MLLR和MAP在远场噪声混响下的语音识别研究
2020-05-20娄英丹徐静林黄丽霞张雪英
娄英丹,徐静林,黄丽霞,张雪英
太原理工大学 信息与计算机学院,太原 030024
1 引言
远场语音识别是目前研究的热门方向,它可以很方便地实现人机交互,而不需用人戴麦克风[1],其在智能家居、办公环境、人形机器人、汽车和语音翻译等研究领域都有广泛应用[2]。然而,墙壁、地板、天花板及其他物体的反射和干扰噪声源都会很大程度地降低远场语音信号的质量,致使语音识别的性能急剧下降。目前国内外主要从信号域、特征域、模型域几个层次来提高远场语音识别的鲁棒性。Mirsamadi 等人[3]提出使用分布式麦克风的鲁棒的多声道频谱增强方法,该方法使用非负张量因子分解(Nonnegative Tensor Factorization,NTF)技术从一组不同通道的混响声谱图中识别出干净的语音分量。胡玥[4]将宽带频域不变波束形成器和一种改进的相干梳状滤波器结合起来增强远距离语音信号。Uluskan 等人[5]提出基于音素类的特征适应(Phoneme-Class Based Feature Adaptation,PCBFA),使远距离语音的音素类的分布近似于多维MFCC(Mel Frequency Cepstrum Coefficient)空间中的近距离声学模型,从而提高了语音识别性能。张宇等人[6]提出基于注意力机制和多任务学习框架的长短时记忆(Long Short-Term Memory,LSTM)递归神经网络声学模型,显著提升了模型对远场语音的建模能力。
以上提到的三个层次的方法都有其弊端,如:基于麦克风阵列的噪声抑制、盲源分离和波束形成的语音增强方法所用的麦克风阵列体积很大,设备成本较高;特征规整方法处理效果不如信号域理想,且过于复杂的处理算法影响系统的实时性;训练带有混响的语音数据得到的模型能比较精确地描述混响环境的特征,但所需数据量大,且在其他实验中不适用,造成资源的大量浪费;非线性模型参数补偿方法以及基于混响模型的补偿方法,这几种模型域的补偿方法原理和具体实施方式各不相同,且各自的应用场合与方法复杂度也各不相同[7]。
声学模型自适应技术是从非特定人(Speaker Independent,SI)模型开始,通过调整模型参数来适应当前语音特征,从而以少量的数据获得类似于特定人(Speaker Dependent,SD)模型的更好的识别性能,很好地解决了在有些情况下得不到大量语音数据的问题,例如自动电话热线。声学模型自适应技术应用在很多语音领域,如口令识别[8]、跨性别语音识别[9]、维吾尔语语音识别[10]及不同发声力度语音识别[11]。最大似然线性回归(Maximum Likelihood Linear Regression,MLLR)和最大后验概率(Maximum A Posteriori,MAP)是两种经典的声学模型自适应技术。Kumatani 等人[1]将MLLR 用在远场语音中,尚未涉及到MAP。本文将两种经典的声学模型自适应技术MLLR、MAP用在远场环境下,比较它们对带噪带混响的远场语音识别的性能。

图1 具有自适应技术的远场连续语音识别系统
2 具有MLLR/MAP自适应技术的语音识别系统
典型的连续语音识别系统框架通常由预处理和特征提取模块、声学模型模块、语言模型模块、语音解码和搜索算法模块几部分组成,本文所研究的远场连续语音识别系统框架如图1[12]。
首先,对连续纯净语音进行加噪加混响处理,再将噪声混响语音的一部分数据用来进行声学模型自适应,另一部分用来测试,即所做实验为开集实验。用来进行自适应的语音经过MLLR 或MAP 自适应后,生成适合当前环境的新的HMM 声学模型。测试用的语音经过预处理、MFCC特征提取、语音解码和Viterbi搜索算法,再结合自适应后的HMM 声学模型、N-gram 语言模型和字典,就可以得到语音识别结果。
3 MLLR和MAP的自适应技术
3.1 MLLR自适应技术
MLLR是一种模型自适应技术,它可以从少量的适应数据中收集统计数据,用于计算线性回归变换的平均向量,以最接近自适应数据,并且可以使用前向-后向算法来估计变换矩阵。该方法的一个重要特征是可以使用任意适应数据而不需要特殊的句子。利用这种转换和数据共享,MLLR可以用少量的适应数据改进语音识别性能[13]。
MLLR的自适应流程图如图2所示。其中语音特征向量空间划分中,如果仅有少量适应数据,则全局变换用于系统中的所有模型,如果有更多数据可用,则变换的数量增加,此时将会根据声学模型的不同高斯分布分量的均值来进行聚类[10]。这样就保证了即使没有可用的模型特定数据,也可以调整所有模型状态。用于估计变换参数的统计量是使用自适应数据的前向-后向对齐生成的。

