域信息共享的方法在蒙汉机器翻译中的应用
2020-05-20苏依拉牛向华赵亚平仁庆道尔吉
张 振,苏依拉,牛向华,高 芬,赵亚平,仁庆道尔吉
内蒙古工业大学 信息工程学院,呼和浩特 010000
1 引言
基于神经网络模型的机器翻译[1]在几种语言对的翻译任务测试中均表现出较好的翻译水平。然而,神经机器翻译(Neural Machine Translation,NMT)系统依赖大规模的适用于训练此类系统的平行语料对的数据,如果没有或缺乏平行语料库,经常出现训练质量不佳的情况,甚至不能进行正确的翻译。目前,机器翻译领域的相关专家对NMT 系统已经给出了结论,很多种语言的神经机器翻译可以通过大规模的平行数据和GPU等硬件强大的计算能力获得高质量的翻译结果[2-3]。另一方面,神经网络的科研人员正在思考如何为平行语料句对缺乏的低资源语言和特定领域提供一个可行的方案,由于为低资源语言数据准备如此庞大的语料库仍然是一个大问题,通过阅读大量的文献资料,最终选定一种目前快速发展并且实测有效的方法来缓解语料资源稀缺的问题。本文采用的方法是利用ELMo 蒙语和汉语单一语种的数据预处理提取语境上下文信息的方案来缓解平行语料不足的困难。
预训练词向量表征[4-5]是很多神经语言理解模型的关键组成部分,主要用来实现文本句子的向量化表征,并且通过单语的预训练实现词语向量上下文语境的特征提取,使得每一个词的向量不仅表示单词本身的含义,而且包含周围n-gram 单词的上下文语境语义信息。然而,学习较高质量的词语的向量化表征非常有难度。为了帮助基于神经网络的机器翻译模型实现更好的翻译效果,预训练词向量表征技术应该完美建模单词使用方面的复杂特征(如句法和语义),以及单词使用在不同语言环境或上下文语境关系的变化(即建模一词多义)。本文对蒙汉语料库进行ELMo(Embeddings form Language Models)预训练的方法与其他词嵌入Word Embedding向量的表征方法(如Glove、CBOW)相比,本文的蒙汉语料ELMo(深层语境化词表示)方法可以更好地学习到词语的上下文语境信息,ELMo[6]介绍了一种新型的具有一定深度的结合上下文语境关系的向量化词表征,ELMo的神经网络模型基于双向长短期暂态记忆神经网络。BiLSTM(Bidirectional Long Short-Term Memory)神经网络可以对较长序列的上下文相关的文本进行序列递归循环记忆编码,通过其独特的双向循环神经网络,结合长短期记忆单元,不仅能够对词语本身的含义进行向量化的表示,还可以通过神经网络复杂的特征提取能力对相邻位置的词语进行向量化的信息提取,这样可以帮助单词学习到复杂的自然语言信息,如句法和语义。不仅如此,因为本文的蒙汉平行语料中有很多对话、上下文相关的小说等大型段落级文本信息,所以使用的ELMo 神经网络预训练词向量的方式能够帮助语料中的词语在语言语境和上下文语境中的变化进行建模。ELMo 的预训练的实验数据是内蒙古工业大学蒙汉机器翻译课题组构建的126 万蒙汉平行语句对、单语语料库以及从多个蒙语网站爬取的蒙语文本和汉语文本,其中包括新闻、政府工作报告、对话、演讲稿、小说等上下文语境相关的大型文本语料库。通过基于BiLSTM 的深层语境化的词表示方法,本文的ELMo 预训练方法还可以对蒙、汉多义词以及词语的语态等词语变形进行建模。
