基于特征跟踪和网格路径运动的视频稳像算法*
2020-06-02王传胜管来福曾春艳
熊 炜,王传胜,管来福,童 磊,刘 敏,曾春艳
(1.湖北工业大学电气与电子工程学院,湖北 武汉 430068; 2.美国南卡罗来纳大学计算机科学与工程系,南卡 哥伦比亚 29201)
1 引言
通过智能手机等个人设备拍摄短视频已经成为人们记录生活的主流方式。在手持移动设备拍摄视频的过程中,由于设备内部或者外在因素的影响,获得的视频通常不稳定。抖动视频降低了视频图像的质量,使得观看者有晕眩感。视频稳像技术的目的主要是消除或减少视频的抖动,以便生成稳定的视频[1]。
视频稳像方法一般包含3个部分,分别是运动估计、运动平滑和运动补偿。根据运动估计中运动模型的不同,又可以分成2D方法[2,3]、2.5D方法[4]和3D[5]方法。3D方法鲁棒性差、速度慢。2.5D方法需要跟踪很长的运动轨迹,仅适用于专业设备,不适用手持设备拍摄的视频。由于2D方法处理速度快、鲁棒性好,常被用来处理视频去抖问题。
2D视频稳像方法中的相机运动估计先进行局部运动估计,再通过局部运动向量估计全局运动向量。局部运动估计方法主要包括2类:基于像素点的方法和基于特征点的方法[1]。基于像素点的方法主要包括块匹配法、相位相关法、灰度投影法以及光流法等。块匹配法原理简单、实现方便、应用广泛,但是在有快速运动的场景中效果并不好;相位相关法是一种非线性的算法,基本原理是傅里叶变换,有较高的匹配精度,且具有一定的抗干扰能力,但是计算时间过长,不适用于实时场景;光流法尽管不需要了解相关场景信息就能准确地检测识别运动目标位置,但有计算量大、耗时长、对光线敏感等缺点。基于特征点的方法主要将高维的图像数据进行简化表达,常见方法包括角点检测法、斑点检测法、边检测法等。角点是指在某方面属性特别突出的点,一般角点检测法有Harris角点检测法、FAST(Features from Accelerated Segment Test)算法等。斑点检测法主要对特征点周围像素灰度值大的区域进行检测,常见方法有SIFT(Scale-Invariant Feature Transform)算法、SURF(Speeded Up Robust Features)算法等。2011年,Grundmann等人[2]提出L1优化处理的运动平滑方法来处理抖动视频;2013年,Liu等人[6]提出捆绑相机路径框架算法进行视频稳像;2016年,Liu等人[7]提出一种新型MeshFlow运动模型算法来实时稳定抖动视频;2017年,熊晶莹[8]提出基于特征提取与匹配的车载电子稳像方法;2018年,Nie等人[9]在视频拼接中考虑视频稳像,提出一种结合识别视频背景和捆绑相机路径的方法来拼接视频;随着计算机视觉及深度学习的发展,2019年,Wang等人[10]提出一种StabNet神经网络模型处理抖动视频,该方法对计算机显卡及内存要求较高。
针对手持设备拍摄的抖动视频问题,本文提出一种基于特征跟踪和多网格路径运动的视频稳像算法。根据SIFT与KLT(Kanade-Lucas-Tomasi)相结合的特征跟踪方法[11],首先通过SIFT算法检测视频帧的特征点;再对检测出来的SIFT特征点通过KLT算法进行特征追踪匹配;然后根据匹配到的特征点,利用RANSAC(RANdom SAmple Consensus)算法估计相邻帧间的仿射变换矩阵;再根据文献[6]思想,将视频帧划分为均匀的网格,选取均匀网格中的一格,把相邻帧间仿射矩阵与前一帧相机运动路径累乘,由此计算视频的运动轨迹。再通过极小化能量函数优化平滑多条网格路径。最后由原相机路径与平滑相机路径的关系,计算相邻帧间的补偿矩阵,利用补偿矩阵对每一帧进行几何变换,从而得到稳定的帧序列。本文算法框架如图1所示。