图2 MLLR流程图
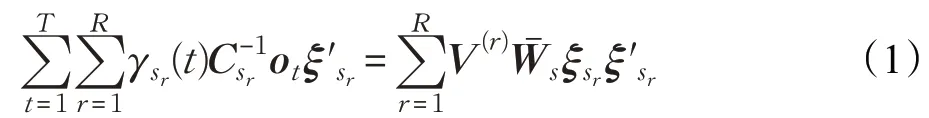
其中,R为状态数,γsr(t)表示在时间t处占用状态sr的概率,为状态sr输出高斯概率分布函数的协方差矩阵,ot为第t帧语音的特征矢量,为扩展均值向量,ω为偏移量,ω=1 表示回归中包含偏
变换矩阵可以通过下式来获得:移量,ω=0 表示忽略偏移量,Ws是n×(n+1)维的扩展变换矩阵。
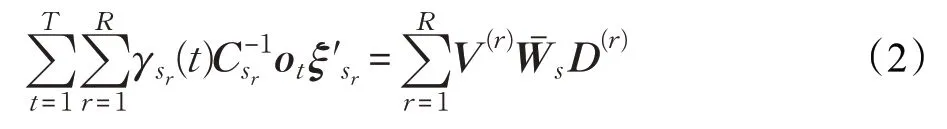
如果式(2)的右侧由元素为yij的n×(n+1)矩阵Y表示,则V(r)、Ws和D(r)的各个矩阵元素分别为和,则:

完全协方差对于捆绑矩阵中的估计公式没有封闭形式,因此仅考虑对角协方差分布的情况,又由于D是对称的,则:
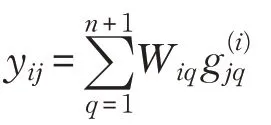

如果式(2)的左侧由元素为zij的n×(n+1)矩阵Z表示,则Z=Y并且
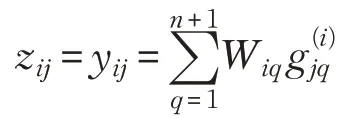
应当注意,zij和不依赖于,并且两者都可以从观察矢量和模型参数计算。因此,可以联立如下方程组计算:

其中,wi和zi分别是Ws和Z的第i行。可以使用高斯消元法或LU分解法来解这些方程。由式(3)可得到。
估计出变换矩阵Ws后,再对声学模型的参数进行变换。
3.2 MAP自适应技术
自适应技术是减小语音识别系统与测试环境之间差异的一组有效方法[14]。
MAP 自适应方法基于贝叶斯决策理论,它将新的语音数据与原有模型相结合,获得新的模型参数。给定观测数据ο,MAP 方法将模型参数看作是一个随机变量,引入模型参数的先验分布,利用最大后验概率准则对模型参数进行重估,即MAP 基于后验概率最大化准则。MAP的目标函数为:

对应的模型参数为:

式中,P(λ)是模型参数的先验分布,一般通过已有的SI模型的参数估计,此先验项在参数估计过程中起约束作用,将自适应数据较少的声学模型的参数限制在SI模型参数附近,从而保证自适应后的模型参数不会产生较大偏差。通过对MAP 的目标函数进行推导,得到均值的更新公式为:

式中,μk与分别表示第k个高斯自适应前后的均值向量,μk是从P(λ)中得到的先验均值,τk是控制先验权重的系数,γt(j,k)是t时刻的观察矢量ot由状态j中的第k个混合分量产生的概率,t表示自适应语音的帧数,N表示状态数。从式(6)可以看出,MAP估计结果实际上是SI模型参数与SD模型参数的加权平均,加权系数随着自适应数据的变化而变化。当自适应数据较少时,SI模型参数所占比重大,估计结果接近于SI模型参数;当自适应数据增多时,SD 模型参数所占比重增大,估计结果向SD 模型参数靠近,从而使系统性能提高。理论上当自适应数据趋于无穷时,MAP 估计得到的模型与用充分语料采用最大似然估计得到的模型相等价,因此MAP算法具有理论上的渐进性,即适应数据越多,MAP得到的声学模型越好。
4 实验结果与分析
4.1 自适应实验
4.1.1 MLLR、MAP仿真实验
本文所用语音为CMU ARCTIC 语料库中bdl 组语音,它是男性标准口音连续英语语音,识别引擎为CMU轻量级语音识别器pocketsphinx,其中采样频率为16 kHz,声学特征包括13 维的MFCC 以及它们的一阶二阶差分,预加重系数设置为0.97,采用汉明窗进行分帧,帧长为25 ms,帧移为10 ms,测试语料是与自适应语句不同的25 句语音。本实验用IMAGE 模型生成房间脉冲响应,来模拟远场噪声混响环境,声源到单麦克风距离设置为2.29 m[15-16],混响环境设置为墙壁6个面的反射系数都为0.6,不同噪声环境下语音识别词错率(Word Error Rate,WER)结果如表1~表3所示。
当SNR为15 dB时,经过不同方法进行声学模型自适应后,远场语音识别的WER 如表1 所示。由表中数据可得,在所有的自适应句数中,MAP 自适应算法的WER都是最小的,且其所有WER都小于自适应句数为0(未自适应)时的情况;MLLR 自适应算法的WER 在各种自适应句数下都是最大的,主要原因可能是语音数据在划分特征空间时比较粗糙。说明在各个墙壁反射系数为 0.6,SNR 为 15 dB 这种远场条件下,MLLR 自适应方法不适用,而MAP 自适应方法得到了最好的声学模型和最好的语音识别性能。
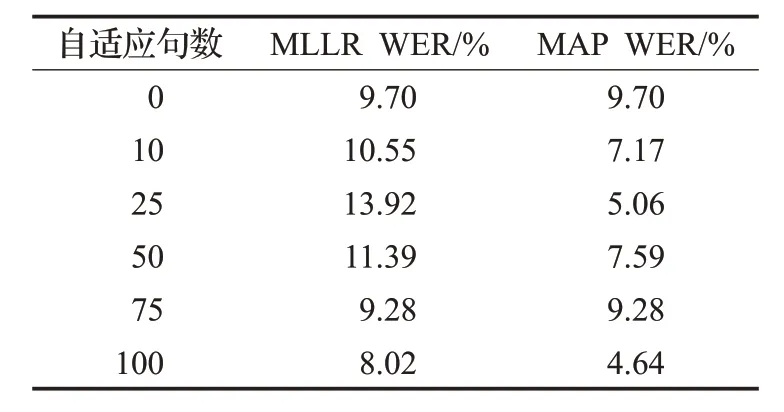
表1 SNR为15 dB时两种自适应方法的语音识别WER

表2 SNR为10 dB时两种自适应方法的语音识别WER

表3 SNR为5 dB时两种自适应方法的语音识别WER
表2和表3分别列出了SNR为10 dB和5 dB时不同自适应方法的语音识别结果。同SNR 为15 dB 时的结果相同,MAP 自适应效果优于MLLR,这就说明,在远场噪声混响环境中不论是在大噪声还是小噪声的情况下,MAP方法都适用,且在两种方法中效果最好。
图3 显示了每种算法在各自适应句数下的平均WER。由图可得,不论是否进行自适应,SNR 越小,WER 越大。在 SNR 分别为 15 dB、10 dB、5 dB 时,MAP算法的平均词错率分别为6.75%、40.34%、93.00%,比未自适应时分别降低了2.95%、12.82%、1.51%,而MLLR算法的平均词错率都比未自适应时高,说明MAP 能很好地适应远场噪声混响环境,而MLLR 不适用,且只有在SNR适中的时候,MAP才有最好的自适应效果。

图3 不同SNR下两种算法在各自适应句数下的平均WER
4.1.2 MAP真实实验
为了评估MAP 算法在真实环境下的可行性,在一个小型会议室中采集了语音。其中房间大小为7 m×6 m×4 m,房间内摆放的沙发、桌椅以及墙壁造成了一定的混响,语音采集过程中还存在电脑运转以及房间外人员走动等噪声。采集卡为SKC 公司的USB 数据采集卡Q801,这是一款基于USB 总线的高性能多功能数据采集卡,其采样频率为8 kHz,具有8路单端16位高速同步模拟信号采集功能。所用麦克风为MP40传声器,是1/4英寸预极化自由场测量传声器,无需极化电压,是一款与前置放大器不可分离的产品,具有灵敏度高、稳定性好、可靠性高等特点。语音采集设备如图4所示。

