基于TAKE的中文关键短语提取算法研究
2020-05-20刘晨晖张德生
刘晨晖,张德生,胡 钢
西安理工大学 理学院,西安 710054
1 引言
随着互联网技术的不断发展,中国整体的网络使用量也呈指数形式的增长。迄今为止,我国现有常驻网民数量已达到7亿。随着时间的推移,这个数量仍呈现直线攀升的趋势。而大规模的网民数量和日益成熟的网络技术将带来大量的网络信息。而在这些信息中,文本信息是最原始有效的数据表现形式,因此随着大数据时代的来临,文本挖掘[1]作为数据挖掘一项极为重要的研究领域被一些学者所提出。本文所研究的文本关键短语提取技术[2]则是文本挖掘工作的一项基础性内容。
文本关键短语提取技术是基于语言学、认知科学、心理学、社会学和统计学等相关知识,挖掘多个词语或短语,来良好地刻画文章、文档或某类主题的文本关键信息提取技术[3-4]。传统的关键短语提取技术[4-5]所提取的关键短语准确率较低,短语歧义性强,并且承载信息量较少,因而无法很好地刻画文章的主旨信息。
基于以上问题,本文在英文关键短语提取算法TAKE(Totally Automated Keyword Extraction)[6]的基础上,加入适合中文文本的中文分词器和新词识别算法,并改进原有算法的词语过滤和特征计算方法,提出一种改进的TAKE算法(简称本文算法)。
2 相关工作
文本关键短语提取技术的研究最早开始于美国,IBM 公司的Luhn[7]提出了基于词频统计的文献自动标引方法,这也标志着关键短语自动抽取研究与应用的开始。之后,Edmundson在前人的理论基础上真正意义上设计实现了最早的关键短语自动抽取系统。而后,许多研究人员加入到相应领域的研究中,形成了基于规则、基于语义、基于统计、基于主题等多个技术体系。
基于规则[4]就是基于机器学习等相关计算机知识建立规则来提取关键短语。早期有非常经典的KEA[8]系统。KEA 是利用有监督的机器学习方法,在训练模型中引入候选词特征值的概念来建立较为精确的模型。随后,Tomokiyo等[9]提取关键词的方法则是基于信息论中KL 散度来对候选词进行排名,提取关键短语。发展至今,相对主流的方法则是基于网络图的TextRank[10]方法。
基于语义[11]就是通过语法剖析句子结构,通过计算机学习人类理解句子的方式来提取文章关键主旨,但这少不了外界知识库、语义词典作为相关训练集。Ercan等[12]所提出基于词汇链进行语义分析和索红光等[13]利用“知网”构建词汇链提取关键词都在基于语义的关键短语提取上有所突破。当然,单纯使用基于语义的方式也存在着很大的缺陷,这主要源于它过于依赖原有的外界知识,可能造成模型产生过拟合且移植性较差。
基于统计就是通过统计学相关知识建立统计量来合理量化短语的各个特征,并通过量化结果进行排序,提取关键短语。Salton 等最早提出了相对成熟的基于统计的关键短语提取算法TF-IDF(Term Frequency-Inverse Document Frequency)[14],该方法通过词频和逆文档频率来构造统计量刻画短语的关键程度。但这样只考虑频率来定义统计量过于粗糙,将造成很多不能代表文章的低频短语或词语被提取出来。