基于GPU的并行Turbo乘积码译码器*
2020-06-02李荣春潘衡岳
李荣春,周 鑫,潘衡岳,牛 新,高 蕾,窦 勇
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
Turbo乘积码TPC(Turbo Product Code)是一类高性能前向纠错码FEC(Forward Error Correction)。1994年,Pyndiah等[1]提出了一种基于软译码和软判决输出的迭代译码算法,该算法在误比特率BER(Bit Error Rate)方面接近最优译码性能。文献[2]中介绍的Turbo译码算法被称为Chase-Pyndiah算法,它显著降低了乘积码的译码复杂性。因为软输入软输出SISO(Soft-In Soft-Out)译码方案与卷积Turbo码CTC(Convolution Turbo Code)的译码方法非常相似,所以TPC也称为块Turbo码BTC(Block Turbo Code)。之后,TPC因其在高码率下具有良好的BER性能和合理的译码复杂度而得到广泛应用。
TPC在现代通信网络中发挥着重要作用,出现在几个通信标准[3]中,例如IEEE 802.16[4]和IEEE 802.20[5]。此外,TPC还广泛应用于光通信系统[6]、卫星通信应用和数据存储系统[7]。
许多研究都聚焦于提高译码性能和降低TPC译码器的译码复杂度[8 - 10]。但是,大多数工作都基于硬件平台,例如专用集成电路(ASIC)[11]。基于图形处理单元(GPU)的TPC译码器的实现很少。可以看出,一组二维乘积码通常以二维矩阵形式出现,并且在译码过程中涉及许多矩阵的加法和乘法运算。由于GPU具有强大的并行处理能力和浮点运算能力,因此通常用于加速大规模矩阵运算。因此,基于GPU译码是提高TPC译码效率的可行方案。与专用硬件译码器相比,在GPU上译码具有更好的灵活性和通用性,还可以节省开发时间。
软件定义无线电SDR(Soft Defined Radio)的提出可以通过软件配置支持各种通信标准,而无需改变硬件平台[12]的理念。基于GPU的译码也是SDR的解决方案,在一些实例中,GPU译码器的吞吐率甚至优于ASIC[13]。已有研究提出了许多高效的基于GPU的译码器,例如Viterbi译码器[14]、Turbo 译码器[15]和LDPC 译码器[16]。因此,基于GPU的TPC译码器也能够满足SDR的要求。
Chase-Pyndiah算法是一种迭代算法,每轮迭代之间存在数据依赖。尽管文献[10,17]提出了几种并行方法,但很少有并行实现基于诸如GPU之类的软件平台。文献[18]提出了由BCH(Bose-Chaudhuri-Hocquenghem)码组成的TPC的高吞吐率译码,实现了TPC的并行译码,且引入了几种有效的存储器控制方法来提高译码效率。
