基于共现关系的多源主题融合模型
2020-05-20杨文忠王雪颖马国祥王庆鹏
秦 旭,杨文忠,王雪颖,马国祥,王庆鹏
1.新疆大学 软件学院,乌鲁木齐 830046
2.新疆大学 信息科学与工程学院,乌鲁木齐 830046
3.新疆电力有限公司 信息通信公司 信息调控中心,乌鲁木齐 830046
1 引言
随着互联网的快速发展,人们对网络的依赖也越来越强,更多的人愿意在网络上发表自己的观点和看法。与传统的媒体相比较,互联网新媒体有着卓越的优势,它的交互性、及时性都更加体现着新闻的价值。如今,很多热点的社会事件都是在互联网上被引爆。人们越来越习惯于用手机来接收新消息,也更喜欢用手机来浏览新闻并在上面发表自己的见解,简短的文字、有效的表达成为了一种时尚,这使得微博、知乎、今日头条、百度贴吧等成为主要的新闻传播途径,不仅仅是中国,Twitter 等国外网站也出现了这样的情况。因而改变人们接收信息的方式,有效、准确地发现大家都在关注的主题,成为了研究热点。在众多文本处理算法中,主题发现的方法分为两类:一类是基于统计概率的主题发现方法;另一类是基于机器学习的主题发现方法。
基于统计概率的主题发现方法的代表为LDA(Latent Dirichlet Allocation)算法,它通过应用贝叶斯概率模型将文本信息转化为概率分布。LDA算法现在被广泛应用在图像分析[1]、书籍分类、文本处理[2]、生物基因分类[3]、人脸识别[4]等场景中。因为LDA 算法可以将连续的数据概率化,同时将数据假设为没有顺序的关系,这样大大简化了计算的复杂程度,使得它在众多方面得到了广泛的应用,但是也留下了改进的空间。众多的改进算法都取得了不错的效果。文献[5]对LDA 进行了改进,将数据加入了时间性,使词的出现顺序变得重要,在话题发现领域取得不错的效果;文献[6-9]也对LDA 进行了不同程度的改进。另一方面,使用基于频繁项集的主题发现也得到了大家的认可,它们通过生成频繁项集发现其中的关联来定义文本的主题。优点是利用Apriori原理加快了速度,因为关联挖掘的数据集往往是重复性很高的,这就能带来很高的压缩比,节省了大量的存储空间;而缺点是效率比较低,实现比较困难,对于数据要求较高的某些应用中性能下降。
另一种就是基于机器学习的主题发现,基于RNN(Recurrent Neural Network)和主题模型的社交网络突发话题发现[10],通过神经网络[11]的高度抽象性发现大量数据中隐藏的关系,取得了一些成果。近些年来,对混合算法的研究逐渐增多,尤其是在聚类方面,很多数据来源不再是单一类型,文献[12]专门针对不同种类的混合数据提出了混合算法,文献[13-15]提出了更加高效的混合聚类算法。不同的数据有着其自身的特性[16],不可能适应每一种数据,将不同来源的数据进行分析,准确发现主题有着重要意义。为了解决上述问题,本文提出了一种基于共现的异类源话题发现方法,它可以适应于多种来源的文档[17-18],能够有效地发现主题,有效利用每种文档来源的特性。该方法具有适应多种文本进行主题发现,对于文本类型和主题要求较低的优点,但由于使用了多重算法进行处理,数据运算效率有一定的下降。
2 相关研究
近些年来,主题检测逐渐受到国内外科研工作者的广泛关注。长文本主题检测已经取得了较好的效果,但在短文本[19]上的检测结果始终差强人意。本文采用长文本主题检测后的结果对短文本聚类[20]结果进行补充来获得更准确更贴切的主题。对于长文本和短文本分别采用LDA 和K-means 算法进行聚类融合,并对其进行了一些改进。
2.1 LDA模型
在LDA 的具体计算中,认为一篇文章生成的模式如下:从迪利克雷分布α中取样形成文档i的主题分布θi;从主题的多项式分布θi中抽出生成文档i第j个词的主题zi,j;从迪利克雷分布β中抽出词语形成主题zi,j对应的词语分布φi,j;从词语的多项式分布φi,j最终生成词语wi,j。
对于一篇文章来说,它的形成过程是每次写一个词的时候,首先会以一定的几率选择一个方向。不同方向被选中的概率是不一样的,在这个理论中,假设文章和主题之间存在一定的关系,它符合多项式分布。同理,主题和词之间也被认为存在多项式分布。所谓分布(概率),就是不同情况出现的几率,它们能被总结成为一个特定的规律。
对应贝叶斯参数估计的过程:先验分布+数据的知识=后验分布。根据式子可以知道它们对应观测到的样本数据。
举一个例子:假设对于词库来说总共有词的数量是N,假设人们关注的每个词出现vi的发生次数ni,那么,可以发现它正好是一个多项式分布:

