基于深度学习的中孕期胎儿超声筛查切面自动识别
2020-05-20
1.南京大学医学院附属鼓楼医院 a.临床医学工程处;b.妇产科,江苏 南京 210008;2.东南大学 生物科学与医学工程学院,江苏 南京 210096
引言
中孕期是胎儿各个系统发育成熟的最佳时期,超声检查显示图像清晰,并可以多角度观察胎儿脏器,对明确畸形诊断,有效降低缺陷胎儿的出生率具有重要意义[1]。与此同时,中孕期胎儿结构筛查工作也存在很大风险,检查过程的不规范可能导致胎儿的畸形不能够被检出,导致缺陷儿的出生,也可能导致正常胎儿被误诊而因此引产[2]。因此,中孕期胎儿超声检查的质量控制尤为重要。
在实际的临床超声检查工作中,超声检查质量控制主要是由具有丰富经验的专家医师制定超声图像的质量评价标准,在标准中规定需要存取的切面,然后根据每个切面制定相应的评价内容,然后根据评价标准进行手动评价[2-3]。然而,手动评价存在很多缺点,如评价结果倾向于评价专家的主观性、评价过程耗时耗力,增加了评价专家的工作负担,实际工作中很难实现。为此,我们需要一种胎儿超声图像的自动质量控制解决方案,该方案能够根据专家医师制定的质量评价标准对医生采集的图像进行自动评价。然而,自动质量控制的第一步就是要精确识别医生采集的图像为哪一个切面,因此,精确识别胎儿超声筛查图像对中孕期胎儿超声筛查图像的自动质量控制至关重要。
近年来,随着计算机硬件水平的飞速提升和互联网技术的蓬勃发展,深度学习方法不断地在实践中取得革命性进展,在视觉和听觉等感知问题上取得了令人瞩目的成果。卷积神经网络(Convolutional Neural Networks,CNN)作为深度学习中的经典模型之一,在计算机视觉任务上取得了巨大成功,对处理图像的分类问题有着极高的效率[4]。在医学领域,深度学习方法也发展迅速并在多个方面成功应用,郭磊[5]构造了一个CNN,对宫颈细胞正常细胞与病变细胞进行识别分类;王媛媛[6]以肺部PET/CT三模态图像为研究对象,构建CNN,用于肺部肿瘤的分类和辅助诊断;余镇等[7]基于CNN和迁移学习方法,完成了对胎儿颜面部超声图像的自动识别;熊彪[8]基于CNN,搭建图像分类模型,应用于糖尿病视网膜病变的眼底图像分类。受以上研究启发,本研究将基于深度学习方法,利用CNN,完成对中孕期胎儿超声筛查切面的自动识别。
1 方法
本研究主要基于Vgg16网络模型,在该模型基础上进行模型微调,完成对中孕期胎儿超声筛查切面的精确自动识别。下面将对该方法进行详细介绍,主要包括CNN原理、Vgg16网络介绍及模型微调原理。
1.1 卷积神经网络原理
1962年,生物学家Huble和Wiesel在研究猫脑视觉皮层过程中,提出“感受野”概念[9]。感受野中的细胞有着复杂的神经网络结构,不同细胞选择性地响应不同刺激模式的特征,因此能够更好地展示出自然图像中的局部空间相关性。CNN就是受此研究的启发而提出的[10],与传统神经网络不同,CNN用卷积层和池化层替代了全连接层,通过权值共享、局部感受野和下采样,大大减少了训练参数的数量,并使其可以更加有效地学习越来越复杂、越来越抽象的视觉概念[11]。CNN主要由输入层、卷积层、池化层(降采样层)、全连接层和输出层组成(图1)。

图1 CNN结构图
输入层用来接收输入数据,对于图像数据,输入数据为多维的像素值矩阵。卷积层的主要作用是通过卷积运算完成对输入图像的特征提取,卷积运算由预先设定的卷积核在输入图像上以一定的步长滑动来完成,卷积核内的数值即为需要训练的权重,卷积运算后输出的图像称为特征图。卷积层由很多神经元组成,每个神经元对输入图像在卷积核尺寸大小的范围内进行局部连接,通过自身的权重与输入数值的加权,得到输出值。卷积层运算可用式(1)表示。