在本文中,TPC由汉明码构成,本文的目标是简化译码过程并有效利用GPU上的资源。本文解决方案中考虑了细粒度和粗粒度并行性,不仅能够同时译码TPC矩阵的每一行(或列),而且并行计算扰动序列和有效码字。实验结果表明,与基于CPU的TPC译码器相比,本文方法译码延迟减少,而吞吐率显著提高。
2 乘积码
乘积码是由Elias于1954年推出的。如文献[19]中所述,可以使用2个短分组码高效地构建乘积码。假设C1(n1,k1,d1)和C2(n2,k2,d2)为2个线性分组码,其中ni,ki和di(i=1,2) 代表码长度、信息位数和最小汉明距离。C1和C2可用于构建乘积码P。使P=C1⊗C2,P的参数为(n1×n2,k1×k2,d1×d2)。乘积码P的构建过程如下所示:
(1) 将k1×k2信息位放在码字矩阵的前k1行和k2列中;
(2) 使用码C1编码k1行;
(3) 使用码C2编码k2列;
(4) 计算并将扩展位附加到相应的行和列。
如上所述可以发现,通过使用扩展的线性分组码,仅通过非常小的码率损失,可以大大增加TPC的最小汉明距离。图1所示是二维TPC码的结构。

Figure 1 Structure of 2D Turbo product code图1 二维TPC码结构
3 Chase-Pyndiah译码算法
文献[2]中描述的Turbo译码算法适用于基于线性分组码的任何乘积码。因此,我们用扩展汉明码构造乘积码,每行和列的译码方法对应汉明码译码方法。本文提出的基于GPU并行译码算法就是基于这种方法译码的。
3.1 汉明码译码
假设C是二进制汉明码,其中C=(c1,c2,…,cn)。设H为C的校验矩阵,H中的所有列都不相同;y是经过硬判决的二进制向量。C的syndrome由式(1)得到:
s=yH
(1)
如果C中第i位出错,那么s等于hi,其中hi是H的第i列。汉明码的该特性可用于定位接收数组y中的错误位置。
由于H在译码之前就已经确定,可以构造纠错表以定位错误位置。hi是一个二进制序列,可以转换为十进制值。设这个十进制值是纠错表的索引,相应的列索引是表的值。然后,一旦计算出syndrome,就可以找到y的错误位置。
3.2 Chase-Pyndiah算法
通常,码字通过二进制相移键控BPSK(Binary Phase Shift Keyind modulation)调制,并且由{0,1}序列映射到{-1,+1}序列。然后它们通过加性高斯白噪声AWGN(Additive White Gallssian Noise)信道传输。假设收到的序列是r=(r1,r2,…,rn)。以乘积码行的译码为例,以下步骤描述了主要的译码过程:
步骤1可靠性数组|K|={|r1|,|r2|,…,|rn|},其中|ri|为接收值ri的绝对值,每行的输入序列y={y1,y2,…,yn},其中:
(2)
其中,i=1,…,n。