对应到LDA 模型中,文章和主题分布的关系就变成了分布统计是每个主题的词的数量。主题和词对应的是主题中每个词的数量。
2.2 K-means模型
K-means算法[21]是较为经典的聚类算法,它采用相对于中心点的距离作为指标,通过不断地迭代将数据分为输入K个类,算法认为的类中心点是本类中所有值的平均值,每个类用聚类中心点的特征来进行描述。对于给定的一个包含n个d维数据点的数据集X以及要分得的类别K,选取欧式距离作为相似度指标[22],聚类目标是使得各类的聚类平方和最小,即最小化:

结合最小二乘法和拉格朗日原理,聚类中心为对应类中每个类中数据的均值,在计算中保证算法能够收敛,应该尽量使类的中心保持不变[23]。
K-means是一个反复迭代的过程,算法分为4个步骤:
(1)选择样本中的K个对象将它们认为中心;
(2)对于样本中的实际计算对象来说,依据它们与这些选定中心的欧氏距离,按近距离优先的原则,将它们与离它们最近的中心划分到一起;
(3)更新聚类中心,计算每个类别中对象到中心的距离获取平均值重新获得中心,并按照优化函数判断是否聚类结束;
(4)对上一次计算的结果与本次进行对比,如果没有发生变化,则输出结果,若出现变化,判断是否需要重新计算,若需要,则返回(2)。
3 基于共现关系的多源主题融合模型
下面对本文的核心内容进行叙述。将不同来源的数据进行主题发现,利用不同文本源的特点,对其进行分析。
3.1 主要参数及定义
将同时出现在同一个主题中的词定义为共有词,通过共有词可以比较两个主题的相识程度,通过比较可以发现,在主题中的共有词达到一定比例后,就可以认为两个主题为同一类主题的不同情况。
相对相似度:将通过不同源得出的主题词进行比较,得出不同源之间相互关系。将不同源主题之间进行相互比较,得出相对相似度。
相对相似度公式:

其中,S1是对应的主题的相对相似度值;a1为主题相同词数;L1为词条长度。
Similarity calculation描述:
LDA_Theme_length=getKmeans_keyword.length;
Kmeans_Theme_length=getKmeans_keyword.length;
if LDA_Theme_length>=Kmeans_Theme_length for word in Kmeans_Theme:
if(word in LDA_Theme)
sumNum=sumNum+1;
else
for word in LDA_Theme:
if(word in Kmeans_Theme)
sumNum=sumNum+1;
return sumNum/total
end
通过同义词和相对相似度,对不同的主题进行计算。对于计算结果设定阈值,当大于该阈值时,认为这两个主题为相似主题,预备进行融合。在后续的比较过程中发现更相近的则进行替换,否则在算法结束时进行融合。

其中,PS为两个主题间的平均相似度,a1为LDA主题相同词数,a2为K-means 主题相同词数;L1+L2为对应主题词条长度之和。
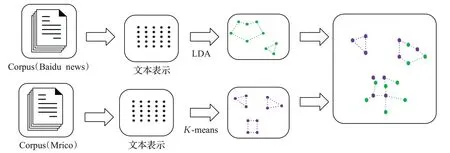
图1 处理总流程图
3.2 基于共现关系的多源主题融合模型
将不同的数据源根据数据具体特性采用相应的算法进行处理,对于长文本类型数据源,采用LDA算法进行处理,对于短文本类型数据,采用K-means算法进行处理。多源主题融合模型的总流程图如图1所示。
首先,将数据根据文本进行分词,采用jieba 分词,去停用词方法;对长文本使用LDA 计算出主题概率矩阵,同时将短文本类型的词使用K-means进行处理,在K取值方面采用Calinski-Harabasz准则。