其中,l代表CNN的层数,k为卷积核,表示前一层的输出的一个特征图,表示卷积核的权重,为每个输出特征图的偏置,σ()为激活函数。激活函数的主要作用是用来加入非线性因素,表示输入输出之间非线性的复杂的任意函数映射,以解决线性模型表达能力不足的缺陷,常见的激活函数主要有Sigmoid函数、Tanh函数和ReLU函数。
池化层的主要作用是进行池化操作,池化是缩小高、长方向上的空间的运算,其主要作用是对特征图进行下采样,减少需要处理的特征图的元素个数。池化一般分为最大池化(Max Pooling)和平均池化(Average Pooling),最大池化是从目标区域中取出最大值,平均池化则是计算目标区域的平均值。
全连接层作用是将所有二维图像的特征图连接为一维特征作为全连接网络的输入,通过输入加权求和并通过激活函数的响应得到全连接层的输出。Softmax层为CNN的最后一层,以Softmax函数作为激活函数,广泛应用于多分类的神经网络中。Softmax函数公式如式(2)所示:

Softmax函数的作用就是如果判断输入属于某一个类的概率大于属于其他类的概率,那么这个类对应的值就逼近于1,其他类的值就逼近于0。其本质是将一个K维的任意实数向量映射成K维的实数向量,其中向量中的每个元素取值都介于(0,1)之间,且所有元素的和为1[12]。
CNN训练的目的就是获得合适的权重值。输入图像进入网络后,首先经过连续的卷积和池化运算得到预测值,然后通过损失函数计算预测值和真实值之间的损失值,通过优化器来更新权重值,优化器一般使用梯度下降算法,经过多次迭代循环,直到获得合适的权重值,使得损失值最小。损失函数主要有交叉熵误差(Crossentropy Error)和均方误差(Mean Squared Error),常用的优化其算法主要有随机梯度下降算法、Momentum算法、AdaGrad算法、RMSprop算法和Adam算法。CNN的训练过程[13],见图2。
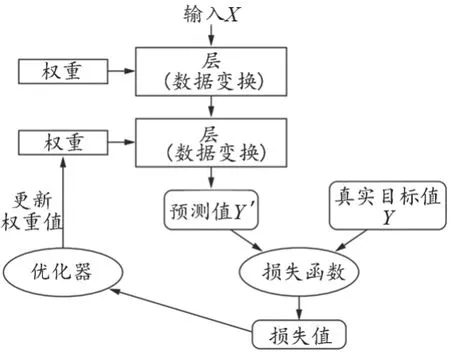
图2 卷积神经网络学习过程示意图
1.2 Vgg16网络模型
Vgg16网络是由牛津大学的Simonyan等[14]提出的一种深度CNN模型(图3),并且在当年的ILSVRC比赛中取得了92.3%的Top-5正确率[14]。
如图3所示,Vgg16网络由16层含有可训练参数的层组成,其中黑色表示卷积层,红色表示池化层,蓝色表示全连接层,棕色表示Softmax层。所有的卷积层都采用3×3的卷积核,步长为2,并进行0值填充,激活函数采用ReLU函数,所有的池化层池化范围为2×2,步长为2。这里我们用(长度×宽度×维数)来表示输入图像、特征图和卷积核的大小。图中输入图像大小为(224×224×3),第1、2层为含有64个大小为(3×3×3)的卷积核的卷积层,输出特征图大小为(224×224×64),经过池化层后,输出特征图大小为(112×112×64);第3、4层为含有128个大小(3×3×64)的卷积核的卷积层,输出特征图大小为(112×112×128),经过池化后变为(56×56×128);第5、6、7层为含有256个大小(3×3×128)的卷积核的卷积层,输出特征图大小为(56×56×256),经过池化后变为(28×28×256);第8、9、10层为含有512个大小(3×3×256)的卷积核的卷积层,输出特征图大小为(28×28×512),经过池化后变为(14×14×512);第11、12、13层为含有512个大小(3×3×512)的卷积核的卷积层,输出特征图大小为(14×14×512),经过池化后变为(7×7×512);第14、15、16层为含有4096个神经元的全连接层,最后经过Softmax层完成1000个类别的分类。