ELMo 的预训练过程可以在蒙语或汉语的大型单语文本中动态地学习词向量表示,ELMo的预训练能够为蒙汉神经机器进行翻译,然后把较好的训练模型结点迁移到翻译模型中。本文的翻译模型采用的实验数据为126 万句蒙-汉平行语料,平行语料数据通过FastText技术进行词嵌入表示,然后将其输出投入到翻译模型的Word Embedding 层 。 FastText 与 传 统 的 word2vec 或Glove 词嵌入方式相比,它们都可以利用没有标记的数据在没有监督机制的情况下自学习词向量,不过本文采用的FastText训练词嵌入层词语的词向量时,会考虑更细粒度的子词词素信息,即subword,有利于缓解低资源语言翻译中词汇表受限的问题。本文的翻译模型是基于多任务学习的一个编码器对应多个解码器的神经网络架构,多个解码器共享部分参数,每个解码器在解码过程中可以联合参考其他解码器所共享的域信息,能够有效地解决低资源语言翻译过程中经常出现的平行语料数据稀缺和词汇表受限的问题。
2 神经机器翻译
目前的神经机器翻译框架多数遵循[1]端到端(即序列到序列)建模的方法。其基本思路是通过给定一个源语言句子,并将其进行词嵌入向量化表示x=(x1,x2,…,xi,…,xl) 和相应的目标语句词嵌入向量化表示y=(y1,y2,…,yj,…,yJ),神经机器翻译旨在基于概率计算来模拟源序列翻译到目标序列文献[1]提出了一种编码器-注意力机制-解码器框架来计算这种概率。
双向递归编码器-解码器模型(BiLSTM)中的编码器从源句子向量中读取一个单词xi,并输出一个固定长度向量的句子表示。BiLSTM 采用双向递归的方式进行编码,使得前向和后向相连接。
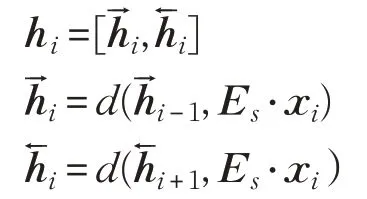
其中,Es是在源语言嵌入词向量之间共享的源语言字嵌入矩阵,d是编码器基于先前隐藏状态计算的当前隐藏状态的循环单元。然后,将hi称为隐层注释向量,其从前向和后向两个方向对源语句进行编码直到第i个时间步。然后建立注意机制,以便选择哪个隐层注释向量应该有助于推导下一个目标词的预测决定。通常,先前目标词与注释向量之间的相关性得分rel(zj|1,hi)用于计算上下文语境向量ci:
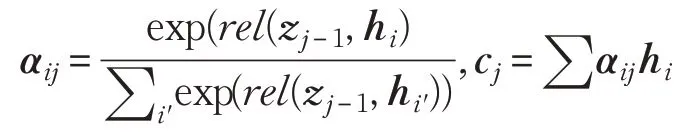
在编码器-解码器架构的另一端,解码器一次递归地生成一个目标字yj:

其中:
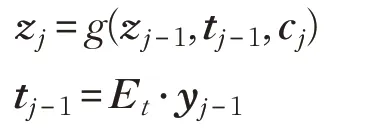
解码器中的序列递归计算机制类似于编码器中的对应机制,除了先前隐藏状态zj-1和目标嵌入tj-1之外,它还将来自注意机制层的上下文语境向量cj作为输入来计算当前隐藏状态zj。然后可以从隐藏状态的softmax分布对在第j个时间步的预测字yj进行采样。
3 无监督预训练