其中,SSB是类方差,z为所有点的中心,mi为某类的中心点;SSW是类内方差,是复杂度;VRC比率越大,数据分离度越大。VRC 其本质是方差分析,将类间方差与类内方差比较,若两者之比近似1,说明来自同一个正态总体,若远远大于1,说明类间方差远大于类内方差,两者不来自同一个整体。
本文给出一个LDA算法处理过后文本主题的数量N,使用N作为中心点进行K的取值;分别尝试对N与N+1 两个数值进行计算,然后得出ΔVRC值,确认K值,完成K-means 算法分类。对分类完毕的数据采用式(4)进行计算。
算法流程:
(1)将不同源的数据依据数据特性使用对应的方法进行主题发现;
(2)对发现的主题词进行整理;
(3)对主题词进行比较,发现共有主题词;
(4)计算相对相似度和平均相似度。
对相似度进行比较、融合。该算法具体过程如图2所示。
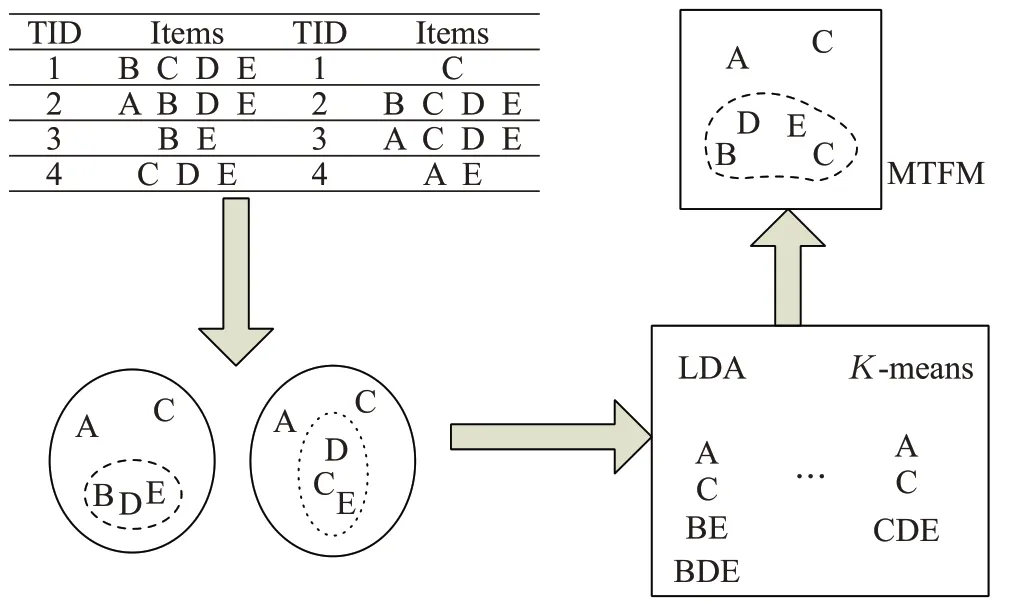
图2 融合演示图
该算法伪代码如下。
Fusion algorithm描述:
getLda_keyword=key_lda(input_source)
getKmeans_keyword=key_kmeans(input_source)
if theme in getLda:
if word in theme:
for compareSame(word,key_kmeans_word)
if similarity>=60%
convergence_theme(getLda_keyword,getKmeans_keyword)
end
4 实验结果及对比
本实验的硬件平台采用Intel i5 1.8 GHz,8 GB 内存,在Windows 环境下采用56Python 语言编写实验代码。编写Python 程序爬取百度新闻与新浪微博组成的数据集。经实验证明,具有更多分类标准能够提高聚类效果。
4.1 数据收集
本文数据收集主要采用Python爬虫,对网络上的信息进行收集处理,针对指定区域进行采集,从2018年11月18—20日,采集了新浪微博数据和百度新闻这两个平台的娱乐数据。将采集完毕的数据首先进行处理,将无用信息,例如、等进行清理。对数据直接采用CVS 格式保存,新浪微博记录信息具体格式:_id,text,comments,id,name,time,attitudes,reposts;百度新闻采用txt格式存储,将每篇新闻按照时间顺序进行存储;总共采集的数据集分为4 个,每个数据集的数据量如表1所示。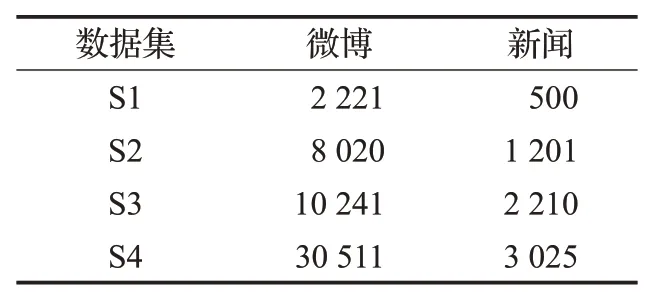
表1 数据集表
收集了更加复杂的贴吧信息,贴吧数据集的数据量如表2所示。

