多注意力层次神经网络文本情感分析
2020-05-20刘国利孙天岳赵启涛
韩 虎,刘国利 ,孙天岳,赵启涛
1.兰州交通大学 电子与信息工程学院,兰州 730070
2.甘肃省人工智能与图形图像工程研究中心,兰州 730070
1 引言
目前,随着互联网的发展,越来越多的人倾向于在购物APP上进行消费,这种方式不仅方便了人们的日常生活,而且拓展了商家的销售渠道。同时消费者可以对自己购买的产品给出及时的评价,商家通过对这些评论数据进行情感分析来判断消费者对产品的褒贬态度,从而来调整产品的定位和营销策略[1-2]。
神经网络以其优越的性能在文本情感分析领域取得了重大的突破[3-5]。Bahdanau 等人利用神经网络进行语言模型的构建,将词向量在低维空间中进行表示,能够更好地度量词与词之间的相关性[6];Kim等人采用多个大小不同卷积核的卷积神经网络(Convolutional Neural Networks,CNN)模型进行局部特征提取,并成功应用于文本分类[7];Wang 等人利用长短时记忆网络(Long Short-Term Memory,LSTM)解决句子中词语的时序关系以及词语之间的交互性问题,有效提高了情感分析的准确度[8];Tang 等人在词向量中加入了情感信息,有效提高了情感分析的准确度[9];Graves 等人提出使用循环卷积神经网络进行文本的分类,该方法采用双向循环结构对文本进行建模,在减少句子中词的歧义噪声的同时可以更好地保留词序信息[10];Tai等人在LSTM网络的基础上引入树形结构来提高句子的语义表达[11]。
为了区分句子中不同词语对分类的不同贡献,注意力模型也被广泛地引入到深度学习模型中。Yin等人在CNN 模型的基础上加入了注意力机制,较未加入注意力机制的模型有更好的效果[12];Wang 等人结合LSTM网络和注意力机制进行基于特定方面的情感分类,使得模型在训练中只关注特定方面,从而避免对所有文本做相同处理,取得了比之前模型更好的效果[13]。
本文将LSTM 网络与CNN 模型相结合,提出了多注意力机制层次神经网络模型。该模型主要包含两个组成部分:模型第一部分首先利用CNN 提取句子的局部特征,其次将得到的结果作为下一个LSTM模型的输入得到句子级的语义表示,最后将得到的句子级语义表示作为下一个LSTM的输入,最终形成篇章级的语义表示用于分类。模型第二部分针对评论数据中用户特征和商品属性对评论数据情感极性判定的重要贡献,采用注意力模型分别在句子级和篇章级把评价语料中用户特征和商品属性加入进去,在不同层次上更好地反映语义信息。
2 相关理论
2.1 词向量表示
使用神经网络构建模型时,首先需要将文本中的每个单词转换为低维的词向量表示,作为模型的输入。利用word2vec将已分好词的语料单词进行词向量的转化,定义词向量的维度为k,则某个词的词向量表示为:

假设输入句子S的长度为n,则句子可以用一个向量矩阵来表示,,其中表示句子中第i个词的向量表示。
2.2 卷积神经网络
卷积神经网络的具体结构如图1所示。
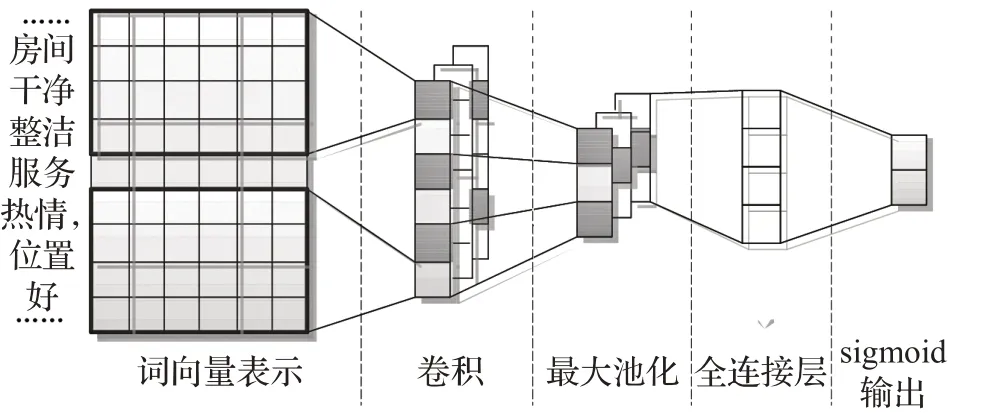
图1 卷积神经网络
主要由以下几个部分组成:
(1)输入层
(2)卷积层