源语言的词嵌入(Word Embedding)向量化表示方法是机器翻译甚至自然语言处理(Natural Language Processing,NLP)任务中最常用的词向量化表示方法。目前,常用的词语向量化嵌入到Word Embedding 层表示的方法是word2vec 等方法,然而词语的Word Embedding嵌入层向量化表示的word2vec方法的实现原理其实是一个词语根据初始化状态进行静态化表示的方法。简而言之,自然语言输入后利用word2vec 学习完每个词的表示之后,词的表示层状态就固定不变了,之后机器根据Word Embedding层的词嵌入信息学习的时候,无论新句子上下文语境的信息是什么,这个词的词语嵌入层Word Embedding的参数表示都不会跟随上下文语境的场景发生变化。由于静态表示的局限性,导致这种情况对于多义词的表示是非常不充分的,无法根据上下文语境信息表示多义词的含义。
本文使用ELMo 网络的目的就是为了解决上述情况中语境信息丢失的问题,利用前向和反向同时学习的双向LSTM 神经网络的训练动态地去更新词语的词嵌入层。ELMo的本质思想是:事先用长短期记忆神经网络语言模型在一个大的语料库上学习好词的词嵌入层表示;然后,用平行语料库中蒙语或者汉语单方面的训练数据来微调预训练好的ELMo 模型。在ELMo 模型中,将这种微调的方法称为多任务参数共享的域信息迁移的方法。通过ELMo 多任务域信息迁移预训练数据的方式,本文模型可以获得词语在当前上下文相关语境下的词嵌入层向量信息。
3.1 ELMo:来自语言模型的嵌入
本文采用的ELMo 神经网络预训练词向量嵌入的方法结合动态的蒙、汉双语上下文语境来对词语的向量化表示层进行建模,与最广泛使用的单词嵌入方法[5]不同,ELMo深层语境词语的向量化表示(词表征)的词向量信息数据的维度蕴含了整个输入句子的函数。本文的ELMo 预训练模型首先建立具有字符卷积层的提取特征层,在此基础上再建立两层biLM。
3.2 对蒙语的字符卷积编码
本文的语料预训练处理方法通过使用字符的卷积运算从位置上相邻的子词单元中获益,通过这样的卷积操作,可以无缝地将多义信息通过分层卷积运算集成到下游任务中[7],而无需经过带有标签的数据的训练学习过程。
蒙古语句子信息向量化的编码过程可以抽象为一个向量化表示和特征提取的过程,卷积神经网络模型提取向量特征的依据是根据卷积窗口数量、卷积核移动的步长来决定。例如一个蒙古语句子“(内蒙古首府是呼和浩特)”,利用卷积神经网络进行编码时可以根据图1所示编码过程进行。
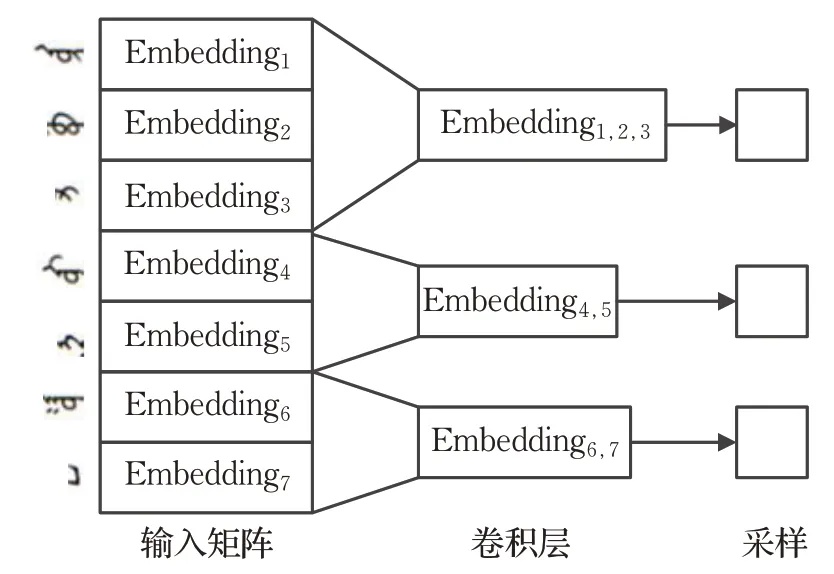
图1 蒙古语句子编码
根据设定的卷积窗口,第一个卷积窗口获取蒙古语词干词缀向量“”,第二个窗口获取“”,以此类推,发现经过一层卷积层卷积操作后,提取到的上下文语境语义关系仅仅局限于上下文语境直接相邻的若干n-gram 个字符,对于位置上距离较远的传统回鹘蒙古语字母,简单的浅层卷积模型没有很好的提取特征的能力,来识别它们之间的上下文语境深层的语义关系。由此,本文依据深度学习思想,采用一种深层关联的叠加结构的卷积神经网络来对蒙汉机器翻译模型编码器进行构建。
本文编码模型的卷积神经网络模型构建的方法是让第二个卷积层的输入信息从第一个池化层的输出获取,先卷积提取特征作为编码信息,然后池化操作进行下采样,再把池化层的输出作为下一个卷积操作的输入。重复这一过程,使得低层的卷积层能够直接提取到位置上相邻的蒙古语句子向量信息,较高层的卷积层能够间接提取到位置上距离较远的上下文语境的向量信息,从而在一定程度上缓解卷积神经网络提取特征的视野相对较窄的局限,实现其对整句话甚至连续的多个句子的历史信息进行记忆。最后,将最后一层池化层下采样的信息通过向量平铺的方式传递给全连接层,这样层叠的卷积神经网络就完成了句子的编码过程。以(内蒙古首府是呼和浩特)”为例,对应的层叠卷积编码器的网络结构如图2所示。
