基于Top-k查询算法的图书自整合信息快速检索方法
2020-05-29董光芹夏文秀
董光芹, 夏文秀
(东北大学 图书馆, 沈阳 110819)
Top-k查询(k项最大值)算法[1]与其他信息识别技术的差异是其不需要通过键盘输入信息数据, 而是采用Top-k查询算法设备输入, 该算法具有信息采集速度快、可靠性高等优点[2-3].图书自整合信息检索是图书馆的一项基本工作, 如何能更方便快速地对图书馆中海量图书进行自整合信息识别是该领域的主要任务.目前, 图书自整合信息快速检索方法已有许多研究成果.文献[4]提出了一种基于模糊聚类与模糊模式识别(STAR)的方法, 该方法对图书信息进行检索时, 对图书借阅用户的信息素质和借阅图书的资源信息检索情况进行聚类分析, 确定图书信息的最佳分类阈值, 实现对图书信息的快速检索, 但该方法存在用户信息不准确、图书资源检索种类繁多的问题, 导致获取信息不精确, 检索结果有误差.文献[5]提出了一种基于特征聚类的信息检索方法, 该方法首先对图书信息进行降维处理, 保留图书信息的关键词特征, 同时去除冗余文本带来的影响, 然后按照图书信息关键词特征相似程度将图书信息特征进行聚类, 确定图书信息检索的目标函数, 采取约束条件对其进行约束, 最后调整图书信息关键词特征的聚类中心和权值, 实现对图书信息的检索, 但该方法工作量较大, 耗时较长, 且未考虑对自整合信息的管理.
基于上述问题, 本文提出一种基于Top-k查询算法的图书自整合信息快速检索方法.仿真实验结果表明, 该方法具有检索速率快、检索自整合信息准确等优点.
1 改进图书自整合信息快速检索方法设计
为更精确完成图书自整合信息的快速检索, 本文采用小波分解方法对自整合信息进行去噪[6].对去噪后的自整合信息进行检索前的预处理, 最终实现基于Top-k查询算法的图书自整合信息检索.
1.1 自整合信息的去噪 本文采用小波去噪的方法对自整合信息进行去噪处理, 小波去噪方法通常可将一维信号的模型表示为S(i)=f(i)+e(i), 其中:S(i)为含噪声的自整合信息;f(i)为真实信息;e(i)为噪声.通常真实的信息为低频信号, 而噪声为高频信号.对于图书变形数据, 变形表现为低频平稳的变化, 数据中的观测误差即为噪声, 具有高频特征, 所以可利用小波去噪的原理去除噪声.小波去噪有很多方法: 小波分解与重构法、非线性小波变换阈值法、平移不变量法、小波变换模极大值法等.本文采用小波分解与重构法, 步骤如下:
1) 一维信号的小波分解, 先根据数据的平滑需要和噪声模型的适应性确定分解所用的小波函数, 本文采用db6函数, 然后确定分解的层数N, 按要求对变形信号进行分解, 如图1所示;
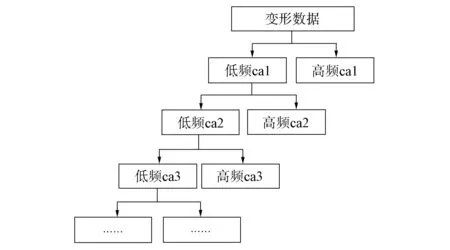
图1 自整合信息的小波N层分解Fig.1 Wavelet N layer decomposition of self-integrated information
2) 小波分解后, 将高频部分进行阈值量化处理;
3) 一维小波重构, 小波分解到第N层后的低频部分和已经阈值处理后的高频部分进行重构, 得到去噪后的变形信息.
采用小波去噪方法时, 通常选用MATLAB工具箱对信息进行处理, 通过wave工具, 将需处理的数据转变为信息选择对应的参数, 并对转变后的参数进行适当调整, 最终完成信息的去噪处理, 从而得到去噪后的信息.通过上述步骤完成图书自整合信息的去噪, 消除无效数据在检索过程中的干扰.