其中,ci表示经过卷积操作后的第i个局部特征值,f(*)表示激活函数,和分别表示卷积核的权重和偏置,Si:i+m-1表示从第i个词到第i+m-1 个词的词窗口。多个卷积核经过卷积后的全体特征矩阵C为:

(3)池化层
池化层是CNN 的重要网络层,对通过卷积操作得到的特征C进行池化操作,提取最重要的局部特征,输出一个固定大小的矩阵。
(4)全连接层和输出层
池化层的输出通过连接一个全连接层传递给sigmoid输出层进行计算,得到最后的分类标签。
2.3 长短时记忆网络
长短时记忆网络(LSTM)是在循环神经网络(Recurrent Neural Network,RNN)的基础上进行改进,可以解决原始RNN 网络中存在的梯度消失问题,同时避免文本数据中由于间隔和延迟较长而忽略的重要信息,增加了长时记忆的能力。其单一节点的结构如图2所示。
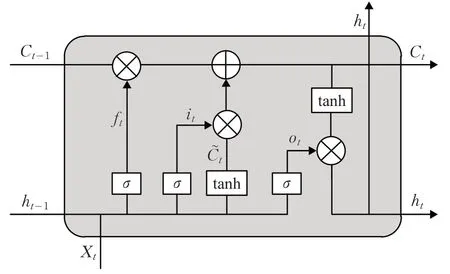
图2 长短时记忆网络
根据LSTM的网络结构,每个LSTM单元的计算公式如下:
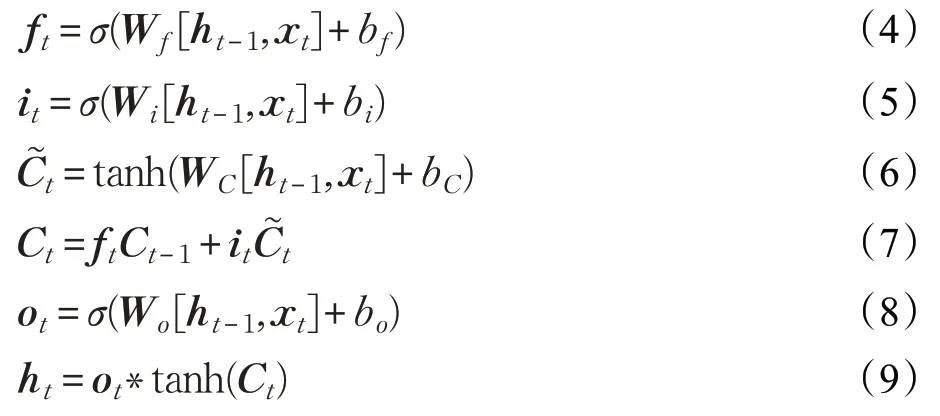
其中,σ表示sigmoid 函数,tanh 是双曲正切函数,ft和ii分别代表遗忘门和输入门,表示前一时刻状态,Ct表示t时刻的状态,ot为输出门,ht表示t时刻LSTM单元的输出,ht-1表示前一时刻LSTM单元的输出。
2.4 注意力机制
虽然CNN 和LSTM 能够很好地提取文本信息,但是评论文本中的句子或词对情感分析的重要性是不一样的。注意力机制(Attention Mechanism)在高层语义中对重要词的捕捉有很好的表现。注意力机制最早是在图像处理领域被提出,随后在翻译系统和对齐任务上取得了很好的结果。
注意力机制把LSTM 输出的隐层向量表达进行加权求和计算,其中权重的大小表示每个词或句子的重要程度。公式如下:


其中,e表示一个重要性评分函数,定义如下:

3 基于注意力机制和CNN_LSTM的多粒度层次神经网络
3.1 基于CNN 和LSTM 的多粒度层次神经网络模型
在文本情感分析的研究中,一条评论所包含的语义信息有不同的粒度,分为词语级别、句子级别和篇章级别等,其中句子级和篇章级情感分析将评论作为一个整体进行建模,分类结果过于粗糙。因此提出一种基于CNN 和LSTM 的多粒度层次神经网络模型,命名为HNN。该模型分别从词级别、句子级别和篇章级别获取语义信息,模型结构如图3所示。
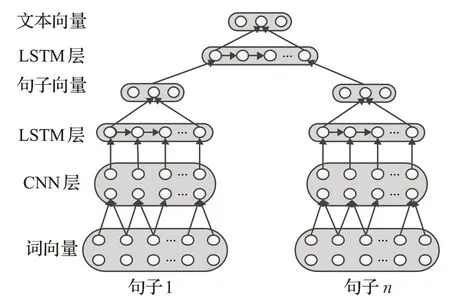
图3 层次神经网络
给定一条商品评论d,按照标点符号分为m个句子,即d={s1,s2,…,sm},其中每个句子si都包含n个词语,即si={w1,w2,…,wn}。提出基于 CNN 和 LSTM 的多粒度层次神经网络模型分别进行文本向量化处理,使用卷积操作获取词的上下文语义信息,利用LSTM计算不同级别的语义信息,最后使用softmax 函数实现文本的情感分类。具体步骤如下:
步骤1 通过word2vec得到每个词的向量表示:

步骤2 在模型的第二层使用卷积操作对句子中词的上下文语义信息进行提取。

其中,f函数为卷积操作,wi,context为通过当前词wi学习到的上下文表达。Wi-1、Wi、Wi+1表示权重,b为偏置。
步骤3 使用LSTM学习句子表达:

其中,H为学习到的当前句子表达,w1,context,w2,context,…,wd,context为一个句子中的d个词的上下文向量。
步骤4 把步骤3中句子级别的输出再次作为LSTM的输入,学习得到篇章的整体表示。
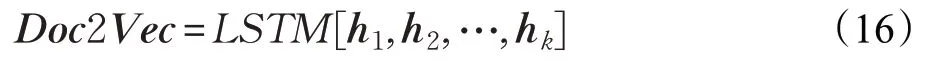
其中,Doc2Vec是整个评论的向量表示,h1,h2,…,hk为篇章中的每一个句子的向量表达。
步骤5 使用softmax函数把网络的最后输出转换为概率输出,具体公式如下:
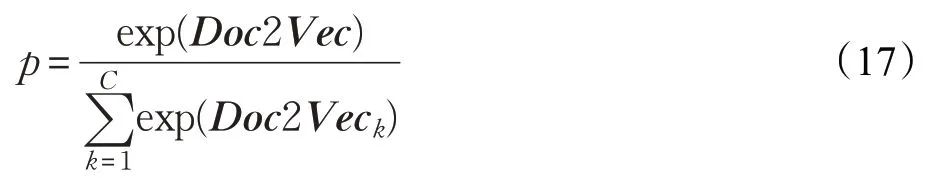
其中,C表示情感的类别数,p为评论属于各个类别的概率大小。通过最小化交叉熵损失函数对模型进行优化:
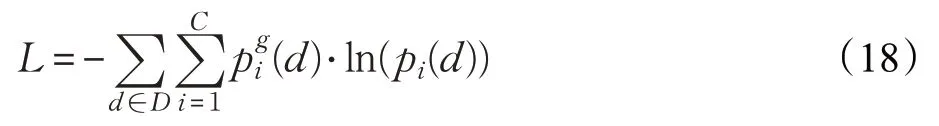
其中,D为训练集中所有数据,d为训练集中的一条数据,为实际类别,pi(d)为模型预测类别。
3.2 引入注意力机制的CNN_LSTM模型
基于CNN和LSTM的层次神经网络首先利用CNN的卷积和池化操作提取句子中词的局部特征,然后将其输入分层的LSTM模型中再次训练,但是却忽略了用户信息以及商品信息同样对分类结果有着重要的影响。因此为了提取不同层次(句子层次、篇章层次)的重要性,提出一个命名为UP-HNN 的新模型,在句子层次和篇章层次都加入了基于用户信息和商品信息的注意力机制来计算不同词和句子的重要性,将评论中重要的词和句子进行突出表现。模型结构如图4所示。