Figure 1 Block diagram of the algorithm in this paper图1 本文算法框图
2 基于特征跟踪的全局运动估计
基于特征跟踪的全局运动估计主要分为以下4步:
首先选取视频第1帧作为基准,而后进行相邻帧间的处理,通过直方图均衡化、高斯或卡尔曼滤波等方法进行预处理;然后进行SIFT[12]特征点的检测及KLT跟踪,主要检测图像中梯度变化较大的点,对相邻帧间的特征点进行跟踪;再根据之前跟踪匹配的特征点,估计出帧间的仿射变换;最后将帧间的仿射变换进行累积,得到相机的路径。
2.1 SIFT特征点提取
SIFT算法对视角变化、仿射变换、噪声等保持较好的稳定性;同时,在图像旋转、尺度缩放、亮度变化等方面具有很好的不变性。SIFT算法步骤如下所示:
(1)尺度空间和极值点的检测。图像I(x,y)的高斯尺度空间(如图2a左侧)可用式(1)表示:
L(x,y,σ)=G(x,y,σ)·I(x,y)
(1)
得出不同尺度下的特征点后,进一步由高斯尺度空间生成高斯差分尺度空间DOG(Difference Of Gaussian)。其DOG(如图2a右侧)可用式(2)表示:
D(x,y,σ)=(G(x,y,kσ)-G(x,y,σ))·I(x,y)
(2)
其中,k为组内总层数的倒数。
接下来在DOG尺度空间通过比较每一个像素和它所有相邻像素的值,从而得到极值点,如图2b所示。

Figure 2 Schematic diagram of feature point acquisition图2 特征点获取示意图
(2)关键点定位及其主方向确定。关键点是由DOG空间的局部极值点组成的。首先利用拟合关系确定关键点的精确位置和尺度。在完成关键点的梯度计算后,使用直方图统计邻域内像素的梯度和方向,然后建立关键点邻域像素的梯度方向直方图,直方图的峰值方向代表了关键点的主方向。如图3所示。
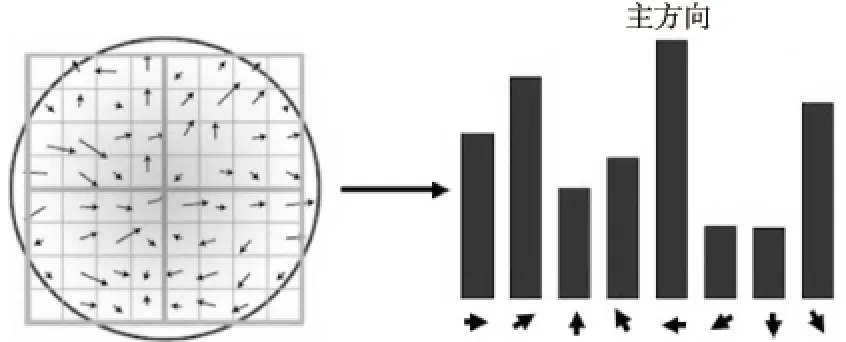
Figure 3 Main gradient direction determination图3 主梯度方向确定
(3)关键点描述子的生成。先将坐标轴移动到关键点的主方向,以关键点为中心取8×8窗口,计算图像每个像素的梯度。然后建立45°的等间隔梯度直方图,计算得到不同方向的累加值。最后利用归一化处理得到的累加值作为一个描述子。如图4所示。
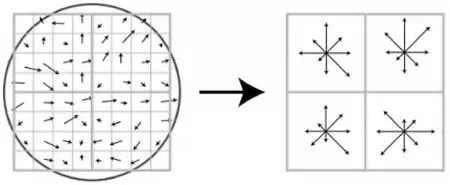
Figure 4 Key point descriptor generation图4 关键点描述子生成
通过SIFT算法提取视频每一帧特征点,得到特征点如图5所示。