图3 Vgg16网络结构
1.3 模型微调
模型微调是一种广泛使用的模型复用方法,是指冻结预训练模型中的一些层,而只训练剩余的网络层。预训练模型是指已经在大型数据集上训练好的模型,如果这个原始数据集足够大且足够通用,那么预训练网络学到的特征的空间层次结构可以有效地作为视觉世界的通用模型,因此这些特征可用于各种不同的计算机视觉问题,即使这些新问题涉及的类别和原始任务完全不同。该方法可以大大加快网络训练速度,同时避免训练数据量过小而出现的过拟合现象[15-17]。本研究所使用的预训练模型为在ImageNet[18]数据集上训练好的Vgg16网络模型,ImageNet为一个包含140万张标记图像,共1000个不同类别的数据集。本研究中,我们将微调最后6个卷积层和最后的全连接层。微调网络的步骤如下:① 在已经训练好的基网络(Base Network)上根据自己的分类需要更改全连接层分类器;② 冻结基网络的相关层;③ 训练所添加的部分;④ 解冻基网络的一些层;⑤ 联合训练解冻的这些层和添加的部分。
1.4 实验验证
1.4.1 实验数据集
本实验中,所有数据均采集自南京鼓楼医院妇产科超声诊断中心,共采集2016—2018年孕18~24周胎儿结构筛查图像76260张,包含31个切面图像(表1)。其中,将68386张图像作为训练集,7874张图像作为测试集,训练集和测试集图像均包含31个切面,训练集中每个切面图像数量均为2206张,测试集中每个切面图像数量均为254张。

表1 采集切面名称及分类序号
1.4.2 实验环境
本研究采用基于Tensor flow为后端的Keras深度学习库为主要框架。TensorFlow是Google开源的一个深度学习框架,其拥有有完整的数据流向与处理机制,同时还封装了大量高效可用的算法及神经网络搭建方面的函数,是当今深度学习领域中最火的框架之一[19]。Keras[13]是一个模型级(Model-level)的库,为开发深度学习模型提供了高层次的构建模块。它不处理张量操作、求微分等低层次的运算。相反,它依赖于一个专门的、高度优化的张量库来完成这些运算,这个张量库就是Keras的后端引擎(Backend Engine)。目前,Keras有三个后端实现:TensorFlow后端、Theano后端和微软认知工具包(Microsoft Cognitive Toolkit,CNTK)后端。实验软件环境为Windows 10 64位操作系统,Python3.6.5,Tensor flow1.8.0,Keras 2.2.4,硬件环境为Intel i7 8700 3.20GHz CPU,NVIDIA GeForce GTX 1070 8G GPU,16G内存。
2 结果
本研究在基于Vgg16微调模型的基础上,将输入图像调整大小为224×224,采用categorical crossentropy损失函数,Adam优化器,设置学习率为0.001,为充分利用所有的数据,进行了1000次迭代,每次迭代选择64个样本数据进行梯度计算。在每次迭代后,分别计算训练数据的准确率和损失值及验证数据的准确率和损失值。根据训练结果,准确率及损失值曲线见图4~5。图4和图5中横轴表示训练迭代次数,纵轴表示准确率和损失值。如图4和图5所示,在进行了约60次迭代后,模型开始收敛,经过1000次迭代后,测试集准确率为94.8%。

图4 训练集及测试集准确率曲线

图5 训练集及测试集损失值曲线
为了更加直观地查看分类效果,我们通过混淆矩阵来查看各个类别具体的分类结果,归一化的混淆矩阵见图6。图6中的行代表该模型对超声图像预测的类别,列表示被预测图像的实际类别,对角线表示预测的类别与实际类别相同的图像所占比例。从图6中可以看出,除鼻骨切面、主肺动脉管径切面、腹壁脐带插入部位切面、宫颈切面识别准确率较低外,总体而言,该模型对图像的分类效果良好。
此外,我们采用国际通用分类评价参数:精确率、召回率、F1分数对每一个类别的分类结果进行定量评价。其中,精确率是指被预测为该类的数据中确实为该类别的数据所占的比例,召回率是指某一类别的数据中被预测为该类别的数据所占的比例,F1分数是精确率和召回率的调和均值,取值为0~1,其值越大,表明网络模型越稳定。各类别分类结果参数,见表2。

图6 归一化后的混淆矩阵

表2 各类别识别结果
3 讨论
中孕期胎儿超声结构筛查关乎胎儿的健康出生及家庭幸福,因此,超声筛查图像的质量控制至关重要。然而,目前手动评分的质量控制方法在实际的临床工作中耗时耗力,很难实现。随着深度学习方法的兴起,人工智能在日常生活中的很多领域取得成功,超声图像的自动质量控制也成为可能,精确识别超声切面图像是自动质量控制的重要内容,也是其他质量控制内容自动化的基础。本研究利用CNN,通过在Vgg16网络模型上微调,对胎儿超声筛查图像的识别准确率为94.8%,能够基本准确识别超声图像,但对其中少数类别的识别准确率偏低,在今后的研究中还需优化网络结构和训练技巧,进一步提高模型的泛化能力。本研究为胎儿超声图像的自动质量控制打下了坚实的基础,并可应用于其他医学图像的分类识别,具有良好的应用价值。
