先下坡再上坡的道路上行驶的图片代表三声,汽车在下坡的道路上行驶的图片代表四声。每次训练开始前,指导儿童将四个声调准确对应到正确的指示图片,训练时,语音样本逐一播放,要求儿童判断所听到的声音为哪一个声调,通过指认电脑屏幕上的图片完成判断。施训教师会对儿童的判断进行反馈,当儿童判断正确时,播放下一个语音样本;当儿童判断错误时,教师提供正确答案,并重复播放当前语音样本两遍。为保证训练效果,参训儿童完成120个语音样本的声调训练后,即时参加小测试,随机从当前训练的120个语音样本中随机选取20个样本作为小测试材料,要求儿童完成小测试材料的声调识别。只有在参训儿童达到或超过80%的判断正确率时,才结束当次训练。对照组8例不进行语言训练。
1.3声调感知能力测试材料与方法 分别干预前、干预后、干预结束三个月后进行声调测试,所有测试均在隔声室中进行,本底噪声低于30 dB A。声调听辨测试通过E-prime2.0程序实现,测试材料通过基于Windows系统的笔记本连接听力计和扬声器在声场中播放,播放强度为65 dB A。受试者位于正对扬声器1.2 m的位置,测试材料为普通话元音/i/的四个声调(阴平、阳平、上声、去声),由2名男性和2名女性普通话母语者在隔声室内录制完成,发音强度RMS标准化为65 dB SPL,一声、二声、三声和四声的平均时长分别为537、532、614和374毫秒。录制采用的音频设备为Mbox Mini,采样率为44 100 Hz;每一位发音人每个声调朗读10次,一位资深的语言学者从每位发音人录制的每个声调中选取5个样本,共选出80个语音样本作为测试材料。
采用声调分辨任务进行测试,两个声调配对呈现,中间间隔为500毫秒。共有两种类型的声调配对形式,其中不同的声调配对有6组,分别为:一声-二声(T1-T2)、一声-三声(T2-T3)、一声-四声(T2-T2)、二声-三声(T2-T3)、二声-四声(T2-T4)、三声-四声(T3-T4);相同的声调配对有4组,分别为:一声-一声(T1-T1)、二声-二声(T2-T2)、三声-三声(T3-T3)、四声-四声(T4-T4)。受试儿童听到一组声调配对需要判断为相同还是不同,通过指认电脑呈现的图片进行判断,认为相同则指向2个苹果的图片,认为不同则指向一个苹果一个橘子的图片。正式测试开始之前,每位儿童均有2分钟的练习时间,确保其理解测试任务后,开始正式测试,记录声调识辨的平均正确率。
1.4统计学方法 首先,测算出每位受试儿童声调分辨的正确率,然后,对正确率数值进行反正弦变换,转化为RAU (rationalized arcsine units)值[7],最后,运用RAU值进行统计分析,RAU值越大,则声调识别正确率越高,反之正确率越低。RAU值广泛应用于言语辨识任务的数据统计中,用以减少饱和效应,恢复方差齐质。本研究数据分析应用SPSS 23.0统计软件,采用单因素重复测量方差分析,其中声调识别率为因变量;儿童分组为受试者间变量,分为干预组和对照组两个水平;测试时间和声调配对为受试者内变量,测试时间包括干预前、干预后和干预结束3个月后三个水平;声调配对包括六组不同声调配对和四组相同声调配对共十个水平;干预组和对照组组间比较用两样本T检验。
