Focal损失在图像情感分析上的应用研究
2020-05-20傅博文唐向宏
傅博文,唐向宏,肖 涛
杭州电子科技大学 通信工程学院,杭州 310018
1 引言
图像情感分析旨在利用计算机和特定算法来预测人看到一幅图像时产生的心理变化[1]。图像情感分析和文本情感分析[2-3]等都属于情感计算领域的重要研究分支,能够从图像情感分析研究中受益的包括社交媒体分析人员、多媒体供应商(例如商业图库)等。分析人员可以利用用户在社交媒体中上传的图像来进行舆论分析或舆论预测等,商业图库则可以根据对图库的情感分析来对图像进行更加细致的分类。进行图像情感分析,首先需要选择适当的心理学模型来表现情感。在心理学研究中有两种典型的表现情感的模型:情感状态类别(Categorical Emotion States,CES)和情感维度空间(Dimensional Emotion Space,DES)[4]。CES方法认为情感属于少数几个基本类别之一,如恐惧、满足、悲伤等,而DES方法认为情感在大脑中是连续的,因此将情感归为多维情感空间中一个点。分类任务中的CES 更容易让用户理解和标记,而在回归任务中DES更灵活,描述更加细腻。此前研究多采用CES方法,将情绪分为在严格的心理学研究中定义的八个类别,包括负面情绪:愤怒、厌恶、恐惧、悲伤,积极情绪:愉悦、敬畏、满足、兴奋。本文将沿用CES 这一模型,将情感分为八个类别,便于和此前的研究进行比较。
以往图像情感分析的研究可以分为基于手工特征的方法和基于深度神经网络的方法。早期图像情感分析使用了多种手工特征,手工特征方法的不足是模型容量较小,而且难以利用大规模数据集的优势。近年来,卷积神经网络(Convolutional Neural Network,CNN)的发展已经证明了自动表示学习(Representation Learning)具有巨大的潜力[5-7],因此,众多学者将深度神经网络应用于图像情感分析研究中,并取得了较好的效果。Chen等[8]直接使用在ImageNet数据集[9]上预训练过的原始AlexNet与AlexNet 叠加支持向量机模型来进行情感图像分类。Rao 等[10]认为图像在多个尺度上影响人的情绪,于是将整幅图像均匀剪裁成4块和16块的子图像,分别用三种不同的卷积神经网络(AlexNet[5]、A-CNN[11]、T-CNN[12])提取高级语义特征、美学特征和纹理特征。将提取到的三种特征,通过平均聚合函数进行聚合,再经过softmax分类器进行分类,提出了一种学习多层次深度表示(MldrNet)的图像情感分类模型。
由于深度学习模型的训练往往需要大量的数据,基于神经网络的图像情感分析研究必须先建立情感图像数据集。目前,虽然人们已经建立了基于互联网图像的大型图像情感数据集,但是这些数据集中经常存在一定的样本不平衡问题(即各类别样本的数量差异较大)。这种样本不平衡现象不仅会使得模型的训练容易出现一定程度的过拟合问题,同时也会因为不同类别数据的分类难易程度不同,导致训练得到的分类模型在不同类别上的表现有较大的性能差异[13-14]。