1.2 基于Top-k查询算法的图书自整合信息检索 Top-k查询算法是一种最常用的查询方法, 通过Top-k查询算法对数据集合中的记录进行检索时, 用户可设定不同属性的权值反映其自身偏好, 而系统则根据用户提交的权值估计, 并根据估算后的权值进行匹配, 返回符合该用户需求的前k个结果.Top-k查询能帮助用户从大量数据中得到所需信息, 不需查询所有记录即可获取检索结果, 检索效率较高.本文利用Top-k查询算法对获取的图书自整合信息区域进行可信度分配, 并对词意进行度量, 最终完成图书自整合信息快速检索.
自整合信息检索是指从大量信息中搜寻到所需自整合信息的过程.常用的自整合信息检索模型有Boole模型、空间向量模型、几率模型和文字模型等.本文方法模型以Top-k查询算法为基础对图书进行自整合信息检索.假设图书自整合信息Top-k查询算法框架为Θ={相似,不相似,无法确定}, 图书自整合信息快速检索模型可描述为如下基本可信度分配:
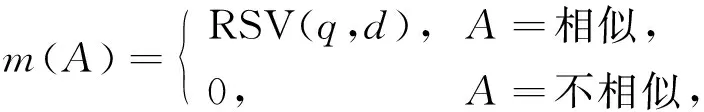
(1)
其中RSV(q,d)表示对应的检索方法中相似度计算结果[7].在该模型中, Bel(相似)=m(相似)=RSV(q,d),pl(相似)=1-Bel(不相似)=1-m(不相似).
图书自整合信息的词意特性和无法确定词意按下述可信度分配:
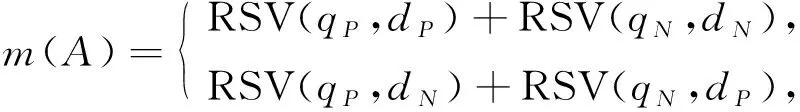
(2)
其中:qP和dP分别为图书自整合信息q和d中的肯定因素;qN和dN为否定因素.基于当前的检索模型, 令词意相似的计算为匹配, 词意不相似的计算为不匹配, 得
Bel(相似)=RSV(qP,dP)+RSV(qN,dN).
(3)
结合相关先验知识对当前检索模型和无法确定的词意进行结合:

(4)
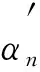
在实际计算中简化为
其中: RSV函数为检索模型的相似度计算方法;l为否定词意的对立系数;m为词意特性系数.
用关于计算事件发生几率的Markov链方法对词意进行度量其在图书自整合信息内的重要性[8-9].采用当前的原始状态几率值和状态变更几率矩阵, 验证事件的未来情况, 步骤如下.
1) 确定原始状态几率向量H0: 即在检索过程中确定图书自整合信息内各词意的原始几率, 公式为
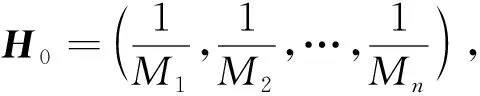
(7)
其中M为图书自整合信息内所有不相同的词数.
2) 计算状态变更几率的矩阵: 按照创建的词图可得出图书自整合信息内词同时出现的矩阵, 再根据矩阵得到各词间的几率变更矩阵Pi×j(i,j=0,1,…,H-1), 计算公式为
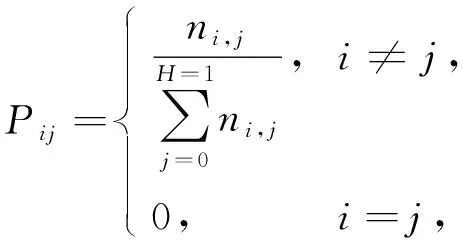
(8)
其中ni,j表示两个词意在图书自整合信息中同时出现的次数.考虑到词意在同部位共同出现次数的关系[10-13], 运用形式类似PageRank算法中混入阻尼因子的方法, 将式(8)改为
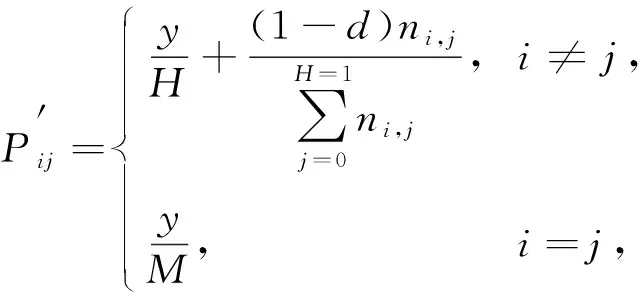
(9)
其中y表示阻尼因子, 初始值取0.18.