近年来,如文献[15-17]等许多文章比较成功地将TF-IDF进行改进并应用到中文关键短语挖掘当中。但这些改进方法大都针对于某些特定领域的中文语料,由于特定领域的中文语料本身携带有一定的先验知识,此类文章多数通过先验知识训练机器学习模型再与TF-IDF 相融合,或依据先验知识在原有TF-IDF统计量中加入量化的短语特征来完成改进。少部分不限制语料领域范围的文章在没有先验知识的情况下,都是通过无监督的机器学习融合TF-IDF 进行算法改进,它们的主要缺点在于精确率较低且算法的时间成本较高。总体上看,目前国内现有的TF-IDF 改进算法缺少大规模的用户使用检测,仅通过论文中的小规模数据无法真正意义地说明相关算法的实用性与稳定性。因此国内外大多数论文仍沿用经典的TF-IDF算法作为相关实验的对比算法。
随后,Blei等[18]提出的LDA(Latent Dirichlet Allocation)关键短语提取算法认为词语、主题、文章之间都存在有一定概率分布,一篇文章由随机的主题组成,而主题则由随机的词语构成,通过先后验概率模型对每个短语建立得分统计量进行短语排名来提取关键短语。这也开创了基于主题的中文关键短语提取技术的先河。而后,关于LDA 算法结构改进且无文本领域限制的相关论文较少,如文献[19]都是基于微博、短文本等特定文本领域的LDA算法改进。此后大多数相关论文都是对于LDA 算法的实际应用。从2012 年至今,LDA算法被广泛应用于分类器、文本聚类、模式识别、语义情感分析等相关领域的研究当中。因此LDA至今仍被作为一个经典的关键短语提取算法参与到相关领域论文的对比实验当中。
随着时间的推移,单纯基于某一方面的关键短语自动提取算法已经成为了历史,取而代之的是基于多领域融合的关键短语自动提取技术。在IEEE大数据国际会议上Pay 提出的TAKE[6]算法就是近年来比较完善的英文关键短语提取技术。他在文献[20]的基础上通过加入词语词性、词语位置、停词约束等多项特征而提出了一种英文关键短语自动提取算法。本文算法也是在该算法的基础上改进并应用于中文文本当中。
3 TAKE算法
3.1 整理框架
本文将TAKE 算法完整步骤整理到图1 的框架图中。其中:候选提取是从文本语料中提取候选关键单词或短语集合;词语过滤是通过单词在文中的词性、位置等特征,从候选关键词中筛选出更有可能是关键词的词汇;特征计算是通过频率、度等特征,建立统计量对过滤后的候选关键词进行量化排名;阈值函数是设定一定的阈值,从量化排名的结果中提取得分超过阈值的关键词或短语作为文章关键短语。
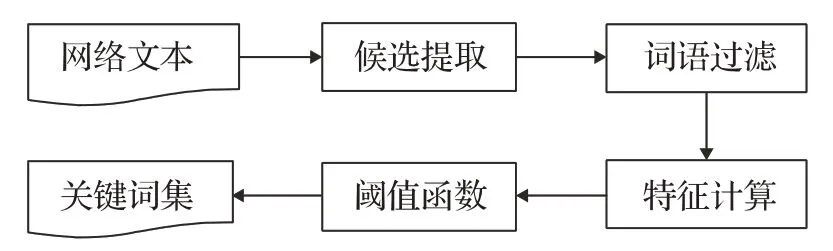
图1 TAKE算法的整体框架
3.2 候选提取
候选提取就是将原始语料构建成候选词语集的过程。由于TAKE算法针对英文文本,因此原文通过标点符号将文本分割成语句,再通过空格将语句分割成单词,最终将所有单词构建成候选关键词语集合。
3.3 词语过滤