针对这个样本不平衡的问题,本文利用Focal 损失函数具有挖掘困难样本(即分类损失较大、难以学习的样本,反之则为简单样本)和缓解样本不平衡的特性,将其应用于神经网络的图像情感分析中。通过引入类别权重因子和渐增式聚焦因子,对Focal 损失函数中参数的确定进行改进,并将改进的Focal 损失函数用于图像情感分析模型的训练中。本文将改进的模型在三个数据集(LDDEFC、ArtPhoto、IAPS-subset)上进行了多组实验。实验结果表明,相比于交叉熵损失函数,改进的Focal损失函数能够将两个模型的准确率、宏召回率、宏精准率分别提升 0.5~2.3 个百分点、0.4~3.9 个百分点、0.5~3.3个百分点。使用改进的Focal损失函数的模型,在几个表现较差的类别上的分类能力上也有较好的提升。
2 基于神经网络的情感分析模型
现有的研究工作表明,神经网络提取的图像特征具有一定的通用性,在大型通用图像数据集上训练过的深度神经网络,再经过一定的结构调整和训练,可以很好地迁移到其他问题上[15],因此本文选用了在ImageNet数据集上预训练的AlexNet[5]和ResNet-50[7]模型作为情感分析模型,以验证本文改进算法的有效性。
AlexNet 网络结构如图1 所示。输入为227×227×3像素的三通道图像,输入图像首先进行五层卷积运算。第一个、第二个和第五个卷积层后面进行了最大池化(Max-pooling)运算以降低信息冗余,提升模型的尺度不变性和旋转不变性。此外在第一和第二个卷积层后面还进行了局部响应归一化(Local Response Normalized)运算来增加泛化能力。第五个卷积层输出的特征被降为一维的特征向量,并经过两层全连接网络,最后通过一个softmax分类器输出一个概率分布向量。所有神经网络使用ReLU[5]作为激活函数。
ResNet-50 的网络结构如图2 所示。网络依次由卷积层conv1 以及conv2_x、conv3_x、conv4_x、conv5_x 四个卷积块构成。卷积块conv2_x到conv5_x内部由重复的残差块[7]构成,ResNet通过残差块中的残差连接来避免深度卷积神经网络的退化问题,并且减少模型的训练时间。输入经过五个卷积块以后,再经过一个平均池化运算,最后由softmax分类器输出各类别的概率。
本文采用的两个卷积神经网络均使用ImageNet 数据集的预训练模型,并将网络的输出层维度改为8(即训练集中样本的类别数),然后使用情感图像数据集来训练网络的最后一层。但是这两个模型都未对训练样本中的样本不平衡问题进行处理,因此在模型的训练过程中,还应该采取一定的方法来处理样本不平衡问题。
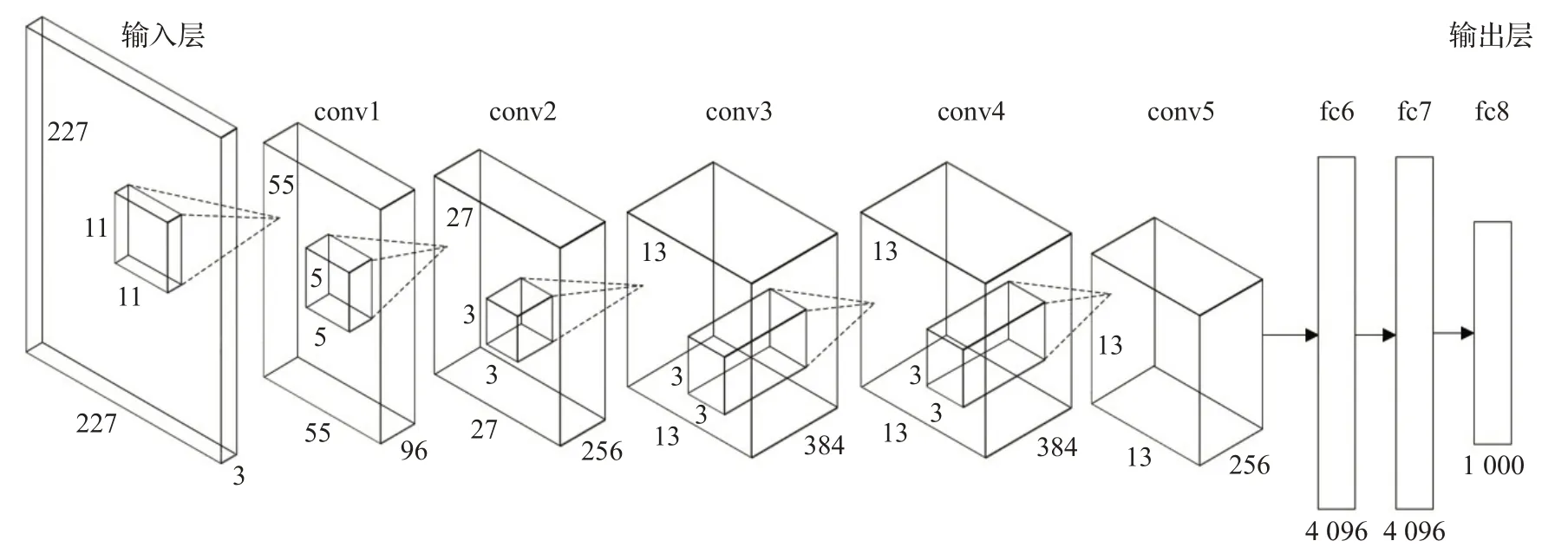
图1 AlexNet网络结构
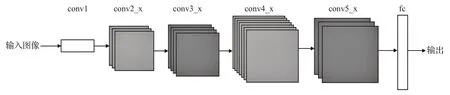
图2 ResNet网络结构
3 样本不平衡问题与Focal损失函数的改进