步骤2生成2p个测试样例。通过获取|K|中p个最小值的索引,找到p个最不可靠的位置。对于每个测试样例ti,i=1,2,…,2p,ti中的p个位置设置为2p个由0和1组成的可能组合,ti中的其他位置设置为0。
步骤3确定2p个扰动序列:
zi=ti⊕y,i=1,2,…,2p
(3)
然后对2p个扰动序列进行译码:
(1) 首先,通过式(4)计算扰动序列的syndrome:
si=ziHT,i=1,2,…,2p
(4)
其中,H是汉明码的奇偶校验矩阵。
(2) 矩阵H在编码某个汉明码时可事先确定,因此可以确定由syndrome索引的查找表(LUT),有效地找到错误位置。因此,可以通过式(5)纠正错误位:
(5)
LUT(si)是zi的错误位置,由si索引。
(3)计算奇偶校验位zi:
(6)
前3个步骤描述了Chase算法的搜索过程[20],旨在获得以y为中心,(di-1),i=1,2 为半径的范围内最可能的码字。
步骤4计算已译码字的模拟权重为:
wi=- 〈zi,r〉
(7)
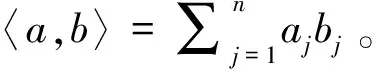
d=zm
(8)
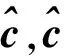
(9)
步骤6更新外部信息E:
(10)
其中,β是可靠性因子。
步骤7更新列的软输入:

(11)
其中,α是缩放因子。
(12)
注意到,在列计算结束后,译码器的软输出会按式(13)更新:
(13)
完整的译码过程如图2所示。

Figure 2 Process of Chase-Pyndiah algorithm图2 Chase-Pyndiah算法计算过程
4 TPC译码器GPU实现
GPU上的流处理器(SM)提供强大的计算能力,成千上万的线程同时在这些SM上工作。通常,通过尽可能多地并行完成工作,可以实现更低的延迟和更高的吞吐率。虽然GPU具有强大的计算能力,但GPU上的资源有限。例如,存储器和寄存器是GPU上的有限资源。因此,在优化算法时,需要了解每个线程的工作负载和进行合理的存储器分配。
本节研究并行TPC译码算法,以高效利用GPU上的资源。为了简化译码过程,对算法的某些部分进行了修改。经过优化串行计算的部分,减少了译码延迟。此外,通过利用二维线程块和多通道译码方法实现了更高的并行度。
4.1 GPU和CUDA的架构
SM是GPU上的基本单元,启动核函数后,会将线程块分配给某个SM。每个SM都有寄存器文件、缓存、CUDA核心和处理器所需的其他必要单元。可以一次将多个线程块分配给同一SM,根据SM空闲资源情况来安排线程块[21]。计算统一设备架构(CUDA)为用户提供了一种在GPU上利用计算资源的简便方法。CUDA将GPU上的硬件计算单元映射到逻辑线程网格和块,在CUDA编程时,所有工作都由线程组织。
4.2 多线程计算和内存层次结构
Chase-Pyndiah算法是一种迭代译码算法,本文聚焦于优化一轮迭代中的译码过程。通常,组成乘积码的2组汉明码C1和C2是同源码字,这意味着n1=n2,k1=k2,d1=d2。乘积码码字P被组织为二维矩阵,矩阵的每行或每列是汉明码字,并由基本译码器译码。在并行译码器中,n行或n列被同时译码。