层叠卷积输入蒙古文句子,首先对句子的Word Embedding层进行一层卷积操作,然后经过第一个池化层对输入矩阵中第1、2、3个蒙古语向量进行采样,输入矩阵的第二个池化层对第4、5 个蒙古语句子的Word Embedding 采样。同样的方式,第三个池化层对第6、7个蒙古语Word Embedding 层采样,并以第一层池化层的输出作为输入,进一步进行卷积运算,当第二层卷积层窗口为2 时,则把蒙古语的前5 个向量做卷积运算传递至第二层池化层。同时第4 到7 个蒙古语Word Embedding 向量做卷积运算传递至第二层池化层的下一个节点中,以此实现位置上距离较远的向量之间的联合编码。由此层叠卷积编码器模型构建完成,且该模型中的卷积计算方式和池化层的特征提取方式与卷积神经网络一致。
3.3 双向语言模型
给定N个标记的序列(t1,t2,…,tN),前向语言模型通过对给定历史(t1,t2,…,tk-1)的记忆,然后对标记tk的概率建模来计算序列的概率:

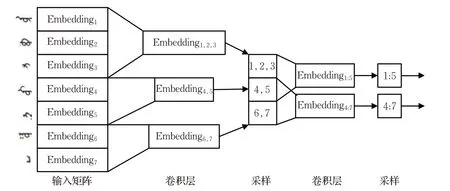
图2 堆栈卷积编码器
从后向前训练的语言模型类似于从前向后训练的语言模型,除了它反向运行序列,在给定未来上下文语境的情况下预测前一个标记:
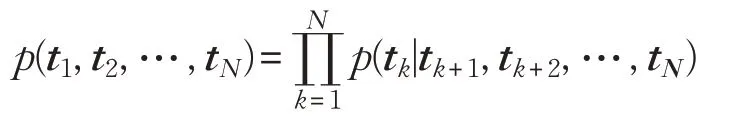
它能以类似于前向训练模型的方式实现,每个后向LSTM层j在L层深度模型中产生表示tk的。
双向语言模型biLM结合了前向传播和反向传播的语言模型LM。本文的公式联合最大化前向和反向的对数可能性:

本文在前向传播Feed-Forward 和反向传播Back-Forward的方向上与标记表征和Softmax层的参数进行绑定,同时保持LSTM的参数在每个方向上分离。总的来说,这个公式类似于Matthew等人[8]的方法。
3.4 ELMo
ELMo是biLM中间层表示的任务特定组合。对于每个标记tk,L层biLM计算一组2L+1 表示:
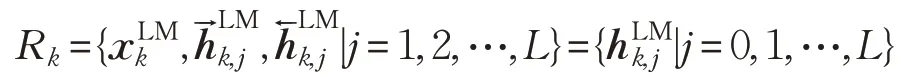
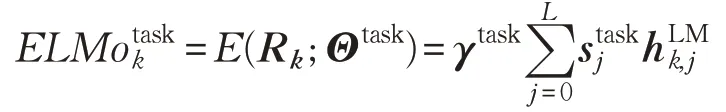
在上面的公式中,Stask是Softmax 标准化权重,标量参数γtask允许任务模型缩放整个ELMo 向量。考虑到每个biLM层的激活具有不同的分布,在某些情况下,它还有助于在加权之前将层标准化[9]应用于每个biLM层。
3.5 语料的ELMo表征