图4 基于注意力机制的层次模型
区别于原始的Attention权重公式,UP-HNN模型在计算Attention权重时加入了用户信息和商品信息,计算公式如下:

其中,u、p分别表示用户和商品的向量表达。评分函数e的公式如下:
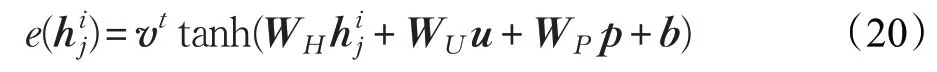
4 实验与分析
4.1 实验平台与数据集
本文实验基于Google 的深度学习框架Tensorflow进行实现。Tensorflow支持多种语言(Python、Java、C++等),同时提供CPU/GPU 并行计算能力,并集成了多种神经网络模型,例如卷积神经网络和LSTM 等,降低了模型代码构建的难度,提高了实验效率。
实验平台的具体设置如表1所示。

表1 实验平台设置
本文在三个公开的评论数据集上进行实验与测试,对提出的HNN 模型和UP-HNN 模型的有效性进行验证。实验数据集的信息统计如表2所示。

表2 IMDB、Yelp2013和Yelp2014数据集统计信息
表中Yelp2014 和Yelp2013 数据集的情感倾向值均为 1~5 分,IMDB 的情感分值为 1~10 分。1 分代表评论的情感倾向是负的,分数越高表示评论情感趋于正向。在实验中,对每个数据集进行划分(训练集、测试集和验证集的比例为8∶1∶1)。
4.2 评价指标
本文使用准确度Acc和均方误差RMSE作为评价模型分类结果的指标。

其中,T是本文模型预测正确的类别个数,N是所有的评论数,gd是真实类别,pr是预测类别。Acc越大,表示模型预测越准确。RMSE越小,表示真实值和预测值之间的差异越小。
4.3 超参数与训练
表3是实验所用参数的具体说明,其中词向量的维度设为200 维,用户向量和商品向量的维数也给定为200 维初始化全0 的向量,LSTM 的神经元个数为200。神经网络优化算法使用梯度下降法来更新参数,并利用Dropout机制来避免实验的过拟合。
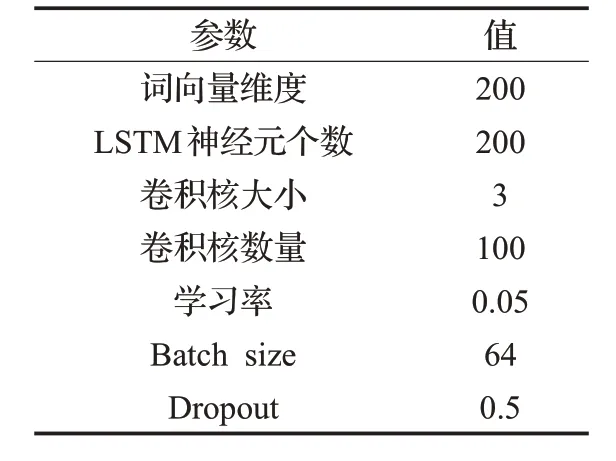
表3 实验参数
4.4 实验结果与分析
采用以下几种文本情感分类的方法与提出的模型进行比较:
Majority:对训练集中概率最大的标签值进行统计,作为测试集最终的情感标签。
Trigram:在SVM分类器中使用unigrams和trigrams作为特征进行训练。
SSWE+SVM:在SVM 分类器中利用SSWE 进行特征表示,然后训练[9]。
Paragraph Vector:基于PVDM算法的文本情感分析[14]。
JMARS:在主题模型和协同过滤的基础上加入用户信息和商品信息,用于文档级别的情感分类。
UPNN:在CNN分类模型中加入用户和商品的向量表达作为特征,并计算文本偏好矩阵进行情感分类[15]。
NSC:分别在句子级别和篇章级别使用分层的LSTM进行建模[16]。
NSC-UPA:在NSC的基础上加入用户和商品信息,利用注意力机制提取重要信息的分层LSTM模型[16]。
实验结果由包含用户和商品信息与不包含用户和商品信息两部分构成,具体结果如表4和表5所示。