令每行码字或列码字的参数为(n,k,d)。在并行译码器中,分配用于译码一行或一列的线程数始终等于码字长度,即n,所以有n×n个线程用于并行译码。因为每个块的最大线程数是1 024(CUDA计算能力为7.5),所以通过将每个行或列的译码计算分配给不同的线程块以避免过载。因此,分配n个线程块以同时译码n行或列。注意到,对一列的译码需要来自所有行的译码结果,因此在2次半迭代之间需要同步。该并行方法的优点是在不改变译码程序的情况下支持任意大小的码字。
GPU上的内存层次结构包括全局内存、共享内存和常量内存。全局内存通常用于GPU和CPU之间的通信,因此输入矩阵和估计结果存储在全局存储器中。GPU上的共享内存速度更快,但容量更小,中间结果存储在共享存储器中,以减少访存的开销。在本文的TPC译码器中,输入矩阵R存储在全局存储器中,在译码过程开始时它被加载到共享存储器,以便进行译码计算,并且在译码结束时将结果更新为R并存入全局存储。
4.3 并行基本译码器
算法1是并行基本译码器算法。基本译码器是用于译码字输入矩阵的一行或一列的基本译码单元。但是,如第3节介绍,此译码过程需要分阶段执行7个步骤。本节介绍了一种并行基本译码器,以简化该译码过程。
算法1并行基本译码器
输入:p,z,r,lrp。
输出:dist。
1.tx←threadIdx.x;
2.ty←threadIdx.y;
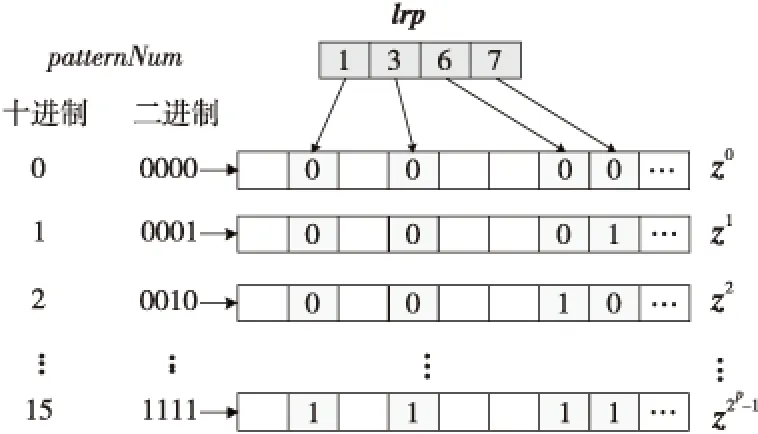
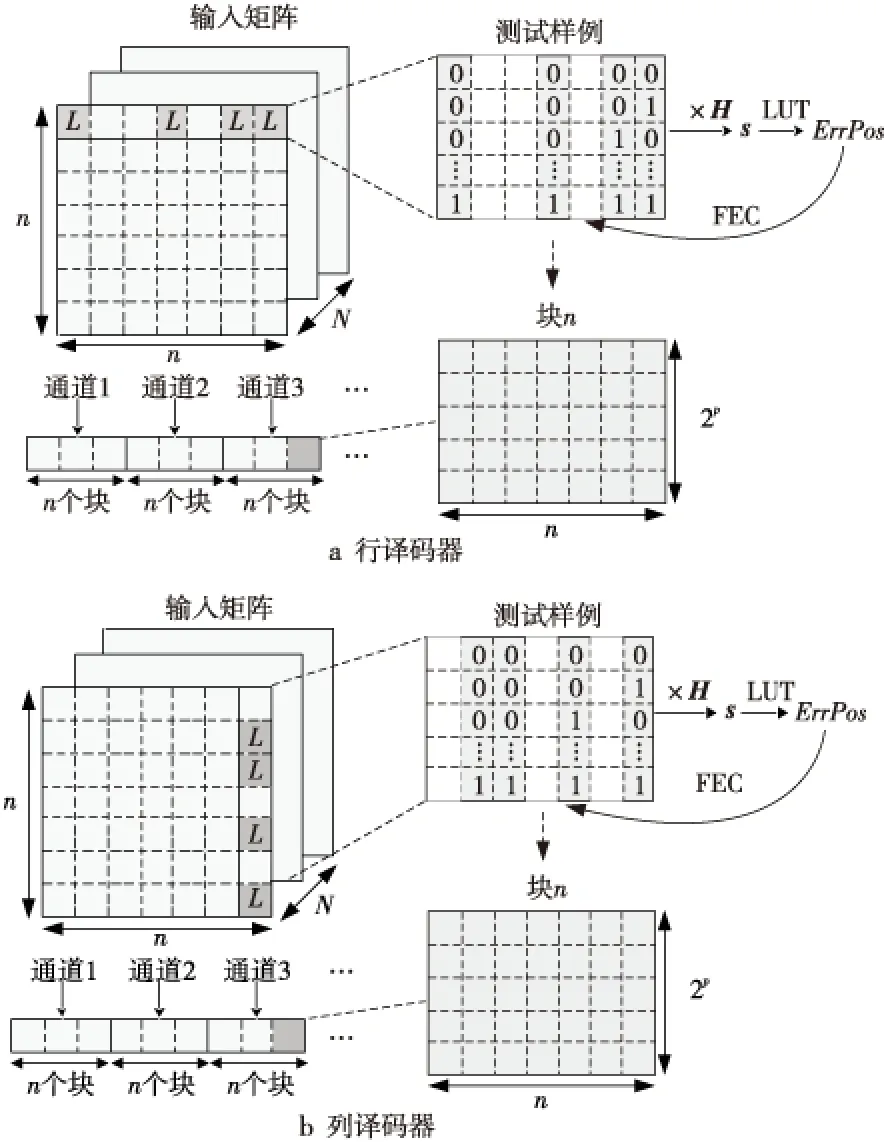
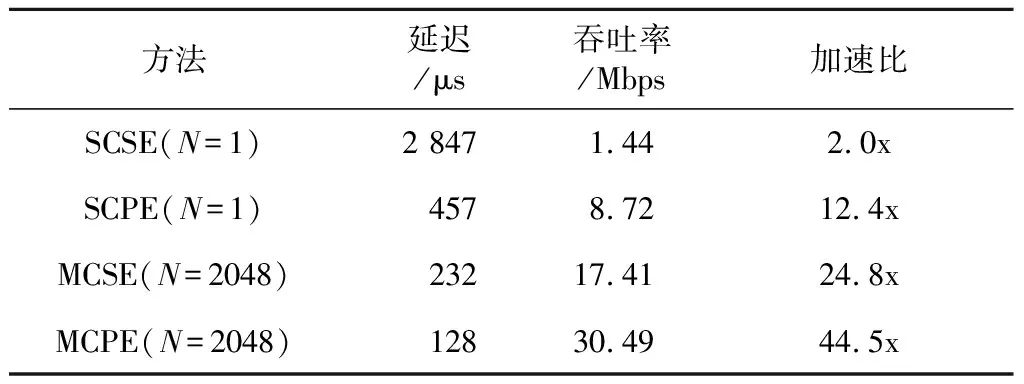
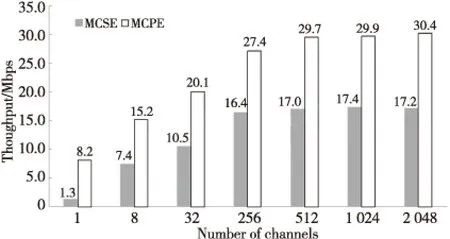
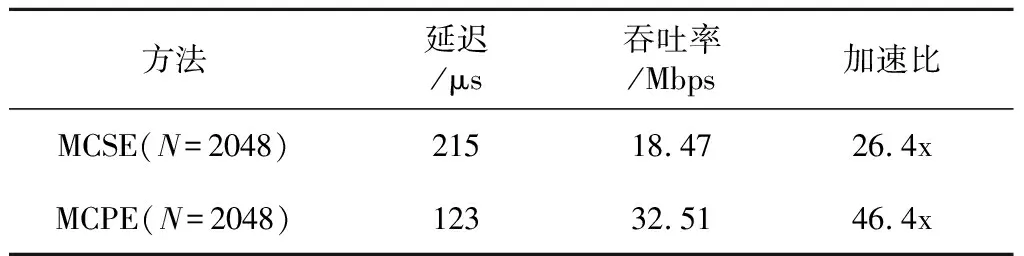
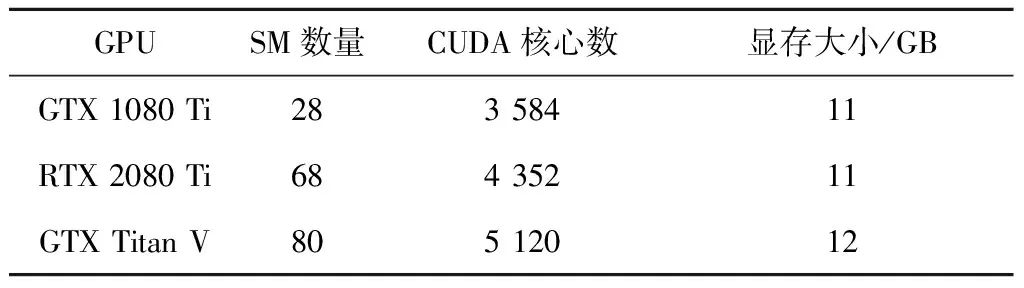
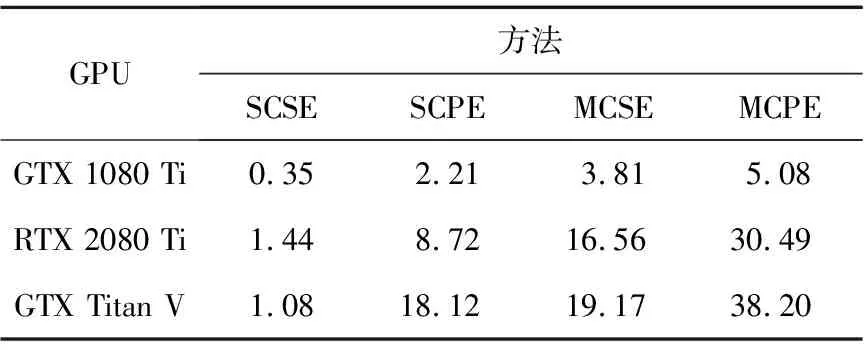
3.iftx 4.patternNum←(ty>>(p-tx-1)); 5.zty[lrp[tx]]←patternNum⊕hdata[lrp[tx]]; 6.end if 7.iftx 8.syndromeBinty←ztyHmod 2; 9.end if 10.iftx==0 then 11. forj=0→d-1 do 12.stv+=syndromeBinty<<(V-j-1); 13. end for 14. ifsty≠0 then 15.errPosty←LUT[sty]; 16.zty[errPosty]←1-zty[errPostv]; 17. end if 18.end if 尽管可以通过n个线程块同时译码TPC,但在这种分配方案下,一轮迭代过程中的译码过程仍未被优化。