样本不平衡是机器学习领域中一个重要的问题。将不平衡的样本用于分类模型的训练中,会使得模型的泛化性能较差[16]。图像情感分析研究早期使用手工特征研究所用数据集的规模较小,通常包含的图像数量约为数百张[17-18]。这些数据集对于基于手工特征的方法已经足够,但是随着深度学习方法的兴起,这些小型数据集已经不能够满足模型训练的需要。因此,研究人员开始通过互联网获取图像来建立大规模情感图像数据集,使得基于深度神经网络模型的应用研究得以进一步开展。图像情感分析研究中常用的数据集包括IAPS-subset[18]、ArtPhoto[17]、LSDFEC[14],各数据集的数量如表 1所示。其中,最大的情感图像数据集LSDFEC是You等人[14]在社交网站Flickr 和Instagram 上使用情感关键字抓取图像,并通过人工标注情感类别整理得到的。该数据集有2万多张图片,数据量能够较好地满足深度学习模型训练的需求。但是该数据集中存在着较为明显的样本不平衡问题,其中数量最多的类别与数量最少的类别的数量比约为5∶1。而另外两个小型数据集ArtPhoto与IAPS-subset 也存在着较为明显的样本不平衡问题。因此,对于图像情感分析研究而言,处理样本不平衡问题有着重要的意义。

表1 三个数据集中各类别图片的数量
处理样本不平衡问题的常用方法有:样本加权[19]、数据集重采样[20-21]、样本合成[22]。但是前两种方法仅考虑了类别数量的差异,忽略了样本分类难度的差异,而样本合成方法的适用性比较有限,在图像分类等问题中的应用较为复杂。
Lin 等[23]针对目标检测中的样本不平衡问题,对交叉熵(Cross Entropy)进行了改进,提出了Focal 损失函数。在基于卷积神经网络的情感分析模型中,交叉熵是最为常用的损失函数,其大小为:

其中,p为模型判断输入样本属于真实类别的概率(即样本置信度)。然而,在情感分析模型训练时,传统交叉熵损失函数对训练集当中困难样本的关注度不够,同时也不能较好地处理训练情感图像数据集当中存在的类别样本不平衡问题[14]。这样,交叉熵损失函数在多分类任务时,数据集的类别样本不平衡问题就会使得模型的性能退化。同时,困难样本与简单样本数量的不平衡也会导致大量的简单样本降低模型整体的损失,模型在训练中很难关注到数量较少的困难样本。
为此,Lin等人提出了Focal损失函数:

其中,聚焦参数γ为一个大于0的超参数。通过实验来得到最优值,其作用是通过(1-p)γ项来放大低置信度样本的损失在总损失中的权重,缩小高置信度样本的损失在总损失中的权重。这是因为对于置信度高的样本,即p越大的样本,调制因子(1-p)γ越小;反之,置信度低的样本,即p越小的样本,调制因子(1-p)γ越大。这样,在训练中,困难样本的损失被放大,模型会更加关注困难样本。平衡参数α同样是一个超参数,由网格搜索(Grid Search)方法得到最优值,其作用是控制正负样本对总损失的权重,平衡不同类别样本的数量。
虽然Focal损失函数较好地解决了二分类问题中困难样本挖掘和正负样本数量不均衡问题,但是将它应用于图像情感多类别分类模型时,若仍采用通过网格搜索的方法得到平衡参数α,这样随着类别数量的增加,平衡参数α的调优工作量会大大增加(例如对于二分类,实验10个α值需要102次训练;对于八分类则需要108次训练)。此外,固定的聚焦参数γ对于分类难度不同的样本损失在训练过程中的缩放程度不变,不利于模型精度的进一步提升。因此,本文将对Focal 损失函数中聚焦参数γ和平衡参数α的确定方法进行改进,将平衡参数α与数据集当中各类别的数据量相关联,将聚焦参数γ与模型训练的过程相关联。具体对Focal损失函数中的聚焦参数γ和平衡参数α的确定如下。