Figure 5 Feature points of a sample video frame extracted by SIFT algorithm图5 SIFT算法提取视频帧的特征点
2.2 KLT算法跟踪
提取视频中相邻2帧间的SIFT特征点后,需要对其特征点进行跟踪。主要的匹配跟踪方法有K最近邻算法、快速最近邻逼近搜索算法、KLT算法[13]等。KLT算法是基于最优估计的匹配跟踪算法,也是一种基于特征点匹配算法。由于其在运动速度小的情况下匹配精度较高、耗时较少[11],所以本文采用该算法进行特征点跟踪。
KLT跟踪算法假设目标在视频流中只产生一致性的小位移,并且目标的灰度变化不大。那么,算法必须是在以下3个假设成立的前提下产生良好的效果:(1)亮度一致;(2)时间连续或者运动位移小;(3)空间一致性,邻近点有相似运动,保持相邻。本文使用的抖动视频都由移动设备拍摄所得,运动速度较小,帧间位移也较少,满足上述的3点假设。因此,使用KLT算法匹配可以缩小匹配过程中的搜索范围,减少匹配时间,且有较高的匹配精度。
KLT算法是一种以待跟踪窗口在视频相邻帧间的灰度差平方和(SSD)作为度量的匹配算法[11]。假设一个包含特征纹理信息的特征窗口W,设t时刻对应的视频帧用I(x,y,t)表示,t+τ时刻对应的视频帧用I(x,y,t+τ),其对应的位置满足式(3):
I(x,y,t+τ)=I(x-Δx,y-Δy,t)
(3)
其中,Δx和Δy为特征点X(x,y)的偏移量。在I(x,y,t+τ)中的每个像素点,都可以根据I(x,y,t)中相对应的像素点平移d(Δx,Δy)求得。
假设给定的相邻帧I和J,定义ε为:
(4)
其中,W是给定的特征窗口,ω(X)为权重函数,且常设为1。
将式(4)中J(X)-I(X-d)替换成其对称的形式J(X+d/2)-I(X-d/2),可改写为式(5):
(5)
为了得到最佳匹配点,将J(X+d/2)进行泰勒展开,去掉最高次项,仅保留前2项,g是泰勒展开式的一阶泰勒系数,gx和gy分别为x和y方向上的一阶泰勒系数。根据式(5)对d进行求导,可得式(6):
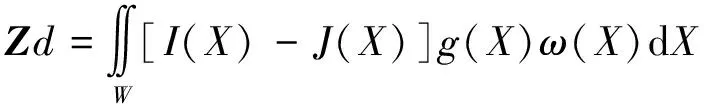
(6)

(7)
其中,d表示特征窗口W中心的平移,dk表示第k次牛顿迭代计算所得d值。在迭代过程中,计算d需要使用初始估计值d0,设初始值d0=0。
通过KLT跟踪算法得出视频帧的跟踪点,如图6所示。

Figure 6 Feature points of a sample video frame tracked by KLT algorithm图6 KLT算法跟踪视频帧的特征点
2.3 帧间全局运动估计
相邻视频帧间的全局运动主要表现为平移、缩放、旋转等变换,其他更加复杂的变换形式都由这些基本变换组合而成,比如相似变换、刚性变换和仿射变换[14]等。本文采取仿射变换作为相邻帧间的全局运动,利用RANSAC算法估计出帧间的仿射变换矩阵。
其基本数学模型如下所示:
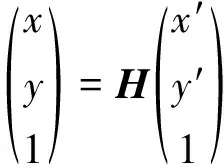
(8)
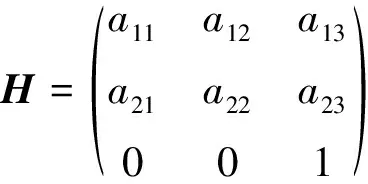
对于输入视频相邻的2帧图像I和J,分别设为第t帧和第t+1帧。先用SIFT算法检测图像的特征点,再对检测出来的SIFT特征点通过KLT算法进行特征追踪匹配,最后对跟踪匹配到的特征点利用RANSAC算法估计相邻帧间的仿射变换矩阵。


(9)
其中,Ht-1表示第t-1帧与第t帧的仿射变换矩阵。
通过帧间运动计算相机的运动轨迹。网格i运动路径计算如图7所示。
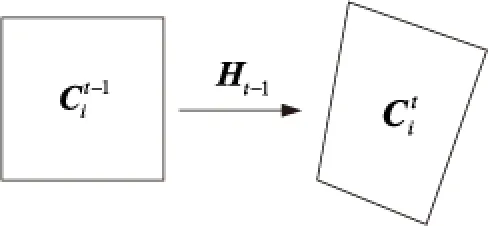
Figure 7 Motion path of the grid图7 网格的运动路径
3 基于多网格路径的运动平滑
选择基于2D捆绑相机路径[6]框架来稳定视频。本文将求出的相邻帧间仿射变换矩阵,应用于下一帧均匀的网格中。具体地,设输入的视频共有N帧,将视频的每一帧划分为m×n的均匀网格。通过求解相邻帧间的仿射变换矩阵,可以得出相邻网格运动。进一步,计算相机的运动路径轨迹。
(10)