2 结果
2.1两组儿童干预前声调感知能力 干预组和对照组干预前声调分辨正确率RAU值如表2所示,二声和三声调的正确分辨RAU值率仅为47.11,单样本T检验表明与50%的机会水平差异无统计学意义(P=0.68)。经单因素重复测量方差分析显示,二声-三声的分辨正确率与其他所有声调配对分辨正确率RAU值比较差异均有统计学意义(P<0.05),其他各声调配对的分辨正确率RAU值之间差异均无统计学意义(P≥0.05)(表3)。说明,人工耳蜗植入儿童容易混淆二声和三声,对这两个声调的分辨难度最大。

表2 干预组和对照组干预前不同和相同声调配对的声调分辨正确率的RAU值

表3 干预前不同声调配对差异显著性检验的P值
2.2干预组语音训练后声调感知能力 干预组和对照组干预前、干预后、干预结束后三个月的声调分辨正确率RAU值见表4。两样本T检验,干预前干预组和对照组的声调分辨正确率RAU值差异无统计学意义(P=0.71);干预后两组有显著差异,干预组高于对照组(P=0.02);干预结束后三个月,干预组和对照组的声调分辨正确率RAU值差异呈边缘性显著(P=0.088);说明,“多人言语声”语音训练能在短时间内提升人工耳蜗植入儿童的声调感知能力,尤其是二声和三声的正确分辨率RAU值从47.11上升到75.38,即使在训练结束三个月后,干预组的声调分辨正确率RAU值仍然优于对照组。
3 讨论
人工耳蜗植入儿童的听觉言语康复一直为国内外学者广泛关注,高效的语音训练对听障儿童人工耳蜗植入术后的听觉言语康复极为关键[8]。研究发现,当前人工耳蜗编码技术在传输和再现F0信息上有很大的局限性[3,9],使得人工耳蜗植入人群的声调感知较差[10~12]。Peng等[12]采用识别任务(identification task)对28例人工耳蜗植入者(6.6~21.4岁)进行声调感知能力测试,识别成绩及混淆矩阵(confusion matrix)分析表明一声和四声相较二声和三声更容易辨认,二声和三声两者之间更容易混淆。本研究采用分辨任务(discrimination task),将普通话四声两两配对,形成对比对,直接考察各声调间的混淆情况。另外,本研究受试儿童均在7岁以下,在学龄前患儿群体中更具代表性。文中结果显示,二声-三声配对的分辨正确率RAU值显著低于其他声调配对(P<0.05),并且16名受试儿童二声-三声的平均正确分辨率RAU值仅为47.11,与50%的机会水平(chance level)无显著差异(P=0.68),提示学龄前人工耳蜗植入儿童最难区分二声和三声,容易混淆这两种声调,有的甚至将这两种声调归为同一声调,与近几年的研究结果一致[12~15]。分析其原因,第一,二声和三声之间有非常相似的声学特征[16],两声调在单发时基频都有先降后升的走向(pitch contour),差异在于降的幅度以及先降后升的拐点位置,现行的人工耳蜗编码策略并不能有效再现这种细微的声学差异;第二,普通话中的连读变调(tone sandhi)尤其是广泛存在的三声变调(即在连续语流中接连出现两个三声,第一个三声会变成二声;如“法语”、“语法”等),使得二声和三声在语流中有一定的变换关系,两声调之间的复杂关系也可能会加剧二者间的混淆。