(1)平衡参数α的确定。在多类别分类问题中,如果参数α进行网格搜索优化,会使得训练的工作量呈指数级增长,因此本文不再用优化的方法确定参数α的数值,而采用启发式的方法,直接根据训练集中各类别数量来确定参数α的数值,即根据各类别样本的数量来重缩放(Rescale)分类损失大小[19]。为了平衡各类别样本的数量,本文希望所有类别的样本在训练中对于分类器同等重要,即希望加大少数样本损失的权重,同时减少多数样本损失的权重[23]。具体而言,权重设定的目标要使得任意两个类别的权重之比等于这两个类别样本数量的反比。若设数据集中类别总数为N,则第i类(i∈[1,N])的平衡参数αi等于类别权重值的大小,即:

其中,mi为第i类的样本数量。从式(3)可以看出,平衡参数αi在训练中能较好地按照数据集中各类别样本的数量比例放大或者减小损失值。
表2 给出了表1 中数据集各类别对应的类别权重值。由表2 可见,如果某个类别的数据量越大,也就是在训练时出现的频率越高,对应的类别权重值就越小,即单个样本在总损失的比重越小;反之则对应的类别权重值就越大,也就是单个样本在总损失的比重越大。
(2)对于聚焦参数γ的确定。通过研究发现,在训练早期,Focal 损失函数会使模型的训练精度低于使用交叉熵损失函数时的精度。图3 给出了一组交叉熵损失(CE)与α=1,γ分别取2、4 时Focal 损失(FL)的数值曲线。从图中可以看出,随着样本的置信度的增加,交叉熵损失值减小相对较缓,而Focal 的损失值的减小则相对较快。当样本的置信度为0.1 时,交叉熵损失值为2.3,而Focal 损失值分别为1.8、1.5;当样本的置信度为0.9 时,交叉熵损失值为0.1,Focal 损失值则分别为1×10-3、1×10-5。在训练早期,大部分样本的置信度都不高(远小于1)。当样本的置信度较低时,交叉熵损失要小于Focal 损失值。因为Focal 损失函数中的(1-p)γ项反而会使训练整体的损失降低,从而降低了模型学习的速度;而在训练的后期,大部分样本的置信度都得到了提升,此时由于γ值不变,(1-p)γ项对高置信度样本损失值的抑制和对低置信度样本的放大程度也不变,不利于训练的进一步进行。此时如果能增大γ值,就可以进一步放大低置信度样本的损失。
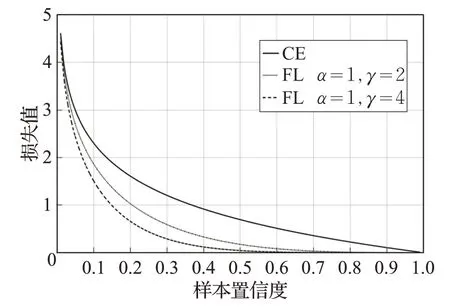
图3 交叉熵损失与不同γ 值时Focal损失的对比
因此,本文在训练中,采用每N轮训练后调整一次γ值,即:
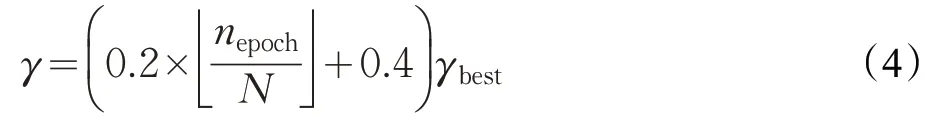
其中,nepoch为训练的轮数;为向下取整运算;γbest为γ的最优值。这样,用一种渐增方式来确定γ的值,在训练早期先使用一个较小的γ值,在训练中后期逐渐增大γ的值,进一步放大低置信度样本的损失在总损失中的权重,缩小高置信度样本的损失在总损失中的权重,使得模型在训练的中后期更加聚焦于困难样本的训练,从而提升分类模型的精度。