本文使用从双向LSTM中预训练蒙、汉单语语料得到词语的语境上下文的向量,该双向 LSTM 使用的语料数据是大规模平行句对语言模型bi-LSTM 在120 万平行语料库和网页中爬取的单语文本语料库上训练得到的。与一些语料预训练的方法[10-11]不同,基于ELMo的蒙汉语料预训练方法的词向量表示方法的嵌入层信息表示的内部函数是复杂的,ELMo神经网络可以对深层次的信息如上下文语境信息、多义词、语义、语态等信息进行建模。具体来说,对于每个神经网络的训练任务,学习堆叠在每个输入单词上的向量的非线性组合或者线性组合。这种数据预训练方法可以显著提升性能,效果优于仅使用LSTM 顶层的表征[12]。用这种预训练蒙语或汉语的单语语料数据方式,组合深度神经网络函数的内部状态,可以带来丰富的词语语境和上下文信息的向量化表征。图3 显示了蒙古语句子(经过了这么多年,你想消除你们之间的分歧谈何容易)进行BiLSTM编码的过程。
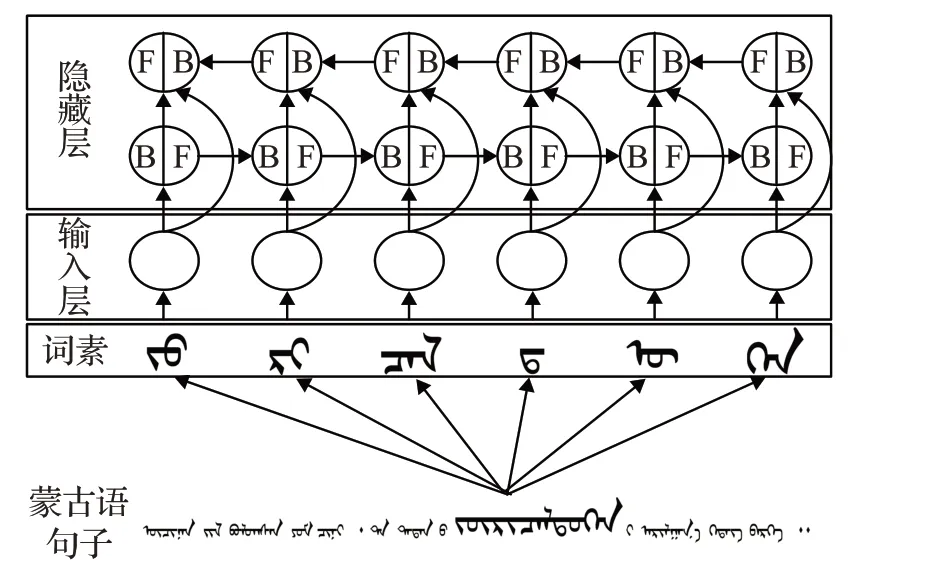
图3 蒙语词素输入过程
图3表示的是蒙语词素输入的过程,词嵌入层的编码器将蒙语句子中的回鹘蒙古文词语进行词根、词干、词缀的切分,并以构词词素为基本输入单元进行输入,输入层编码器一次输入一个词素的向量信息[13]。通过输入过程来进行蒙古语的编码,图4所示为编码器网络结构。
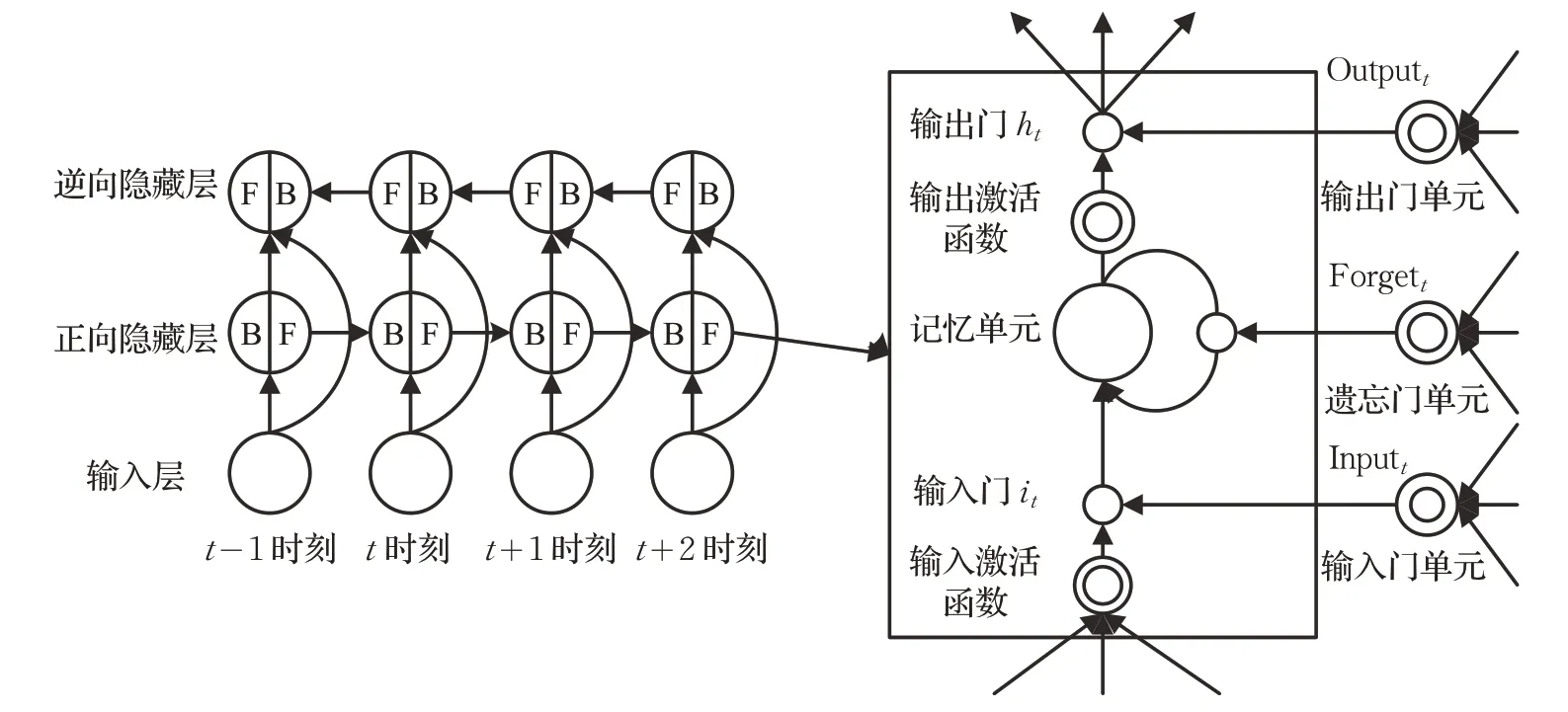
图4 编码器模型结构图
4 基于多任务参数共享的蒙汉机器翻译系统
首先,词嵌入层从ELMo神经网络的输出获得源和目标字向量,其中是模型大小,V是词汇量大小。在嵌入查找步骤之后,将字向量乘以缩放因子。为了捕获输入序列中单词的相对位置,将根据不同频率的正弦曲线定义的位置编码添加到源和目标的缩放的单词矢量中。
编码器层将输入字向量映射到连续隐藏状态表示。如前所述,它由两个子层组成。如图5 所示,第一个子层执行多头点积自我注意。在单头情况下,将子层的输入定义为x=(x1,x2,…,xT) ,输出定义为z=(z1,z2,…,zT),其中,输入被线性变换以获得密钥(ki)、值(vi)和查询(qi)向量:
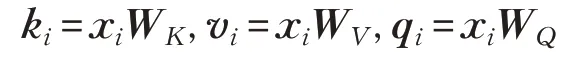
接下来,通过在这些相似度值上应用Softmax 函数来计算关注系数(αij)。
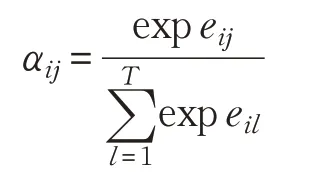
自注意输出(zi)通过注意权重与值向量的凸组合,然后线性变换来计算。
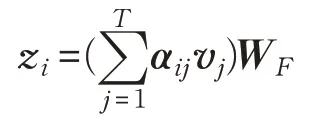
其中,WK、WV、WQ、WF是形态为的可学习和训练的参数变换矩阵。为了将注意力机制扩展到多头注意(ℓ),将编码器中获取的键、值和解码器中获取的查询向量分成“向量”,对键、值和查询的每个向量并行执行注意力计算,然后将它们的计算结果进行连接,最后在WF进行最终线性变换。第二个子层由两层位置前馈网络(Feedforward Network,FFN)组成[13],并且这里的FFN是具有ReLU激活的函数。
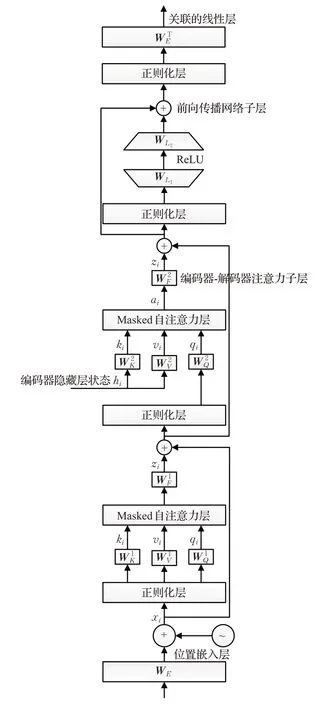
图5 多任务参数共享的编码器-解码器框架图
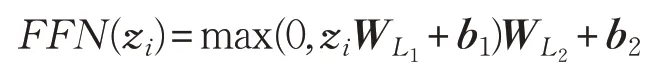