词语过滤是通过词语词性、位置以及是否为停用词(无具体实际意义的常用词汇)来重构候选关键短语集合。原文首先对所有候选单词进行词性标注,然后找出词语中的停用词,将相邻两个停用词之间的所有单词按原文顺序组合成候选短语放入候选短语集中。接下来TAKE 认为英文中含有意义的短语一定是多个形容词加名词的词性组合方式,因此去掉所有不属于上述组合方式的短语。最后原文认为短语出现频率不大于1,并且不出现在文章首尾10%以及标题中的短语极大可能性不是关键短语,因此原文删除这些不符合上述条件的候选短语。
3.4 特征计算
特征计算是通过单词频数和度的量化指标建立统计量排序候选短语集中所有短语的过程。其中一个单词的频数是计算候选短语集中该单词独立出现的次数,度是单词在候选集中总共出现的次数(包括该单词涵盖在某个短语内)。接下来原文将度和频数的比值作为该单词的最后得分,如果短语是由多个单词构成,那么短语的得分将是组成它所有单词的得分总和。
3.5 阈值函数
阈值函数就是通过某个标准定义一个阈值,让候选短语集中的所有得分大于阈值的短语作为文章关键短语。原文的阈值定义标准有很多,最终主要由实际情况而定,比如取候选集中得分的平均值或众数作为阈值,当然也可以规定取得分前几名作为阈值。至此便完成TAKE算法的最后一步。
4 本文算法
下面给出两个定义,方便解释本文算法。
定义1 词语在汉语中的定义非常含糊,不同于英文文本,中文字、词、短语之间的界限很难有一个统一完整的定义。因此本文将分词后的每一个最小单元称为词语,如“数据”“挖掘”“是”“有”“必要”“的”都可以称为词语。
定义2 本文将中文短语定义为词语(定义1)的有序组合,如“数据挖掘”“有必要的”。
4.1 本文算法结构
将本文算法的整体流程整理到图2 的框架图中。其中文本分词是因为本文主要针对中文文本,所以要在原文的基础上加入中文分词系统;新词识别主要因为中文词语概念含糊并且结构复杂多样,所以有必要在原文的基础上加入新词识别方法重构分词结果;词语合并与原算法的候选提取类似;特征融合是在TAKE的词语过滤和特征计算的基础上加入更多约束条件改进完成的。
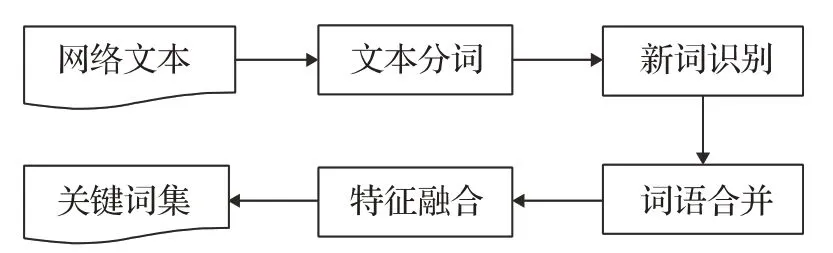
图2 本文算法整体框架
4.2 文本分词
因为TAKE是针对英文文本而言,所以分词过程只需要借助天然的空格即可分割单词。而中文文本由于语言特征等一系列原因,导致分词过程处理起来十分复杂,因此本文加入了jieba分词器作为本文的分词工具,并将分割好的词汇通过已有的词汇库标注词语词性,词汇库未命中词汇按名词属性标注。
4.3 新词识别
本文的新词(本文指未被传统词汇库罗列的词汇)识别采用基于多领域特异性的新词识别算法。由于中文新词通常只流行于某些领域,传统的中文词语库不会罗列相关词语,因此它们常会被分词系统错误分割为不正确的词语,如“给/力”“高/富/帅”“数据/挖掘”等。
新词虽然结构多样不易挖掘,但新词却有很多垃圾串(本文指非新词)所不具有的属性。组成新词的各个词语一般很少含有停用词,并且如果某个词语是一个专业领域的词汇,那么在这个领域的文章中组成该词汇的所有词语一定大量共现。另一点区别在于专业领域词汇通常只会大量出现在某些特定领域,而垃圾串通常在各种领域出现的概率都是均等的。如“数据挖掘”人们很难在某个文学期刊中看到,但“数据”在各个领域都会经常用到。但仅基于以上特征的筛选是过于“粗鲁”的,因此本文还设定了3个指标构建了新词得分函数。这3个指标分别是覆盖率、聚合力、自由度。