3) 计算变更结果: 根据Markov链的特征, 当几率变更矩阵P经过q步几率变更为正规几率矩阵U, 代入模型Bk=B0U中, 得到Bk约束.由式(9)可见, 本文方法采用的几率变更矩阵P已是正规几率矩阵.
4) 确定词的TI: 约束得到状态几率向量B中的几率被用于计算词意在图书自整合信息中的重要性TI, 公式为
TI(ti,d)=BiH,
(10)
其中:i为图书自整合信息t中词意的下标;Bi为约束后向量B中第i个词意对应的几率.
基于上述步骤完成基于Top-k查询算法的图书自整合自整合信息快速检索方法.
2 实验结果与分析
实验平台为Windows10系统, CPU 2.6 GHz主频, 8 GB内存, 利用ImageMatch软件进行仿真实验.实验选取某高校图书馆中的856本图书作为实验对象, 对图书自整合信息进行预处理后, 完成词意匹配, 最终实现对图书自整合信息的快速检索.仿真实验采用文献[4]和文献[5]方法作为对比方法, 以检索所需的时间和准确率作为评价指标.
2.1 检索效果分析 在真实环境下通过所需时间和准确率可体现不同方法的检索性能, 图书信息检索数量和图书信息数量的拟合结果表示检索准确率, 计算方法如下:
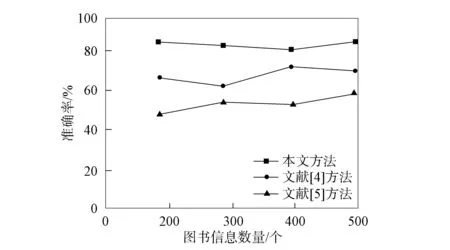
图2 不同方法的准确率对比Fig.2 Comparison of accuracy of different methods
其中G0(j)为图书信息总数量.基于评价指标值的检索结果对比如图2所示.由图2可见, 文献[5]方法的检索效果最差, 本文方法的平均准确率为88%, 文献[4]和文献[5]方法的平均准确率分别为58%和55%.与这两种方法相比, 本文方法的检索效果较好.由于文献[4]方法主要偏于图的检索, 运用随机计算的方式, 从而导致检索效果不准确的情况.而本文方法考虑了词意关系的强弱和时态词意, 因此检索效果比对比方法更好.
2.2 检索效率分析 分别对3种方法的图书自整合信息检索效率进行对比, 对比结果如图3所示.由图3可见, 随着图书自整合信息数量的增加, 3种方法所用时间都呈增加趋势, 文献[5]方法所用时间最多, 其次是文献[4]方法, 本文方法所用时间相对较短, 表明本文方法提高了检索效率.
根据本文方法进行拓展实验, 从实验对象中选取不同的图书自整合信息数量, 计算各组检索自整合信息时间的平均值.图4是3种方法的响应时间.在不同的图书自整合信息数量下, 3组效率排序为: 文献[5]方法<文献[4]方法<本文方法, 由计算可得本文方法的检索效率提高了120.49 ms.由图4可见, 随着关键词数量的增加, 3种方法的时间都有增加, 文献[5]方法时间增加最多, 本文方法增加的时间最少, 这是由于本文方法添加了对时间的限制, 所以增加的时间少于文献[4]和文献[5]方法, 提高了检索效率.