4 实验结果与分析
为验证本文改进的Focal 损失函数的性能,在计算机上进行了仿真实验。实验中使用了Keras深度学习框架,CPU 为英特尔酷睿i7-7700HQ,内存大小为16 GB,GPU为英伟达GTX 1070显卡,显存大小8 GB。
神经网络模型首先使用大规模情感图像数据集LSDFEC来进行训练。使用该数据集训练模型时,均将数据集随机划分为:训练集(数据总数的80%)、测试集(数据总数的15%)、验证集(数据总数的5%)。图像在输入网络前进行去均值化处理[6]。训练使用mini-batch梯度下降法,学习率为0.001,batch大小为64,momentum值[24]设置为0.9。
为了验证Focal损失函数以及相关参数设置的改进效果,本文在实验中对比了普通交叉熵函数、Focal损失函数参数α、γ采用不同方法取值时在两个神经网络上的训练效果。详细对比实验模型设置如下:
模型1 AlexNet+交叉熵损失函数(由式(1)定义)
模型2 AlexNet+Focal 损失函数(固定γ值,设置α=1)
模型3 AlexNet+改进的Focal损失函数(固定γ值,α值由式(3)定义)
模型4 AlexNet+改进的Focal损失函数(γ值由式(4)定义,α值由式(3)定义)
模型5 ResNet+交叉熵损失函数(由式(1)定义)
模型6 ResNet+Focal损失函数(固定γ值,设置α=1)
模型7 ResNet+改进的Focal 损失函数(固定γ值,α值由式(3)定义)
模型8 ResNet+改进的Focal损失函数(γ值由式(4)定义,α值由式(3)定义)
除了在大规模数据集上进行实验以外,还使用了ArtPhoto 和IAPS-subset 两个小型数据集来进行实验。由于ArtPhoto 和IAPS-subset 这两个小数据集的数据量都很小,本文首先用大型数据集LSDFEC 来训练模型,然后再将训练模型在小型数据集上微调(Finetune)最后一层。

表2 三个数据集中各类别的类别权重值
为了进行客观分析比较,实验中采用了准确率(Accuracy)、宏召回率(Macro Recall,MR)和宏精准率(Macro-Precision,MP)三个性能评价指标[25],并且给出了各个实验模型的混淆矩阵结果[14]。
本文首先利用AlexNet、ResNet 两个卷积神经模型来确定γ在这两个卷积神经模型上的最优值γbest,其结果如表3 所示。从表3 的实验结果中可以看出,参数γ在 AlexNet、ResNet 模型上的最优值分别是 1.8 和 1.6。然后,在对比实验模型2、模型5 的训练时,分别用对应最优值γbest作为γ的固定值;在对模型3 和模型6 的训练过程中,则采用式(4)的渐增方式确定γ值。表4 给出了N取不同值时AlexNet 与ResNet 两模型的实验仿真结果(每10 轮训练改变一次γ值)。从表中可以看出,虽然N取不同值时,各模型的准确率很接近,但两模型均在N=10 时取得了略好的准确率,因此在实验仿真中取N=10。