在计算得到最不可靠的位置之后,在这些位置处更新硬输入数组,以构建2p个测试样例。这些测试样例通过汉明译码方法译码,然后计算这些已译码字与软输入阵列之间的相关性。根据相关性,从2p个码字中选择最大似然码字。在原始算法中,上述过程是串行的,这意味要串行处理测试样例的构造、汉明译码和相关的计算。但是,不同测试样例之间不存在依赖关系,完全可以并行处理此过程,因此,本节研究并行基本译码器,以简化该译码过程。在优化并行基本译码器时,我们修改了原始算法以提高译码效率,并实现了几种优化方法。 在并行基本译码器中,分配2p×n大小的二维线程块用于译码。线程的垂直方向用于计算2p个测试样例并将它们并行译码。用ty表示块的列索引,用tx表示块的行索引。在算法1中,z表示扰动序列矩阵,它是大小为2p×n的short int矩阵;hdata是硬判决输入{0,1}序列;lrp是已经在先前步骤中计算过的最不可靠位置的数组。 首先,使用lrp来生成测试序列t。扰动序列z是t与硬判决数组hdataxor运算的结果。在我们的并行算法中,可以通过样例数patternNum高效地计算扰动序列。如图3所示,patternNum的大小为0~2p-1。它的二进制形式用于生成2p个不同的序列,这些序列由2p个0和1组合构成。该方法用int数替换n-length数组,节省了2p×n×4字节共享内存。 Figure 3 Constructing test patterns图3 测试样例的构建 其次, 使用H和patternNum计算2p扰动序列的syndrome,其中H是(n-1)×d奇偶校验矩阵。syndromeBin是2p×d矩阵, 是由z中每一行的syndrome值的二进制表示组成。V表示校验位的数量。一旦计算出syndrome,就根据由syndrome索引的查找表校正错误位。 最后,z中每一行的最后一位,即前n-1位的奇偶校验位,可通过并行归约来进行更新。伪代码的最后一行计算zty和r之间2p的相关性。 本文所提出的并行基本译码器利用二维线程块来译码每个行或列,这种并行方法在译码过程中减少了循环次数。例如,令p=4,然后在计算测试样例和有效码字时迭代次数为16。循环带来的开销使得这一过程在GPU上计算效率极低,因此可以利用并行基本译码器来提高译码效率。 在优化TPC的译码算法时,不仅要考虑细粒度并行性,还要在GPU上实现粗粒度并行。 本文设计了多通道译码方法,以便有效地利用GPU上的资源并提高译码吞吐率。本文的并行基本译码器的块大小为2p×n,n个线程块被分配用于译码TPC的n行或列。设n为一个译码组,分配N个线程块对来自N通道的码字同时译码。 图4描述了多通道译码器的主要思想。其中,N通道的输入矩阵由N组块译码。L代表最不可靠位,LUT是事先构造好的查找表。