覆盖率就是这个候选新词在文中出现的频率。聚合力即 EMI(Enhanced Mutual Information)[21]指标,它的具体定义将在式(1)中给出。该指标认为如果某个词可能是新词,那么组成它的词语一定大概率共现。如“支持”“向量”“机”在机器学习领域中通常都会同时出现。自由度是指左右纠缠熵[22]指标,具体定义如式(2)、(3)所示。这个指标认为如果某个词可以构成新词,那么它在文中向左向右的拓展性应该很高。如“屌丝”经常在文中可以组成“是屌丝”“老屌丝”“屌丝是”“屌丝认为”等短语。
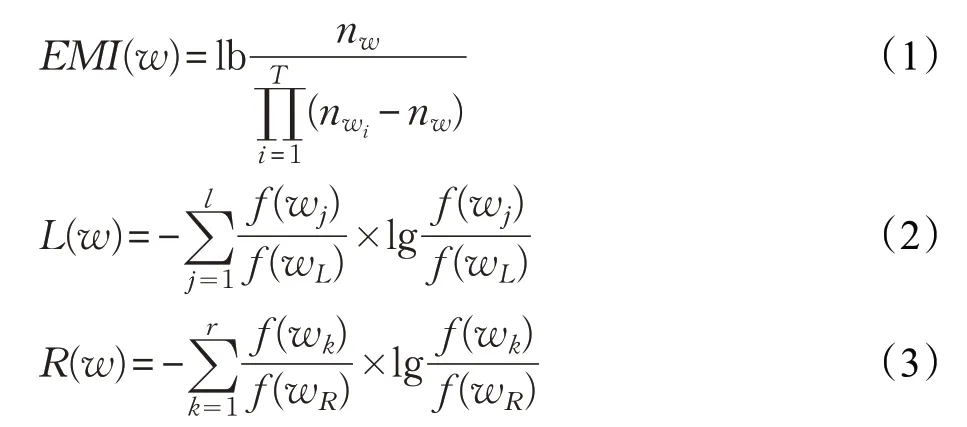
式(1)中,候选新词w由词语集 (w1,w2,…,wT)组成,n表示词语出现频数。式(2)中,f(wL)表示候选新词w所有向左结合成不同短语的数量,f(wj)表示w向左结合成某个短语的数量,l表示候选新词w在文本中向左可以结合成多少种短语。式(3)的定义完全和式(2)相反,它是向右结合。
最终给出新词的得分公式,该公式是根据以上统计量综合给出,具体定义如式(4)所示。
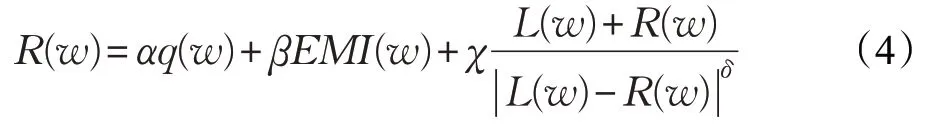
其中,q(w)表示候选新词w出现的频率,EMI(w)、L(w)、R(w)如式(1)、(2)、(3)所示,α、β、χ、δ代表4个权重参数,并且α+β+χ=1(α,β,χ,δ∈[0,1])。
基于以上所有讨论,本文将新词识别整理成如下伪代码。
输入:多篇来自n个领域文章经过分词后的词语集合Wi(i∈ {1,2,…,n})。
输出:新词集合Ni。
1. 将每个Wi中的词语按顺序与之后的词语组合,最多只能组合3次并放入候选新词集NWi中;
2. 过滤掉候选新词集合中组合词语出现次数小于组成它词语独立出现次数最大值的组合词语。
3. 去掉含有停止词的组合词语。
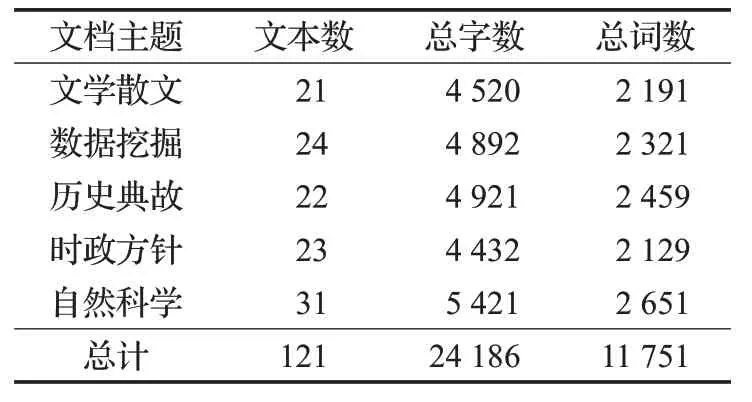
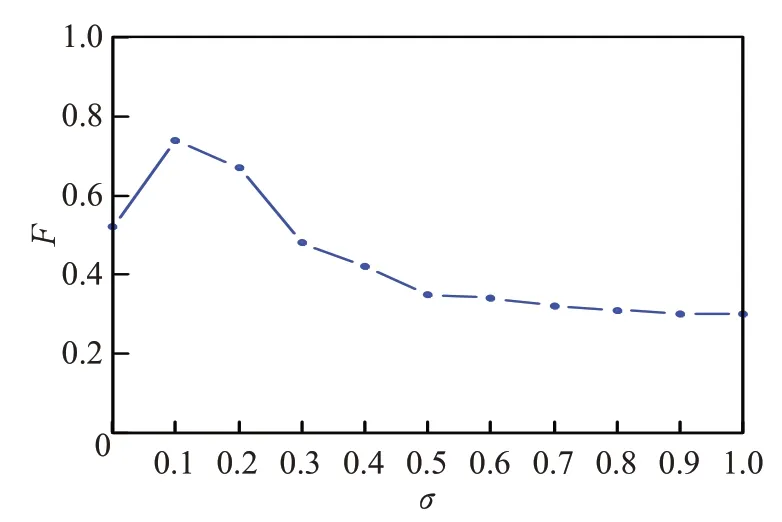
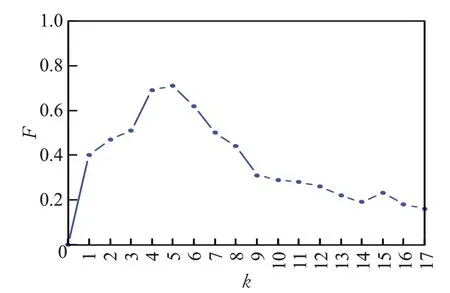
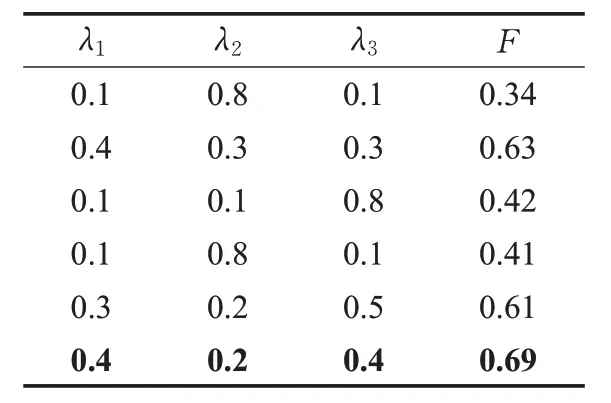
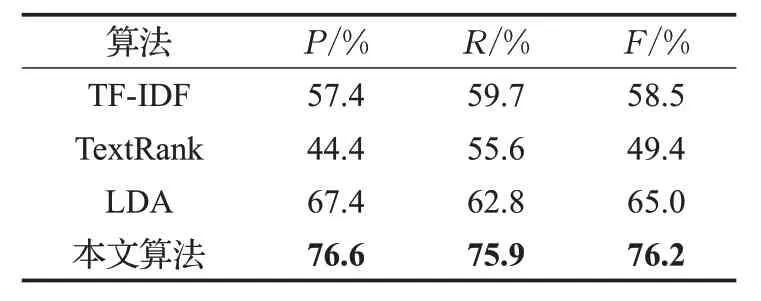
4. whilei 5. forwinNWi: 6. ifwinNWj(j≠i): 7. 从NWi中删除w; 8. end if; 9. end for; 10. ++i; 11. whilei 12. forwinNWi: 13. 将R(w)放入新词集合Qi; 14. end for; 15. ++i; 16. 设立阈值k; 17. foriinn: 18. 从Qi中提取数值最大的k个w放入集合Ni。 19. end for; 20. returnN; 其中R(w)的计算如式(4)所示,k表示给定的阈值。 