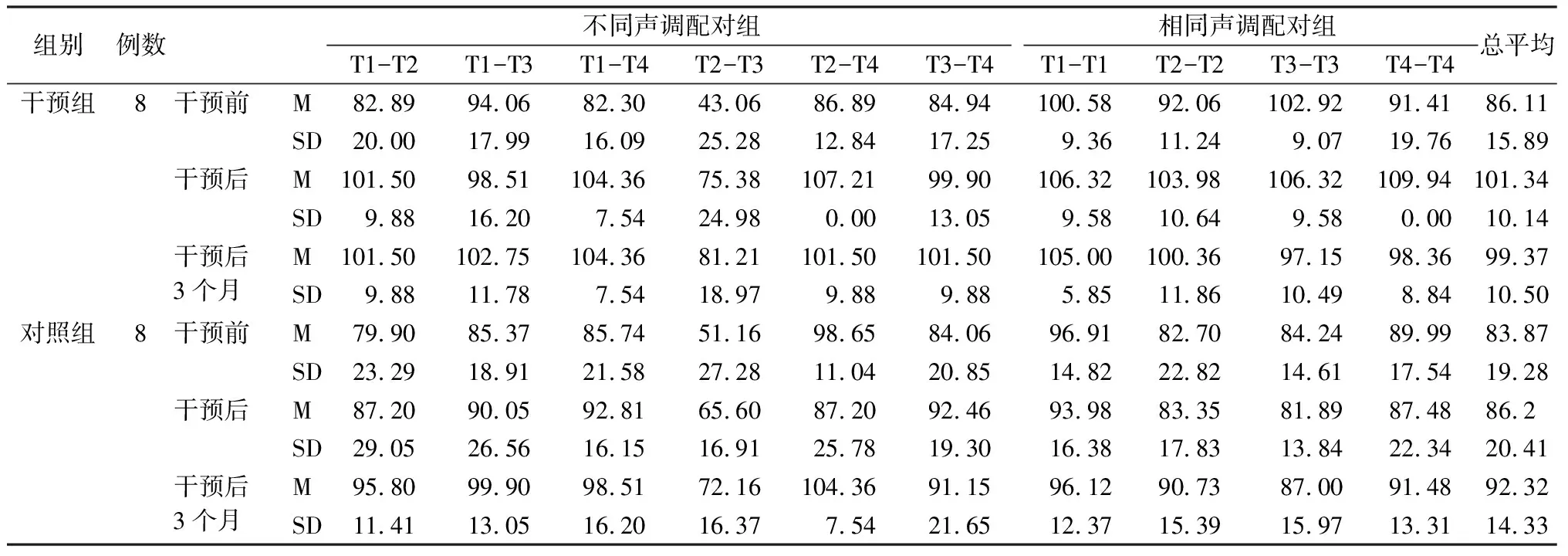
表4 干预组和对照组干预前、干预后和干预后3个月不同和相同声调配对声调分辨正确率的RAU值
注:T1:一声; T2:二声; T3:三声; T4:四声
音位是语言中能够区别词汇意义的最小单位,所有言语交际单位均是在音位的基础上建构起来的。Kuhl等[17,18]在研究婴儿及儿童语言能力发展的基础上指出,在语言发展早期阶段准确建立母语音位范畴与其后期的言语感知、发音能力的发展紧密相关。每一个音位范畴在大脑中的建立不是以点状形式存在的,而是一个集合,包含该音位的所有声学变量以及声学分布特征,音位的典型范畴像磁铁一样,将音位变体吸附在其周围(即感知磁吸效应,perceptual magnet effect)[19]。Kuhl[20]还发现婴儿及儿童在早期语言习得中听到多人言语声有助于其提升母语音位的区别能力,促进对母语语音进行归类,进而在大脑中准确建立母语的音位范畴。“多人言语声”语音训练最显著的特点是运用多位说话人的发音,为训练对象提供极富变化性的、丰富的音位变体材料,促进学习者音位范畴的习得。该方法作为一种成熟的训练范式,多应用于提升二语学习者目标语的语音范畴感知能力研究中,既包括元音、辅音等音段音位[21,22],也包括普通话声调等超音段音位[23]。Sharon等[24]尝试将该语音训练方法应用于植入人工耳蜗的听障患者的音位训练中,发现这种训练方法可以有效提高人工耳蜗植入术后成人的辅音音位辨识能力。本研究结果表明,“多人言语声”训练方法同样适用于人工耳蜗植入术后儿童的声调分辨训练,可以通过短期具有针对性的训练提高听障儿童的声调辨识能力,促进患儿声调范畴的准确建立。这种训练方法同样有一定的保留效应(retention effect),本组对象训练结束三个月后,干预组儿童的声调辨识表现仍优于对照组,虽然可能由于受试儿童数目较少,两组间的差异仅呈现出边缘性显著(P=0.088)。另外,研究发现经过训练,患儿声调辨识能力的提升主要表现在二声和三声上,这也提示在今后人工耳蜗植入儿童的听觉及言语康复训练过程中,应重点关注并强化二声和三声的辨识,以提高康复训练的效率。
综上所述,学龄前人工耳蜗植入儿童声调感知表现较差,尤其是二声和三声的辨识,存在较严重的混淆现象;“多人言语声”语音训练可以在短时间内有效提升此类患儿的声调感知能力,尤其是二声和三声的感知。在听觉言语康复训练中,应充分认识人工耳蜗植入儿童声调感知的特点,有针对性的重点强化儿童容易混淆的声调配对组合;设计教学内容时应重点考虑言语的声学特征,用丰富的音位变体材料提升干预对象的音位敏感度,形成更高效的训练方案。