图4 真实环境下的语音采集系统
所录制语音及其余参数同4.1.1 小节,真实环境下语音识别WER如表4所示。
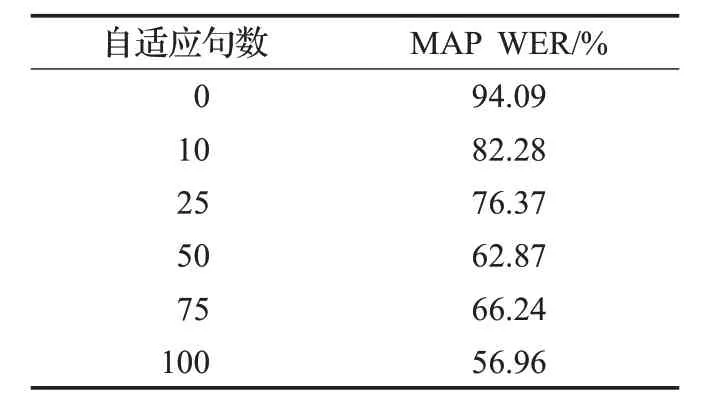
表4 真实环境下MAP自适应语音识别WER
由表4可以看出,真实环境下录制的噪声混响语音识别WER为94.09%,经过MAP自适应后,WER都有所下降,当自适应句数为10 句时,语音识别WER 已经下降了11.81%,自适应句数为100时,WER下降幅度达到了37.13%,说明在真实的噪声混响环境下,MAP有良好的自适应性能。
4.1.3 仿真实验和真实实验结果对比
上述实验表明,在噪声混响条件下,MAP在模拟环境和真实环境下都能有效提高远场语音识别性能。在信噪比分别为15 dB、10 dB、5 dB 的仿真环境下,MAP使WER最多降低了3.06%、21.09%、2.10%;而在真实环境下,MAP使WER最多降低了37.13%。造成这种结果的主要原因是仿真环境所加噪声和真实环境下不完全相同,本实验所加噪声为高斯白噪声[4]。
4.2 MAP渐进性实验
在4.1.1小节实验中已经证实了在远场噪声混响环境下,两种自适应方法中MAP 有最好的声学模型自适应性能,因此本实验采用MAP 自适应算法,来验证MAP的渐进性。其噪声大小如表4所示,所用语料库为CMU ARCTIC下的bdl分组,总共包括1 132句语音,因此本实验自适应句数最大选择到1 000 句,测试语句为与自适应语句不同的132 句语音。其余实验条件同4.1节实验。从10句到1 000句,各种不同自适应句数进行声学模型自适应后语音识别实验结果如表5所示。
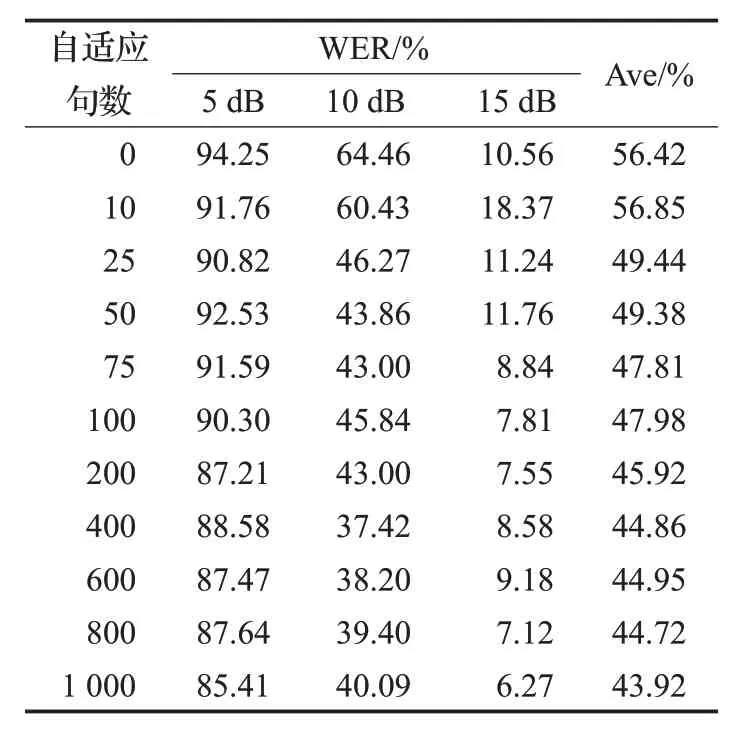
表5 不同自适应句数和SNR下MAP自适应后语音识别WER
表5 中Ave 表示每种自适应句数下三种SNR 的平均WER。从表5 可以看出,同一种自适应语句数下,SNR 越大,语音识别WER 越小;对于同一种SNR,随着自适应句数的增多,识别WER虽然不是绝对地降低,但是有降低的趋势,且从Ave结果来看,自适应句数越多,识别的WER越小,即MAP有良好的渐进性。在自适应句数为1 000 句时,经过自适应后的语音识别率比自适应前平均提高12.50%。
5 结束语
本文在远场噪声混响环境下比较了MLLR和MAP两种自适应方法进行声学模型自适应后的语音识别性能。实验结果表明,在房间反射系数为0.6 时各种噪声环境下MLLR 自适应效果很差,MAP 因引入了模型参数的先验信息自适应效果较好。本文还验证了MAP良好的渐进性及其在真实环境下的适用性。
本文所做自适应实验没有对语音进行增强处理,将远场语音增强和声学模型自适应结合起来进行语音识别是接下来要研究的主要内容。