在行译码器中,每个块译码输入矩阵的一行。对于列译码器,每列输入矩阵被并行译码。H表示奇偶校验矩阵。s是测试样例和H的乘积。ErrPos是通过搜索由syndromes索引的查找表获得的错误位置,其中FEC对码字进行纠错。 在图4所示的的多通道TPC译码器中,通道数量可根据GPU的计算能力进行配置和自适应。 Figure 4 Multi-channel parallel TPC decoder图4 多通道并行TPC译码器 并行TPC译码器由2部分组成:一部分是行译码核函数,它在前半个迭代时启动;另一部分是列译码核函数,一旦行译码核函数完成就会启动。 算法2是整个迭代译码过程。输入为TPC矩阵R、最不可靠位数p、迭代次数maxIter和syndromeNum。因为列译码器按列译码并更新R,所以它必须等到行译码器更新完R的所有行才能开始执行。码字估计值由最后一步硬判决结果决定。 算法2迭代译码算法 输入:R,p,sydromeNum,maxIter。 输出:EstimatedCodes。 1.foriter=0 →maxIterdo 4.end for 算法3并行行译码算法 输入:R,p,syndromeNum。 1.tx←threadIdx.x; 2.ty←threadIdx.y; 3.r←Rblockidx.x;//R的第blockIdx.x行 4.E←|r|; 5.ifr[tx]≥0 then 6.hdata[tx]←1 7.else 8.hdata[ty]←0 9.end if 10.lrp←BitonicSort(E); 11.zty←hdata;//z的第ty行 12.dist←ElementaryDecoder(p,z,r,lrp) 13.iftx==0 &ty==0 then 14.tmp←MAXVAL; 15. fori=0→2p-1 do 16. iftmp 17.min←i 18. end if 19. end for 20.end if 21.wc←MAXVAL; 22.fors=0→2p-1 do 23. ifzty==(1-zty) &dist[s] 24.wc←dist[s] 25. end if 26.end for 27.ifwc 28.E←(2zmin-1)(wc-dist[min])-r 29.else 30.E←(2zmin-1)β 31.end if 本节测试所提出的并行TPC译码器在GPU上的延迟和吞吐率,为了验证优化方法的效果,测试了不同版本的程序,此外,还测试了基于不同GPU的译码吞吐率。测试结果表明,本文的并行译码器比串行译码器具有更低的延迟和更高的吞吐率。实验用的CPU是Intel i7-8700K,3.7 GHz,GPU是NVIDIA RTX 2080 Ti。CUDA版本是10.1。 测试样例中的TPC由(64,57)的扩展汉明码构成,最后一位是奇偶校验位,用于检查码字是否有效。