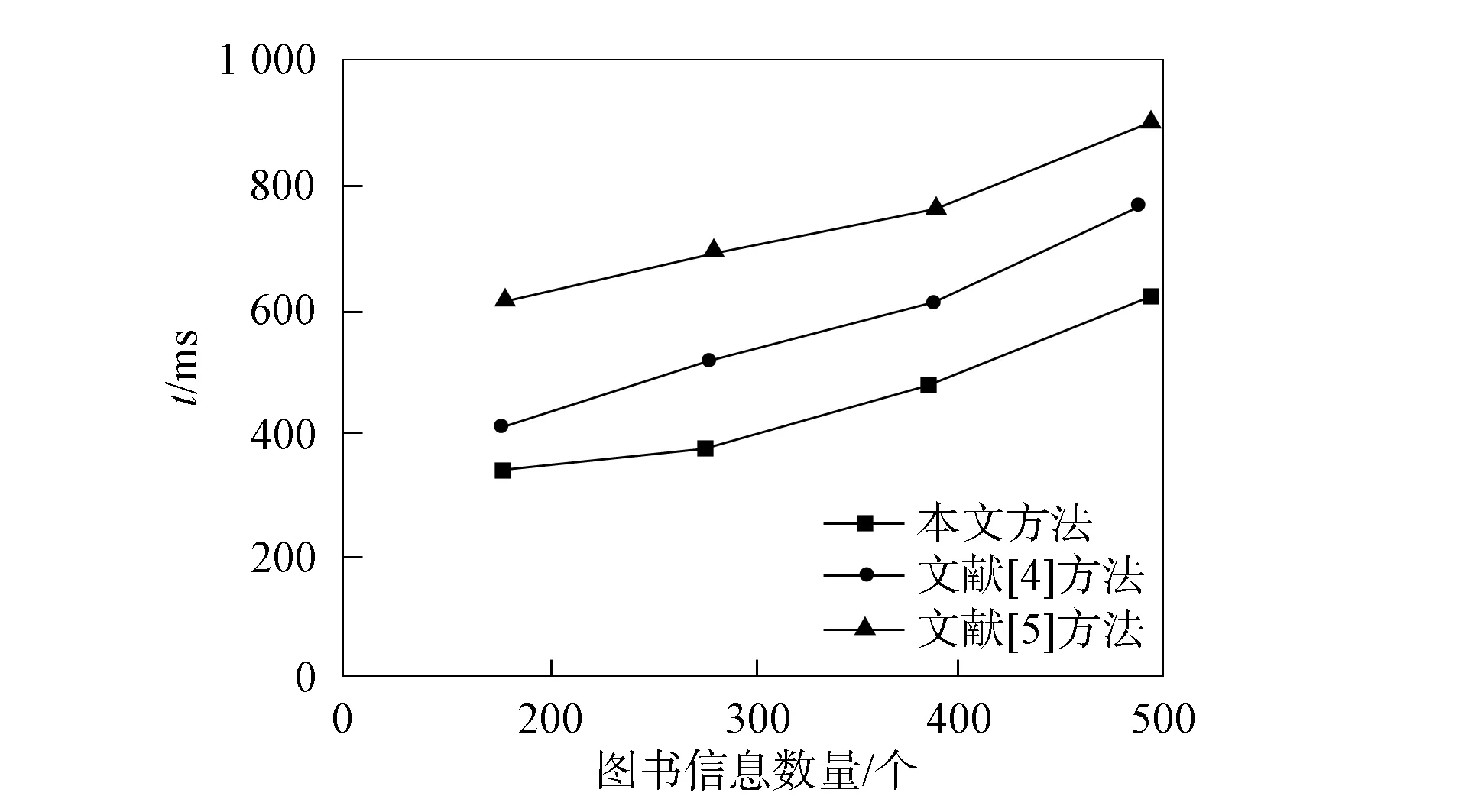
图3 不同图书自整合信息数量对检索效率的影响Fig.3 Influence of self-integrated information quantity of different books on retrieval efficiency
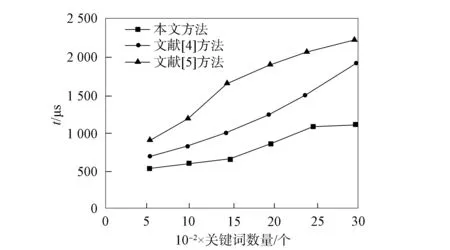
图4 Top-k检索时间Fig.4 Retrieval time of Top-k
综上所述, 针对采用当前检索方法进行图书自整合信息检索时, 难以保证自整合信息检索结果的质量和效率, 存在图书自整合信息检索准确率和效率较低的问题, 本文提出了一种基于Top-k查询算法的图书自整合信息检索方法.仿真实验结果表明, 本文方法不仅能准确检索出图书自整合信息, 且检索效率更高.