解码器层和编码器层具有类似的结构,它也是由3个用于解码的子网络层组成。类似于编码器的第一子层的自我注意力机制,不同的是解码器的第一个子层执行MASK(掩码机制)的自我注意机制,其中掩模用于防止解码过程中当前位置的解码参考后续位置目标语言向量。解码器的第二个解码子层执行的是编码器-解码器交互的多头注意力机制,其中查询向量Q的输入层向量信息来自解码器层的词向量,而注意力机制的键K和值V向量的输入层信息来自编码器的最后一层嵌入层表示。图6 展示了用于一对多多粒度融合翻译任务的MTL(Multi-Task Learning)方法的框图,该方法基于多个解码器之间参数的部分共享。本文为了更清晰地表示解码器中这两个注意力子层中的参数向量,加入MASK 机制的自注意机制子层的转换机制的权重向量被引用为,编码器-解码器注意机制子层参数向量表示为。第三个子层由FFN 组成。在解码器层的顶部有一个用于预测生成下一个字词的线性层[14]。
图5 中,词嵌入层权重为WE,关联层权重为,自我关注的一部分权重为,编码器-解码器注意力的权重为,前向传播网络子层参数为。
5 实验和结果分析
本文的实验环境包括系统的硬件环境的配置和系统内软件环境的配置,具体实验环境配置如表1所示。
5.1 语料划分和句子切分预处理
内蒙古工业大学蒙汉翻译课题组构建了126 万句对回鹘蒙古语和汉语平行语料库,另外使用了由一些专有名词组成的词典库,用来矫正本文的蒙汉翻译系统,蒙汉平行词典库包含11 160 组地名库、15 001 组人名库、2 150组农业名词库、308 714组医学名词、5 000组物理名词。为了实验的顺利开展,本文将蒙-汉平行语句翻译语料数据集中语料分为三部分:训练集、验证集和测试集。本文翻译模型的平行语料库中数据集划分如表2所示。

表1 实验环境配置

表2 实验数据集划分
本文采用了分布式表示(Distributional Representation)的词向量方法,用UTF-8作为蒙汉双语语料的编码格式。
本文对原始的蒙汉平行语料句子分别进行了分字切分、BPE切分(https://github.com/rsennrich/subword-nmt)、LSTM-CRF 神经网络词切分(https://github.com/Glassy-Wing/bi-lstm-crf)三种词切分方式的对比,实验结果如表3所示。

表3 语料的多种形式的分词预处理
表3中的蒙古文-汉文语句1和语句2的单词对应关系如图7和图8所示。
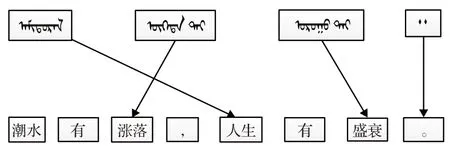
图7 蒙古文-汉文语句1单词的对应关系
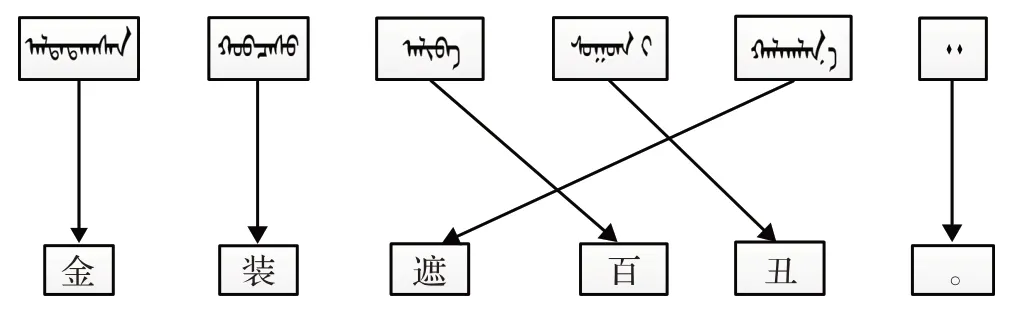
图8 蒙古文-汉文语句2单词的对应关系
5.2 基于ELMo 预训练的Transformer 框架下的多任务参数共享的翻译实验
本文通过应用蒙古语和汉语的字节对编码[15]和32 000 个合并操作[16],系统使用基于字词单元切分的BPE 方法联合编码回鹘蒙古语语句和汉语语言单词。为了进行实验对比,使用两种方法对所有可训练的模型参数初始化:一种方法是使用LeCun 统一初始化方法[17];另一种方法是由FastText[18]预训练的参数模型迁移到本文翻译模型从而进行初始化。基于FastText 的预处理方法在大型未标记回鹘蒙古语和汉语文本预训练的方法很快,FastText 方法可以快速训练大型语料库得到预训练之后的模型,并且FastText方法基于蒙语词素和汉语字符的细粒度的编码方式,可以帮助人们计算未出现在训练数据中的亚词单词的近似组合形式词语的单词表示。最后根据截断的高斯分布随机初始化部分嵌入层权重。