词语合并首先就是根据新词识别后所给予的新词集合Ni对原有文本重新分词。 之后标记所有分词结果的词语属性,新词库中的词汇都按名词处理。TAKE算法用停用词作为标识,合并相邻停用词之间的单词。但这对于中文而言不够合理,因为中文语句相对于英文语句中的停止词两两间隔较长,这不利于挖掘真正的关键短语。因此本文接下来除了标记停用词以外,还将标记所有除名词、形容词、动词以外的词汇,并将标记词汇之间的词语结合成候选短语放入候选短语集中,再将在文中出现频数等于1的短语剔除。 最后,本文考虑到英文中动词修饰名词时经常使用动名词的形式,如“datamining”中“mining”就从动词标记转化为名词标记,因此TAKE才会剔除所有不是名词结尾的候选短语。但这对中文来讲将产生很多问题,如“数据挖掘”中“挖掘”在中文标注下仍然是动词词性,如果剔除了非名词结尾的短语,那么关键短语“数据挖掘”将被“鲁莽”剔除。基于这些讨论,本文将剔除所有不含名词以及名词和动词不作短语结尾的候选短语。 特征融合就是通过候选短语的频率、共线性、短语性等多个短语特征,构建统计量排序候选短语的过程。TAKE 仅使用度与频数的比值作为得分函数排序短语的做法过于“粗鲁”,如果“数据挖掘”出现次数较多,但原文中也经常使用高频词“数据”单独出现,那么“数据挖掘”最终在TAKE 中的得分却会比较低。与此同时TAKE所使用的词语累加得分的方式也比较“粗糙”,这种做法过于偏向短语的超集,如“支持向量机”与“支持向量机构造方法”同在候选关键短语集中出现,那么后者的得分将一定高于前者。但通常情况下,人们更能接受“支持向量机”作为关键短语。基于以上讨论,本文提出了特征融合算法来排序候选短语。在此之前本文提出两个新的概念:短语性、纯洁性。 短语性是基于候选短语的无歧义而提出的。短语无歧义就是指短语易于理解、语法正确、语义完整的短语。如“数据挖掘造成模型”“数”都是短语表达存在歧义且不完整的短语,而“数据挖掘”则是一个良好无歧义的短语。经过大量实验说明,关键短语的长度大都集中在4 字左右。另一方面通常“支持向量”与“机”的条件概率一定会远大于“支持向量机”与“造成”的概率。因为“支持向量机”的共现可能必将会大于“支持向量机造成”的共现概率,这也源于“造成”与“支持向量机”搭配的不稳定性,使得“支持向量机造成”很有可能不是一个常有的固定搭配。基于以上讨论,本文提出了短语性统计量,如式(5)、(6)所示: 其中,l(w) 代表短语w的长度,a1+a2+a3+a4+a5+a6=1 为式(5)中参数的约束条件。D(w)表示短语w的短语性。P((w1,w2,…,wi-1)|wi)表示顺序组成短语w的词语集合(w1,w2,…,wi)的条件概率。 纯洁性是基于短语词性而提出的。通常在关键短语中起主导作用的是名词词语,而形容词和动词都是对于名词的补充与修饰,如“数据挖掘”是“数据”被动词“挖掘”的一种修饰,当关键词中只出现“数据”而没有出现“挖掘”时,通常人们都可以联想到这是一篇与数据相关的文章,但反之,人们会对于文章内容毫无头绪。基于以上讨论,本文提出了纯洁性,具体定义在式(7)中给出。 其中,C(w)表示短语w的纯洁性,w表示候选短语,e+f+g+h=1 是参数的约束公式。 