表4 不包含用户和商品信息的实验结果
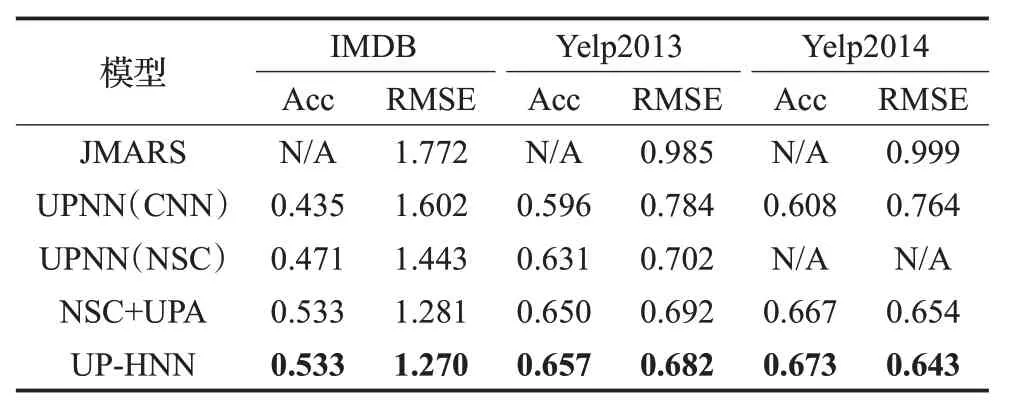
表5 包含用户和商品信息的实验结果
由表4和表5可以看出,HNN模型和UP-HNN模型在两部分均取得较好的效果。
在表4 中可以看出Majority 的效果是最差的,这是因为该方法没有提取到任何的文本信息。基于unigrams和trigrams 的Trigram 方法远好于Majority 方法。NSC方法通过在模型中分别引入句子级别和篇章级别的层次LSTM 网络进行建模,取得了比SSWE+SVM 和Paragraph Vector更好的效果。其中在Yelp2013数据集中,HNN 模型的均方误差低于Paragraph Vector 算法但比NSC算法略高,这是由于HNN在CNN池化操作的时候选择的是最大池化的方式。
在表5第二组实验中,可以看到加入用户和商品信息后的UP-HNN 模型较第一组未考虑用户和商品信息的HNN 模型而言,准确率分别提升了6.9、2.3 和2.7 个百分点,这表明在模型中加入用户信息和产品信息的确有助于提高情感分析的精度。此外,UP-HNN 模型和NSC+UPA 模型使用的是同一种注意力机制,可以看到在相同的条件下,UP-HNN模型在三个数据集上的实验效果均优于NSC+UPA模型,取得了更好的实验结果。
5 结束语
针对评价语料数据中存在词语级别、句子级别和篇章级别等不同粒度的语义信息,提出一种基于CNN 和LSTM 的多粒度层次神经网络模型。该模型首先利用卷积神经网络来提取句子的局部特征,其次将得到的结果作为下一个LSTM模型的输入得到句子级语义表示,最后将得到的句子级语义表示作为下一个LSTM 的输入,最终形成篇章级语义信息用于分类;同时针对评论数据中用户特征和商品属性对评论数据情感极性判定的重要贡献,在第一阶段给出的层次神经网络模型基础上,采用注意力模型分别在句子级和篇章级把评价语料中用户特征和商品属性加入进去,计算不同词和句子的注意力权重,在不同层次上更好地反映语义信息。在三个公开数据集上的实验结果也表明,加入用户和商品信息的模型较传统的方法更能提高情感分类的精度。