参数p为4,迭代次数为6,缩放因子α=1和β=0.5,信噪比(SNR)为3 dB。实验验证了本文GPU基译码器的正确性,结果表明BER性能接近Matlab中的仿真结果。 当使用CPU译码时, 延迟为5 709 μs, 吞吐率为0.7 Mbps。加速比的计算方法如式(14)所示: (14) 其中,tCPU是CPU的译码延迟,tGPU是GPU的平均译码延迟。 测试结果如表1所示。表1中的缩写解释如下:SCSE代表单通道和串行基本译码器,SCPE代表单通道和并行基本译码器,MCSE代表多通道和串行基本译码器,MCPE代表单通道和并行基本译码器。由表1可知,通过GPU译码比使用未经优化的SCSE译码器的CPU译码快近2倍。优化并行方法的加速比大于12。多通道方法减少了平均延迟并进一步提高了吞吐率。最高吞吐率超过30 Mbps,是CPU吞吐率的44倍。测试样例和有效码字的计算在SCSE中是串行的,但在SCPE中是并行的。因此,SCPE的译码吞吐率比SCSE高6倍。这种改进主要归功于基本译码器的优化。并行基本译码器的译码块是二维的,这个二维线程块包含2p×n个线程,在(64,57)的情况下为1 024。此外,RTX 2080 Ti的计算能力为7.5,每块的最大线程数为1 024,因此并行基本译码器在GPU上实现了较高的占用率。 Table 1 Performance comparison of various methods on RTX 2080 Ti 从表1中可以发现,在多信道的情况下,吞吐率的提高不如单信道的情况那样显著。MCPE的吞吐率仅比MCSE高2倍。图5显示了吞吐率随通道数量的增长情况,并非所有1~2 048通道数的结果都在直方图中给出,本文选择了8个典型数字来表示其增长趋势。用N表示通道数,结果表明,当N>256时,多通道译码的吞吐率增加速度变缓。这种变缓的一个原因是数据传输的开销。由于输入数据和译码输出的大小随N增加,CPU和GPU之间的通信延迟变得更高。因此,译码吞吐率受到该延迟的影响。另一个原因是GPU上资源的限制。RTX 2080 Ti具有68个SM和4 352个CUDA核心,每个SM的最大驻留块数是32,因此理论上GPU上的最大驻留块总数是2 176。然而,256通道TPC译码器需要16 384个块用于并行译码,太大的通道数可能导致大多数块必须等到SM空闲时才能计算。此外,每个SM上能使用的寄存器和存储器也是有限的。例如,如果每个SM上的64K 32位寄存器用完,大多数中间数据将被存储在本地存储器中,访问本地存储器的速度比访问寄存器的速度慢得多,因此寄存器耗尽也可能导致严重的访问开销。 Figure 5 Throughput with various channel numbers图5 多通道下变化的吞吐率 由于上述原因可知,更多的通道数不一定带来更高的吞吐率,选取合适的通道数取决于GPU的计算能力。 多个核函数可以在GPU上同时执行。