最后,基于式(6)、(7)以及TAKE的得分函数,本文定义了排序函数,具体定义如式(8)、(9)所示。 其中,短语w由词语集(w1,w2,…,wn)顺序组成。deg(wi)表示词语wi总共出现的频率,freq(wi)表示词语wi单独出现的频率。λ1、λ2、λ3为 3 个权重参数,λ1+λ2+λ3=1 是相应的参数约束条件。 最终本文在阈值函数的选取上沿用TAKE 算法的选取方式。但现今大多数应用场景对于关键词位的数量是给定的,因此本文仅在不要求关键词数量的情况下沿用TAKE的阈值函数。 为检验本文方法的提取效果,通过以下实验结果加以说明。本文语料库来源于百度文库纯文本文章219篇,其涉及领域有文学散文(21 篇)、数据挖掘(24 篇)、历史典故(22 篇)、时政方针(23 篇)、自然科学(31 篇)。具体信息如表1所示。 表1 语料信息 本文实验采用国内外公认的精确率P、召回率R、F值作为结果评判标准,具体定义如式(10)、(11)、(12)所示。 其中,r表示每个主题候选短语集合中选取的短语个数;s表示每个主题实际的关键短语个数;c表示每个主题下所抽取的关键短语对照该主题下实际关键短语的正确匹配个数。 首先确定4.3 节中新词识别的各个参数,本文通过5.1 节的实验语料人工标记新词,通过最终的F值指标给定新词识别中的各个参数。其中参数α、β、χ具体选定过程如表2 所示。表2 中F值是阈值k分别取1、5、10 且参数δ分别取0.1、0.4、0.9 自由排列组合后,α、β、χ取表中各数值时的平均F值。从表2中可以看出,当α、β、χ取0.4、0.3、0.3时,可以得到最大的F值,因此本文后续实验都采用以上的数值设定参数α、β、χ。从结果中不难看出,式(4)中各个特征对于新词的鉴定都十分重要,因此这3个指标的权重数值较为接近时可以取得最大F值。 表2 α、β、χ 的 F 值走势 接下来在以上参数确定的基础上将δ以不同数值带入式(4)中,通过5.1节中所提供实验语料求出相应的F值完成实验,如图3所示。图3中的F值是参数k分别取 1、5、9 时相应参数δ的平均F值。从图 3 中可以看出,当δ取0.1时,相应的F值会达到最大,随着数值不断接近于1,相应的F值也在不断地变小。因此本文将δ确定为0.1。 图3 δ-F 关系对比图 在图2、图3 的实验基础上,本文赋予k不同取值,在相应取值下通过F值的走势来确定参数k的最终取值。具体结果如图4所示,其中当k=0 时召回率和精确率公式的分子为0,因此F值指标也为0,当随着参数k的不断变大F值也在相应增大,当与实验语料真正的新词个数匹配时会达到F值的峰值点,如果超过峰值这个零界点继续增大k时相应的F值也在变小。从图4中可以看出,零界点在数值5 左右,因此本文在后续实验中确定参数k的值为5。 图4 k-F 关系对比图 最终需要确定式(5)、(7)、(9)中的相关参数,其中通过人工标记的关键短语完成式(5)中参数a1、a2、a3、a4、a5、a6和式(7)中参数e、f、g、h的定值实验,具体结果如表3、表4所示。 