本实验采用的是谷歌开发的基于Tensor2Tensor 框架的Transformer模型[19],建立了6个基于多头自注意力机制的编码器-解码器层,dm=512,dh=2 048,τ=8。本文 使 用 Adam 优 化 器[20]超 参 数β1=0.9,β2=0.997,ε=1E-9.3。学习率(lr)时间表在每个优化步骤(步骤)中根据以下因素而变化:

每个小批量包括大约2 048 个源tokens 和2 048 个目标标记,使得类似长度的句子被一起打包。本文训练模型直到收敛并使用开发集性能保存最佳检查点。对于模型正则化,使用标签平滑(ε=0.1)[21]并设置丢弃率(使用Pdrop=0.1)[22]应用于词嵌入,注意力机制系数,ReLU激活,以及剩余连接之前每个子层的输出。在解码期间,使用波束宽度为5 的波束搜索(Beam Search)和长度归一化[23],其中α=1。神经网络反向传播优化流程如图9所示。
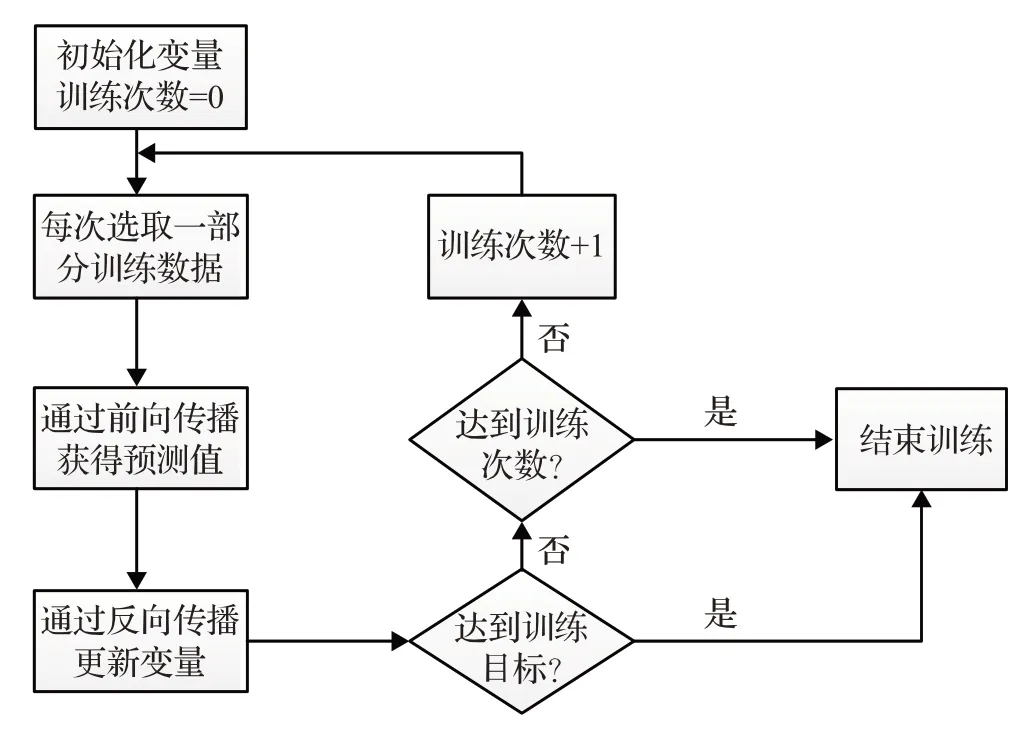
图9 神经网络反向传播优化流程图
5.3 实验对比和结果分析
本文利用检查点模型进行实验,10个epoch迭代的实验评测结果如图10 和图11 所示。图10 中的折线图统计的数据是训练误差的损失值loss,图11中的折线图统计的数据是训练正确率Accuracy。
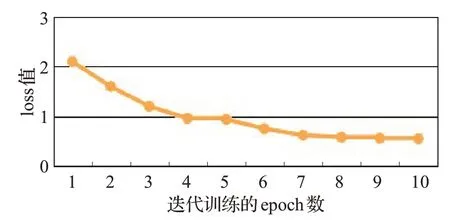
图10 训练误差的损失值
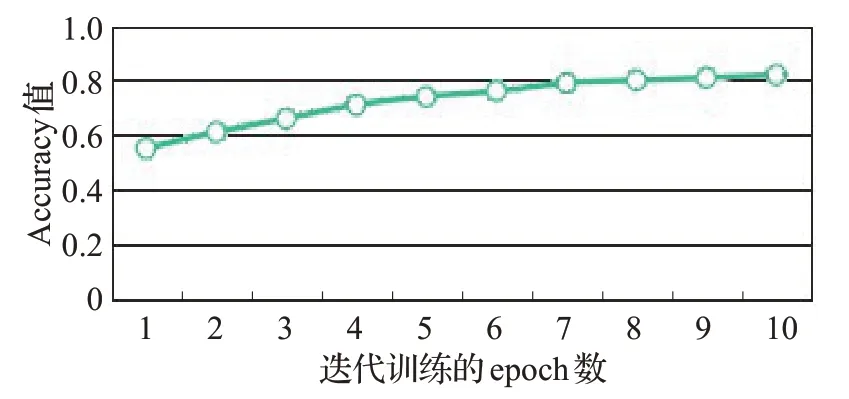
图11 训练正确率Accuracy
通过实验结果分析,随着迭代次数的增加,训练误差损失loss值逐渐变小,翻译正确率Accuracy值也随着增长。但是从第7 个epoch 开始,模型训练中由于过拟合导致loss 值下降到0.5 左右。模型的最优BLEU 值达到48.27,并没有展现出更好的翻译效果,究其原因主要是模型译文候选集的选取中存在一定的问题,导致模型没有从中选取最优译文。
本文又进行了一系列的对比实验。首先,分别进行了Transformer模型和ELMo-Transformer模型的实验作为对比。内蒙古工业大学蒙汉翻译课题组构建的126万句对回鹘蒙古语和汉语平行语料库中包括长度低于10 个字的短句子,也有长度大于30 个字的段落级上下文相关的长句子,其中长度大于30 的情况主要出现在政府工作报告、小说和人物对话中。因为这种段落级的语料蕴含的上下文相关信息更加丰富,所以结合ELMo的预训练可以帮助神经网络更好地提取特征,进而使得翻译更加准确。
ELMo预训练神经网络对单语数据建模时,可以对任意长度的句子进行编码,无需对句子的长度进行特殊操作。然而,在测试数据集中,为了对ELMo 预训练的效果进行评估,对测试集数据进行了句子的长度正则化处理。第一步,给出长度范围的4 组标准,分别是长度为1~10 个字为第一组,长度为11~20 个字为第二组,长度为 21~30 个字为第三组,长度为 31~40 个字为第四组。第二步,对于每一组长度的实验,测试数据集的数据中每行句子长度采用同一组标准(以上4组),然后编写Python 脚本代码,将不符合要求的句子断行处理(将长度超过标准长度的句子超出标准之外的部分切断,然后独自成一行),对于长度不满足要求的句子长度可以将偶数行数据添加到奇数行再按照长度标准分行处理。总而言之,本文的测试集的每一组实验的句子长度都有一个标准(1~10,11~20,21~30,31~40其中一个)。