CUDA应用程序通过CUDA流管理核函数启动和内存传输的执行顺序。如果同时启动多个核函数则会为每个核函数分配流ID,具有相同流ID的核函数按顺序启动,具有不同流ID的核函数同时执行。存储器传输和核函数执行的重叠可以提高译码吞吐率。 本节测试了MCSE和MCPE的吞吐率,结果如表2所示,并发执行和内存传输的吞吐率增加了大约6%。带来的加速效果不够明显,这是因为迭代译码过程引入了同步开销。 Table 2 Performance using CUDA stream on RTX 2080 Ti 本文并行译码器的性能是在不同的GPU上测量的,用于测试的CPU平台有NVIDIA GeForce GTX Titan V、RTX 2080 Ti和GTX 1080 Ti。表3给出了这些GPU平台的SM数量、CUDA核心数和内存大小。这些GPU具有不同的计算能力,可用于衡量本文并行译码器在不同规模的计算资源下的执行的性能。结果如表4所示。 基于GTX 1080 Ti的SCSE吞吐率小于基于CPU的吞吐率。此结果表明SCSE无法有效利用GPU上的计算资源。 Table 3 Performance comparison on various GPU platforms 与RTX 2080 Ti相比,GTX Titan V上的CUDA核心数量和SM数量增加了大约20%以上。因此,GTX Titan V上的MCSE和MCPE在表4中具有更高的吞吐率和加速比。此外,SCPE的吞吐率是SCSE吞吐率的16倍。结果表明,GTX Titan V上更多的SM和CUDA核数有助于提高译码吞吐率。 Table 4 Throughput of different methods on different GPU platforms 本文提出了一种基于GPU的并行TPC译码器,可同时译码矩阵的所有行或列。研究了并行基本译码器,以实现更高的吞吐率和更低的译码延迟。所有测试样例和有效码字都是并行生成的。此外,本文还提出了一种多通道TPC译码器,以进一步提高译码吞吐率。 本文测试了4种不同译码器SCSE、SCPE、MCSE和MCPE的延迟和吞吐率,还分析了多通道译码器的局限性。最后,我们测试了本文译码器在不同GPU上的性能,结果表明,该方法具有良好的可扩展性。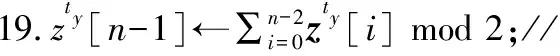

4.4 多通道译码
4.5 并行TPC译码器
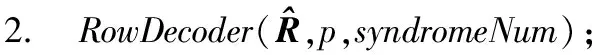
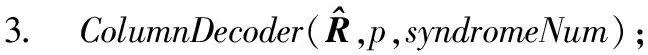
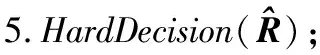

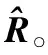
5 实验结果
5.1 延迟和吞吐率
5.2 通道数量
5.3 CUDA流
5.4 不同GPU上的译码
6 结束语