表3 不同短语长度数量占比表 表4 不同名词数量短语占比表 表3中长度表示关键短语的长度,占比表示该长度下的短语数量在总体关键短语中的占比。由于5.1 节中实验语料均为随机抽取,因此给定式(5)中相关参数:a1=0.14、a2=0.09、a3=0.39、a4=0.29、a5=0.07、a6=0.02。从实验结果中不难看出,中文关键短语长度大概率集中在4 到5,这也与人们的中文语言习惯有很大的相关性。 表4 是对式(7)中参数的定值实验结果,其中名词数量代表该短语中所包含的名词词语数量,占比与表3的含义相似。通过实验结果,将参数e、f、g、h分别定为0.11,0.56,0.29,0.04。可以看出,大多数关键短语都是由两个或一个名词词语组成,这主要是因为通常名词充当另一个名词补语大都只使用一次。如果两个名词修饰一个名词多会掺杂其他词性的修饰语来保证语义符合语法,但这样会使得整个短语长度过长,从而促使短语歧义性增强,因此才会出现表4 所示的统计结果。从中可以看出一个关键短语中大都只含有一个或两个名词性的词语。 通过以上参数的确定,将最终确定式(9)中相关参数。本文同样通过赋予参数λ1、λ2、λ3不同数值后F值的不同表现确定参数的实际数值,具体实验结果如表5所示。从表5中可以看出,式(9)中的任何一个指标都对最终结果产生很大影响,但其中纯洁性特征的影响较弱。根据结果,本文将实验参数λ1、λ2、λ3确定为0.4、0.2、0.4。 表5 λ1、λ2、λ3 的 F 值走势表 根据5.2 节的实验参数,在表6 中展示本文算法与传统经典中文关键短语提取算法TF-IDF、TextRank 和LDA 的对比实验结果。由于本文所改进算法TAKE 只能对英文文本做关键词自动提取,因此本文不做比较。最终实验采用Linux X86作为软件运行环境,其中jieba分词系统采用自带常用词典;停词库由百度文库提供的1 893个停用词组成,算法由C++实现,gdb调试,具体实验结果见表6。 表6 四种算法基于P、R、F 的对比结果 从表6 中可以看出,TextRank、IF-IDF、LDA 算法在准确率上与本文算法相比偏低,这说明每种算法在取相同数目的关键短语时,本文算法所提取关键短语与正确关键短语的匹配程度更高,即式(10)中的c大于其他对比算法。这也导致本文算法在召回率,即式(11)上分母相同的情况下分子大于其他算法,因此相对于其他三种对比算法在召回率上有更为良好的表现。因为F值指标是对准确率和召回率的综合衡量,所以表6中本文算法在F值上要远高于其他对比算法。这也说明了本文算法在关键短语提取上更贴近文章主题。 本文针对英文关键短语提取算法TAKE 进行了文本分词、新词识别、特征融合等一系列有效改进,所提出的本文算法成功运用于中文文本的关键词自动抽取当中。通过与经典的中文关键短语提取算法进行对比,本文算法在精确率、召回率和F值上具有更高的量化表现,说明了本文算法的主题关键短语提取效果更加良好。与此同时,本文算法仍有很大的改进空间,例如加入更多的先验知识优化本文算法的约束规则,添加机器学习相关算法等。4.4 词语合并
4.5 特征融合



5 实验分析
5.1 评判标准

5.2 实验参数



5.3 实验结果
6 结束语