在句子词数分别为1~10、11~20、21~30以及大于30等四种长度的句子中进行比较,实验结果的BLEU值评分如表4所示。

表4 实验比较
通过表4的结果分析,即使采用基于词级粒度结合BPE分词方法的语料输入,基于ELMo的机器翻译模型在句子长度小于30 时,得出的翻译评分稍低于Transformer 模型,而随着词数的增加,ELMo-Transformer 模型的翻译质量逐渐提高,在大于30个词的句子翻译中,BLEU 值达到 49.47,相比较 Transformer 模型 BLEU 值提高了1.10。
然后对Transformer 翻译模型分别进行了LeCun 统一初始化,与先由FastText预训练的参数模型迁移到本文的翻译模型从而进行初始化两个实验进行对比。BLEU值评测效果如表5所示。
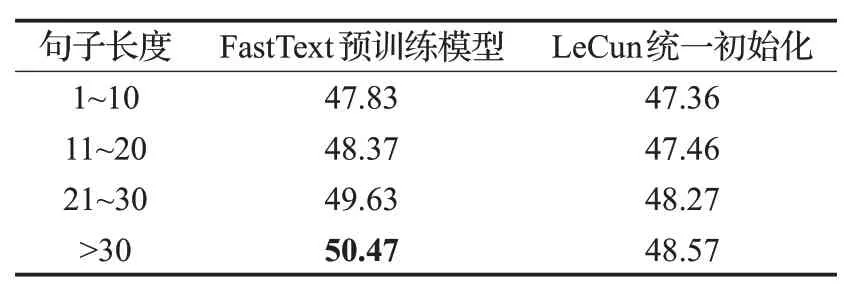
表5 实验比较
通过表5的结果分析,在句子长度小于20时,FastText预训练模型对Transformer基线系统的翻译效果提升比较小,但是随着词数的增加,经过FastText 预训练的Transformer机器翻译模型的翻译质量逐渐提高,最大的BLEU 值达到50.47,相比较LeCun 统一初始化参数的Transformer模型BLEU值提高了1.90。
6 结论和未来展望
蒙汉机器翻译属于低资源语言的翻译,面临着平行标记的语料资源稀缺的困难,为了缓解平行语料资源数据稀缺和词汇表受限带来的翻译质量差的问题,本文利用多任务预训练数据的方法结合Transformer翻译架构进行蒙汉翻译。首先,利用ELMo(深层语境化词向量表示)进行蒙语或者汉语单方面语料资源的预训练。实验结果表明,使用ELMo数据预训练蒙语和汉语语料之后再进行Transformer 翻译能有效提升翻译质量,特别是对于句子比较长的输入序列,通过分析Transformer模型架构,发现Transformer 每一层的结点需要和上一层的所有结点进行相关性的计算,这样的计算成本和显存需求非常高,如果不进行数据预训练,想要对大规模数据进行高质量的特征提取和建模,那么随着网络层数的增加,Transformer 的计算量和参数增长,带来内存需求量的增加。通过ELMo预训练,能够充分利用BiLSTM模型的序列递归和长期记忆的能力,有效记忆上下文语境关系,有助于Transformer 在不增加网络层数的前提下做下一步的训练。其次,本文利用FastText词嵌入算法把蒙汉平行语料库中的上下文语境相关的大规模文本进行预训练。基于FastText 文本语料预训练的方法很快,允许快速训练大型语料库上的模型,并允许计算未出现在训练数据中的单词表示。然后,根据多任务共享参数以实现域信息共享的原理,构建了一对多的编码器-解码器模型进行蒙汉神经机器翻译。实验结果表明,本文的翻译方法比Transformer 基线翻译方法在长句子输入序列中可以有效提高翻译质量。