设相机的原始运动路径为Ci,i=1,2,3,…,m×n,而相机的运动路径轨迹是由所有网格的路径合成的。
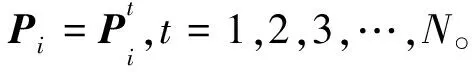
先针对一条路径进行平滑。给定路径C,若要得到处理后的平滑路径P,则C=Ct,P=Pt。根据文献[6]的思想,P可以通过极小化能量函数得到,该能量函数如式(11)所示:
(11)
其中,λt为自定义参数;Ωt表示第t帧的相邻帧;‖Pt-Ct‖2项使得平滑处理后的路径尽可能地接近原始路径,确保稳像后的视频的裁剪率与扭曲率较小;‖Pt-Pr‖2为平滑项,用于稳定原始路径。
如果对于每一条网格路径都采取式(11)平滑相机运动轨迹,则视频帧对应的空间网格不能被保留,会导致稳像后的视频出现扭曲率较大的情况。所以,相机运动轨迹的平滑是通过极小化能量函数来平滑所有的空间网格。其能量函数如式(12)所示:
(12)
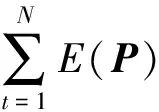
i=1,2,3,…,m×n;t=1,2,3,…,N
(13)
通过基于Jacobi的迭代[15]的方法求解式(13)稀疏线性方程组,迭代形式用式(14)表示:
(14)

4 运动补偿
由运动平滑得到相机运动轨迹后,根据原相机运动轨迹和求得的新的运动轨迹之间的关系,可得到新的运动网格。依据新的运动网格和原视频网格间的位置差异,可求得相邻每帧的运动补偿,最后对每一帧进行运动补偿,进而获得稳定的视频。
通过运动平滑对相机路径Ct平滑处理之后,将对视频的每一帧进行补偿。假设补偿矩阵为Bt,则得到的视频帧间的路径Pt满足:
Pt=CtBt
(15)
通过式(15)计算得出相邻帧间的补偿矩阵Bt。计算每一帧的补偿矩阵后,利用Bt对每一帧图像进行几何变换,从而得到稳定的帧序列,也就得到了稳定的视频。
5 实验结果与分析
将本文提出的算法与Liu等人[6]的捆绑相机路径算法、Liu等人[7]的MeshFlow模型算法以及Javier[16]的参数模型算法进行了大量对比实验。图8展示了实验中使用的视频数据集,编号为1~8。测试视频来源于文献[6,10]提供的公开数据集,其中视频1~6来自文献[6],视频7、视频8来自文献[10],且视频的分辨率均为640×360。视频1具有单个前景运动物体,视频2具有多个运动物体,视频3有小范围镜头移动,视频4有快速移动的部分,视频5和视频6都有小范围的左右摇晃,视频7是沿着同一方向的移动,视频8具有大范围的左右摇晃。
本文采用相邻帧间的PSNR(Peak Signal to Noise Ratio)[8]和SSIM(Structural Similarity Index)[17]均值及相对应的标准差作为客观质量评价指标。本文在Intel酷睿i5-3230M 2.6 GHz CPU和4 GB内存的计算机上,利用未经优化的Matlab 2017b进行实验。实验中,在运动估计阶段,把视频每一帧都划分为8×8的均匀网格。
实验结果如表1和表2所示。由于视频8的运动复杂性,采用文献[7]的MeshFlow未能生成最终的稳定视频,因此未记录其PSNR值与SSIM值。

Figure 8 Video data used in the experiment,numbered from 1~8图8 实验中使用的1~8号视频数据
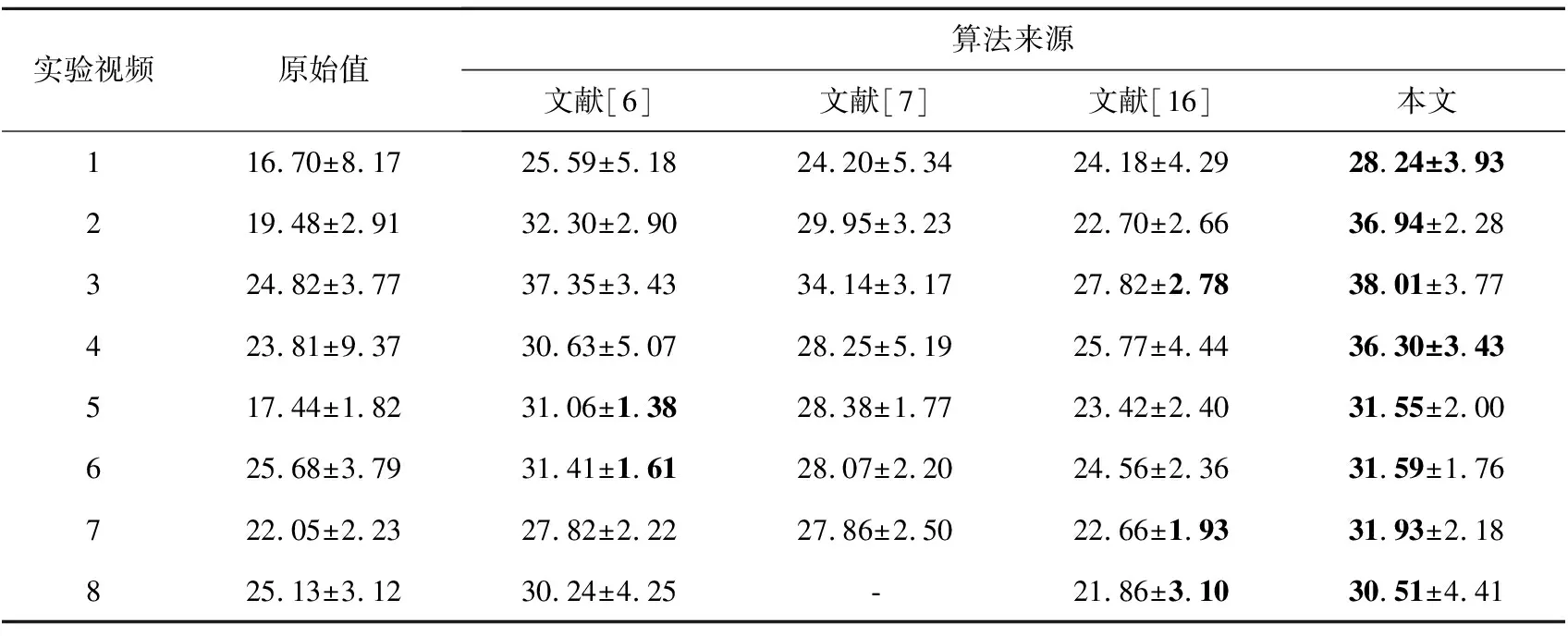
Table 1 Comparison of PSNR mean and standard deviation between frames