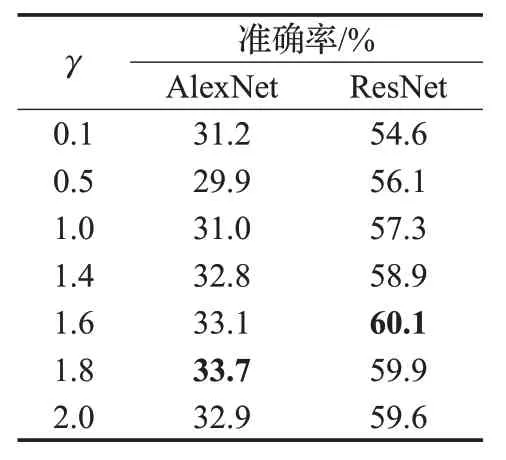
表3 不同γ 值在两个模型上的准确率结果
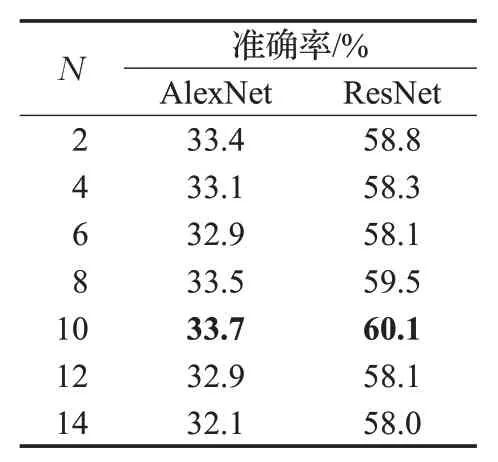
表4 N 取不同值在两个模型上的准确率结果
表5 分别给出了各模型在各个数据集上训练得到的准确率、宏召回率和宏精准率结果。图4分别给出了各模型在LSDFEC数据集上的混淆矩阵结果。

图4 各实验模型在LSDFEC数据集上的混淆矩阵结果
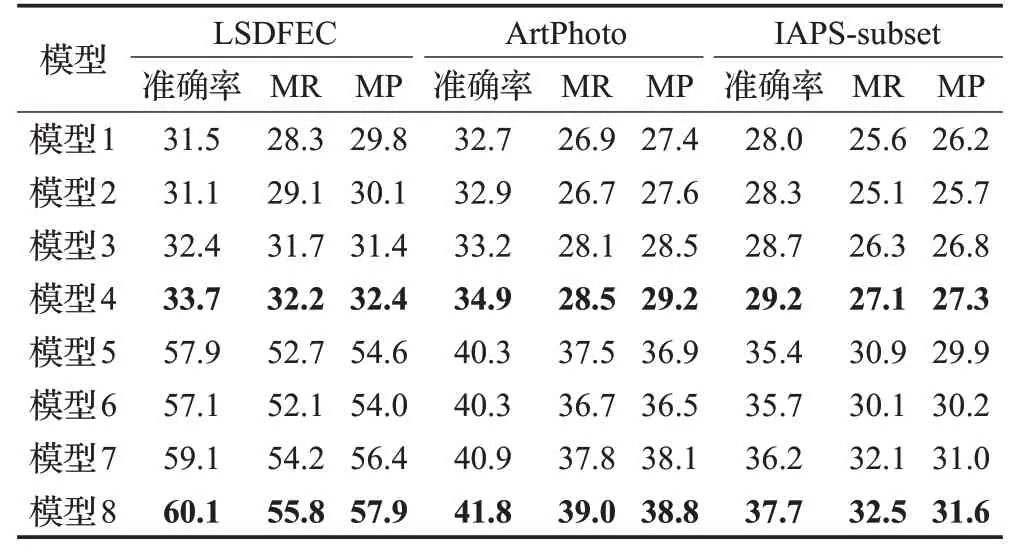
表5 各模型在各个数据集上准确率、宏召回率和宏精准率结果%
首先,对比模型4 与模型1、模型8 与模型5 可以发现,相比于交叉熵损失函数,将Focal损失函数应用于神经网络模型的图像情感分析时,神经网络模型的分析性能整体上都得到提升,且ResNet 模型的性能要优于AlexNet。其中AlexNet模型的准确率、宏召回率与宏精准率分别提升了 1.2~2.2 个百分点、1.5~3.9 个百分点、1.1~2.6个百分点;ResNet模型的准确率、宏召回率与宏精准率分别提升了1.5~2.3个百分点、1.5~3.1个百分点、1.7~3.3个百分点。
其二,对比图4中模型2与模型3、模型6与模型7的混淆矩阵可以看出,采用本文方法设置α的值,相比于设置α=1(即无平衡参数的影响),能够有效地提升模型在几个样本数量较少的类别(例如愤怒、恶心、恐惧)上的分类能力,从而使得模型在各个类别上的表现相对更加均衡。其中AlexNet 模型的准确率、宏召回率与宏精准率分别提升了0.3~1.3个百分点、1.2~1.6个百分点、0.9~1.3个百分点;ResNet模型的准确率、宏召回率与宏精准率分别提升了0.5~2.0个百分点、1.0~2.1个百分点、0.8~2.4个百分点。
其三,对比模型3 与模型4、模型7 与模型8 可以看出,相较于固定γ值,采用渐增式调整γ值时,神经网络模型的图像情感分析性能得到提升。其中AlexNet模型的准确率、宏召回率与宏精准率分别提升了0.5~1.7 个百分点、0.4~0.8 个百分点、0.5~1.0 个百分点;ResNet 模型的准确率、宏召回率与宏精准率分别提升了0.9~1.5个百分点、0.4~1.6个百分点、0.6~1.5个百分点。
5 结束语
针对交叉熵损失函数对困难样本关注度低,以及难以处理训练图像数据集中样本不平衡问题,本文将Focal损失函数应用到图像情感分析中。在模型的训练中,利用类别权重因子来确定平衡参数大小,采用渐增变化方式调节聚焦因子大小,对Focal 损失函数参数的确定方式进行改进,以提升情感分析模型的训练效率和性能。仿真实验结果表明,改进的Focal 损失函数能够有效地提高模型的准确率、宏召回率和宏精准率,并且使得模型在各个类别上的分类能力更加均衡,较好地缓解数据不平衡问题的负面影响。这些性能指标的提升对于图像情感分析的应用,例如基于情感的图像检索和基于图像情感的社交媒体舆论分析等,都是具有重要价值的。