表2 贴吧数据集表
4.2 实验验证
(1)分别在每个数据集对MTFM与LDA、K-means的主题词平均长度进行比较(见图3)。

图3 平均词条长度图
对于传统的判断两个文档相似的方法TF-IDF,主要就是查看两个文档共同出现的单词的数量,这种方法没有考虑到前后语义的关联。文档-词语的概念就是文档主题与词语之间产生联系,更加精确,更多的主题词能更好地反映主题。
本文通过改进LDA 和K-meams 算法获得MTFM算法。通过共有词对主题词进行融合,可以发现,对于不同的数据集来说(S1~S4数据量逐渐增大),在数据量增大时,由于LDA算法通过概率发现主题,数据量的增加能明显增加LDA主题词的长度;对于K-means来说,更多的词有更多的词条长度,但是本文算法明显有更长的主题词条长度。
(2)与LDA、K-means进行主题发现的准确度比较。
困惑度是用来衡量语言概率模型优劣的一种方法。一个语言概率模型可以看成是在整个句子或者文段上的概率分布。通常用于评价聚类算法好坏的方法有两种:其一是使用带分类标签的测试数据集,然后使用一些算法,比如Normalized Mutual Information 和Variation of Information distance,来判断聚类结果与真实结果的差距;其二是使用无分类标签的测试数据集,用训练出来的模型来测试数据集,然后计算在测试数据集上所有token 似然值几何平均数的倒数,也就是perplexity指标。这个指标可以直观理解为用于生成测试数据集的词表大小的期望值,而这个词表中所有词汇符合平均分布。
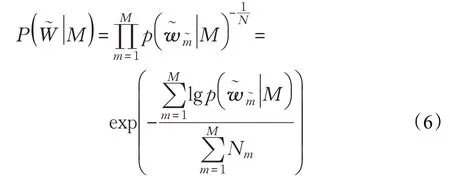
式(6)中,M 是指训练好的模型参数,在不同的模型中指不同的参数类型。例如在LDA 中将collapsed Gibbs Sampler 采样的w 向量和z 向量带入计算可以得出困惑度。困惑度的基本思想是给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完成后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好;根据困惑度公式可知,困惑度越小,句子概率越大,语言模型越好。本文模型与LDA、K-means在困惑度上的实验对比结果如图4所示。
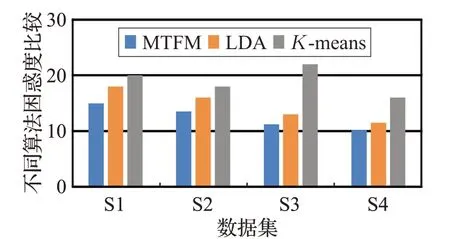
图4 困惑度比较图
对于主题准确率,从图中可以发现在数据量较少时,三种算法都不能有效地发现主题,在文本规模达到一定数量时,发现LDA 发现主题的困惑度有明显的提高;但是在数量增长到一定规模后,特别是混合后的文本,困惑度明显上升,而MTFM算法却能获得不错的效果。
(3)在不同数据集进行综合对比。
采用平均词条长度、主题数量、样本数、困惑度和时间跨度对同一数据集进行综合考虑,比较算法的差异。综合对比后结果如图5所示。

图5 MTFM与LDA、K-means综合比较图
通过图5 比较可以看出,在相同的样本数量、相同的时间跨度之下,本文方法具有较低的困惑度,聚集出较多的主题数量;同时随着样本数量的不断增多,从文本数量较大的样本分析看,相同的时间跨度之下,本文方法能获得更低的困惑度,具有研究效果。
(4)在帧吧数据集上,将本文提出的算法与K-modes 算法进行了困惑度和评价词条长度两项的对比实验,结果如图6所示。

图6 贴吧数据集上MTFM与K-modes比较图
实验如图6 所示,在更加复杂的数据集中,本文提出的方法在困惑度上依然有优秀的表现,在平均词条长度上也能取得不错的效果。
5 结束语
本文通过对不同源的数据采用本文算法进行处理,对不同源的数据特性进行充分利用,将更加丰富的主题词添加进主题中,能够更加准确地定义主题。通过实验证明,本文方法能够在不同源的数据上取得一定的效果,能获得更好的主题分类。在后面的研究中,将考虑词语倾向性分析,使扩展的主题更加准确有效。未来会考虑将多源主题发现应用于舆情监控系统,及时对舆论进行引导。