Table 2 Comparison of SSIM mean and standard deviation between frames
通过表1可以发现,实验选取的8个视频,稳像后的PSNR值与原视频相比得到了明显提高,说明相邻帧间的灰度差变小,视频帧序列稳定。8个视频原始PSNR值平均值为21.9 dB,本文算法的平均值为33.1 dB。稳像后的PSNR值平均提升了11.2 dB。捆绑相机路径算法平均PSNR值为30.8 dB,相比提升2.3 dB。通过表2可以发现,本文的稳像算法有效提高了图像间的结构相似性,稳像后比稳像前SSIM大约提升了59%。相比捆绑相机路径算法平均SSIM值提升3.3%。
本文算法主体包含2部分:使用SIFT算法与KLT算法相结合的特征跟踪和基于多网格路径的运动平滑。本文采用SIFT算法对视频帧进行特征提取,并使用KLT算法对特征点进行跟踪。SIFT特征是图像的局部特征,其对旋转、尺度缩放、亮度变化具有不变性,对视角变化、仿射变换、噪声也具有一定程度的稳定性。SIFT算法对于部分物体遮蔽的特征提取效果也十分不错,因此对所选的8个视频都有很好的特征提取效果,这样使得KLT算法跟踪更加精确,使仿射矩阵计算更加准确,也将使得最终的稳像效果较好。在多网格路径的运动平滑部分,文献[6]将视频每一帧划分为均匀的网格,并求出相邻每个均匀网格的单应性变换矩阵,应用于下一帧均匀网格中。本文算法将全局运动估计用于帧间的局部运动估计,相比文献[6]更能使抖动视频变得稳定。相比文献[7],本文算法更加准确地表示了视频全局运动轨迹,且计算量小。文献[7]提出的MeshFlow是平滑图像空间稀疏运动,仅在网格顶点处具有运动矢量。匹配的特征点上的运动矢量被传递到它们对应的附近网格顶点,运动轨迹变复杂,整个变换矩阵计算也变得复杂。相比文献[16]直接估计帧与帧之间的全局变换,本文算法提出的基于SIFT与KLT相结合的特征跟踪能够更加精确地匹配跟踪特征点并计算出全局变换矩阵,使得最终稳像效果较好。
6 结束语
针对手持移动设备拍摄的抖动视频问题,本文提出了一种基于特征跟踪和多网格路径运动的视频稳像算法。通过SIFT算法提取视频帧的特征点,采用KLT算法追踪特征点,利用RANSAC算法估计相邻帧间的仿射变换矩阵,将视频帧划分为均匀的网格,计算视频的运动轨迹,再通过极小化能量函数优化平滑多条网格路径。最后由原相机路径与平滑相机路径的关系,计算相邻帧间的补偿矩阵,利用补偿矩阵对每一帧进行几何变换,从而得到稳定的视频。实验表明,该算法在手持移动设备拍摄的抖动视频中有较好的结果。
